Priced Motion Through Optimal Faces: A Normal-Fan Geometry for Non-Stationary Adversarial MDPs
Pith reviewed 2026-06-30 09:21 UTC · model grok-4.3
The pith
Dynamic regret in non-stationary adversarial MDPs decomposes exactly into priced face motion plus within-face selection error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
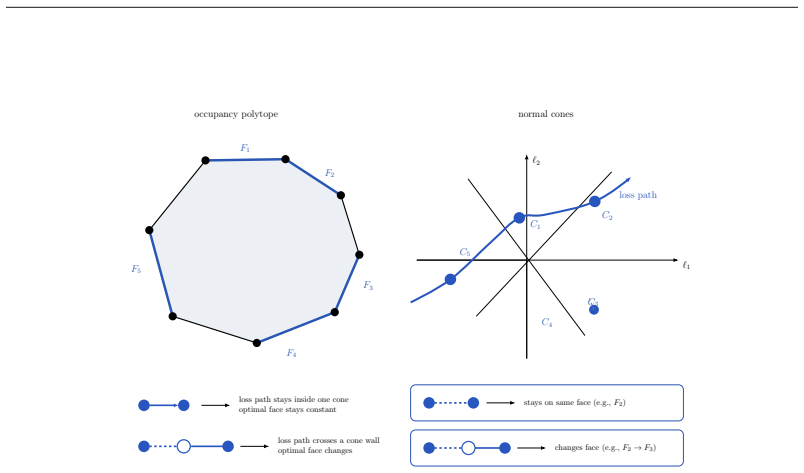
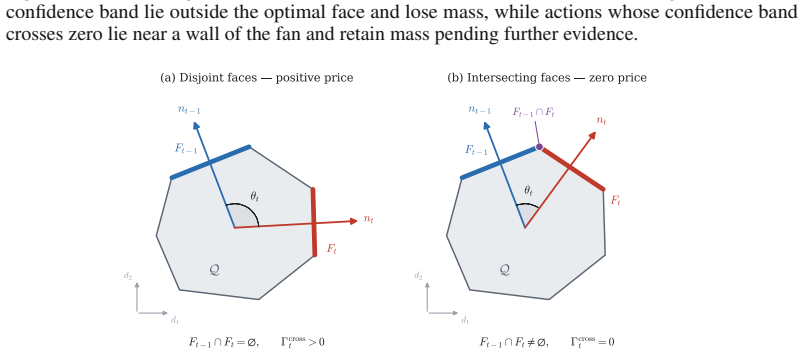
Occupancy measures form a polytope whose normal fan partitions loss space into cones, each exposing one optimal face. A path of losses traces a path through this fan; motion inside a cone leaves the optimal face fixed, while crossing a wall changes it. The face-crossing price is the minimum regret of remaining on the old face under the new loss. For any learner that tracks the previous face, dynamic regret equals the total priced motion through the fan plus the within-face selection error.
What carries the argument
The normal fan of the occupancy polytope together with the face-crossing price, which quantifies the regret cost of moving from one cone to another.
If this is right
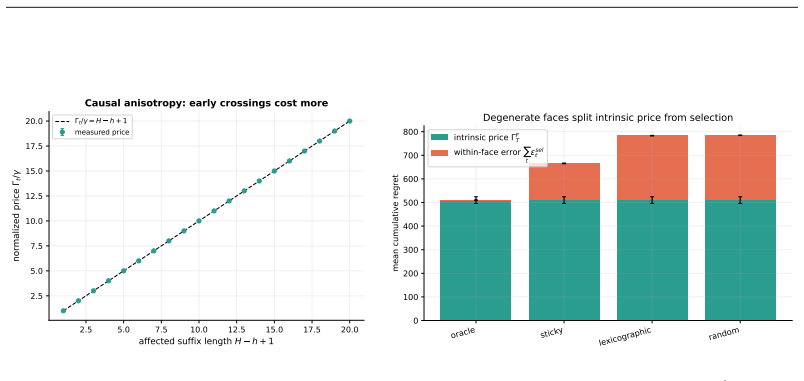
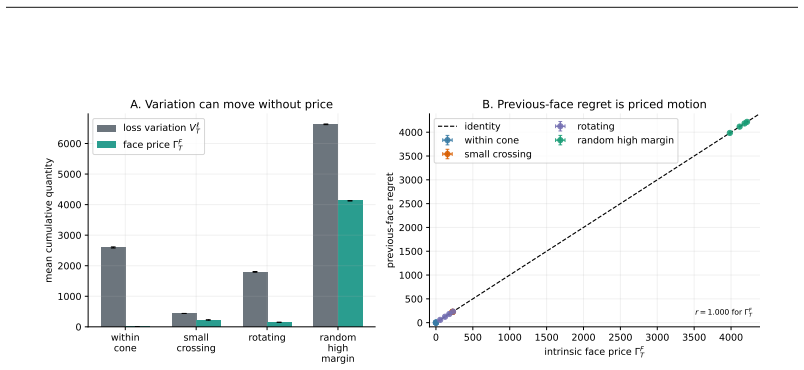
- Loss variation of arbitrary magnitude can produce zero priced motion and therefore zero added regret if the path stays inside one cone.
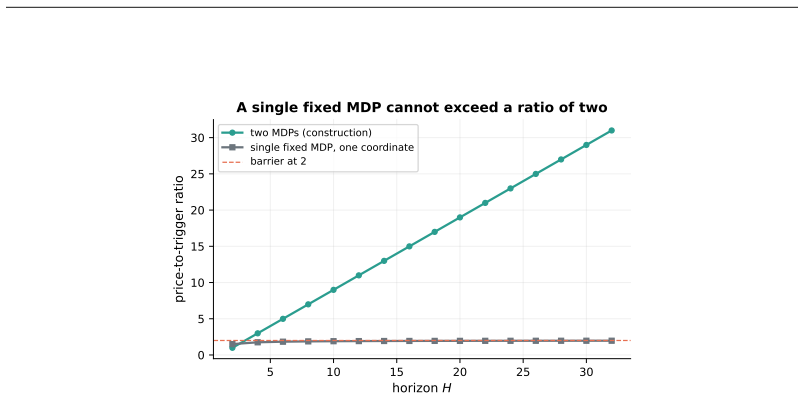
- Identical variation in one coordinate can produce horizon-scale differences in regret depending on whether the change crosses a cone boundary.
- Regret bounds can be expressed solely in terms of the priced length of the path through the fan rather than the total length of the loss path.
- Learners achieve low dynamic regret by tracking only the sequence of optimal faces rather than reacting to all loss changes.
Where Pith is reading between the lines
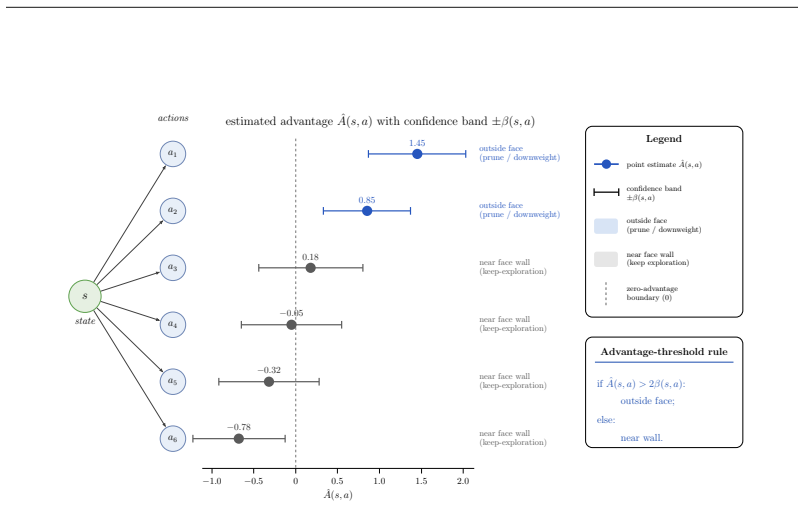
- Algorithms could be designed to monitor estimated face crossings and switch only when the crossing price exceeds a threshold.
- The same priced-motion decomposition may apply to other polyhedral decision problems where comparators lie on faces of a fixed feasible set.
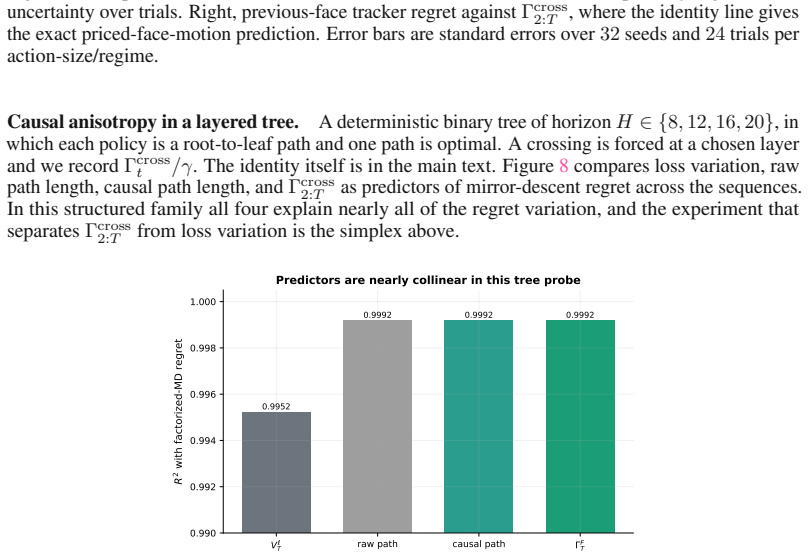
- In environments where face crossings are sparse, dynamic-regret bounds would scale with the number of crossings rather than total variation.
Load-bearing premise
Transitions stay fixed, so the set of occupancy measures remains the same polytope and every loss vector exposes a well-defined optimal face.
What would settle it
A concrete finite-horizon MDP, loss sequence, and face-tracking learner for which the observed dynamic regret differs from the sum of face-crossing prices plus within-face error by more than a vanishing additive term.
Figures
read the original abstract
In a changing decision problem, standard dynamic-regret analyses have often equated the cost of non-stationarity to how far loss moves. However, it is simultaneously possible for a loss sequence to travel far and retain the same optimal policy, or for a small movement in loss to force the optimal policy to change completely. Thus, the size of the movement through loss variation, transition variation, or comparator path length describe the adversary's motion, but not the cost of that motion to the control problem. For a more faithful analytic interpretation, this paper develops a normal-fan geometry for finite-horizon adversarial MDPs with fixed transitions. Occupancy measures form a polytope, and each loss vector exposes an optimal face of that polytope. Non-stationarity in rewards is therefore a path through the normal fan, where motion inside one cone leaves the optimal face unchanged, while crossing a wall may carry regret. We pose the notion of a face-crossing price, which is the minimum regret incurred by remaining on the previous optimal face under the new loss. For any learner that tracks the previous face, dynamic regret decomposes exactly into intrinsic priced face motion plus within-face selection error. The resulting theory separates consequential from harmless non-stationarity, where loss variation can be arbitrarily large at zero price, and identical one-coordinate variation can hide horizon-scale differences in regret.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a normal-fan geometry for finite-horizon adversarial MDPs with fixed transitions, where occupancy measures form a polytope and loss vectors expose optimal faces. It defines face-crossing price as the minimum regret incurred by remaining on the previous optimal face under a new loss, and claims that for any learner tracking the previous face, dynamic regret decomposes exactly into intrinsic priced face motion plus within-face selection error. This separates consequential non-stationarity (face crossings) from harmless loss variation (motion inside a cone).
Significance. If the decomposition holds, the work supplies a geometrically precise accounting of non-stationarity cost that can be zero despite arbitrarily large loss changes when the optimal face is unchanged. The exact, definitionally grounded decomposition and the static-polytope assumption under fixed transitions are explicit strengths that enable falsifiable distinctions between motion types.
minor comments (2)
- [Abstract] Abstract, paragraph 3: the decomposition is stated without a forward reference to the theorem or proposition that establishes it; adding such a pointer would improve readability.
- The definition of face-crossing price (minimum regret of staying on the old face) is introduced without an accompanying small numerical example illustrating a zero-price versus positive-price crossing; a one-paragraph illustration in §2 or §3 would clarify the normal-fan geometry.
Simulated Author's Rebuttal
We thank the referee for the careful reading, accurate summary of the normal-fan geometry and priced face-crossing decomposition, and for the positive significance assessment. The recommendation of minor revision is noted; no specific major comments were raised in the report.
Circularity Check
Decomposition reduces to definition of face-crossing price
specific steps
-
self definitional
[Abstract]
"We pose the notion of a face-crossing price, which is the minimum regret incurred by remaining on the previous optimal face under the new loss. For any learner that tracks the previous face, dynamic regret decomposes exactly into intrinsic priced face motion plus within-face selection error."
The priced motion term is defined precisely as the regret incurred by staying on the old face; the claimed exact decomposition for face-tracking learners is therefore an immediate restatement of that definition rather than a derived equality that could be independently verified or falsified.
full rationale
The paper introduces a face-crossing price as the minimum regret of remaining on the prior optimal face, then states that dynamic regret decomposes exactly into priced face motion plus within-face error for learners that track the prior face. This equality holds by construction once the price is defined that way; no independent derivation or external benchmark is required for the equality to hold. The geometry of the normal fan and fixed-transition polytope provide context but do not alter the definitional character of the split. No other load-bearing steps exhibit circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Occupancy measures form a polytope for finite-horizon MDPs with fixed transitions
invented entities (1)
-
face-crossing price
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alekh Agarwal, Sham M. Kakade, Jason D. Lee, and Gaurav Mahajan. On the theory of policy gradient methods: Optimality, approximation, and distribution shift. (arXiv:1908.00261),
-
[2]
doi: 10.48550/arXiv.1908.00261. URLhttp://arxiv.org/abs/1908.00261. Carlo Alfano, Rui Yuan, and Patrick Rebeschini. A novel framework for policy mirror descent with general parameterization and linear convergence. (arXiv:2301.13139),
-
[4]
Routledge. doi: 10.1201/9781315140223. URL https://www.taylorfrancis.com/ books/9781315140223. Amir Beck and Marc Teboulle. Mirror descent and nonlinear projected subgradient methods for convex optimization.Operations Research Letters, 31(3):167–175,
-
[5]
doi: 10.1287/opre.2015.1408. URL http://arxiv.org/abs/1307
-
[6]
URL https: //epubs.siam.org/doi/10.1137/0331063
doi: 10.1137/0331063. URL https: //epubs.siam.org/doi/10.1137/0331063. Adrian Rivera Cardoso, He Wang, and Huan Xu. Large scale markov decision processes with changing rewards,
-
[7]
Large Scale Markov Decision Processes with Changing Rewards
URLhttps://arxiv.org/abs/1905.10649v1. Nicol`o Cesa-Bianchi and G ´abor Lugosi.Prediction, Learning, and Games
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[8]
URL https://arxiv. org/abs/2006.14389v1. Robert Dadashi, Adrien Ali Ta¨ıga, Nicolas Le Roux, Dale Schuurmans, and Marc G. Bellemare. The value function polytope in reinforcement learning. (arXiv:1901.11524),
-
[10]
doi: 10.14288/1.0044649. Nima Eshraghi and Ben Liang. Dynamic regret of online mirror descent for relatively smooth convex cost functions. (arXiv:2202.12843),
-
[11]
URL http://arxiv.org/abs/2202.12843
doi: 10.48550/arXiv.2202.12843. URL http://arxiv.org/abs/2202.12843. Eyal Even-Dar, Sham. M. Kakade, and Yishay Mansour. Online markov decision processes.Math- ematics of Operations Research, 34(3):726–736,
-
[12]
Yingjie Fei, Zhuoran Yang, Zhaoran Wang, and Qiaomin Xie
URL https://www.jstor.org/ stable/40538442. Yingjie Fei, Zhuoran Yang, Zhaoran Wang, and Qiaomin Xie. Dynamic regret of policy optimization in non-stationary environments. (arXiv:2007.00148),
-
[13]
URLhttp://arxiv.org/abs/2007.00148
doi: 10.48550/arXiv.2007.00148. URLhttp://arxiv.org/abs/2007.00148. Eric C. Hall and Rebecca M. Willett. Dynamical models and tracking regret in online convex programming,
-
[14]
Dynamical Models and Tracking Regret in Online Convex Programming
URLhttps://arxiv.org/abs/1301.1254v1. 10 Wasim Huleihel, Soumyabrata Pal, and Ofer Shayevitz. Learning user preferences in non-stationary environments. (arXiv:2101.12506),
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
URL http:// arxiv.org/abs/2101.12506
doi: 10.48550/arXiv.2101.12506. URL http:// arxiv.org/abs/2101.12506. Ali Jadbabaie, Alexander Rakhlin, Shahin Shahrampour, and Karthik Sridharan. Online optimization: Competing with dynamic comparators. (arXiv:1501.06225),
-
[16]
doi: 10.48550/arXiv.1501. 06225. URLhttp://arxiv.org/abs/1501.06225. Chi Jin, Tiancheng Jin, Haipeng Luo, Suvrit Sra, and Tiancheng Yu. Learning adversarial mdps with bandit feedback and unknown transition,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1501
-
[17]
URL https://arxiv.org/abs/1912. 01192v5. S. Kakade and J. Langford. Approximately optimal approximate reinforcement learning
1912
- [18]
-
[19]
URL http: //arxiv.org/abs/2507.08718
doi: 10.48550/arXiv.2507.08718. URL http: //arxiv.org/abs/2507.08718. Guanghui Lan. Policy mirror descent for reinforcement learning: Linear convergence, new sampling complexity, and generalized problem classes. (arXiv:2102.00135),
-
[20]
arXiv (2023) https://doi.org/10.48550/arXiv
doi: 10.48550/arXiv. 2102.00135. URLhttp://arxiv.org/abs/2102.00135. Long-Fei Li, Peng Zhao, and Zhi-Hua Zhou. Dynamic regret of adversarial linear mixture mdps. Advances in Neural Information Processing Systems 36, pp. 60685–60711,
work page internal anchor Pith review doi:10.48550/arxiv
-
[21]
doi: 10.52202/ 075280-2650. URL https://papers.nips.cc/paper_files/paper/2023/file/ becd02b89259774da2ede23116a80648-Paper-Conference.pdf. Long-Fei Li, Peng Zhao, and Zhi-Hua Zhou. Near-optimal dynamic regret for adversarial linear mixture mdps, 2024a. URLhttps://arxiv.org/abs/2411.03107v1. Long-Fei Li, Peng Zhao, and Zhi-Hua Zhou. Improved algorithm for ...
-
[22]
URL https://doi.org/10.1007/ s11228-008-0077-9
doi: 10.1007/s11228-008-0077-9. URL https://doi.org/10.1007/ s11228-008-0077-9. Weichao Mao, Kaiqing Zhang, Ruihao Zhu, David Simchi-Levi, and Tamer Ba s ¸ar. Model-free non-stationary rl: Near-optimal regret and applications in multi-agent rl and inventory control. (arXiv:2010.03161),
-
[23]
URL http://arxiv.org/abs/ 2010.03161
doi: 10.48550/arXiv.2010.03161. URL http://arxiv.org/abs/ 2010.03161. Nikola Milosevic and Nico Scherf. The geometry of nonlinear reinforcement learning. (arXiv:2509.01432),
-
[24]
URL http://arxiv.org/ abs/2509.01432
doi: 10.48550/arXiv.2509.01432. URL http://arxiv.org/ abs/2509.01432. Johannes M¨uller and Guido Mont´ufar. Geometry and convergence of natural policy gradient methods. Information Geometry, 7(S1):485–523,
-
[25]
URL http: //arxiv.org/abs/2211.02105
doi: 10.1007/s41884-023-00106-z. URL http: //arxiv.org/abs/2211.02105. Arkadi˘ı Semenovich Nemirovski˘ı and David Berkovich IUdin.Problem Complexity and Method Efficiency in Optimization. Wiley,
-
[26]
Andreas Paffenholz
URL https://papers.nips.cc/paper_files/paper/2010/ hash/7bb060764a818184ebb1cc0d43d382aa-Abstract.html. Andreas Paffenholz. Polyhedral geometry and linear optimization
2010
-
[27]
Online Learning with Predictable Sequences
Alexander Rakhlin and Karthik Sridharan. Online learning with predictable sequences. (arXiv:1208.3728),
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Online Learning with Predictable Sequences
doi: 10.48550/arXiv.1208.3728. URL http://arxiv.org/abs/ 1208.3728. R. Tyrrell Rockafellar.Convex Analysis. Princeton University Press,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1208.3728
-
[29]
URLhttps://arxiv.org/abs/1905.07773v1. J. Ben Schafer, Joseph Konstan, and John Riedl. Recommender systems in e-commerce. In Proceedings of the 1st ACM conference on Electronic commerce, EC ’99, pp. 158–166, New York, NY , USA,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[30]
Association for Computing Machinery. doi: 10.1145/336992.337035. URL https://dl.acm.org/doi/10.1145/336992.337035. Andreas Schlaginhaufen and Maryam Kamgarpour. Identifiability and generalizability in constrained inverse reinforcement learning. (arXiv:2306.00629),
-
[31]
URL http://arxiv.org/abs/2306.00629
doi: 10.48550/arXiv.2306.00629. URL http://arxiv.org/abs/2306.00629. John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. Trust region policy optimization. (arXiv:1502.05477),
-
[32]
Trust Region Policy Optimization
doi: 10.48550/arXiv.1502.05477. URL http: //arxiv.org/abs/1502.05477. Guy Shani, Ronen I. Brafman, and David Heckerman. An mdp-based recommender system. (arXiv:1301.0600),
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1502.05477
-
[33]
An MDP-based Recommender System
doi: 10.48550/arXiv.1301.0600. URL http://arxiv.org/abs/ 1301.0600. Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1301.0600
-
[34]
Mirror descent policy optimization
Manan Tomar, Lior Shani, Yonathan Efroni, and Mohammad Ghavamzadeh. Mirror descent policy optimization. (arXiv:2005.09814),
-
[35]
Mirror descent policy optimization
doi: 10.48550/arXiv.2005.09814. URL http:// arxiv.org/abs/2005.09814. Joel A. Tropp. Acm 204: Lectures on convex geometry
-
[36]
URL https://resolver.caltech.edu/CaltechAUTHORS:20220412-220319430
doi: 10.7907/GEDA-H205. URL https://resolver.caltech.edu/CaltechAUTHORS:20220412-220319430. Chen-Yu Wei and Haipeng Luo. Non-stationary reinforcement learning without prior knowledge: An optimal black-box approach. (arXiv:2102.05406),
-
[37]
URL http://arxiv.org/abs/2102.05406
doi: 10.48550/arXiv.2102.05406. URL http://arxiv.org/abs/2102.05406. Wenhao Zhan, Shicong Cen, Baihe Huang, Yuxin Chen, Jason D. Lee, and Yuejie Chi. Policy mirror descent for regularized reinforcement learning: A generalized framework with linear convergence. (arXiv:2105.11066),
-
[38]
URL http://arxiv.org/abs/ 2105.11066
doi: 10.48550/arXiv.2105.11066. URL http://arxiv.org/abs/ 2105.11066. Peng Zhao, Yu-Jie Zhang, Lijun Zhang, and Zhi-Hua Zhou. Dynamic regret of convex and smooth functions. (arXiv:2007.03479),
-
[39]
doi: 10.48550/arXiv.2007.03479. URL http://arxiv. org/abs/2007.03479. Peng Zhao, Long-Fei Li, and Zhi-Hua Zhou. Dynamic regret of online markov decision processes,
-
[40]
Peng Zhao, Yu-Jie Zhang, Lijun Zhang, and Zhi-Hua Zhou
URLhttps://arxiv.org/abs/2208.12483v1. Peng Zhao, Yu-Jie Zhang, Lijun Zhang, and Zhi-Hua Zhou. Adaptivity and non-stationarity: Problem- dependent dynamic regret for online convex optimization. (arXiv:2112.14368),
-
[41]
URLhttp://arxiv.org/abs/2112.14368
48550/arXiv.2112.14368. URLhttp://arxiv.org/abs/2112.14368. 12 G¨unter M. Ziegler.Lectures on Polytopes, volume 152 ofGraduate Texts in Mathematics. Springer, New York, NY ,
-
[42]
doi: 10.1007/978-1-4613-8431-1. URL http://link.springer. com/10.1007/978-1-4613-8431-1. Alexander Zimin and Gergely Neu. Online learning in episodic markovian decision processes by relative entropy policy search. InAdvances in Neural Information Processing Systems, volume
-
[43]
Martin Zinkevich
URL https://papers.neurips.cc/paper_files/ paper/2013/hash/68053af2923e00204c3ca7c6a3150cf7-Abstract.html. Martin Zinkevich. Online convex programming and generalized infinitesimal gradient ascent
2013
-
[44]
Proposition 2(Predictive selection).Let mt be a prediction of ℓt and choose xt ∈ arg minu∈Ft−1 ⟨u, mt⟩
A PROOFS FROM THE MAIN TEXT A.1 WITHIN-FACE SELECTION When the previous optimal face Ft−1 is higher-dimensional, the learner chooses one occupancy inside it, and that choice is the source of the selection errorε sel t . Proposition 2(Predictive selection).Let mt be a prediction of ℓt and choose xt ∈ arg minu∈Ft−1 ⟨u, mt⟩. Ifδ t =∥m t −ℓ t∥∗, thenε sel t ≤...
1983
-
[45]
Table 1: Hyperparameters
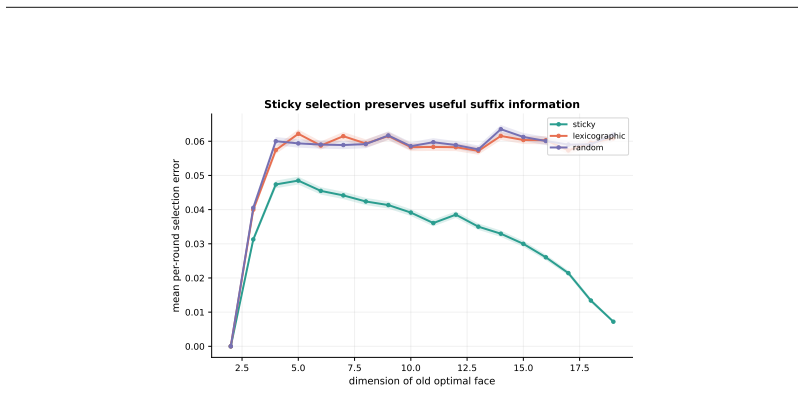
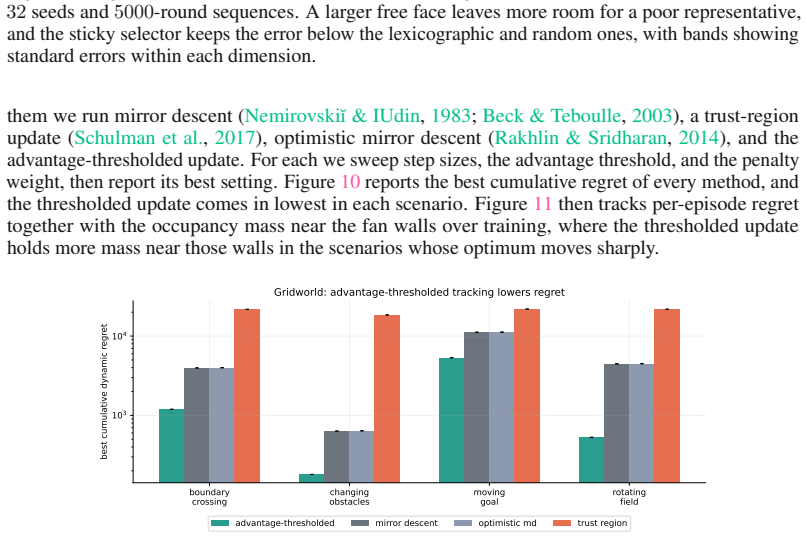
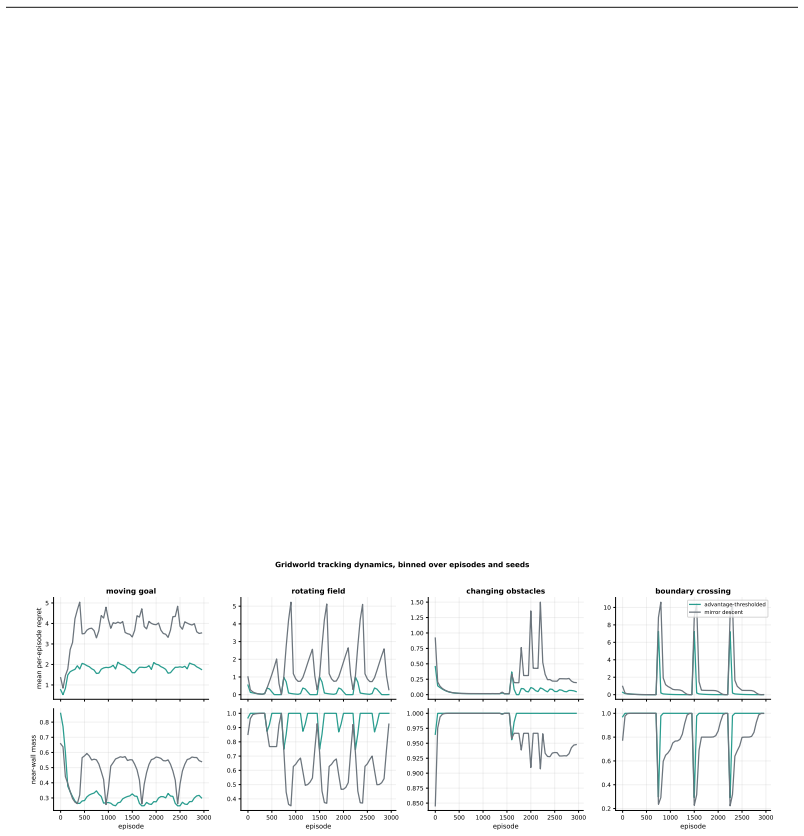
The per-step loss unit in the priced quantities isγ. Table 1: Hyperparameters. Step sizes η and the method-specific parameters are swept over the ranges shown, and every benchmark uses32seeds. Benchmark Settings SimplexK∈ {16,32,64,128} actions, horizon T=5000 , γ=0.25, η∈ {0.04,0.08,0.15,0.3,0.6,1.0},24trials per regime, four regimes Layered treeH∈ {8,12...
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.