Each Judge Its Own Yardstick: Discovering Per-VLM Taxonomies for Physical Video Evaluation
Pith reviewed 2026-06-26 09:01 UTC · model grok-4.3
The pith
Each vision-language model performs better as a video judge when given its own custom taxonomy of physical errors instead of a shared global one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
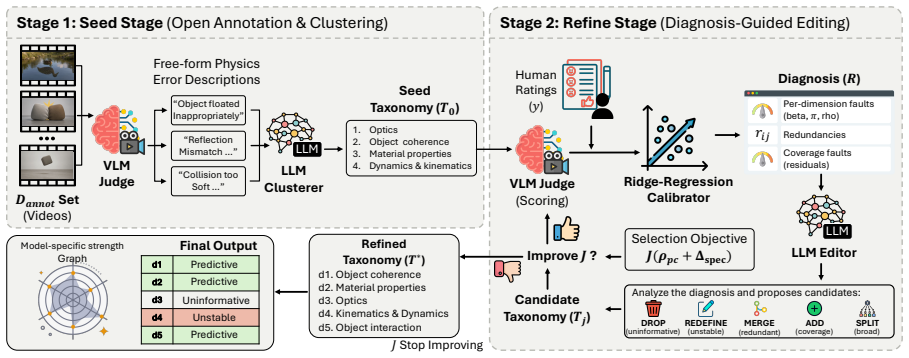
The paper claims that an iterative procedure can discover a per-VLM evaluation taxonomy for physical video evaluation that outperforms any fixed global schema. Starting from the target VLM's own error descriptions on a small video set, dimensions are clustered and then refined by diagnosing performance against human physical-commonsense ratings and prompting repairs. When applied to models from eight families the resulting taxonomies deliver a mean 32 percent relative improvement on held-out videos and reveal model-specific reliability patterns that global rankings obscure.
What carries the argument
JudgeFit, the iterative refinement procedure that constructs and repairs per-VLM taxonomies by combining self-prompted error enumeration with human calibration diagnostics.
If this is right
- Automated judges can provide more accurate reward signals for training video generators and world models.
- Selection of VLMs for evaluation tasks can be guided by their specific reliability profiles rather than overall rankings.
- Data filtering for training sets can avoid model-specific failure modes in physical perception.
- Benchmarks can expose distinct blind spots across model families that aggregate scores hide.
Where Pith is reading between the lines
- The method could be tested on whether the discovered taxonomies can be used to fine-tune the VLMs themselves toward better physical understanding.
- Similar adaptive taxonomies might improve evaluation in other modalities such as generated audio or 3D scenes if human ground truth can be collected.
- The per-VLM profiles suggest that future comparisons of VLMs should report dimension-level reliability rather than single aggregate scores.
Load-bearing premise
Human physical-commonsense ratings constitute an unbiased external ground truth against which VLM dimension scores can be calibrated without the calibration step itself introducing new biases.
What would settle it
Collecting fresh human ratings on held-out videos with different prompts or raters and finding that the refined per-VLM taxonomy no longer outperforms the global schema by the reported margin would falsify the central claim.
Figures

read the original abstract
Maintaining physical consistency in video generators and world models increasingly relies on vision-language models (VLMs) as automated judges that provide reward signals, ranking decisions, and data-filtering criteria. Yet VLMs differ substantially in training data and architecture, encoding physical phenomena through distinct internal representations. A single global evaluation schema therefore gives every VLM the same axes of competence, regardless of what each can actually perceive. We propose JudgeFit, an iterative refinement procedure that discovers a per-VLM evaluation taxonomy. An initial taxonomy is constructed by prompting the target VLM to enumerate physics errors on a small set of videos and clustering the resulting descriptions. The taxonomy is then refined through a diagnostic step: we calibrate the VLM's per-dimension scores to human physical-commonsense ratings, diagnose which dimensions it scores unreliably or redundantly, and prompt an LLM to repair them, iterating until convergence. We further instantiate this procedure as a benchmark and apply it to 16 VLMs spanning eight model families. The refined taxonomy outperforms the global-schema baseline on held-out videos for every VLM tested, with a mean relative improvement of approximately 32%. Beyond aggregate accuracy, the per-VLM profiles expose model-specific blind spots that overall rankings cannot anticipate, with reliability patterns differing markedly across model families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes JudgeFit, an iterative procedure to discover per-VLM taxonomies for physical video evaluation. An initial taxonomy is generated by prompting the target VLM on a small video set and clustering descriptions; the taxonomy is then refined by calibrating VLM per-dimension scores to human physical-commonsense ratings, diagnosing unreliable or redundant dimensions from residuals, and prompting an LLM to repair them until convergence. Applied to 16 VLMs across eight families, the refined per-VLM taxonomies outperform a global-schema baseline on held-out videos with a mean relative improvement of ~32%, while also exposing model-specific blind spots.
Significance. If the central numerical claim survives scrutiny on statistical details and evaluation symmetry, the work is significant for automated evaluation of video generators and world models. It demonstrates that tailored, per-VLM axes can yield more reliable reward signals and data filters than a single global schema, and the multi-family evaluation provides evidence that reliability patterns vary systematically by architecture and training data.
major comments (3)
- [Abstract] Abstract: The abstract states a 32% mean relative improvement on held-out videos but supplies no information on dataset size, statistical significance, variance across models, how held-out videos were chosen, or whether the improvement survives multiple-testing correction. Without these details the central numerical claim cannot be assessed.
- [Abstract / §3] Abstract / §3 (procedure): Calibration of VLM scores to human ratings occurs inside the taxonomy-refinement loop, and the same ratings implicitly serve as the evaluation target on held-out videos. The global-schema baseline receives no equivalent calibration step, so the reported outperformance may reflect asymmetric fitting to rater-specific biases rather than discovery of independent per-VLM axes.
- [§4] §4 (experiments): The paper does not report whether the 32% lift is robust when human ratings are collected under a different prompt template or from an independent rater pool, which is required to isolate genuine gain from circular dependence on the calibration signal.
minor comments (2)
- [§2] §2: The clustering step for the initial taxonomy would benefit from an explicit description of the distance metric and linkage method used.
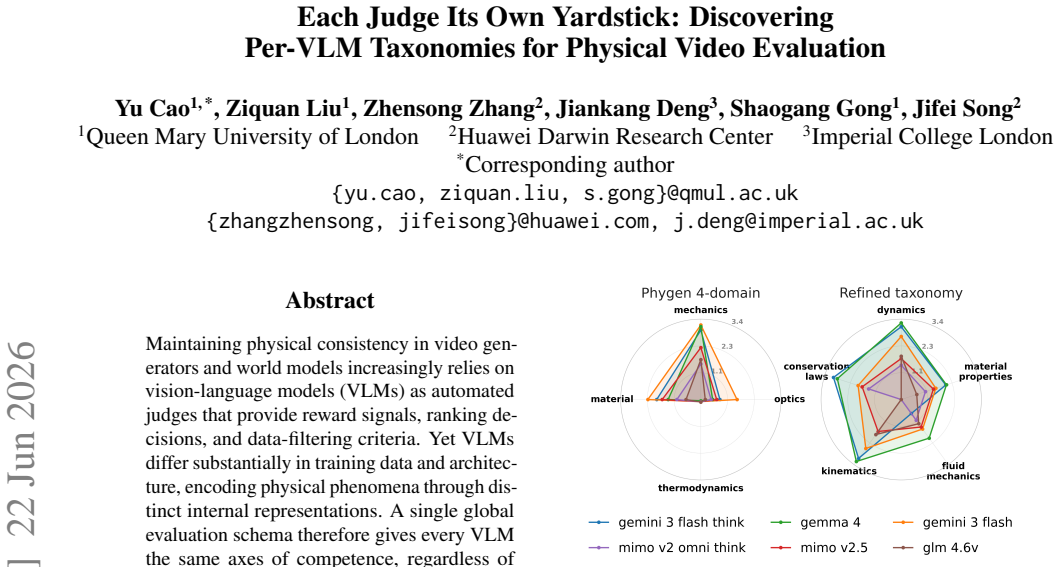
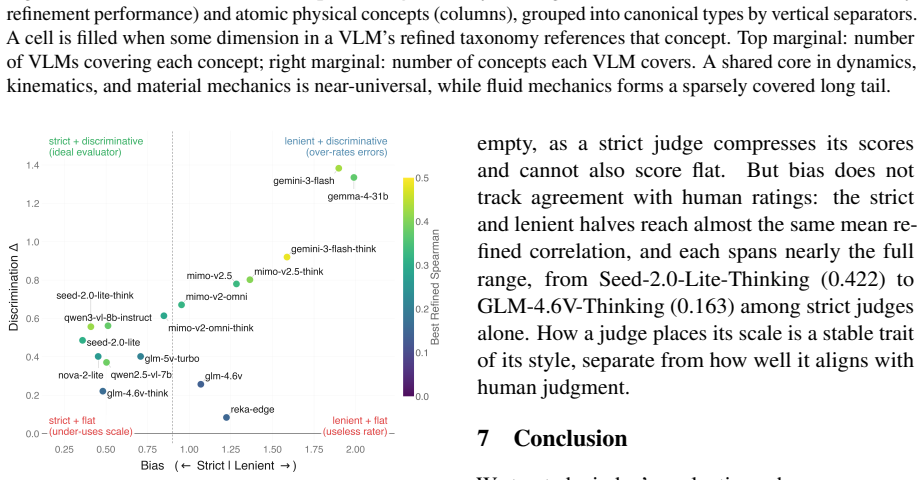
- [Figure 3] Figure 3: Axis labels and legend entries are too small to read at standard print size; consider enlarging or splitting into multiple panels.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below with clarifications on the reported results and evaluation protocol, and indicate revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states a 32% mean relative improvement on held-out videos but supplies no information on dataset size, statistical significance, variance across models, how held-out videos were chosen, or whether the improvement survives multiple-testing correction. Without these details the central numerical claim cannot be assessed.
Authors: The abstract is intentionally concise. Full details on dataset size, the held-out selection procedure (disjoint split from the calibration videos), variance across the 16 models, and statistical testing (including any corrections) appear in §4. We will revise the abstract to include the evaluation scale and a reference to the statistical analysis performed. revision: yes
-
Referee: [Abstract / §3] Abstract / §3 (procedure): Calibration of VLM scores to human ratings occurs inside the taxonomy-refinement loop, and the same ratings implicitly serve as the evaluation target on held-out videos. The global-schema baseline receives no equivalent calibration step, so the reported outperformance may reflect asymmetric fitting to rater-specific biases rather than discovery of independent per-VLM axes.
Authors: The calibration step is the core diagnostic mechanism of JudgeFit: human ratings on a calibration subset are used only to identify unreliable or redundant dimensions via residuals and to prompt repairs to the taxonomy. Held-out videos are disjoint from the calibration set, and both the refined per-VLM taxonomy and the global-schema baseline are evaluated against the same human ratings on the held-out set. The asymmetry is by design—the global baseline represents the standard unrefined comparator. We will add explicit wording in §3 to state the disjoint split and the purpose of calibration. revision: partial
-
Referee: [§4] §4 (experiments): The paper does not report whether the 32% lift is robust when human ratings are collected under a different prompt template or from an independent rater pool, which is required to isolate genuine gain from circular dependence on the calibration signal.
Authors: We acknowledge that robustness to alternative rating protocols is not reported. The current results use one rater pool and template. We will add a limitations paragraph in the revised §4 noting this and framing it as an avenue for future validation, while observing that consistent gains across eight model families provide indirect support for the method's stability. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's procedure generates an initial taxonomy via VLM prompting on a small video set, refines it by calibrating per-dimension scores against external human physical-commonsense ratings, and evaluates the refined taxonomy on held-out videos using the same human ratings as benchmark. This constitutes a standard calibration-plus-held-out-test workflow against an independent external signal rather than a self-referential reduction. No equations, self-citations, uniqueness theorems, or ansatzes are quoted that would force the reported 32% relative improvement by construction from the inputs. The global-schema baseline comparison, while asymmetric, does not create a definitional loop within the claimed derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of taxonomy dimensions after refinement
axioms (2)
- domain assumption VLMs can produce enumerations of physics errors when prompted on video clips
- domain assumption Human physical-commonsense ratings provide an unbiased calibration target
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[2]
Advances in Neural Information Processing Systems , volume=
Alpacafarm: A simulation framework for methods that learn from human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Forty-first International Conference on Machine Learning , year=
Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark , author=. Forty-first International Conference on Machine Learning , year=
-
[4]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[5]
International Conference on Learning Representations , volume=
Vision-language models are zero-shot reward models for reinforcement learning , author=. International Conference on Learning Representations , volume=
-
[6]
arXiv preprint arXiv:2509.08826 , year=
Rewarddance: Reward scaling in visual generation , author=. arXiv preprint arXiv:2509.08826 , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Improving video generation with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Large language models are not fair evaluators , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[9]
Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (lrec-coling 2024) , pages=
Calibrating llm-based evaluator , author=. Proceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (lrec-coling 2024) , pages=
2024
-
[10]
International Conference on Learning Representations , volume=
Videophy: Evaluating physical commonsense for video generation , author=. International Conference on Learning Representations , volume=
-
[11]
arXiv preprint arXiv:2503.06800 , year=
Videophy-2: A challenging action-centric physical commonsense evaluation in video generation , author=. arXiv preprint arXiv:2503.06800 , year=
-
[12]
arXiv preprint arXiv:2410.05363 , year=
Towards world simulator: Crafting physical commonsense-based benchmark for video generation , author=. arXiv preprint arXiv:2410.05363 , year=
-
[13]
International Conference on Learning Representations , volume=
Physbench: Benchmarking and enhancing vision-language models for physical world understanding , author=. International Conference on Learning Representations , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Seephys: Does seeing help thinking?--benchmarking vision-based physics reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Do generative video models understand physical principles? , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[16]
International Conference on Learning Representations , volume=
Large language models as optimizers , author=. International Conference on Learning Representations , volume=
-
[17]
gradient descent
Automatic prompt optimization with “gradient descent” and beam search , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[18]
Nature , volume=
Optimizing generative ai by backpropagating language model feedback , author=. Nature , volume=. 2025 , publisher=
2025
-
[19]
arXiv preprint arXiv:2310.03714 , year=
Dspy: Compiling declarative language model calls into self-improving pipelines , author=. arXiv preprint arXiv:2310.03714 , year=
-
[20]
Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology , pages=
Who validates the validators? aligning llm-assisted evaluation of llm outputs with human preferences , author=. Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology , pages=
-
[21]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Llm-rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[22]
Findings of the Association for Computational Linguistics: EACL 2026 , pages=
Learning to judge: LLMs designing and applying evaluation rubrics , author=. Findings of the Association for Computational Linguistics: EACL 2026 , pages=
2026
-
[23]
OpenAI Blog , volume=
Video generation models as world simulators , author=. OpenAI Blog , volume=
-
[24]
International Conference on Learning Representations , volume=
Cogvideox: Text-to-video diffusion models with an expert transformer , author=. International Conference on Learning Representations , volume=
-
[25]
arXiv preprint arXiv:2503.20314 , year=
Wan: Open and advanced large-scale video generative models , author=. arXiv preprint arXiv:2503.20314 , year=
-
[26]
arXiv preprint arXiv:2501.03575 , year=
Cosmos world foundation model platform for physical ai , author=. arXiv preprint arXiv:2501.03575 , year=
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vbench: Comprehensive benchmark suite for video generative models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[28]
Advances in Neural Information Processing Systems , volume=
Imagereward: Learning and evaluating human preferences for text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
International Conference on Machine Learning , pages=
Scaling laws for reward model overoptimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[30]
Judging the judges: A systematic study of position bias in llm-as-a-judge , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[31]
arXiv preprint arXiv:2106.08261 , year=
Physion: Evaluating physical prediction from vision in humans and machines , author=. arXiv preprint arXiv:2106.08261 , year=
-
[32]
National Science Review , volume=
A survey on multimodal large language models , author=. National Science Review , volume=. 2024 , publisher=
2024
-
[33]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[34]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[35]
, author=
A constant error in psychological ratings. , author=. Journal of applied psychology , volume=. 1920 , publisher=
1920
-
[36]
2025 , publisher=
Item response theory: Foundations for psychologists and social scientists , author=. 2025 , publisher=
2025
-
[37]
Advances in Neural Information Processing Systems , volume=
Llm evaluators recognize and favor their own generations , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
arXiv preprint arXiv:2410.21819 , year=
Self-preference bias in llm-as-a-judge , author=. arXiv preprint arXiv:2410.21819 , year=
-
[39]
The Innovation , year=
A survey on llm-as-a-judge , author=. The Innovation , year=
-
[40]
arXiv preprint arXiv:2412.05579 , year=
Llms-as-judges: a comprehensive survey on llm-based evaluation methods , author=. arXiv preprint arXiv:2412.05579 , year=
-
[41]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[42]
arXiv preprint arXiv:2502.13923 , year=
-
[43]
2025 , url=
Bai, Shuai and others , journal=. 2025 , url=
2025
-
[44]
arXiv preprint arXiv:2404.12387 , year=
Reka core, flash, and edge: A series of powerful multimodal language models , author=. arXiv preprint arXiv:2404.12387 , year=
-
[45]
arXiv preprint arXiv:2507.01006 , year=
Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning , author=. arXiv preprint arXiv:2507.01006 , year=
-
[46]
arXiv preprint arXiv:2601.02780 , year=
Mimo-v2-flash technical report , author=. arXiv preprint arXiv:2601.02780 , year=
-
[47]
arXiv preprint arXiv:2604.26752 , year=
GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents , author=. arXiv preprint arXiv:2604.26752 , year=
-
[48]
arXiv preprint arXiv:2408.03326 , year=
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
-
[49]
arXiv preprint arXiv:2504.10479 , year=
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
-
[50]
2025 , institution=
Amazon Nova 2: Multimodal reasoning and generation models , author=. 2025 , institution=
2025
-
[51]
0 model card: Towards intelligence frontier for real-world complexity , author=
Seed2. 0 model card: Towards intelligence frontier for real-world complexity , author=. 2026 , institution=
2026
-
[52]
2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.