The Unsampled Truth: Psychometrics in SLMs Measure Prompt Artifacts, Not Psychological Constructs
Pith reviewed 2026-06-28 09:59 UTC · model grok-4.3
The pith
SLM outputs on psychometric tests reflect prompt artifacts like option symbols and personas more than any simulated psychological traits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
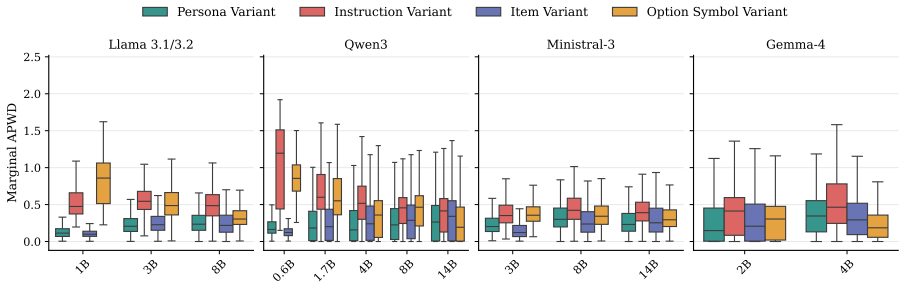
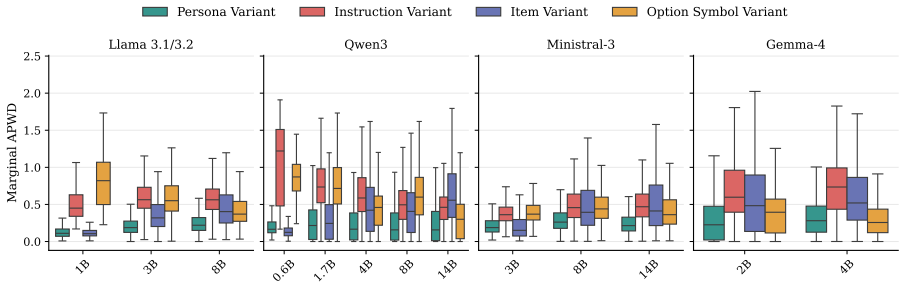
When prompting SLMs for psychometric assessments, researchers assume the outputs reflect semantic reasoning. Using a prompt variation framework that separates semantic signals from prompt artifacts by systematically varying personas, instructions, items, and option symbols, artifactual variance frequently overpowers the semantic signal, so models predominantly reflect prompt compliance rather than simulated psychological traits.
What carries the argument
Prompt variation framework that isolates semantic signals by holding item content fixed while changing personas, instructions, items, and option symbols across multiple models.
If this is right
- SLM utility for measuring psychological traits is limited because prompt compliance dominates.
- The variation framework can flag destructive artifacts in existing prompts.
- Semantic understanding can be isolated for later testing once artifacts are controlled.
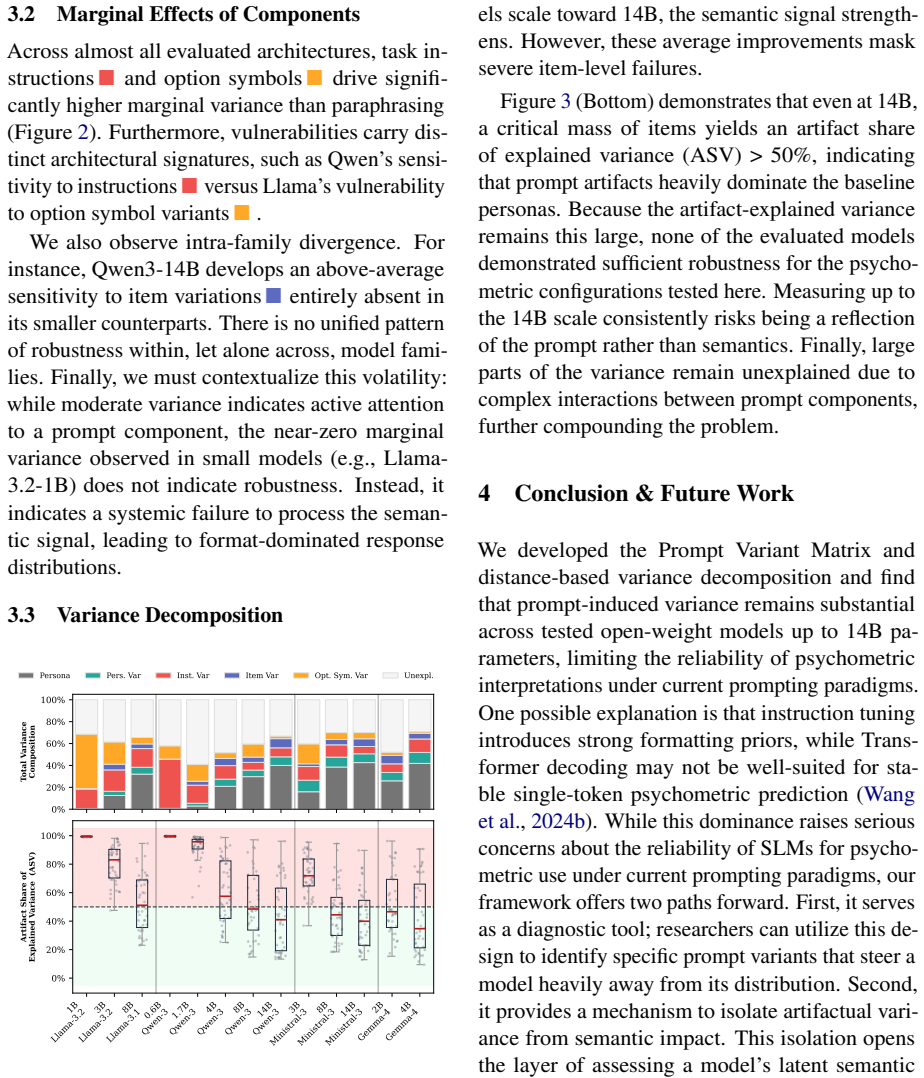
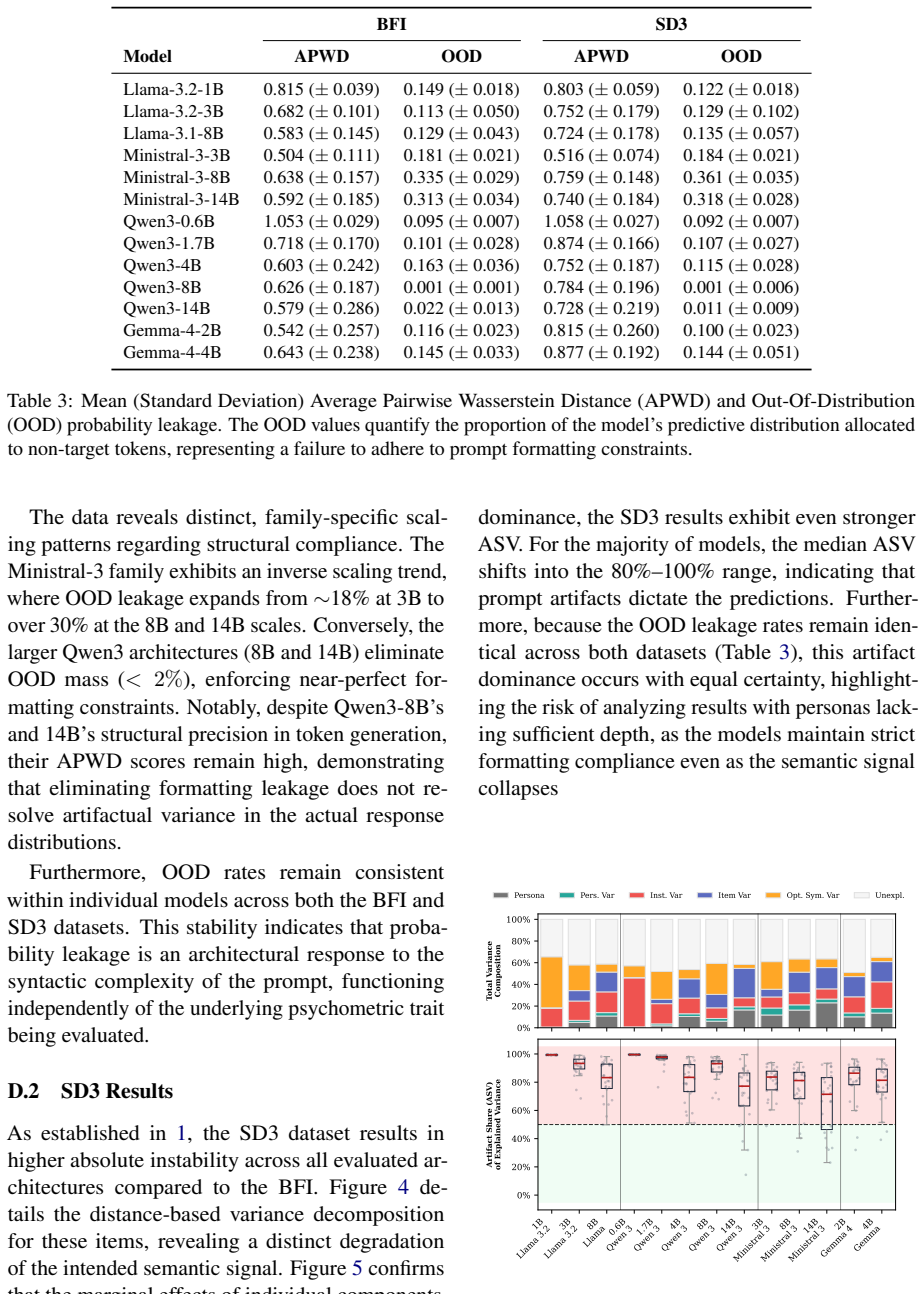
- Model size alone does not eliminate the artifact dominance observed from 0.6B to 14B parameters.
Where Pith is reading between the lines
- Any downstream application that treats SLM answers as trait measurements will inherit the same prompt-sensitivity problem unless the framework is applied first.
- The same variation technique could be used to test whether larger frontier models still exhibit artifact dominance or begin to stabilize on semantic content.
- Psychometric item banks intended for human use may need explicit redesign if they are to serve as stable probes for language models.
Load-bearing premise
The chosen changes to personas, instructions, items, and option symbols cleanly separate prompt artifacts from semantic signals without creating new correlated confounds.
What would settle it
A controlled run in which models produce statistically identical response distributions to the same items when only the non-semantic prompt elements are altered would falsify the claim that artifacts overpower semantics.
Figures

read the original abstract
When prompting SLMs for psychometric assessments, researchers assume the outputs reflect semantic reasoning. We evaluate this premise across 13 open-weights models (0.6B to 14B parameters) using a prompt variation framework that separates semantic signals from prompt artifacts. By systematically varying personas, instructions, items, and option symbols, we find that artifactual variance frequently overpowers the semantic signal. In these cases, models predominantly reflect prompt compliance rather than simulated psychological traits. While these findings limit SLM utility in psychometrics, our framework provides a diagnostic tool to identify destructive artifacts and isolate semantic understanding for future frontier-model research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that SLM outputs on psychometric assessments primarily reflect prompt artifacts rather than semantic reasoning about psychological constructs. Across 13 open-weights models (0.6B–14B parameters), a prompt variation framework systematically alters personas, instructions, items, and option symbols; the resulting artifactual variance is reported to frequently overpower any semantic signal, implying models exhibit prompt compliance instead of simulated traits. The framework is positioned as a diagnostic for isolating artifacts in future work.
Significance. If the claimed separation between artifacts and semantic signals holds after appropriate validation, the result would usefully caution against treating SLM psychometric outputs as proxies for psychological traits and supply a concrete diagnostic method for identifying destructive prompt effects. The empirical breadth (13 models, multiple variation axes) would strengthen the finding's applicability to the field.
major comments (2)
- [Abstract] Abstract: the assertion that the prompt variation framework 'separates semantic signals from prompt artifacts' is load-bearing for the central claim yet unsupported by any reported check for orthogonality. No human ratings of item semantics under each persona/instruction condition, no consistency analysis on semantically matched item pairs, and no other verification are described; without these, observed variance attributed to artifacts may partly reflect unaccounted semantic shifts induced by the persona changes themselves.
- [Abstract] Abstract: the statement that 'artifactual variance frequently overpowers the semantic signal' supplies no quantitative definition of semantic signal, no statistical tests, no error bars, and no exclusion criteria. This absence prevents independent verification of the dominance claim and of the conditions under which it holds.
minor comments (1)
- [Abstract] The abstract does not specify the exact psychometric instruments or item sets used, which would aid reproducibility even at the summary level.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas where additional rigor and clarification will strengthen the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the prompt variation framework 'separates semantic signals from prompt artifacts' is load-bearing for the central claim yet unsupported by any reported check for orthogonality. No human ratings of item semantics under each persona/instruction condition, no consistency analysis on semantically matched item pairs, and no other verification are described; without these, observed variance attributed to artifacts may partly reflect unaccounted semantic shifts induced by the persona changes themselves.
Authors: We agree that the manuscript would benefit from explicit validation of the separation assumption. The framework holds core item text fixed while varying only prompt elements, but we did not report human ratings or consistency checks to rule out induced semantic shifts. In revision we will add a dedicated paragraph in the Methods discussing this design assumption and its limitations, plus a small-scale human annotation study on a subset of items to quantify semantic consistency across conditions. This is a partial revision. revision: partial
-
Referee: [Abstract] Abstract: the statement that 'artifactual variance frequently overpowers the semantic signal' supplies no quantitative definition of semantic signal, no statistical tests, no error bars, and no exclusion criteria. This absence prevents independent verification of the dominance claim and of the conditions under which it holds.
Authors: The manuscript operationalizes semantic signal as variance attributable to fixed item content and artifactual variance as that arising from prompt manipulations, with direct comparisons shown in the results. To enable verification we will revise the Abstract, add explicit definitions in the Methods, incorporate statistical tests (e.g., variance partitioning or mixed-effects models), include error bars on figures, and state quantitative criteria for when artifactual variance overpowers the semantic signal. These changes will appear in the revised version. revision: yes
Circularity Check
No circularity: purely empirical variance decomposition under prompt manipulations
full rationale
The paper reports controlled experiments that systematically alter personas, instructions, items, and option symbols across 13 models and quantify the resulting output variance. No equations, fitted parameters, predictions, or derivations are present. The central claim is an empirical observation that artifactual variance often exceeds semantic signal; this is measured directly from the experimental outputs rather than derived from any self-referential construction or prior self-citation. The framework is a diagnostic tool, not a mathematical result that reduces to its inputs by definition. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Systematic variation of personas, instructions, items, and option symbols cleanly separates prompt artifacts from semantic signals
Reference graph
Works this paper leans on
-
[1]
Survey response gen- eration: Generating closed-ended survey responses in-silico with large language models.arXiv preprint arXiv:2510.11586. Marti J. Anderson
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Charles R Harris, K Jarrod Millman, Stéfan J Van Der Walt, Ralf Gommers, Pauli Virtanen, David Cour- napeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J Smith, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
InFindings of the asso- ciation for computational linguistics: NAACL 2024, pages 3605–3627
Personallm: In- vestigating the ability of large language models to express personality traits. InFindings of the asso- ciation for computational linguistics: NAACL 2024, pages 3605–3627. O. P. John and S. Srivastava. 1999.The Big Five Trait taxonomy: History, measurement, and theoretical perspectives, pages 102–138. Daniel N Jones and Delroy L Paulhus
2024
-
[4]
InFindings of the Associ- ation for Computational Linguistics: NAACL 2025, pages 8397–8437
Do llms have distinct and consistent personality? trait: Personality testset designed for llms with psychometrics. InFindings of the Associ- ation for Computational Linguistics: NAACL 2025, pages 8397–8437. Alexander H Liu, Kartik Khandelwal, Sandeep Sub- ramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill...
2025
-
[5]
Ministral 3.arXiv preprint arXiv:2601.08584. Marlene Lutz, Indira Sen, Georg Ahnert, Elisa Rogers, and Markus Strohmaier
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2507.16076 , year=
The prompt makes the person (a): A systematic evaluation of sociodemo- graphic persona prompting for large language models. arXiv preprint arXiv:2507.16076. Wes McKinney and 1 others
-
[7]
InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 245–258, Suzhou, China
Fingerprinting LLMs through survey item factor correlation: A case study on hu- mor style questionnaire. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 245–258, Suzhou, China. Association for Computational Linguistics. Philip M Podsakoff, Scott B MacKenzie, Jeong-Yeon Lee, and Nathan P Podsakoff
2025
-
[8]
Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto
Prompt perturbations reveal human-like biases in large language model survey responses.arXiv preprint arXiv:2507.07188. Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto
-
[9]
my answer is c
Scipy 1.0: fundamental algorithms for scientific computing in python.Nature methods, 17(3):261–272. Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, and 1 others. 2024a. Large language models are not fair evaluators. InProceedings of the 62nd Annual Meeting of the Association for Compu- tati...
2024
-
[10]
Trans- formers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv,...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
In International Conference on Learning Representa- tions, volume 2024, pages 40193–40219
Evaluating large lan- guage models at evaluating instruction following. In International Conference on Learning Representa- tions, volume 2024, pages 40193–40219. Jingyao Zheng, Xian Wang, Simo Hosio, Xiaoxian Xu, and Lik-Hang Lee
2024
-
[12]
Can llm" self-report?: Evaluating the validity of self-report scales in measuring person- ality design in llm-based chatbots.arXiv preprint arXiv:2412.00207. A Reproducibility and Code A vailability All experimental procedures, statistical analyses, and visualization tools are implemented using Python 3.13+ with standard scientific comput- ing libraries (...
-
[13]
library was used to run the models on one NVIDIA L40S. Com- plete code implementations, experimental con- figurations, processed datasets, results, analy- sis notebooks are available through our reposi- tory that will be made publicly available after the review process ( https://anonymous.4open. science/r/unsampled-truth/). B Generative AI Assistance Duri...
2025
-
[14]
(2026) Has a tendency to talk extensively –re-used fromTosato et al
Has a lot to say –re-used fromTosato et al. (2026) Has a tendency to talk extensively –re-used fromTosato et al. (2026) Often talks a great deal –re-used fromTosato et al. (2026) Is often chatting –re-used fromTosato et al. (2026) Option Symbol Variations■ Arabic Numerals (1–5) (Yang et al., 2025b) Uppercase Letters (A–E) (Yang et al., 2025b) Roman Numera...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.