Learning to Deny: Action Denial in Multimodal Large Language Models
Pith reviewed 2026-07-01 06:19 UTC · model grok-4.3
The pith
Multimodal models that recognize actions above 85 percent accuracy drop below 50 percent when asked to deny those same actions in matched videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
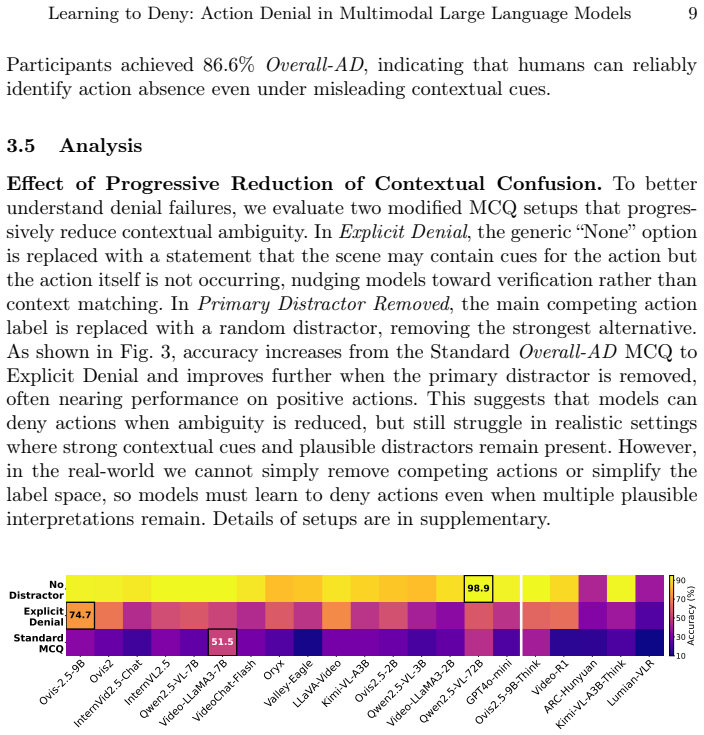
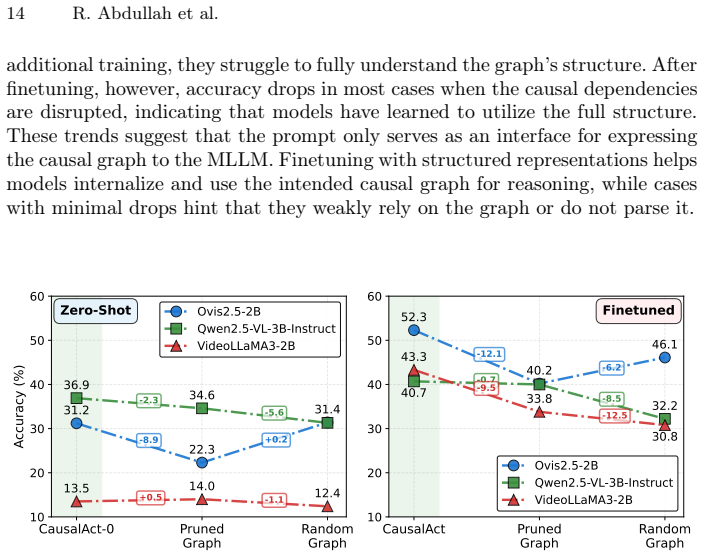
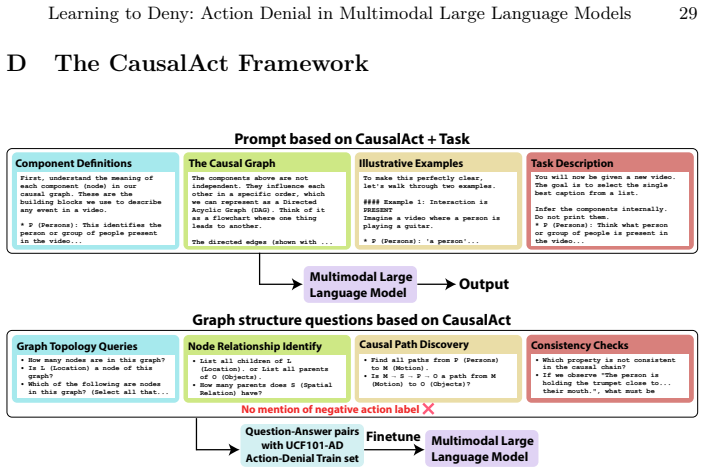
Evaluating twenty state-of-the-art MLLMs on UCF101-AD reveals that models exceeding 85 percent accuracy on positive action classes collapse below 50 percent on their action-denial counterparts; expressing scene structure through natural-language prompts that link context, interaction, and motion via the CausalAct formulation substantially reduces false positives, showing that denial is a learnable reasoning skill.
What carries the argument
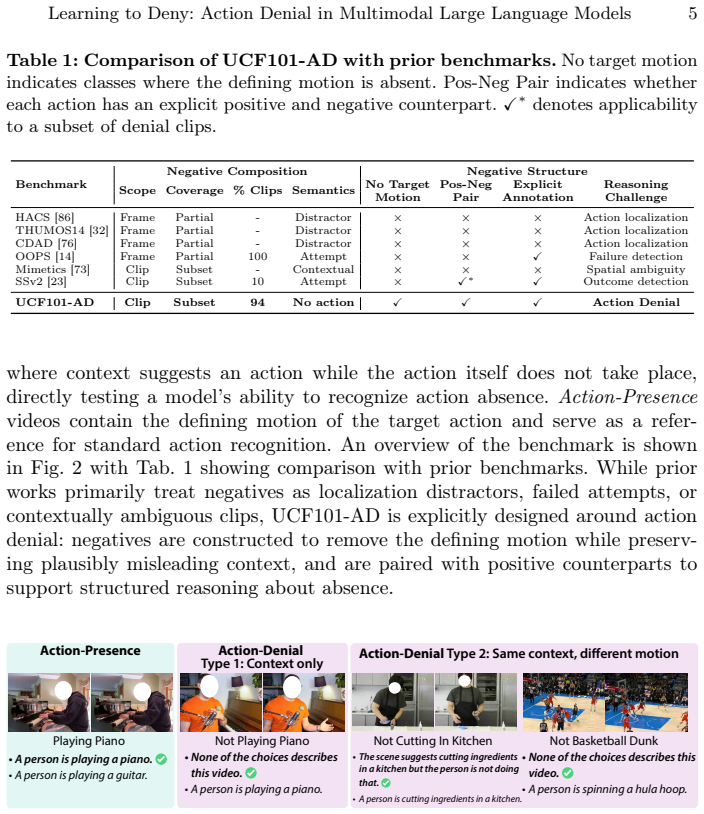
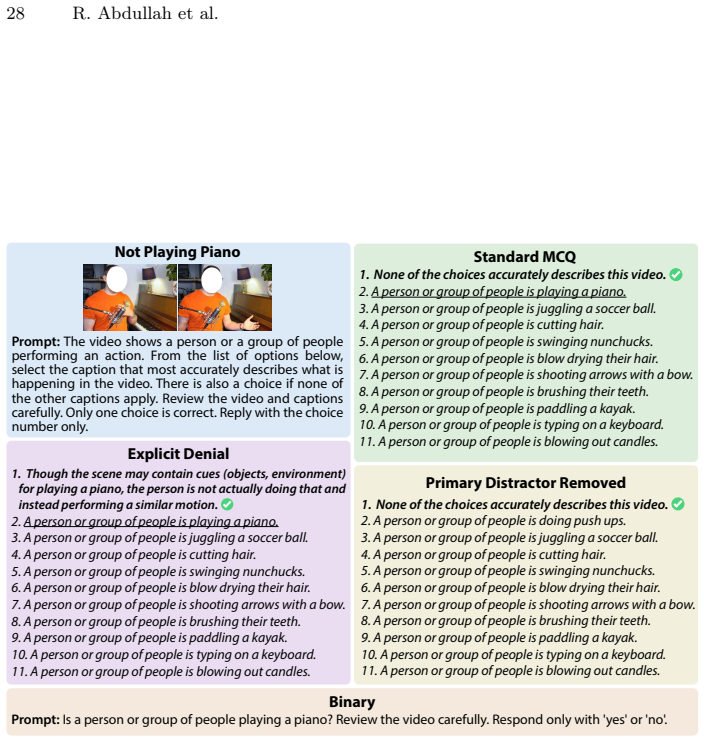
UCF101-AD benchmark of paired positive and negative video clips that preserve identical contextual and motion cues while making the target action explicitly absent, used to isolate denial performance from visual differences.
If this is right
- Standard action-recognition benchmarks overestimate model capability because they do not test denial of plausible but absent actions.
- Denial accuracy improves when models receive explicit natural-language prompts that connect context to interaction to motion.
- Video understanding systems require separate verification of motion occurrence rather than inference from surrounding cues alone.
- The gap between presence and denial performance is consistent across current MLLM architectures.
Where Pith is reading between the lines
- Applications such as automated surveillance or video search could produce systematic false alarms when models cannot reliably report that an expected action did not occur.
- Training regimes that only reward correct affirmation of actions may reinforce the observed bias against denial.
- The same paired-context design could be applied to other modalities or tasks to test whether causal verification failures are widespread.
Load-bearing premise
The negative videos keep the same persons, objects, and locations as the positive ones, differing only by the explicit absence of the target action.
What would settle it
Finding that negative videos contain systematic differences in low-level motion statistics or object trajectories that models could use to separate them from positive clips without causal reasoning.
Figures






read the original abstract
Multimodal large language models (MLLMs) have rapidly advanced video understanding, achieving strong zero-shot and few-shot recognition across standard benchmarks. Yet their ability to deny an action by recognizing when an activity is not happening despite strong contextual cues remains largely unexplored. We introduce UCF101-AD, a large-scale benchmark consisting of paired Action-Presence and Action-Denial clips, designed to evaluate this capacity for denial. Each negative video in UCF101-AD preserves the same contextual and motion cues, including persons, objects, and locations, as its positive counterpart, but the defining action itself is explicitly absent. Evaluating 20 state-of-the-art MLLMs reveals a consistent failure: models that exceed 85% accuracy on the positive action classes collapse below 50% on their action-denial counterparts, indicating a strong inclination to affirm plausible actions rather than verify that they truly occur. This exposes a critical blind spot in modern video understanding: the inability to reason causally about whether a motion actually happens. To probe this issue, we explore a causal graph formulation, CausalAct, which expresses scene structure through natural-language prompts linking context, interaction, and motion. Incorporating such causal cues substantially reduces false positives, demonstrating that denial is a learnable reasoning skill. UCF101-AD provides a new lens for diagnosing and improving causal reasoning in multimodal models. Dataset and relevant code: https://github.com/raiyaan-abdullah/Learn-to-Deny.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UCF101-AD, a benchmark of paired positive and negative action videos from UCF101 where each negative clip is claimed to preserve identical persons, objects, locations, and non-defining motion cues while making the target action explicitly absent. It reports that 20 state-of-the-art MLLMs achieve >85% accuracy on positive classes but collapse below 50% on the corresponding denial tasks, and proposes CausalAct, a natural-language causal-graph prompting method that reduces false positives by linking context, interaction, and motion.
Significance. If the negative-video construction truly isolates action absence, the work identifies a reproducible and previously unquantified limitation in current MLLMs' causal verification of video actions and shows that the limitation is at least partially addressable via explicit causal prompting. The new benchmark and the CausalAct formulation constitute a concrete, falsifiable contribution to the evaluation of multimodal reasoning.
major comments (1)
- [Abstract / UCF101-AD description] Abstract and UCF101-AD construction section: the central interpretive claim—that the observed 85%→<50% accuracy collapse demonstrates a failure of causal verification rather than ordinary distribution shift—rests on the assertion that negatives preserve identical contextual and motion cues while differing only in the explicit absence of the target action. No construction protocol, quantitative similarity metric (e.g., optical-flow or feature-space distance), or human validation study is supplied, so the performance gap cannot yet be attributed specifically to missing causal reasoning.
minor comments (1)
- The GitHub link for dataset and code is a positive reproducibility feature and should be retained.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need to strengthen the evidentiary basis for UCF101-AD. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / UCF101-AD description] Abstract and UCF101-AD construction section: the central interpretive claim—that the observed 85%→<50% accuracy collapse demonstrates a failure of causal verification rather than ordinary distribution shift—rests on the assertion that negatives preserve identical contextual and motion cues while differing only in the explicit absence of the target action. No construction protocol, quantitative similarity metric (e.g., optical-flow or feature-space distance), or human validation study is supplied, so the performance gap cannot yet be attributed specifically to missing causal reasoning.
Authors: We agree that the current manuscript does not supply sufficient detail on the negative-video construction process. In the revised version we will add an expanded Section 3 that (i) describes the exact protocol used to select and edit UCF101 clips so that persons, objects, locations and non-defining motion are matched while the target action is removed, (ii) reports quantitative similarity metrics (optical-flow L2 distance, CLIP feature cosine similarity, and scene-graph overlap) between each positive–negative pair, and (iii) presents the results of a human validation study (N=200 raters) confirming that contextual cues are preserved while the defining action is judged absent. These additions will allow readers to evaluate whether the observed accuracy drop is attributable to causal-verification failure rather than distribution shift. revision: yes
Circularity Check
No circularity: results derive from independent benchmark evaluation
full rationale
The paper introduces the UCF101-AD benchmark and reports empirical accuracies of 20 MLLMs on its positive and negative classes. No equations, parameter fits, predictions, or self-citations are invoked that would reduce the reported performance gap to the input data by construction. The central interpretation (affirmation bias vs. causal verification failure) rests on the stated properties of the new dataset rather than any self-definitional or fitted-input mechanism. This is a standard empirical study whose claims are falsifiable against the released dataset and do not collapse into their own inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
CausalAct
no independent evidence
Reference graph
Works this paper leans on
-
[1]
punching person: Motion transferability in videos
Abdullah, R., Claypoole, J., Cogswell, M., Divakaran, A., Rawat, Y.: Punching bag vs. punching person: Motion transferability in videos. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 11348– 11358 (October 2025)
2025
-
[2]
In: Proceedings of the IEEE/CVF International ConferenceonComputerVision(ICCV)Workshops.pp.1433–1442(October2025)
Abdullah, R., Rawat, Y.S., Vyas, S.: isafetybench: A video-language benchmark for safety in industrial environment. In: Proceedings of the IEEE/CVF International ConferenceonComputerVision(ICCV)Workshops.pp.1433–1442(October2025)
-
[3]
Transactions on Machine Learning Research (2025), https://openreview.net/forum?id=WvgoxpGpuU 16 R
Ahmad, S., Chanda, S., Rawat, Y.S.: T2l: Efficient zero-shot action recognition with temporal token learning. Transactions on Machine Learning Research (2025), https://openreview.net/forum?id=WvgoxpGpuU 16 R. Abdullah et al
2025
- [4]
-
[5]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
4724–4733 (2017),https://api.semanticscholar.org/CorpusID: 206596127
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the ki- neticsdataset.2017IEEEConferenceonComputerVisionandPatternRecognition (CVPR) pp. 4724–4733 (2017),https://api.semanticscholar.org/CorpusID: 206596127
2017
-
[7]
(eds.) Findings of the Association for Computational Linguis- tics: EMNLP 2024
Chen, S., Xu, M., Wang, K., Zeng, X., Zhao, R., Zhao, S., Lu, C.: CLEAR: Can language models really understand causal graphs? In: Al-Onaizan, Y., Bansal, M., Chen, Y.N. (eds.) Findings of the Association for Computational Linguis- tics: EMNLP 2024. pp. 6247–6265. Association for Computational Linguistics, Mi- ami, Florida, USA (Nov 2024).https://doi.org/1...
-
[8]
Advances in Neural Information Processing Systems37, 92554–92580 (2024)
Chen, T., Liu, H., He, T., Chen, Y., Ma, X., Zhong, C., Zhang, Y., Wang, Y., Lin, H., Lin, W., et al.: Mecd: Unlocking multi-event causal discovery in video reasoning. Advances in Neural Information Processing Systems37, 92554–92580 (2024)
2024
-
[9]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
In: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., Garnett, R
Choi, J., Gao, C., Messou, J.C.E., Huang, J.B.: Why can't i dance in the mall? learning to mitigate scene bias in action recognition. In: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., Garnett, R. (eds.) Ad- vances in Neural Information Processing Systems. vol. 32. Curran Associates, Inc. (2019),https://proceedings.neurips.cc/pape...
2019
-
[11]
Lawrence Erl- baum Associates, Hillsdale, NJ, 2nd edn
Cohen, J.: Statistical Power Analysis for the Behavioral Sciences. Lawrence Erl- baum Associates, Hillsdale, NJ, 2nd edn. (1988)
1988
-
[12]
In: Proceedings of the European Conference on Computer Vision (ECCV) (September 2018)
Damen, D., Doughty, H., Farinella, G.M., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., Price, W., Wray, M.: Scaling egocentric vision: The epic-kitchens dataset. In: Proceedings of the European Conference on Computer Vision (ECCV) (September 2018)
2018
-
[13]
In: Karlinsky, L., Michaeli, T., Nishino, K
Duan, H., Zhao, Y., Chen, K., Xiong, Y., Lin, D.: Mitigating representation bias in action recognition: Algorithms and benchmarks. In: Karlinsky, L., Michaeli, T., Nishino, K. (eds.) Computer Vision – ECCV 2022 Workshops. pp. 557–575. Springer Nature Switzerland, Cham (2023)
2022
-
[14]
Epstein, D., Chen, B., Vondrick, C.: Oops! predicting unintentional action in video. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 916–926 (2020).https://doi.org/10.1109/CVPR42600.2020.00100
-
[15]
In: 2019 IEEE Intelligent Transportation Systems Conference (ITSC)
Fang, J., Yan, D., Qiao, J., Xue, J., Wang, H., Li, S.: Dada-2000: Can driving accident be predicted by driver attentionƒanalyzed by a benchmark. In: 2019 IEEE Intelligent Transportation Systems Conference (ITSC). p. 4303–4309. IEEE Press (2019).https://doi.org/10.1109/ITSC.2019.8917218,https://doi.org/10. 1109/ITSC.2019.8917218
-
[16]
Fanous, A., Goldberg, J., Agarwal, A.A., Lin, J., Zhou, A., Daneshjou, R., Koyejo, S.: Syceval: Evaluating llm sycophancy. CoRRabs/2502.08177(Febru- Learning to Deny: Action Denial in Multimodal Large Language Models 17 ary 2025),http://dblp.uni-trier.de/db/journals/corr/corr2502.html#abs- 2502-08177
-
[17]
Video-R1: Reinforcing Video Reasoning in MLLMs
Feng, K., Gong, K., Li, B., Guo, Z., Wang, Y., Peng, T., Wang, B., Yue, X.: Video-r1: Reinforcing video reasoning in mllms. arXiv preprint arXiv:2503.21776 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
In: The Thirteenth International Conference on Learning Representations (2025)
Fioresi, J., Dave, I.R., Shah, M.: Albar: Adversarial learning approach to miti- gate biases in action recognition. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[19]
(eds.) Mul- tiMedia Modeling
Fukuzawa, T., Hara, K., Kataoka, H., Tamaki, T.: Can masking background and object reduce static bias for zero-shot action recognition? In: Ide, I., Kompatsiaris, I., Xu, C., Yanai, K., Chu, W.T., Nitta, N., Riegler, M., Yamasaki, T. (eds.) Mul- tiMedia Modeling. pp. 366–379. Springer Nature Singapore, Singapore (2025)
2025
-
[20]
arXiv preprint arXiv:2507.20939 (2025)
Ge, Y., Ge, Y., Li, C., Wang, T., Pu, J., Li, Y., Qiu, L., Ma, J., Duan, L., Zuo, X., et al.: Arc-hunyuan-video-7b: Structured video comprehension of real-world shorts. arXiv preprint arXiv:2507.20939 (2025)
-
[21]
In: 2018 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition Workshops (CVPRW)
Giancola, S., Amine, M., Dghaily, T., Ghanem, B.: SoccerNet: A Scalable Dataset for Action Spotting in Soccer Videos . In: 2018 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition Workshops (CVPRW). pp. 1792–179210. IEEE Computer Society, Los Alamitos, CA, USA (Jun 2018).https://doi.org/ 10.1109/CVPRW.2018.00223,https://doi.ieeecomputersociet...
-
[22]
Gorti, S.K., Vouitsis, N., Ma, J., Golestan, K., Volkovs, M., Garg, A., Yu, G.: X- pool:Cross-modallanguage-videoattentionfortext-videoretrieval.In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
2022
-
[23]
Goyal, R., Kahou, S.E., Michalski, V., Materzynska, J., Westphal, S., Kim, H., Haenel, V., Fruend, I., Yianilos, P., Mueller-Freitag, M., Hoppe, F., Thurau, C., Bax, I., Memisevic, R.: The “Something Something” Video Database for Learning and Evaluating Visual Common Sense . In: 2017 IEEE International Conference on Computer Vision (ICCV). pp. 5843–5851. ...
-
[24]
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Ham- burger, J., Jiang, H., Liu, M., Liu, X., Martin, M., Nagarajan, T., Radosavovic, I., Ramakrishnan, S.K., Ryan, F., Sharma, J., Wray, M., Xu, M., Xu, E.Z., Zhao, C., Bansal, S., Batra, D., Cartillier, V., Crane, S., Do, T., Doulaty, M., Era- palli, A., Feichtenhofer, C., Frago...
-
[25]
Gu, C., Sun, C., Ross, D.A., Vondrick, C., Pantofaru, C., Li, Y., Vijayanarasimhan, S., Toderici, G., Ricco, S., Sukthankar, R., Schmid, C., Malik, J.: Ava: A video dataset of spatio-temporally localized atomic visual actions. In: 2018 IEEE/CVF 18 R. Abdullah et al. Conference on Computer Vision and Pattern Recognition. pp. 6047–6056 (2018). https://doi.o...
-
[26]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., Zhang, X., Yu, X., Wu, Y., Wu, Z.F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B., Feng, B., Lu, C., Zhao, C., Deng, C., Ruan, C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Luo, F., Hao, G., Chen, G., Li, G., Zhang, H., Xu, H....
-
[27]
In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Heilbron, F.C., Escorcia, V., Ghanem, B., Niebles, J.C.: Activitynet: A large-scale video benchmark for human activity understanding. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 961–970 (2015).https: //doi.org/10.1109/CVPR.2015.7298698
-
[28]
In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, D.A., Ramanathan, V., Mahajan, D., Torresani, L., Paluri, M., Fei-Fei, L., Niebles, J.C.: What makes a video a video: Analyzing temporal information in video understanding models and datasets. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7366–7375 (2018).https://doi. org/10.1109/CVPR.2018.00769
-
[29]
In: The Twelfth International Con- ference on Learning Representations (2024),https://openreview.net/forum?id= zYXFMeHRtO
Huang, X., Zhou, H., Yao, K., Han, K.: FROSTER: Frozen CLIP is a strong teacher for open-vocabulary action recognition. In: The Twelfth International Con- ference on Learning Representations (2024),https://openreview.net/forum?id= zYXFMeHRtO
2024
-
[30]
Jain, S., Ahmed, U.Z., Sahai, S., Leong, B.: Beyond consensus: Mitigating the agreeableness bias in llm judge evaluations (2025),https://arxiv.org/abs/2510. 11822
2025
-
[31]
Ji, J., Krishna, R., Fei-Fei, L., Niebles, J.C.: Action genome: Actions as com- positions of spatio-temporal scene graphs. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10233–10244 (2020). https://doi.org/10.1109/CVPR42600.2020.01025
-
[32]
http://crcv.ucf.edu/THUMOS14/(2014)
Jiang, Y.G., Liu, J., Roshan Zamir, A., Toderici, G., Laptev, I., Shah, M., Suk- thankar,R.:THUMOSchallenge:Actionrecognitionwithalargenumberofclasses. http://crcv.ucf.edu/THUMOS14/(2014)
2014
-
[33]
In: Thirty-seventh Conference on Neural Information Processing Systems (2023),https://openreview.net/forum? id=e2wtjx0Yqu
Jin, Z., Chen, Y., Leeb, F., Gresele, L., Kamal, O., LYU, Z., Blin, K., Adauto, F.G., Kleiman-Weiner, M., Sachan, M., Schölkopf, B.: CLadder: A benchmark to assess causal reasoning capabilities of language models. In: Thirty-seventh Conference on Neural Information Processing Systems (2023),https://openreview.net/forum? id=e2wtjx0Yqu
2023
-
[34]
In: 2014 IEEE Conference on Computer Vision and Pattern Recognition
Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., Fei-Fei, L.: Large-scale video classification with convolutional neural networks. In: 2014 IEEE Conference on Computer Vision and Pattern Recognition. pp. 1725–1732 (2014). https://doi.org/10.1109/CVPR.2014.223
-
[35]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Koupaee, M., Bai, X., Chen, M., Durrett, G., Chambers, N., Balasubramanian, N.: Causal graph based event reasoning using semantic relation experts. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Learning to Deny: Action Denial in Multimodal Lar...
-
[36]
2011 International Conference on Computer Vision pp
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T.A., Serre, T.: Hmdb: A large video database for human motion recognition. 2011 International Conference on Computer Vision pp. 2556–2563 (2011),https://api.semanticscholar.org/ CorpusID:206769852
2011
-
[37]
ArXivabs/2005.00214 (2020),https://api.semanticscholar.org/CorpusID:218470050
Li, A., Thotakuri, M., Ross, D.A., Carreira, J., Vostrikov, A., Zisserman, A.: The ava-kinetics localized human actions video dataset. ArXivabs/2005.00214 (2020),https://api.semanticscholar.org/CorpusID:218470050
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, B., Ge, Y., Ge, Y., Wang, G., Wang, R., Zhang, R., Shan, Y.: Seed- bench: Benchmarking multimodal large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13299–13308 (June 2024)
2024
-
[39]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Lou, P., Wang, L., Qiao, Y.: Mvbench: A comprehensive multi-modal video understanding benchmark. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 22195–22206 (2024).https://doi.org/10. 1109/CVPR52733.2024.02095
-
[40]
Li, T., Foo, L.G., Ke, Q., Rahmani, H., Wang, A., Wang, J., Liu, J.: Dy- namic spatio-temporal specialization learning for fine-grained action recognition. In: Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Is- rael, October 23–27, 2022, Proceedings, Part IV. p. 386–403. Springer-Verlag, Berlin, Heidelberg (2022).https://doi.org/10.1007/...
-
[41]
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Li, X., Wang, Y., Yu, J., Zeng, X., Zhu, Y., Huang, H., Gao, J., Li, K., He, Y., Wang, C., Qiao, Y., Wang, Y., Wang, L.: Videochat-flash: Hierarchical compression for long-context video modeling. arXiv preprint arXiv:2501.00574 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Li, Y., Yang, X., Bao, B.K., Xu, C.: Graph prompts: Adapting video graph for video question answering. In: Kwok, J. (ed.) Proceedings of the Thirty-Fourth In- ternational Joint Conference on Artificial Intelligence, IJCAI-25. pp. 1485–1493. International Joint Conferences on Artificial Intelligence Organization (8 2025). https://doi.org/10.24963/ijcai.202...
-
[43]
In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y
Li, Y., Li, Y., Vasconcelos, N.: Resound: Towards action recognition without rep- resentation bias. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) Computer Vision – ECCV 2018. pp. 520–535. Springer International Publishing, Cham (2018)
2018
-
[44]
Advances in Neural Information Processing Systems 33(2020)
Li, Y., Torralba, A., Anandkumar, A., Fox, D., Garg, A.: Causal discovery in physical systems from videos. Advances in Neural Information Processing Systems 33(2020)
2020
-
[45]
In: Proceedings of the Workshop on Visual Analysis in Smart and Connected Communities
Liu, C., Hu, Y., Li, Y., Song, S., Liu, J.: Pku-mmd: A large scale benchmark for skeleton-based human action understanding. In: Proceedings of the Workshop on Visual Analysis in Smart and Connected Communities. p. 1–8. VSCC ’17, Associ- ation for Computing Machinery, New York, NY, USA (2017).https://doi.org/ 10.1145/3132734.3132739,https://doi.org/10.1145...
-
[46]
Liu,J.,Shahroudy,A.,Perez,M.,Wang,G.,Duan,L.Y.,Kot,A.C.:Nturgb+d120: A large-scale benchmark for 3d human activity understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence42(10), 2684–2701 (2020).https: //doi.org/10.1109/TPAMI.2019.2916873 20 R. Abdullah et al
-
[47]
In: The Thirteenth Inter- national Conference on Learning Representations (2025),https://openreview
Liu, Z., Dong, Y., Liu, Z., Hu, W., Lu, J., Rao, Y.: Oryx MLLM: On-demand spatial-temporal understanding at arbitrary resolution. In: The Thirteenth Inter- national Conference on Learning Representations (2025),https://openreview. net/forum?id=ODiY6pbHZQ
2025
-
[48]
Lu, S., Li, Y., Chen, Q.G., Xu, Z., Luo, W., Zhang, K., Ye, H.J.: Ovis: Struc- tural embedding alignment for multimodal large language model. arXiv:2405.20797 (2024)
-
[49]
Lu, S., Li, Y., Xia, Y., Hu, Y., Zhao, S., Ma, Y., Wei, Z., Li, Y., Duan, L., Zhao, J., Han, Y., Li, H., Chen, W., Tang, J., Hou, C., Du, Z., Zhou, T., Zhang, W., Ding, H., Li, J., Li, W., Hu, G., Gu, Y., Yang, S., Wang, J., Sun, H., Wang, Y., Sun, H., Huang, J., He, Y., Shi, S., Zhang, W., Zheng, G., Jiang, J., Gao, S., Wu, Y.F., Chen, S., Chen, Y., Chen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Ma, H., Pathak, V., Wang, D.Z.: Bridging vision language models and symbolic grounding for video question answering (2025),https://arxiv.org/abs/2509. 11862
2025
-
[51]
In: Arai, K
Malmqvist, L.: Sycophancy in large language models: Causes and mitigations. In: Arai, K. (ed.) Intelligent Computing. pp. 61–74. Springer Nature Switzerland, Cham (2025)
2025
-
[52]
McDuff, D., Song, Y., Lee, J., Vineet, V., Vemprala, S., Gyde, N., Salman, H., Ma, S., Sohn, K., Kapoor, A.: Causalcity: Complex simulations with agency for causal discovery and reasoning (June 2021),https://www.microsoft.com/en-us/ research/publication/causalcity- complex- simulations- with- agency- for- causal-discovery-and-reasoning/, preprint under review
2021
-
[53]
In: 2019 IEEE/CVF International Conference on Computer Vi- sion (ICCV)
Miech, A., Zhukov, D., Alayrac, J.B., Tapaswi, M., Laptev, I., Sivic, J.: Howto100m: Learning a text-video embedding by watching hundred million nar- rated video clips. In: 2019 IEEE/CVF International Conference on Computer Vi- sion (ICCV). pp. 2630–2640 (2019).https://doi.org/10.1109/ICCV.2019.00272
-
[54]
Monfort, M., Vondrick, C., Oliva, A., Andonian, A., Zhou, B., Ramakrishnan, K., Bargal, S.A., Yan, T., Brown, L., Fan, Q., Gutfreund, D.: Moments in Time Dataset: One Million Videos for Event Understanding . IEEE Transactions on Pattern Analysis & Machine Intelligence42(02), 502–508 (Feb 2020).https: //doi.org/10.1109/TPAMI.2019.2901464,https://doi.ieeeco...
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Nguyen, T.T., Nguyen, P., Cothren, J., Yilmaz, A., Luu, K.: Hyperglm: Hyper- graph for video scene graph generation and anticipation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 29150–29160 (June 2025)
2025
-
[56]
In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T
Ni, B., Peng, H., Chen, M., Zhang, S., Meng, G., Fu, J., Xiang, S., Ling, H.: Expanding language-image pretrained models for general video recognition. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision – ECCV 2022. pp. 1–18. Springer Nature Switzerland, Cham (2022)
2022
-
[57]
OpenAI: Gpt-4o mini: Advancing cost-efficient intelligence.https://openai.com/ index/gpt-4o-mini-advancing-cost-efficient-intelligence/(Jul 2024), ac- cessed 2026-06-27
2024
-
[58]
https://openai.com/index/sycophancy-in-gpt-4o/(Apr 2025), accessed 2025- 11-09
OpenAI: Sycophancy in gpt-4o: what happened and what we’re doing about it. https://openai.com/index/sycophancy-in-gpt-4o/(Apr 2025), accessed 2025- 11-09
2025
-
[59]
co / prithivMLmods / LumianâĂŚVLRâĂŚ7BâĂŚThinking(2025), hugging Face model card Learning to Deny: Action Denial in Multimodal Large Language Models 21
prithivMLmods: Lumian-vlr-7b-thinking.https : / / huggingface . co / prithivMLmods / LumianâĂŚVLRâĂŚ7BâĂŚThinking(2025), hugging Face model card Learning to Deny: Action Denial in Multimodal Large Language Models 21
2025
-
[60]
In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= OxKi02I29I
Ranasinghe, K., Li, X., Kahatapitiya, K., Ryoo, M.S.: Understanding long videos with multimodal language models. In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= OxKi02I29I
2025
-
[61]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rasheed, H., Khattak, M.U., Maaz, M., Khan, S., Khan, F.S.: Fine-tuned clip models are efficient video learners. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6545–6554 (2023).https://doi. org/10.1109/CVPR52729.2023.00633
-
[62]
In: Ku, L.W., Martins, A., Srikumar, V
Rrv, A., Tyagi, N., Uddin, M.N., Varshney, N., Baral, C.: Chaos with keywords: Exposing large language models sycophancy to misleading keywords and evaluat- ing defense strategies. In: Ku, L.W., Martins, A., Srikumar, V. (eds.) Findings of the Association for Computational Linguistics: ACL 2024. pp. 12717–12733. As- sociation for Computational Linguistics...
-
[63]
Shao, D., Zhao, Y., Dai, B., Lin, D.: Finegym: A hierarchical video dataset for fine-grained action understanding. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2613–2622 (2020).https://doi. org/10.1109/CVPR42600.2020.00269
-
[64]
In: The Twelfth Interna- tional Conference on Learning Representations (2024),https://openreview.net/ forum?id=tvhaxkMKAn
Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S.R., DURMUS, E., Hatfield-Dodds, Z., Johnston, S.R., Kravec, S.M., Maxwell, T., Mc- Candlish, S., Ndousse, K., Rausch, O., Schiefer, N., Yan, D., Zhang, M., Perez, E.: Towards understanding sycophancy in language models. In: The Twelfth Interna- tional Conference on Learning Representati...
2024
-
[65]
In: Leibe, B., Matas, J., Sebe, N., Welling, M
Sigurdsson, G.A., Varol, G., Wang, X., Farhadi, A., Laptev, I., Gupta, A.: Hol- lywood in homes: Crowdsourcing data collection for activity understanding. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision – ECCV 2016. pp. 510–526. Springer International Publishing, Cham (2016)
2016
-
[66]
In: CRCV-TR-12-01 (2012)
Soomro, K., Roshan Zamir, A., Shah, M.: UCF101: A dataset of 101 human actions classes from videos in the wild. In: CRCV-TR-12-01 (2012)
2012
-
[67]
CoRRabs/2506.08553(June 2025),https://doi.org/ 10.48550/arXiv.2506.08553
Taluzzi, A., Gesualdi, D., Santambrogio, R., Plizzari, C., Palermo, F., Mentasti, S., Matteucci, M.: From pixels to graphs: using scene and knowledge graphs for hd-epic vqa challenge. CoRRabs/2506.08553(June 2025),https://doi.org/ 10.48550/arXiv.2506.08553
-
[68]
In: Proceedings of the 29th ACM International Conference on Multimedia
Tang, M., Wang, Z., LIU, Z., Rao, F., Li, D., Li, X.: Clip4caption: Clip for video caption. In: Proceedings of the 29th ACM International Conference on Multimedia. p. 4858–4862. MM ’21, Association for Computing Machinery, New York, NY, USA (2021).https://doi.org/10.1145/3474085.3479207,https://doi.org/ 10.1145/3474085.3479207
-
[69]
Team, K., Du, A., Yin, B., Xing, B., Qu, B., Wang, B., Chen, C., Zhang, C., Du, C., Wei, C., Wang, C., Zhang, D., Du, D., Wang, D., Yuan, E., Lu, E., Li, F., Sung, F., Wei, G., Lai, G., Zhu, H., Ding, H., Hu, H., Yang, H., Zhang, H., Wu, H., Yao, H., Lu, H., Wang, H., Gao, H., Zheng, H., Li, J., Su, J., Wang, J., Deng, J., Qiu, J., Xie, J., Wang, J., Liu,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
In: Causality and Large Models @NeurIPS 2024 (2024),https://openreview
Vashishtha, A., Kumar, A., Pandey, A., Reddy, A.G., Balasubramanian, V.N., Sharma, A.: Teaching transformers causal reasoning through axiomatic training. In: Causality and Large Models @NeurIPS 2024 (2024),https://openreview. net/forum?id=vnFtU3fO9h
2024
-
[71]
IEEE Transactions on Neural Networks and Learning Systems36(1), 625–637 (2025).https://doi.org/10
Wang, M., Xing, J., Mei, J., Liu, Y., Jiang, Y.: Actionclip: Adapting language- image pretrained models for video action recognition. IEEE Transactions on Neural Networks and Learning Systems36(1), 625–637 (2025).https://doi.org/10. 1109/TNNLS.2023.3331841
-
[72]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Wang, Y., Li, X., Yan, Z., He, Y., Yu, J., Zeng, X., Wang, C., Ma, C., Huang, H., Gao, J., Dou, M., Chen, K., Wang, W., Qiao, Y., Wang, Y., Wang, L.: In- ternvideo2.5: Empowering video mllms with long and rich context modeling. arXiv preprint arXiv:2501.12386 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
International Journal of Computer Vision129, 1675 – 1690 (2019), https://api.semanticscholar.org/CorpusID:209376248
Weinzaepfel, P., Rogez, G.: Mimetics: Towards understanding human actions out of context. International Journal of Computer Vision129, 1675 – 1690 (2019), https://api.semanticscholar.org/CorpusID:209376248
2019
-
[74]
In: ICML (2023)
Weng, Z., Yang, X., Li, A., Wu, Z., Jiang, Y.G.: Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization. In: ICML (2023)
2023
-
[75]
arXiv preprint arXiv:2501.05901 (2025)
Wu, Z., Chen, Z., Luo, R., Zhang, C., Gao, Y., He, Z., Wang, X., Lin, H., Qiu, M.: Valley2: Exploring multimodal models with scalable vision-language design. arXiv preprint arXiv:2501.05901 (2025)
-
[76]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Xiang, W., Li, C., Li, K., Wang, B., Hua, X.S., Zhang, L.: Cdad: A common daily action dataset with collected hard negative samples. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 3920–3929 (2022).https://doi.org/10.1109/CVPRW56347.2022.00437
-
[77]
Xu, H., Ghosh, G., Huang, P.Y., Okhonko, D., Aghajanyan, A., Metze, F., Zettle- moyer, L., Feichtenhofer, C.: Videoclip: Contrastive pre-training for zero-shot video-text understanding (2021)
2021
-
[78]
In: 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition
Yao, B., Fei-Fei, L.: Grouplet: A structured image representation for recognizing human and object interactions. In: 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. pp. 9–16 (2010).https://doi.org/ 10.1109/CVPR.2010.5540234
-
[79]
Yeung, S., Russakovsky, O., Jin, N., Andriluka, M., Mori, G., Fei-Fei, L.: Every moment counts: Dense detailed labeling of actions in complex videos. Int. J. Com- put. Vision126(2–4), 375–389 (Apr 2018).https://doi.org/10.1007/s11263- 017-1013-y,https://doi.org/10.1007/s11263-017-1013-y
-
[80]
In: ICLR (2020)
Yi, K., Gan, C., Li, Y., Kohli, P., Wu, J., Torralba, A., Tenenbaum, J.B.: CLEVRER: collision events for video representation and reasoning. In: ICLR (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.