Epiphany-Aware KV Cache Eviction Without the Attention Matrix
Pith reviewed 2026-06-26 05:45 UTC · model grok-4.3
The pith
Tokens for KV cache eviction can be ranked by the change in a model's internal representation during the forward pass, without ever computing attention weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
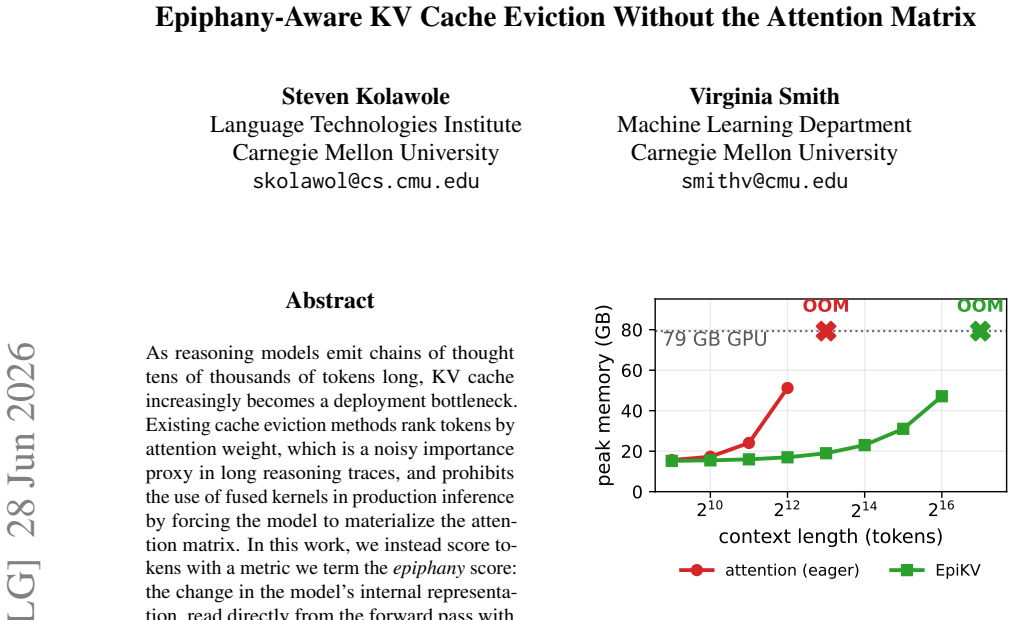
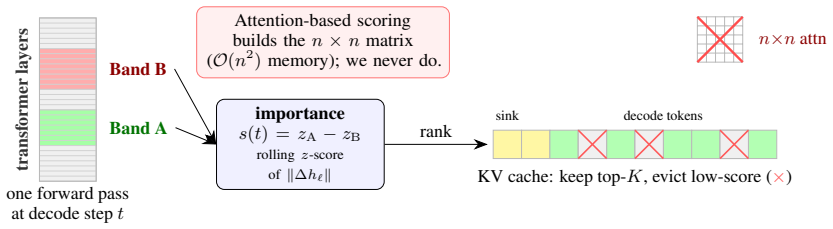
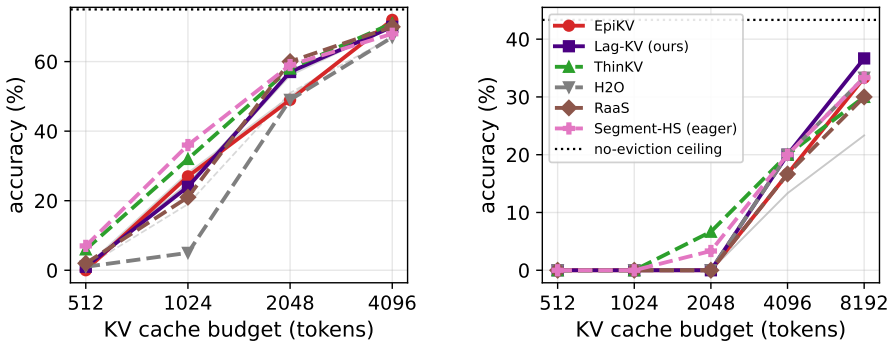
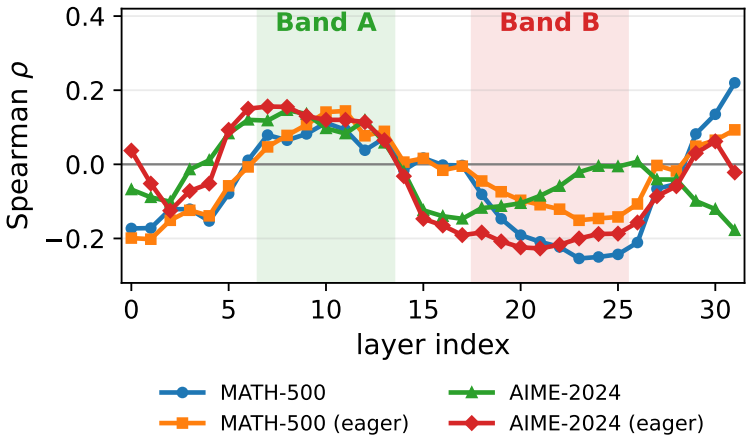
EpiKV replaces attention-based token ranking with the epiphany score, defined as the change in the model's internal representation read directly from the forward pass. After subtracting a causal rolling z-score to remove positional trends and focusing on upper-mid layers, tokens with the lowest scores are evicted. This yields a cache-eviction policy that matches ThinKV (71 percent) and exceeds H2O (67 percent) at 72 percent on MATH-500 with a 4096-token budget, reaches 37 percent on AIME-2024 at 8192 tokens, and extends feasible context length by a factor of 16 relative to attention-matrix methods, all without training or custom kernels.
What carries the argument
The epiphany score: the change in the model's internal representation during the forward pass, used as a direct proxy for token importance that bypasses the attention matrix entirely.
If this is right
- EpiKV integrates directly into existing FlashAttention inference pipelines without any code changes or extra kernels.
- The method extends the usable context length for reasoning models by roughly sixteen times compared with attention-matrix eviction policies.
- A lag-normalized version of the same score reaches 37 percent on AIME-2024 at 8192 tokens while running up to 2.8 times faster than the best attention baseline.
- No additional training data or classifier is needed to achieve parity with attention-based methods on MATH-500.
- The policy works at cache sizes where attention-based scoring becomes infeasible because the attention matrix cannot be materialized.
Where Pith is reading between the lines
- The same internal-state delta could be monitored at additional layers or checkpoints to refine eviction decisions on even longer traces.
- Because the signal is independent of attention, it may combine with hardware-specific kernel optimizations that currently cannot expose attention weights.
- If the epiphany score proves stable across model families, it offers a path to cache management that does not require architecture-specific attention implementations.
- The approach suggests testing whether similar activation-change signals can guide other memory-management decisions such as prompt compression or layer-wise pruning.
Load-bearing premise
Changes observed in the model's internal activations during a single forward pass reliably mark which tokens matter most for the eventual answer.
What would settle it
A controlled experiment in which EpiKV is run on the same long reasoning traces as ThinKV or H2O but produces measurably lower final accuracy once the cache size drops below the tested 4096-token limit.
Figures

read the original abstract
As reasoning models emit chains of thought tens of thousands of tokens long, KV cache increasingly becomes a deployment bottleneck. Existing cache eviction methods rank tokens by attention weight, which is a noisy importance proxy in long reasoning traces, and prohibits the use of fused kernels in production inference by forcing the model to materialize the attention matrix. In this work, we instead score tokens with a metric we term the epiphany score: the change in the model's internal representation, read directly from the forward pass with no attention matrix and negligible extra state. Our resulting cache eviction method, EpiKV, requires no training, classifier, or custom kernel, and can be used directly in FlashAttention inference stacks unchanged -- scaling to a 16x longer feasible context than attention-based scoring. upper-mid layers negatively) and remove a positional trend with a causal rolling z-score. At a 4096-token cache EpiKV reaches 72% on MATH-500, matching the strongest attention-based baseline (ThinKV 71%, H2O 67%); a lag-normalized KV variant reaches 37% on AIME-2024 at 8192 tokens against the best of them (33%), at up to 2.8x the speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EpiKV, a KV-cache eviction method for long CoT reasoning models that replaces attention-weight scoring with an 'epiphany score' computed from the change in hidden-state representations in upper-mid layers after a causal rolling z-score. The method requires no training, no classifier, and no custom kernel, allowing direct use inside FlashAttention stacks. Reported results show EpiKV reaching 72% on MATH-500 at a 4096-token cache (matching ThinKV at 71% and exceeding H2O at 67%) and a lag-normalized variant reaching 37% on AIME-2024 at 8192 tokens (vs. 33% for the best baseline), while supporting up to 16x longer feasible contexts than attention-based eviction.
Significance. If the epiphany score proves to be a reliable, attention-independent importance signal, the approach would remove a practical barrier to fused-kernel inference for long-context reasoning models and could enable substantially longer CoT traces under fixed memory budgets. The absence of training or custom kernels is a concrete deployment advantage.
major comments (2)
- [Experiments / Results] The central claim that the epiphany score supplies an attention-independent importance proxy rests on performance parity alone. No ablation, correlation, or rank-agreement analysis is presented that directly compares epiphany scores against attention weights on identical traces, nor is a controlled swap (attention vs. epiphany under the same eviction logic) reported; without such evidence it remains possible that eviction dynamics rather than the new signal drive the observed results.
- [Experiments] The experimental section states performance numbers (72% MATH-500, 37% AIME) but supplies no details on random seeds, number of runs, statistical tests, or exact baseline re-implementations, making it impossible to assess whether the reported parity is robust or sensitive to implementation choices.
minor comments (2)
- [Method] The abstract and method description would benefit from an explicit equation or pseudocode block defining the epiphany score (including the precise layer range and z-score window) so readers can reproduce the metric without ambiguity.
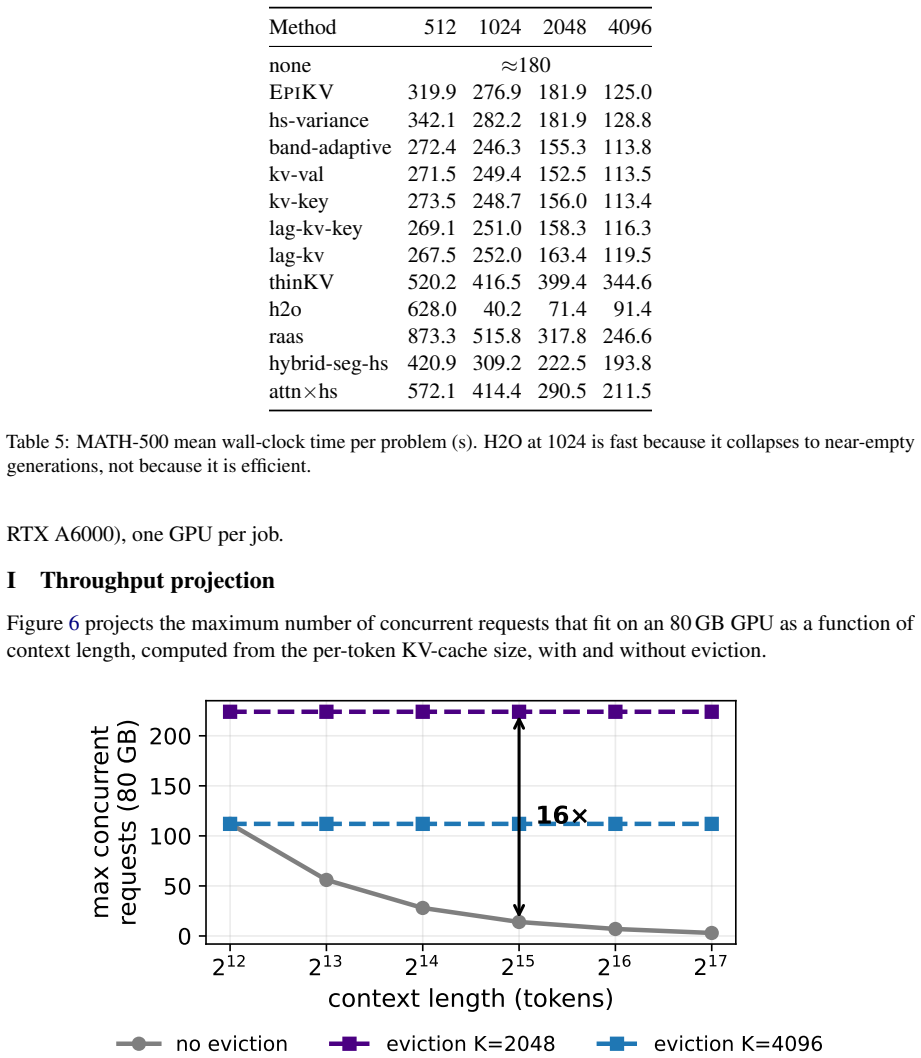
- [Figures / Tables] Figure captions and table footnotes should clarify whether the 16x context scaling claim is measured under identical hardware or is a theoretical projection based on memory footprint.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to address these points. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Experiments / Results] The central claim that the epiphany score supplies an attention-independent importance proxy rests on performance parity alone. No ablation, correlation, or rank-agreement analysis is presented that directly compares epiphany scores against attention weights on identical traces, nor is a controlled swap (attention vs. epiphany under the same eviction logic) reported; without such evidence it remains possible that eviction dynamics rather than the new signal drive the observed results.
Authors: We agree that direct evidence comparing the epiphany score to attention weights would strengthen the claim of an attention-independent proxy. Performance parity alone leaves open the possibility that eviction mechanics contribute to the results. In the revised manuscript we will add (i) Spearman rank correlation and top-k overlap statistics between epiphany scores and attention weights computed on the same traces, and (ii) a controlled ablation that applies identical eviction logic with either attention weights or epiphany scores. These additions will isolate the contribution of the new signal. revision: yes
-
Referee: [Experiments] The experimental section states performance numbers (72% MATH-500, 37% AIME) but supplies no details on random seeds, number of runs, statistical tests, or exact baseline re-implementations, making it impossible to assess whether the reported parity is robust or sensitive to implementation choices.
Authors: We acknowledge the omission of reproducibility details. The revised version will report the number of independent runs, random seeds, any statistical significance tests performed, and precise re-implementation notes for all baselines (including hyper-parameters and code references). revision: yes
Circularity Check
No circularity: epiphany score defined directly from forward-pass hidden-state deltas
full rationale
The paper introduces the epiphany score as an explicit definition—the change in internal representations from upper-mid layers after causal rolling z-score—computed solely from the forward pass without reference to attention weights, fitted parameters, or any self-cited prior result. No equation or claim reduces a prediction to its own inputs by construction, no uniqueness theorem is invoked, and no ansatz is smuggled via citation. Empirical performance numbers (72% MATH-500 at 4096 tokens, etc.) are presented as direct comparisons rather than derived quantities. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
epiphany score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gonzalez and Hao Zhang and Ion Stoica , title =
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph E. Gonzalez and Hao Zhang and Ion Stoica , title =. Proceedings of the 29th Symposium on Operating Systems Principles (SOSP) , pages =
-
[2]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[3]
Publications Manual , year = "1983", publisher =
1983
-
[4]
Chandra and Dexter C
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =
1981
-
[5]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[6]
Dan Gusfield , title =. 1997
1997
-
[7]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[8]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[10]
International Conference on Learning Representations (ICLR) , volume=
Efficient Streaming Language Models with Attention Sinks , author =. International Conference on Learning Representations (ICLR) , volume=
-
[11]
2026 , note =
Ramachandran, Akshat and Neseem, Marina and Sakr, Charbel and Venkatesan, Rangharajan and Khailany, Brucek and Krishna, Tushar , booktitle =. 2026 , note =
2026
-
[12]
2025 , address =
Hu, Junhao and Huang, Wenrui and Wang, Weidong and Li, Zhenwen and Hu, Tiancheng and Liu, Zhixia and Chen, Xusheng and Xie, Tao and Shan, Yizhou , booktitle =. 2025 , address =
2025
-
[13]
Liang, Manlai and Zhang, JiaMing and Li, Xiong and Li, Jinlong , journal =
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Dao, Tri and Fu, Dan and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[15]
Dao, Tri , booktitle =
-
[16]
Li, Yuhong and Huang, Yingbing and Yang, Bowen and Venkitesh, Bharat and Locatelli, Acyr and Ye, Hanchen and Cai, Tianle and Lewis, Patrick and Chen, Deming , booktitle =
-
[17]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in
-
[18]
International Conference on Learning Representations (ICLR) , year =
Mass-Editing Memory in a Transformer , author =. International Conference on Learning Representations (ICLR) , year =
-
[19]
2025 , publisher=
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and others , journal=. 2025 , publisher=
2025
-
[20]
Liu, Xiang and Tang, Zhenheng and Dong, Peijie and Li, Zeyu and Liu, Yue and Li, Bo and Hu, Xuming and Chu, Xiaowen , booktitle =
-
[21]
Cai, Zefan and Zhang, Yichi and Gao, Bofei and Liu, Yuliang and Li, Yucheng and Liu, Tianyu and Lu, Keming and Xiong, Wayne and Dong, Yue and Hu, Junjie and others , booktitle=
-
[22]
Goel, Raghavv and Park, Junyoung and Gagrani, Mukul and Jones, Dalton and Morse, Matthew and Langston, Harper and Lee, Mingu and Lott, Chris , journal =
-
[23]
Gu, Yifeng and Jiang, Zicong and Jin, Jianxiu and Guo, Kailing and Zhang, Ziyang and Xu, Xiangmin , journal =
-
[24]
Su, Yi and Tian, Zhenxu and Qiao, Dan and Zhou, Yuechi and Li, Juntao and Zhang, Min , journal =
-
[25]
Hooper, Coleman and Kim, Sehoon and Mohammadzadeh, Hiva and Mahoney, Michael W and Shao, Yakun S and Keutzer, Kurt and Gholami, Amir , booktitle =
-
[26]
Tang, Jiaming and Zhao, Yilong and Zhu, Kan and Xiao, Guangxuan and Kasikci, Baris and Han, Song , booktitle=
-
[27]
Guangda Liu and Chengwei Li and Zhenyu Ning and Jing Lin and Yiwu Yao and Danning Ke and Minyi Guo and Jieru Zhao , booktitle=. Free
-
[28]
2024 , organization=
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , booktitle=. 2024 , organization=
2024
-
[29]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Transformer Feed-Forward Layers Are Key-Value Memories , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
2021
-
[30]
Edward , journal =
Kariyappa, Sanjay and Suh, G. Edward , journal =
-
[31]
2025 , address =
Sharma, Akshat and Ding, Hangliang and Li, Jianping and Dani, Neel and Zhang, Minjia , booktitle =. 2025 , address =
2025
-
[32]
Measuring Mathematical Problem Solving with the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving with the
-
[33]
International Conference on Learning Representations , volume=
Let's Verify Step by Step , author=. International Conference on Learning Representations , volume=
-
[34]
arXiv preprint arXiv:2110.14168 , year =
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.