Reasoners or Translators? Contamination-aware Evaluation and Neuro-Symbolic Robustness in Tax Law
Pith reviewed 2026-05-20 18:07 UTC · model grok-4.3
The pith
Neuro-symbolic systems that translate tax statutes into formal logic outperform language models on new cases by resisting data contamination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
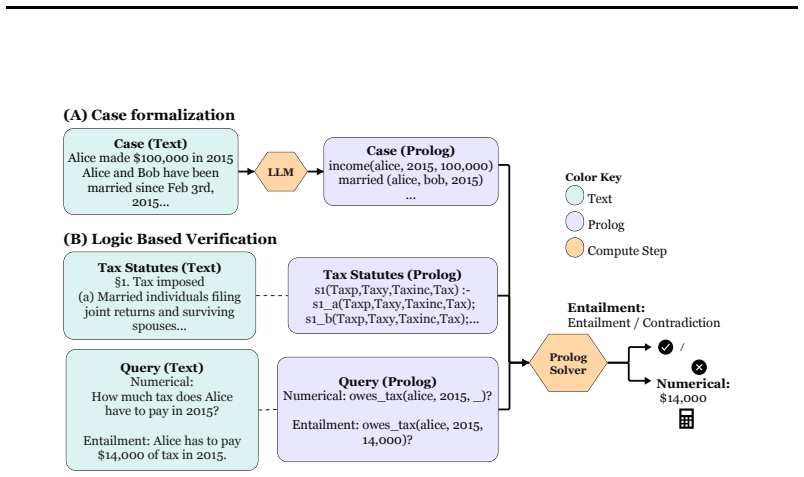
We show that LLM performance on tax law tasks can be inflated by contamination. Using a new test suite that probes generalization via case and rule variations, we compare monolithic language models against neuro-symbolic pipelines that translate statutory text into formal representations and delegate inference to symbolic solvers; the hybrid approach proves more reliable, robust, and capable of handling unobserved situations.
What carries the argument
Contamination detection protocol paired with a test suite of case and rule variations that isolates genuine generalization from memorized training data.
If this is right
- Legal AI evaluations must include explicit checks for training-data contamination to report true reasoning ability.
- Hybrid translation-plus-solver systems generalize better to new tax documents than end-to-end language models.
- Compositional structure in statutes favors separating natural-language translation from symbolic inference.
- Tax-law applications gain reliability when inference is performed by exact solvers rather than probabilistic text generation.
Where Pith is reading between the lines
- The same contamination risks likely appear in LLM evaluations for other narrow domains such as medical or financial regulation.
- Practical tools could combine the translation step with existing symbolic tax engines already used by professionals.
- Scaling the formal-representation layer might eventually reduce reliance on ever-larger language-model training corpora.
Load-bearing premise
The test suite and contamination detection protocol correctly identify examples the models have never encountered before.
What would settle it
A pure language model reaching equal or higher accuracy than the neuro-symbolic system on the varied test cases after the protocol rules out any training-data overlap would undermine the claim that hybrid frameworks are more robust.
Figures

read the original abstract
Recent advances in large language models (LLMs) have significantly enhanced automated legal reasoning. Yet, it remains unclear whether their performance reflects genuine legal reasoning ability or artifacts of data contamination. We present a comprehensive empirical study of tax law reasoning approaches and implement a contamination detection protocol to rigorously assess LLM reliability. We show that performance can be inflated by contamination. Building on this analysis, we conduct a systematic evaluation, comparing monolithic LLMs with hybrid systems that translate statutory text into formal representations and delegate inference to symbolic solvers. We build a novel test suite designed to probe generalization to unseen documents via case and rule variations. Our findings indicate that legal reasoning is inherently compositional and that neuro-symbolic frameworks offer a more reliable and robust foundation for legal AI, as well as improved generalization to unobserved situations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a comprehensive empirical study of tax law reasoning in LLMs, implements a contamination detection protocol to assess reliability, and compares monolithic LLMs against neuro-symbolic hybrids that translate statutory text into formal representations for symbolic inference. It introduces a novel test suite with case and rule variations to probe generalization to unseen documents, concluding that legal reasoning is inherently compositional and that neuro-symbolic frameworks provide more reliable, robust performance with better generalization than pure LLMs.
Significance. If the central claims hold after addressing the noted gaps, the work would meaningfully advance legal AI by demonstrating the practical value of contamination-aware evaluation protocols and hybrid neuro-symbolic systems for compositional reasoning tasks. The introduction of a dedicated test suite for unseen variations represents a constructive step toward more rigorous benchmarking in the domain.
major comments (2)
- [Abstract] Abstract: The manuscript states that a contamination detection protocol was implemented and that LLM performance 'can be inflated by contamination,' yet supplies no quantitative thresholds, similarity metrics, error bars, or concrete examples of excluded cases. This omission is load-bearing for the central claim, as it prevents verification that the novel test suite's variations truly lie outside the training distributions of the evaluated models.
- [Abstract] Abstract / test suite description: The reported robustness advantage of the neuro-symbolic pipeline over monolithic LLMs is attributed to improved generalization to 'unobserved situations' via case and rule variations. Without explicit details on how paraphrased statutory fragments or structurally isomorphic rules were excluded (e.g., via embedding similarity thresholds or manual review criteria), it remains possible that the advantage arises from the symbolic solver's exact matching rather than genuine compositional generalization.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one illustrative quantitative result (e.g., a performance delta or contamination rate) to ground the high-level claims.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important areas for improving the transparency of our contamination detection protocol and test suite construction. We address each point below and will incorporate revisions to strengthen the manuscript's verifiability while preserving the core empirical findings on neuro-symbolic advantages in tax law reasoning.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript states that a contamination detection protocol was implemented and that LLM performance 'can be inflated by contamination,' yet supplies no quantitative thresholds, similarity metrics, error bars, or concrete examples of excluded cases. This omission is load-bearing for the central claim, as it prevents verification that the novel test suite's variations truly lie outside the training distributions of the evaluated models.
Authors: We agree that the abstract would benefit from greater specificity on these elements to support verifiability. The full manuscript (Section 3.2) describes the protocol using sentence-BERT embeddings with a cosine similarity threshold of 0.82 for initial flagging, followed by manual review of the top 20% most similar candidates; this led to exclusion of 14 test instances with concrete examples provided in Appendix B. Error bars (standard deviation across 5 runs) are reported in Tables 2 and 3. We will revise the abstract to concisely reference the similarity threshold, number of exclusions, and point to the appendix for an example excluded case. This addresses the load-bearing concern without altering the reported results. revision: yes
-
Referee: [Abstract] Abstract / test suite description: The reported robustness advantage of the neuro-symbolic pipeline over monolithic LLMs is attributed to improved generalization to 'unobserved situations' via case and rule variations. Without explicit details on how paraphrased statutory fragments or structurally isomorphic rules were excluded (e.g., via embedding similarity thresholds or manual review criteria), it remains possible that the advantage arises from the symbolic solver's exact matching rather than genuine compositional generalization.
Authors: This is a fair point regarding potential ambiguity in attributing the robustness gains. Section 4.3 details the variation generation process: we applied embedding similarity thresholds below 0.78 against both training data and original statutes, combined with automated structural isomorphism checks (via AST comparison of rule trees) and manual review by two domain experts for compositional differences. The neuro-symbolic pipeline's advantage stems from its explicit handling of rule composition and case instantiation in the solver, not exact string matching, as evidenced by performance drops in LLMs even on non-exact but semantically close inputs. We will add a new paragraph in the test suite section (and a brief note in the abstract) explicitly stating the exclusion criteria, thresholds, and review process with one illustrative example of a retained variation. revision: yes
Circularity Check
Empirical evaluation with no circular derivation steps
full rationale
The paper reports an empirical study that compares monolithic LLMs against neuro-symbolic pipelines on tax-law tasks, using a contamination-detection protocol and a novel test suite built from case/rule variations. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the provided text. The central claim that neuro-symbolic systems generalize better rests on experimental outcomes that are independently replicable rather than reducing to prior definitions or inputs by construction. This is a standard empirical comparison whose validity can be assessed against external benchmarks without circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM performance on legal tasks can be meaningfully inflated by data contamination from training corpora
- domain assumption Translating statutory text into formal representations preserves all necessary legal semantics for inference
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2508.21051. Gabriele Lorenzo, Aldo Pietromatera, and Nils Holzenberger. Translating tax law to code with LLMs: A benchmark and evaluation framework. In Nikolaos Aletras, Ilias Chalkidis, Leslie Barrett, C˘at˘alina Goan˘a, Daniel Preoiuc-Pietro, and Gerasimos Spanakis (eds.), Proceedings of the Natural Legal Language Processing Wor...
-
[2]
Dates in any format (e.g., "Feb 3rd, 1992", "2015-01-01", "January 31st")
work page 1992
- [3]
-
[4]
Section/statute/citation references (e.g., "Section 152(c)(1)", "section 151(b)", " 151")
- [5]
-
[6]
Person names and proper nouns (Alice, Bob, Charlie, IRS, Treasury, etc.)
- [7]
-
[8]
Tax/legal terms of art and defined concepts: - Do NOT replace any term that could change doctrinal meaning even if it seems synonymous. - Examples of IMMUTABLE concept-terms include (not exhaustive): "taxpayer", "dependent", "deduction", "exemption", "credit", "income", "gross income", "adjusted gross income", "taxable year", "filing status", "resident", ...
work page 2017
-
[9]
Declare the event type with a unique identifier: `marriage_(alice_and_bob_marriage).`
-
[10]
Attach properties to that event using its ID: 20 `agent_(alice_and_bob_marriage, alice).` `agent_(alice_and_bob_marriage, bob).` `start_(alice_and_bob_marriage, "2015-02-02").` OUTPUT FORMAT
work page 2015
-
[16]
Amounts: integers without symbols (50000 not $50,000) PREDICATE VOCABULARY **Property predicates** attach information to events: - agent_(Event, Entity) - the actor/subject performing or experiencing the event - patient_(Event, Entity) - the affected entity, object, or location - start_(Event, Date) - when the event begins - end_(Event, Date) - when the e...
work page 2017
-
[17]
Declare the event type with a unique identifier: `income_(alice_income_2017).`
-
[18]
Attach properties to that event using its ID: `agent_(alice_income_2017, alice).` `amount_(alice_income_2017, 50000).` `start_(alice_income_2017, "2017-12-31").` OUTPUT FORMAT
work page 2017
-
[19]
Output ONLY Prolog facts - no rules, no`:-`directives, no comments
-
[20]
Each fact must end with a period
- [21]
-
[22]
Person names: lowercase atoms (alice, bob, charlie)
- [23]
-
[24]
Amounts: integers without symbols (50000 not $50,000) PREDICATE VOCABULARY **Property predicates** attach information to events: - agent_(Event, Entity) - the actor/subject performing or experiencing the event - patient_(Event, Entity) - the affected entity, object, or location - start_(Event, Date) - when the event begins - end_(Event, Date) - when the e...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.