FDM-MFVT: Few-step Sampling Diffusion Model for Mask-Free Virtual Try-On
Pith reviewed 2026-06-30 07:40 UTC · model grok-4.3
The pith
A diffusion model produces mask-free virtual try-on images in six sampling steps by optimizing noise from the input image alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
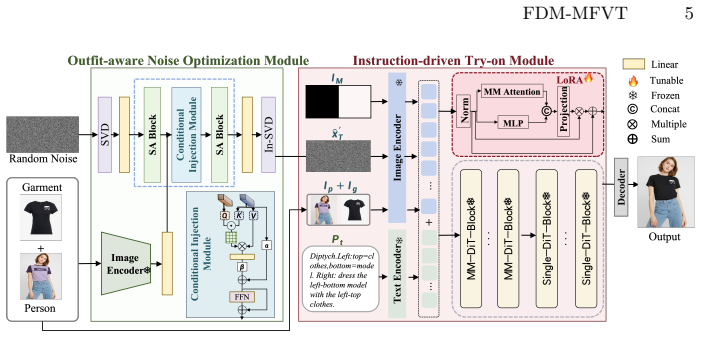
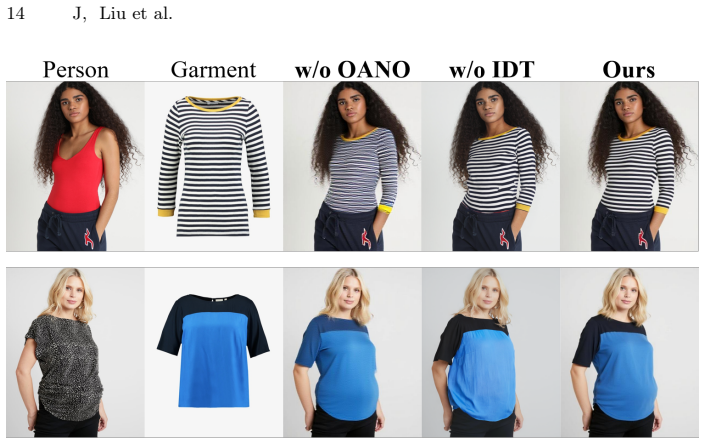
FDM-MFVT combines an Outfit-aware Noise Optimization Module (OANO) that initializes the alignment space with noise taken from the input person image and an Instruction-driven Try-on Module (IDT) that performs efficient adaptation guided by virtual try-on prompts. Together these components generate higher-fidelity try-on images from garment and person images alone after only six diffusion steps, outperforming both mask-based and mask-free baselines that need more steps, while the accompanying MFVT dataset of thirty thousand pairs removes the previous data bottleneck for mask-free training.
What carries the argument
The Outfit-aware Noise Optimization (OANO) module, which derives an initial noise field directly from the input image to set up the diffusion alignment space for few-step generation.
If this is right
- Only six diffusion steps are needed instead of thirty, lowering the compute required per try-on output.
- No masks or separate mask-prediction networks are required at inference time.
- The IDT module produces results from garment and person images alone when guided by text prompts.
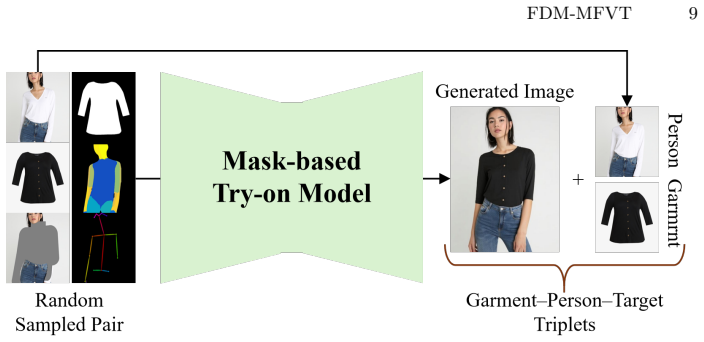
- A new thirty-thousand-pair mask-free dataset is released to support further work on this task.
- Quantitative and qualitative metrics exceed those of existing mask-based and mask-free baselines.
Where Pith is reading between the lines
- Mobile or web applications could run virtual try-on in real time because the step count drops to six.
- The same noise-initialization idea might apply to other diffusion-based image-editing tasks that currently depend on masks.
- Performance on body shapes or clothing categories underrepresented in the new dataset would indicate how far the input-image noise initialization generalizes.
- E-commerce sites could integrate the method without first running a separate segmentation model on every user photo.
Load-bearing premise
Noise taken from the input image alone is sufficient to create an alignment space that yields high-fidelity try-on results after only six diffusion steps without any masks.
What would settle it
A side-by-side comparison on person images with complex poses or garments whose texture and fit differ sharply from the target clothing, checking whether visible misalignment or artifacts remain after exactly six steps.
Figures




read the original abstract
Image-based Virtual Try-On (IVTON) has greatly advanced through diffusion models, yet existing methods require many sampling steps and depend on masks with costly auxiliary networks. In addition, the absence of large-scale mask-free paired datasets further limits the development of mask-free IVTON. We propose FDM-MFVT, a few-step diffusion model for mask-free IVTON, integrating an Outfit-aware Noise Optimization Module (OANO) and an Instruction-driven Try-on Module (IDT) to enhance efficiency and flexibility.The OANO module initializes the alignment space with noise using the input image and only needs 6 steps to generate a higher-fidelity try-on image compared to 30 steps.The IDT module uses virtual try-on prompts and efficient adaptation to generate high-quality results from garment and person images alone. We further introduce MFVT, a 30,000-pair mask-free IVTON dataset. Experiments show that FDM-MFVT achieves superior quantitative and qualitative results with fewer inference steps than mask-based and mask-free baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FDM-MFVT, a few-step diffusion model for mask-free image-based virtual try-on. It introduces an Outfit-aware Noise Optimization (OANO) module that initializes the alignment space using noise derived from the input image alone, an Instruction-driven Try-on (IDT) module that uses virtual try-on prompts for generation from garment and person images, and a new MFVT dataset of 30,000 mask-free pairs. The central claim is that the method produces higher-fidelity outputs in only 6 diffusion steps, outperforming both mask-based and mask-free baselines that require 30 steps.
Significance. If the empirical claims hold, the work would advance practical IVTON by demonstrating that mask-free generation is feasible with substantially reduced sampling steps and without auxiliary networks, addressing efficiency and data limitations in the field. The release of the MFVT dataset would also provide a concrete resource for future mask-free research.
major comments (2)
- [Abstract] Abstract: The assertion of 'superior quantitative and qualitative results' with 6 steps is presented without any reported metrics (e.g., FID, LPIPS, SSIM), baseline comparisons, ablation studies, or error analysis, which is load-bearing for the central claim of outperformance over mask-based and mask-free methods.
- [Abstract] Abstract (OANO description): No information is supplied on the optimization objective inside OANO, the distribution of training poses/garments, or how noise derived from the input image alone produces reliable garment-person alignment; this initialization is the load-bearing assumption for the 6-step inference claim without masks or extra networks.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify points regarding the abstract. We address each major comment below with references to the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of 'superior quantitative and qualitative results' with 6 steps is presented without any reported metrics (e.g., FID, LPIPS, SSIM), baseline comparisons, ablation studies, or error analysis, which is load-bearing for the central claim of outperformance over mask-based and mask-free methods.
Authors: The abstract provides a high-level summary of the contributions and claims. Detailed quantitative results including FID, LPIPS, and SSIM metrics, direct comparisons to mask-based and mask-free baselines (all using 30 steps), ablation studies on OANO and IDT, and error analysis are reported in Section 4 (Experiments) of the manuscript, where FDM-MFVT is shown to outperform baselines at 6 steps. We can revise the abstract to incorporate key numerical results if the editor prefers a more detailed summary. revision: partial
-
Referee: [Abstract] Abstract (OANO description): No information is supplied on the optimization objective inside OANO, the distribution of training poses/garments, or how noise derived from the input image alone produces reliable garment-person alignment; this initialization is the load-bearing assumption for the 6-step inference claim without masks or extra networks.
Authors: The optimization objective for OANO (a combined reconstruction and feature alignment loss), the MFVT dataset statistics (30,000 pairs with diverse poses, garments, and body types), and the alignment mechanism (initializing the diffusion latent space from person-image noise to encode identity and pose priors for subsequent prompt-guided garment synthesis via IDT) are fully specified in Section 3.1. These elements enable the mask-free 6-step inference without auxiliary networks, as validated in the experiments. revision: no
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes FDM-MFVT by introducing two new modules (OANO for noise initialization and IDT for prompt-driven try-on) plus a new 30k-pair dataset MFVT. The abstract and provided text contain no equations, no fitted parameters renamed as predictions, no self-citation chains invoked as uniqueness theorems, and no ansatzes smuggled via prior work. All performance claims rest on empirical comparison to baselines rather than any reduction of outputs to inputs by construction. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can be conditioned on garment and person images for virtual try-on without explicit masks.
invented entities (3)
-
OANO module
no independent evidence
-
IDT module
no independent evidence
-
MFVT dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Avrahami, O., Patashnik, O., Fried, O., Nemchinov, E., Aberman, K., Lischin- ski, D., Cohen-Or, D.: Stable flow: Vital layers for training-free image editing. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7877–7888 (2025)
2025
-
[2]
arXiv preprint arXiv:2303.04248 , year=
Berthelot,D.,Autef,A.,Lin,J.,Yap,D.A.,Zhai,S.,Hu,S.,Zheng,D.,Talbott,W., Gu, E.: Tract: Denoising diffusion models with transitive closure time-distillation. arXiv preprint arXiv:2303.04248 (2023)
-
[3]
In: Pro- ceedings of the IEEE/CVF international conference on computer vision
Cao, M., Wang, X., Qi, Z., Shan, Y., Qie, X., Zheng, Y.: Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. In: Pro- ceedings of the IEEE/CVF international conference on computer vision. pp. 22560– 22570 (2023)
2023
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Choi, S., Park, S., Lee, M., Choo, J.: Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14131–14140 (2021)
2021
-
[5]
In: European Conference on Computer Vision
Choi, Y., Kwak, S., Lee, K., Choi, H., Shin, J.: Improving diffusion models for authentic virtual try-on in the wild. In: European Conference on Computer Vision. pp. 206–235. Springer (2024)
2024
-
[6]
arXiv preprint arXiv:2407.15886 (2024)
Chong, Z., Dong, X., Li, H., Zhang, S., Zhang, W., Zhang, X., Zhao, H., Jiang, D., Liang, X.: Catvton: Concatenation is all you need for virtual try-on with diffusion models. arXiv preprint arXiv:2407.15886 (2024)
-
[7]
arXiv preprint arXiv:2508.20586 (2025)
Chong, Z., Lei, Y., Zhang, S., He, Z., Wang, Z., Zhang, X., Dong, X., Wu, Y., Jiang, D., Liang, X.: Fastfit: Accelerating multi-reference virtual try-on via cacheable diffusion models. arXiv preprint arXiv:2508.20586 (2025)
-
[8]
In: Pro- ceedings of the Winter Conference on Applications of Computer Vision
Cui, A., Mahajan, J., Shah, V., Gomathinayagam, P., Liu, C., Lazebnik, S.: Street tryon: Learning in-the-wild virtual try-on from unpaired person images. In: Pro- ceedings of the Winter Conference on Applications of Computer Vision. pp. 1414– 1423 (2025)
2025
-
[9]
ACM Transactions on Multimedia Computing, Com- munications and Applications19(1s), 1–21 (2023)
De Divitiis, L., Becattini, F., Baecchi, C., Del Bimbo, A.: Disentangling features for fashion recommendation. ACM Transactions on Multimedia Computing, Com- munications and Applications19(1s), 1–21 (2023)
2023
-
[10]
arXiv preprint arXiv:2508.13632 (2025)
Feng, Y., Zhang, L., Cao, H., Chen, Y., Feng, X., Cao, J., Wu, Y., Wang, B.: Omnitry: Virtual try-on anything without masks. arXiv preprint arXiv:2508.13632 (2025)
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ge, Y., Song, Y., Zhang, R., Ge, C., Liu, W., Luo, P.: Parser-free virtual try-on via distilling appearance flows. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8485–8493 (2021)
2021
-
[12]
In: ICML 2023 Workshop on Structured Probabilistic Inference{\&}Generative Modeling
Gu, J., Zhai, S., Zhang, Y., Liu, L., Susskind, J.M.: Boot: Data-free distillation of denoising diffusion models with bootstrapping. In: ICML 2023 Workshop on Structured Probabilistic Inference{\&}Generative Modeling. vol. 3 (2023)
2023
-
[13]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Güler, R.A., Neverova, N., Kokkinos, I.: Densepose: Dense human pose estimation in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7297–7306 (2018) 16 J, Liu et al
2018
-
[14]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Guo,H.,Zeng,B.,Song,Y.,Zhang,W.,Liu,J.,Zhang,C.:Any2anytryon:Leverag- ing adaptive position embeddings for versatile virtual clothing tasks. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 19085– 19096 (2025)
2025
-
[15]
In: Proceedings of the IEEE international conference on computer vision
Hadi Kiapour, M., Han, X., Lazebnik, S., Berg, A.C., Berg, T.L.: Where to buy it: Matching street clothing photos in online shops. In: Proceedings of the IEEE international conference on computer vision. pp. 3343–3351 (2015)
2015
-
[16]
In: Proceedings of the IEEE/CVF international conference on computer vision
Han,X.,Hu,X.,Huang,W.,Scott,M.R.:Clothflow:Aflow-basedmodelforclothed person generation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10471–10480 (2019)
2019
-
[17]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Han, X., Wu, Z., Wu, Z., Yu, R., Davis, L.S.: Viton: An image-based virtual try-on network. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7543–7552 (2018)
2018
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, S., Song, Y.Z., Xiang, T.: Style-based global appearance flow for virtual try- on. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3470–3479 (2022)
2022
-
[19]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence
Hong, J.W., Ton, T., Pham, T.X., Koo, G., Yoon, S., Yoo, C.D.: Ita-mdt: Image- timestep-adaptive masked diffusion transformer framework for image-based virtual try-on. In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence. pp. 28284–28294 (2025)
2025
-
[21]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Hsiao, W.L., Grauman, K.: Creating capsule wardrobes from fashion images. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7161–7170 (2018)
2018
-
[22]
In-context lora for diffusion transformers.arXiv preprint arXiv:2410.23775, 2024
Huang,L.,Wang,W.,Wu,Z.F.,Shi,Y.,Dou,H.,Liang,C.,Feng,Y.,Liu,Y.,Zhou, J.: In-context lora for diffusion transformers. arXiv preprint arXiv:2410.23775 (2024)
-
[23]
In: European Conference on Computer Vision
Issenhuth, T., Mary, J., Calauzenes, C.: Do not mask what you do not need to mask: a parser-free virtual try-on. In: European Conference on Computer Vision. pp. 619–635. Springer (2020)
2020
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kim, J., Gu, G., Park, M., Park, S., Choo, J.: Stableviton: Learning semantic correspondence with latent diffusion model for virtual try-on. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8176– 8185 (2024)
2024
-
[25]
arXiv preprint arXiv:1907.10830 (2019)
Kim, J., Kim, M., Kang, H., Lee, K.: U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image transla- tion. arXiv preprint arXiv:1907.10830 (2019)
-
[26]
In: European Conference on Com- puter Vision
Lee, S., Gu, G., Park, S., Choi, S., Choo, J.: High-resolution virtual try-on with misalignment and occlusion-handled conditions. In: European Conference on Com- puter Vision. pp. 204–219. Springer (2022)
2022
-
[27]
Advances in Neural Information Processing Systems36, 20662–20678 (2023)
Li, Y., Wang, H., Jin, Q., Hu, J., Chemerys, P., Fu, Y., Wang, Y., Tulyakov, S., Ren, J.: Snapfusion: Text-to-image diffusion model on mobile devices within two seconds. Advances in Neural Information Processing Systems36, 20662–20678 (2023)
2023
-
[28]
VTEdit-Bench: A Comprehensive Benchmark for Multi-Reference Image Editing Models in Virtual Try-On
Liang, X., Qu, Z., Zou, M., Liu, J., Jiang, L., Xu, M., Zhu, Y.: Vtedit-bench: A comprehensive benchmark for multi-reference image editing models in virtual try-on. arXiv preprint arXiv:2603.11734 (2026) FDM-MFVT 17
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Meng, C., Rombach, R., Gao, R., Kingma, D., Ermon, S., Ho, J., Salimans, T.: On distillation of guided diffusion models. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 14297–14306 (2023)
2023
-
[31]
In: CVPR workshops
Minar, M.R., Tuan, T.T., Ahn, H., Rosin, P., Lai, Y.K.: Cp-vton+: Clothing shape and texture preserving image-based virtual try-on. In: CVPR workshops. vol. 3, pp. 10–14 (2020)
2020
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Morelli, D., Fincato, M., Cornia, M., Landi, F., Cesari, F., Cucchiara, R.: Dress code: High-resolution multi-category virtual try-on. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2231–2235 (2022)
2022
-
[33]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ning, S., Wang, D., Qin, Y., Jin, Z., Wang, B., Han, X.: Picture: Photorealis- tic virtual try-on from unconstrained designs. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6976–6985 (2024)
2024
-
[34]
arXiv preprint arXiv:2407.14041 (2024)
Qi, Z., Bai, L., Xiong, H., Xie, Z.: Not all noises are created equally: Diffusion noise selection and optimization. arXiv preprint arXiv:2407.14041 (2024)
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684– 10695 (2022)
2022
-
[36]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Sarkar, R., Bodla, N., Vasileva, M.I., Lin, Y.L., Beniwal, A., Lu, A., Medioni, G.: Outfittransformer: Learning outfit representations for fashion recommendation. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 3601–3609 (2023)
2023
-
[38]
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models (2023)
2023
-
[39]
In: Proceed- ings of the International Conference on Machine Learning (ICML)
Song, Y., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: Proceed- ings of the International Conference on Machine Learning (ICML). pp. 9198–9207 (2020)
2020
-
[40]
IEEE Transactions on Image Processing27(12), 6283–6294 (2018)
Wang, B., Zheng, H., Liang, X., Shen, X., Shao, L.: Toward photo-realistic virtual try-on by adaptively generating-preserving image content. IEEE Transactions on Image Processing27(12), 6283–6294 (2018)
2018
-
[41]
Mod- eling and predicting single-cell multi-gene perturbation responses with scLAMBDA.bioRxiv, 2024a
Wang, J., Pu, J., Qi, Z., Guo, J., Ma, Y., Huang, N., Chen, Y., Li, X., Shan, Y.: Taming rectified flow for inversion and editing. arXiv preprint arXiv:2411.04746 (2024)
-
[42]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[43]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Xu, Y., Gu, T., Chen, W., Chen, A.: Ootdiffusion: Outfitting fusion based latent diffusion for controllable virtual try-on. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 8996–9004 (2025)
2025
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, X., Ding, C., Hong, Z., Huang, J., Tao, J., Xu, X.: Texture-preserving dif- fusion models for high-fidelity virtual try-on. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7017–7026 (2024)
2024
-
[45]
In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision
Yang, Z., Li, Y., He, S., Li, X., Xu, Y., Dong, J., Du, Y.: Omnivton: Training-free universal virtual try-on. In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision. pp. 16702–16711 (2025) 18 J, Liu et al
2025
-
[46]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhou, Z., Shao, S., Bai, L., Zhang, S., Xu, Z., Han, B., Xie, Z.: Golden noise for diffusion models: A learning framework. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17688–17697 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.