EPO: Boosting 3D Foundation Models with Edge-based Pose Optimization
Pith reviewed 2026-07-02 14:53 UTC · model grok-4.3
The pith
Edge map alignment refines camera poses in 3D reconstructions without building feature tracks or point correspondences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EPO is a fully differentiable, trackless framework that treats edge-map alignment as a proxy for geometric optimization, recovering camera poses and 3D structure from 3D foundation model outputs while avoiding feature extraction and track construction entirely; evaluations show it matches or exceeds the accuracy of Bundle Adjustment-style methods at substantially lower runtime and memory footprint.
What carries the argument
Edge map alignment, which supplies the optimization objective by measuring consistency of edge maps across views to adjust poses and points without explicit multi-view correspondences.
If this is right
- Refinement becomes possible immediately after a foundation-model forward pass without any intermediate feature detection or matching.
- Memory consumption drops enough for the method to execute on consumer-grade GPUs where competing refinement techniques run out of memory.
- Runtime per scene decreases while accuracy on standard SfM benchmarks stays comparable to or better than track-based methods.
- The same edge-alignment objective can be applied across multiple downstream 3D tasks that start from foundation-model reconstructions.
Where Pith is reading between the lines
- The approach could be inserted into any pipeline that already produces rough camera estimates, lowering the barrier to high-quality 3D output on limited hardware.
- Because the signal comes from edges rather than points, the method might tolerate scenes where repeatable point features are scarce but edge structure remains visible.
- An end-to-end differentiable chain from image to refined 3D model becomes feasible if foundation-model components are also made differentiable with respect to the same edge objective.
Load-bearing premise
Edge maps extracted from the input images supply a sufficiently complete and unbiased geometric signal to recover accurate poses and structure without tracked point features.
What would settle it
A controlled test on a dataset with known ground-truth poses where EPO converges to solutions whose reprojection error or pose error exceeds that of a standard bundle-adjustment baseline by a clear margin.
Figures
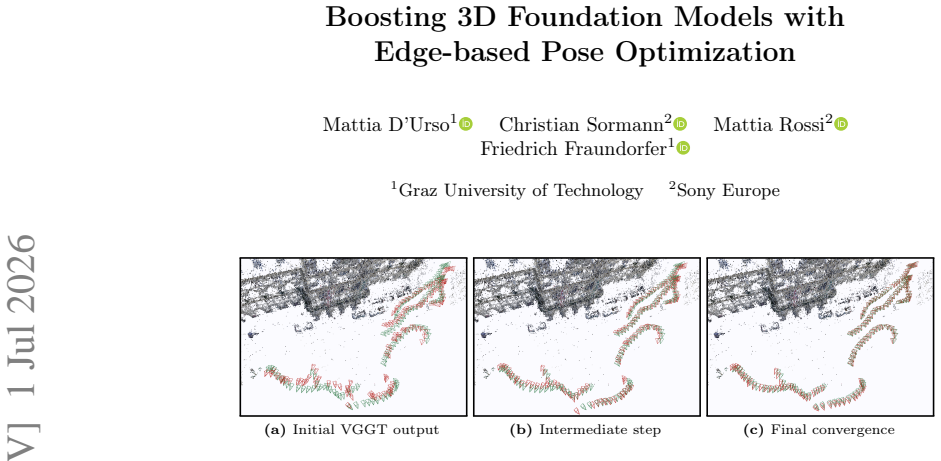


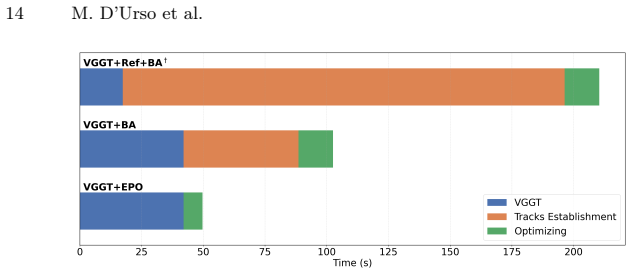
read the original abstract
We introduce \textbf{Edge-based Pose Optimization (EPO)}, a trackless geometric optimization framework specifically designed to boost the Structure-from-Motion reconstructions generated by 3D Foundation Models. These models achieve rapid inference by bypassing the time-consuming feature extraction and matching stages of traditional pipelines, where explicit correspondences between each 3D point and multiple images, referred to as tracks, are established. However, their geometric accuracy currently falls short of traditional pipelines. While this can be addressed in a post-processing step via Bundle Adjustment-like refinement, doing so requires extracting feature tracks, thus defeating the original speed advantage. Instead, our fully differentiable framework uses edge map alignment as a proxy for geometric optimization, avoiding feature extraction and track construction entirely. Through extensive evaluation across multiple datasets and tasks, we demonstrate that EPO matches or outperforms Bundle Adjustment-like methods while requiring significantly lower runtime and memory. Notably, its reduced memory footprint makes EPO suitable for consumer-grade hardware, where competing refinement methods cannot run.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Edge-based Pose Optimization (EPO), a fully differentiable, trackless framework for refining camera poses and 3D geometry from 3D foundation model outputs. It replaces explicit feature tracks and Bundle Adjustment with edge-map alignment as a geometric proxy, claiming to achieve comparable or superior accuracy to BA-like methods while using substantially lower runtime and memory, thereby enabling refinement on consumer-grade hardware.
Significance. If the performance claims hold under rigorous verification, EPO would represent a meaningful advance in efficient post-processing for foundation-model SfM pipelines by eliminating the need for feature extraction and multi-view track construction. The reduced memory footprint is a practical strength for deployment scenarios where traditional refinement is infeasible.
major comments (2)
- [Abstract] Abstract: the central performance claim ('matches or outperforms Bundle Adjustment-like methods') is presented without any quantitative metrics, tables, datasets, or ablation results. Because the soundness of the method rests on this empirical demonstration, the absence of supporting evidence in the manuscript is load-bearing.
- [Abstract] Abstract: the claim that edge-map alignment supplies a sufficiently constraining and unbiased signal for pose recovery is not accompanied by analysis of known limitations (aperture problem, viewpoint-dependent edge fragmentation, low-texture regions). Without explicit handling or empirical mitigation of these issues, the substitution for explicit multi-view tracks remains unverified.
minor comments (1)
- [Abstract] Abstract: the phrase 'Bundle Adjustment-like methods' is imprecise; the manuscript should name the specific baselines (e.g., COLMAP BA, certain differentiable renderers) used in the claimed comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim ('matches or outperforms Bundle Adjustment-like methods') is presented without any quantitative metrics, tables, datasets, or ablation results. Because the soundness of the method rests on this empirical demonstration, the absence of supporting evidence in the manuscript is load-bearing.
Authors: The abstract is a concise summary. The full manuscript provides the required empirical support through quantitative metrics, tables, datasets, and ablations in the Experiments section, demonstrating that EPO matches or outperforms BA-like methods with lower runtime and memory. No change to the abstract is needed as the evidence is already present in the body of the paper. revision: no
-
Referee: [Abstract] Abstract: the claim that edge-map alignment supplies a sufficiently constraining and unbiased signal for pose recovery is not accompanied by analysis of known limitations (aperture problem, viewpoint-dependent edge fragmentation, low-texture regions). Without explicit handling or empirical mitigation of these issues, the substitution for explicit multi-view tracks remains unverified.
Authors: We agree that explicit discussion of these limitations strengthens the paper. In the revised manuscript we will add a dedicated analysis subsection addressing the aperture problem, edge fragmentation, and low-texture regions, including how EPO's differentiable multi-view alignment provides mitigation. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and context describe EPO as a differentiable edge-map alignment proxy for pose optimization that avoids explicit tracks and feature extraction. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work are present in the given material. Performance claims rest on external dataset evaluations rather than any reduction of outputs to inputs by construction. The framework is therefore self-contained against the benchmarks it reports.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip- nerf 360: Unbounded anti-aliased neural radiance fields. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5470–5479 (2022)
2022
-
[2]
In: European Conference on Com- puter Vision
Brachmann, E., Wynn, J., Chen, S., Cavallari, T., Monszpart, A., Turmukhambe- tov, D., Prisacariu, V.A.: Scene coordinate reconstruction: Posing of image collec- tions via incremental learning of a relocalizer. In: European Conference on Com- puter Vision. pp. 421–440. Springer (2024)
2024
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cabon, Y., Stoffl, L., Antsfeld, L., Csurka, G., Chidlovskii, B., Revaud, J., Leroy, V.: Must3r: Multi-view network for stereo 3d reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1050– 1060 (2025)
2025
-
[4]
IEEE Transactions on Pattern Analysis and Machine IntelligenceP AMI-8(6), 679–698 (1986)
Canny, J.: A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine IntelligenceP AMI-8(6), 679–698 (1986)
1986
-
[5]
In: Proceedings of the IEEE conference on com- puter vision and pattern recognition workshops
DeTone, D., Malisiewicz, T., Rabinovich, A.: Superpoint: Self-supervised interest point detection and description. In: Proceedings of the IEEE conference on com- puter vision and pattern recognition workshops. pp. 224–236 (2018)
2018
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Doersch, C., Yang, Y., Vecerik, M., Gokay, D., Gupta, A., Aytar, Y., Carreira, J., Zisserman, A.: Tapir: Tracking any point with per-frame initialization and tem- poral refinement. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10061–10072 (2023)
2023
-
[7]
In: 2025 International Conference on 3D Vision (3DV)
Duisterhof, B.P., Zust, L., Weinzaepfel, P., Leroy, V., Cabon, Y., Revaud, J.: Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion. In: 2025 International Conference on 3D Vision (3DV). pp. 1–10. IEEE (2025)
2025
-
[8]
In: 2026 Inter- national Conference on 3D Vision (3DV)
D’Urso, M., Santellani, E., Sormann, C., Rossi, M., Kuhn, A., Fraundorfer, F.: A streamlined attention-based network for descriptor extraction. In: 2026 Inter- national Conference on 3D Vision (3DV). pp. 247–256. IEEE Computer Society (2026)
2026
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2026)
D’Urso, M., Sormann, C., Rossi, M., Fraundorfer, F.: Multi-view reconstructions of european landmarks in 4k. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2026)
2026
-
[10]
D2-Net: A Trainable CNN for Joint Detection and Description of Local Features
Dusmanu, M., Rocco, I., Pajdla, T., Pollefeys, M., Sivic, J., Torii, A., Sattler, T.: D2-net: A trainable cnn for joint detection and description of local features. arXiv preprint arXiv:1905.03561 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Edstedt, J., Athanasiadis, I., Wadenbäck, M., Felsberg, M.: Dkm: Dense kernel- ized feature matching for geometry estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17765–17775 (2023)
2023
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Edstedt, J., Sun, Q., Bökman, G., Wadenbäck, M., Felsberg, M.: Roma: Robust dense feature matching. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19790–19800 (2024)
2024
-
[13]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Elflein, S., Zhou, Q., Leal-Taixé, L.: Light3r-sfm: Towards feed-forward structure- from-motion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16774–16784 (2025)
2025
-
[14]
Theory of computing8(1), 415–428 (2012)
Felzenszwalb, P.F., Huttenlocher, D.P.: Distance transforms of sampled functions. Theory of computing8(1), 415–428 (2012)
2012
-
[15]
In: European Conference on Computer Vision
Harley, A.W., Fang, Z., Fragkiadaki, K.: Particle video revisited: Tracking through occlusions using point trajectories. In: European Conference on Computer Vision. pp. 59–75. Springer (2022) 10 M. D’Urso et al
2022
-
[16]
In: Proceedings of the IEEE interna- tional conference on computer vision
He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: Surpassing human- level performance on imagenet classification. In: Proceedings of the IEEE interna- tional conference on computer vision. pp. 1026–1034 (2015)
2015
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Karaev, N., Makarov, Y., Wang, J., Neverova, N., Vedaldi, A., Rupprecht, C.: Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6013–6022 (2025)
2025
-
[18]
In: European conference on computer vision
Karaev, N., Rocco, I., Graham, B., Neverova, N., Vedaldi, A., Rupprecht, C.: Cotracker: It is better to track together. In: European conference on computer vision. pp. 18–35. Springer (2024)
2024
-
[19]
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Rota Bulò, S., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: Ma- pAnything:Universalfeed-forwardmetric3Dreconstruction.In:2026International Conference on 3D Vision (3DV). pp. 499–509. IE...
2026
-
[20]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[21]
In: 2016 IEEE international conference on robotics and automation (ICRA)
Kuse, M., Shen, S.: Robust camera motion estimation using direct edge alignment and sub-gradient method. In: 2016 IEEE international conference on robotics and automation (ICRA). pp. 573–579. IEEE (2016)
2016
-
[22]
In: European Conference on Computer Vision
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: European Conference on Computer Vision. pp. 71–91. Springer (2024)
2024
-
[23]
In: 2026 International Conference on 3D Vision (3DV)
Li, J., Wang, H., Irshad, M.Z., Vasiljevic, I., Walter, M.R., Guizilini, V.C., Shakhnarovich, G.: FastMap: Revisiting structure from motion through first-order optimization. In: 2026 International Conference on 3D Vision (3DV). pp. 29–39. IEEE Computer Society (2026)
2026
-
[24]
In: International Conference on Learning Representations (ICLR) (2026),https://openreview.net/forum?id=yirunib8l8, oral
Lin, H., Chen, S., Liew, J.H., Chen, D.Y., Li, Z., Zhao, Y., Peng, S., Guo, H., Zhou, X., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. In: International Conference on Learning Representations (ICLR) (2026),https://openreview.net/forum?id=yirunib8l8, oral
2026
-
[25]
In: Proceedings of the IEEE/CVF international conference on com- puter vision
Lindenberger, P., Sarlin, P.E., Pollefeys, M.: Lightglue: Local feature matching at light speed. In: Proceedings of the IEEE/CVF international conference on com- puter vision. pp. 17627–17638 (2023)
2023
-
[26]
In: European Conference on Computer Vision
Liu, S., Gao, Y., Zhang, T., Pautrat, R., Schönberger, J.L., Larsson, V., Pollefeys, M.: Robust incremental structure-from-motion with hybrid features. In: European Conference on Computer Vision. pp. 249–269. Springer (2024)
2024
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, S., Yu, Y., Pautrat, R., Pollefeys, M., Larsson, V.: 3d line mapping revisited. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21445–21455 (2023)
2023
-
[28]
In: 7th Interna- tional Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: 7th Interna- tional Conference on Learning Representations (2019)
2019
-
[29]
Interna- tional journal of computer vision60(2), 91–110 (2004)
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Interna- tional journal of computer vision60(2), 91–110 (2004)
2004
-
[30]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[31]
In: International Workshop on Reproducible Research in Pattern Recog- nition
Moulon, P., Monasse, P., Perrot, R., Marlet, R.: Openmvg: Open multiple view geometry. In: International Workshop on Reproducible Research in Pattern Recog- nition. pp. 60–74. Springer (2016) Supplementary Material: Boosting 3D Foundation Models... 11
2016
-
[32]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
In: European Conference on Computer Vision
Pan, L., Baráth, D., Pollefeys, M., Schönberger, J.L.: Global structure-from-motion revisited. In: European Conference on Computer Vision. pp. 58–77. Springer (2024)
2024
-
[34]
Advances in neural information processing sys- tems32(2019)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high- performance deep learning library. Advances in neural information processing sys- tems32(2019)
2019
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Pautrat, R., Barath, D., Larsson, V., Oswald, M.R., Pollefeys, M.: Deeplsd: Line segment detection and refinement withdeep image gradients. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17327– 17336 (2023)
2023
-
[36]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Pautrat, R., Suárez, I., Yu, Y., Pollefeys, M., Larsson, V.: Gluestick: Robust image matching by sticking points and lines together. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9706–9716 (2023)
2023
-
[37]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12179–12188 (2021)
2021
-
[38]
Advances in neural information processing sys- tems32(2019)
Revaud, J., De Souza, C., Humenberger, M., Weinzaepfel, P.: R2d2: Reliable and repeatable detector and descriptor. Advances in neural information processing sys- tems32(2019)
2019
-
[39]
In: 2022 26th International conference on pattern recognition (ICPR)
Santellani, E., Sormann, C., Rossi, M., Kuhn, A., Fraundorfer, F.: Md-net: Multi- detector for local feature extraction. In: 2022 26th International conference on pattern recognition (ICPR). pp. 3944–3951. IEEE (2022)
2022
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: Superglue: Learning feature matching with graph neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4938–4947 (2020)
2020
-
[41]
In: 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Schenk, F., Fraundorfer, F.: Robust edge-based visual odometry using machine- learned edges. In: 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 1297–1304. IEEE (2017)
2017
-
[42]
In: 2019 International Conference on Robotics and Automation (ICRA)
Schenk, F., Fraundorfer, F.: Reslam: A real-time robust edge-based slam system. In: 2019 International Conference on Robotics and Automation (ICRA). pp. 154–
2019
-
[43]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4104–4113 (2016)
2016
-
[44]
International journal of computer vision80(2), 189–210 (2008)
Snavely, N., Seitz, S.M., Szeliski, R.: Modeling the world from internet photo col- lections. International journal of computer vision80(2), 189–210 (2008)
2008
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, J., Shen, Z., Wang, Y., Bao, H., Zhou, X.: Loftr: Detector-free local fea- ture matching with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8922–8931 (2021)
2021
-
[46]
In: Proceedings of the 23rd ACM international conference on Mul- timedia
Sweeney, C., Hollerer, T., Turk, M.: Theia: A fast and scalable structure-from- motion library. In: Proceedings of the 23rd ACM international conference on Mul- timedia. pp. 693–696 (2015)
2015
-
[47]
In: Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages
Tillet, P., Kung, H.T., Cox, D.: Triton: an intermediate language and compiler for tiled neural network computations. In: Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages. pp. 10–19 (2019) 12 M. D’Urso et al
2019
-
[48]
In: International workshop on vision algorithms
Triggs, B., McLauchlan, P.F., Hartley, R.I., Fitzgibbon, A.W.: Bundle adjust- ment—a modern synthesis. In: International workshop on vision algorithms. pp. 298–372. Springer (1999)
1999
-
[49]
Advances in neural information processing systems33, 14254–14265 (2020)
Tyszkiewicz, M., Fua, P., Trulls, E.: Disk: Learning local features with policy gra- dient. Advances in neural information processing systems33, 14254–14265 (2020)
2020
-
[50]
ACM Trans- actions on Graphics (TOG)36(1), 1–11 (2017)
Waechter, M., Beljan, M., Fuhrmann, S., Moehrle, N., Kopf, J., Goesele, M.: Vir- tual rephotography: Novel view prediction error for 3d reconstruction. ACM Trans- actions on Graphics (TOG)36(1), 1–11 (2017)
2017
-
[51]
In: 2025 Interna- tional Conference on 3D Vision (3DV)
Wang, H., Agapito, L.: 3d reconstruction with spatial memory. In: 2025 Interna- tional Conference on 3D Vision (3DV). pp. 78–89. IEEE (2025)
2025
-
[52]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025)
2025
-
[53]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Wang, J., Karaev, N., Rupprecht, C., Novotny, D.: Vggsfm: Visual geometry grounded deep structure from motion. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 21686–21697 (2024)
2024
-
[54]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Q., Zhang, Y., Holynski, A., Efros, A.A., Kanazawa, A.: Continuous 3d perception model with persistent state. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10510–10522 (2025)
2025
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20697–20709 (2024)
2024
-
[56]
In: International Conference on Learning Representations (ICLR) (2026),https://openreview
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π3: Permutation-equivariant visual geometry learning. In: International Conference on Learning Representations (ICLR) (2026),https://openreview. net/forum?id=DTQIjngDta
2026
-
[57]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, J., Sax, A., Liang, K.J., Henaff, M., Tang, H., Cao, A., Chai, J., Meier, F., Feiszli, M.: Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21924–21935 (2025)
2025
-
[58]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yeshwanth, C., Liu, Y.C., Nießner, M., Dai, A.: Scannet++: A high-fidelity dataset of 3d indoor scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12–22 (2023)
2023
-
[59]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[60]
arXiv preprint arXiv:2302.09493 (2023)
Zhao, H., Shang, J., Liu, K., Chen, C., Gu, F.: Edgevo: An efficient and accurate edge-based visual odometry. arXiv preprint arXiv:2302.09493 (2023)
-
[61]
IEEE Transac- tions on Instrumentation and Measurement72, 1–16 (2023)
Zhao, X., Wu, X., Chen, W., Chen, P.C., Xu, Q., Li, Z.: Aliked: A lighter keypoint and descriptor extraction network via deformable transformation. IEEE Transac- tions on Instrumentation and Measurement72, 1–16 (2023)
2023
-
[62]
arXiv preprint arXiv:2510.13310 (2025)
Zhong, J., Zhan, Z., Gao, Q., Chen, Z., Lou, H., Mao, J., Neumann, U., Wang, C., Wang, Y.: InstantSfM: Towards GPU-native SfM for the deep learning era. arXiv preprint arXiv:2510.13310 (2025)
-
[63]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation rep- resentations in neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5745–5753 (2019)
2019
-
[64]
IEEE Transactions on Robotics35(1), 184– 199 (2018)
Zhou, Y., Li, H., Kneip, L.: Canny-vo: Visual odometry with rgb-d cameras based on geometric 3-d–2-d edge alignment. IEEE Transactions on Robotics35(1), 184– 199 (2018)
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.