CheXpercept: A Benchmark for Evaluating Expert-Level Lesion Perception in Chest X-rays
Pith reviewed 2026-06-26 15:03 UTC · model grok-4.3
The pith
Vision-language models detect chest X-ray lesions at coarse level but lose accuracy on contours and attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that existing vision-language models achieve adequate performance only at the coarse level of lesion detection in chest X-rays, with accuracy degrading precipitously on deeper visual tasks of contour evaluation and attribute extraction, and that medical VLMs exhibit almost no perceptual advantage over general-domain counterparts.
What carries the argument
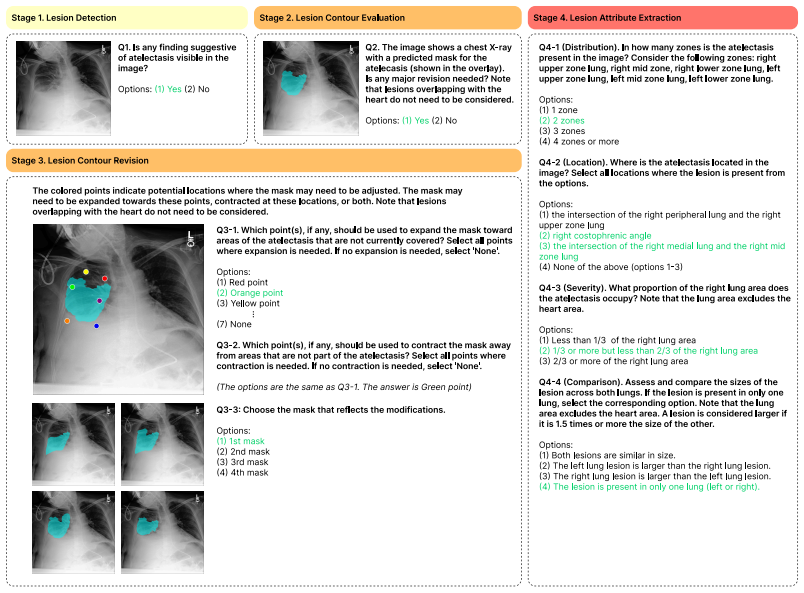
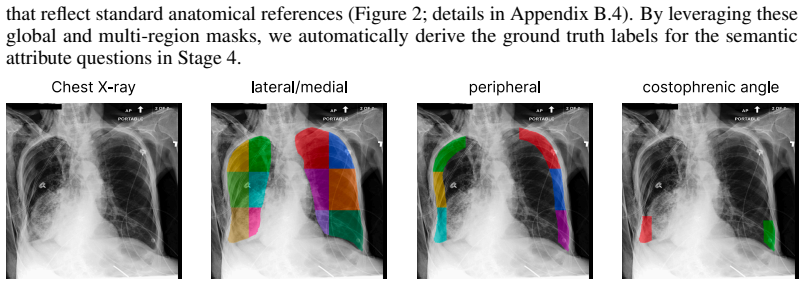
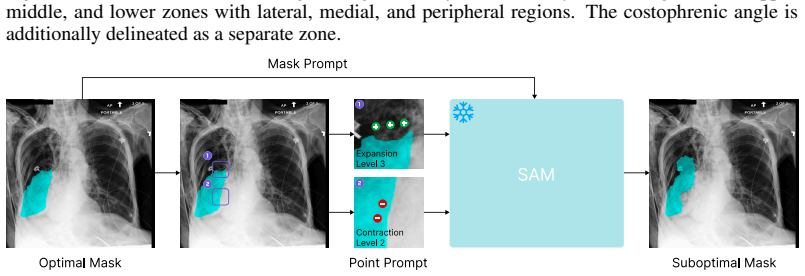
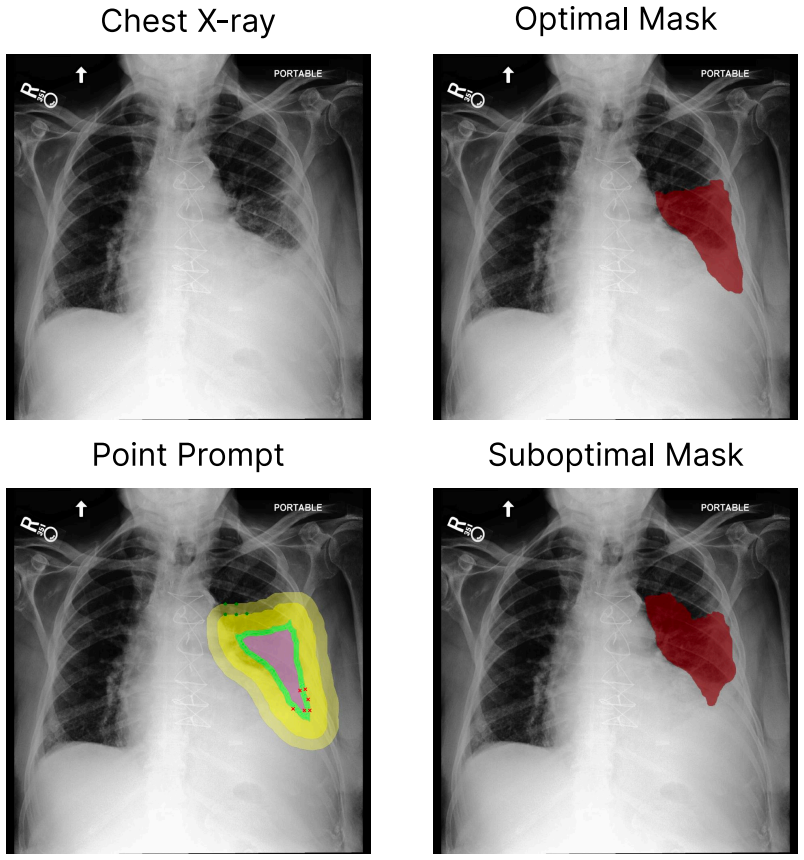
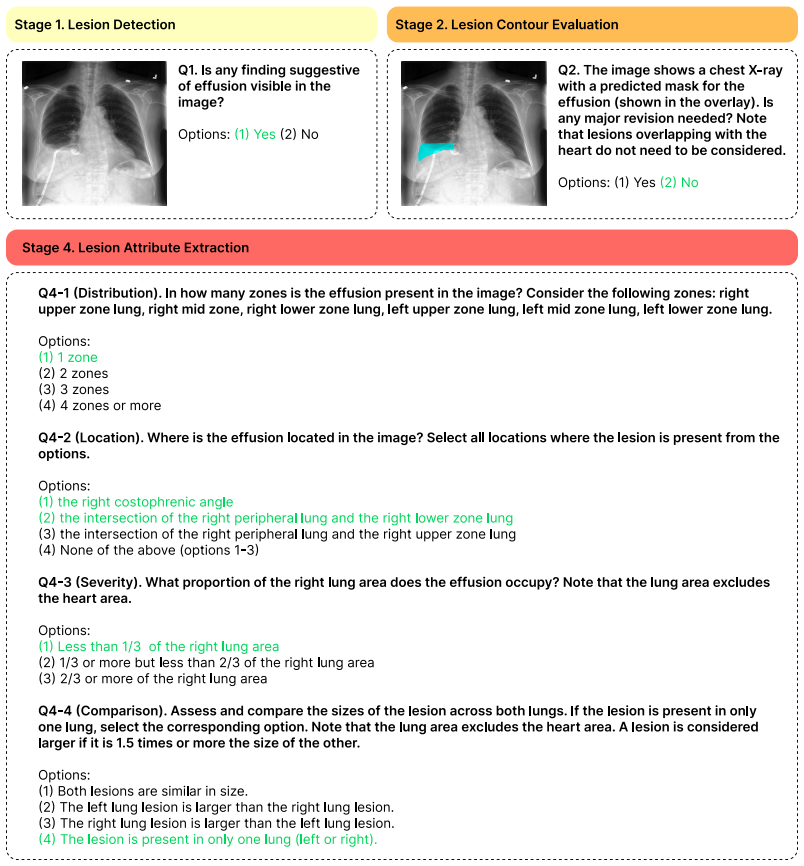
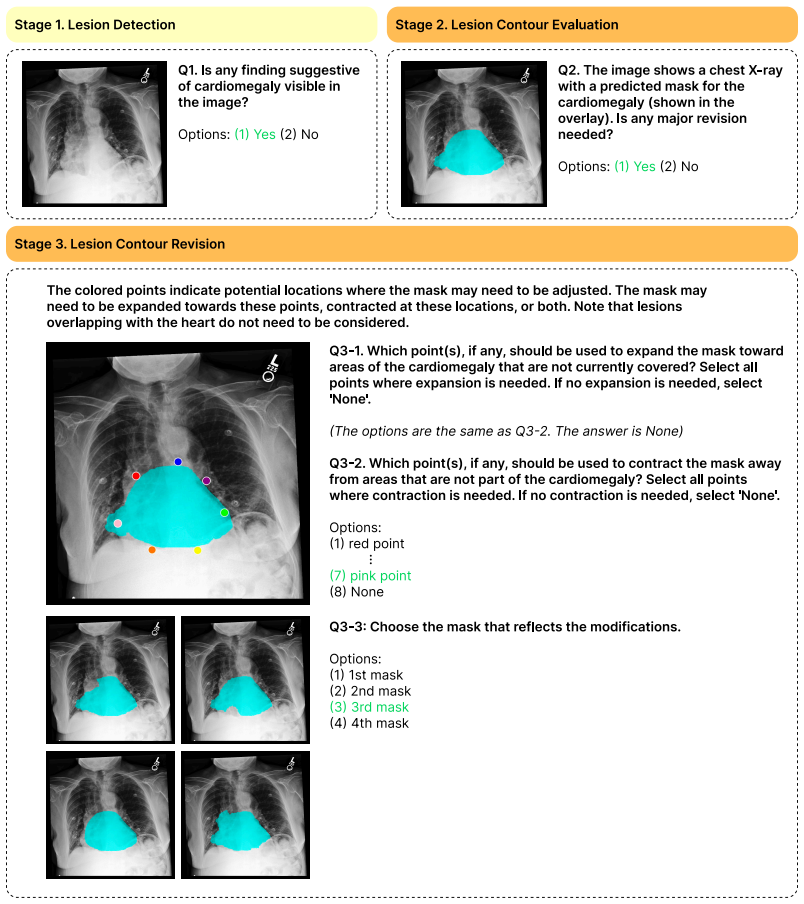
CheXpercept, a sequential multi-level perception benchmark built from 10,400 QA items across 2,100 chest X-rays and seven lesion types via a semi-automated pipeline reviewed by six medical experts.
If this is right
- Clinical use of VLMs for chest X-ray analysis requires explicit improvements in fine-grained visual grounding beyond classification accuracy.
- Domain adaptation techniques for medical VLMs must incorporate mechanisms that preserve perceptual detail across task depths.
- Benchmark design for medical imaging should prioritize sequential workflows that test progressive levels of visual analysis.
Where Pith is reading between the lines
- The multi-level structure could be adapted to evaluate perception in other imaging modalities such as CT or MRI.
- Training objectives for future models may need to include direct supervision on lesion contours and attributes rather than relying on classification alone.
- The gap between coarse and fine performance suggests that scaling model size or data volume alone is unlikely to resolve the perceptual shortfall.
Load-bearing premise
The semi-automated generation pipeline and expert review produce QA items that accurately capture expert-level lesion perception and mirror a radiologist's cognitive workflow across the three levels.
What would settle it
A model that maintains high accuracy on the contour evaluation and attribute extraction levels, comparable to expert radiologists, would show the claim of systemic failure in current domain adaptation does not hold.
Figures






read the original abstract
The evaluation of vision-language models (VLMs) for chest X-ray (CXR) analysis has largely been limited to disease-presence classification without visual grounding. Such evaluations fail to verify the expert-level lesion perception necessary to ensure the clinical reliability of VLMs. To address these limitations, we introduce CheXpercept, a sequential, multi-level perception benchmark that mirrors a radiologist's cognitive workflow across coarse-level detection, fine-level contour evaluation and revision, and semantic-level attribute extraction. To ensure high clinical fidelity at scale, we construct the dataset using a semi-automated generation pipeline paired with a review by six medical experts. CheXpercept contains 10,400 QA items derived from 2,100 CXRs, covering seven clinically critical pulmonary and cardiac lesions. To demonstrate the current landscape of VLM perception, we benchmark 14 general and medical VLMs on CheXpercept. The models achieve adequate performance only at the coarse level, with accuracy degrading precipitously on deeper visual tasks. Notably, medical VLMs show almost no perceptual advantage over their general-domain counterparts, highlighting a systemic flaw in current domain adaptation. The code and dataset will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CheXpercept, a sequential multi-level benchmark for vision-language models on chest X-ray lesion perception. It consists of 10,400 QA items derived from 2,100 CXRs covering seven lesions, constructed via a semi-automated pipeline with review by six medical experts. The benchmark probes three levels mirroring radiologist workflow: coarse detection, fine contour evaluation/revision, and semantic attribute extraction. Benchmarking 14 general and medical VLMs shows adequate performance only at the coarse level with precipitous degradation on finer tasks, and no perceptual advantage for medical VLMs over general-domain counterparts. Code and dataset are to be released publicly.
Significance. If the benchmark items validly capture expert-level lesion perception without pipeline artifacts, the work would highlight a systemic limitation in current VLM domain adaptation for clinical CXR analysis. The public release of code and dataset strengthens reproducibility and enables future extensions or ablations by the community.
major comments (2)
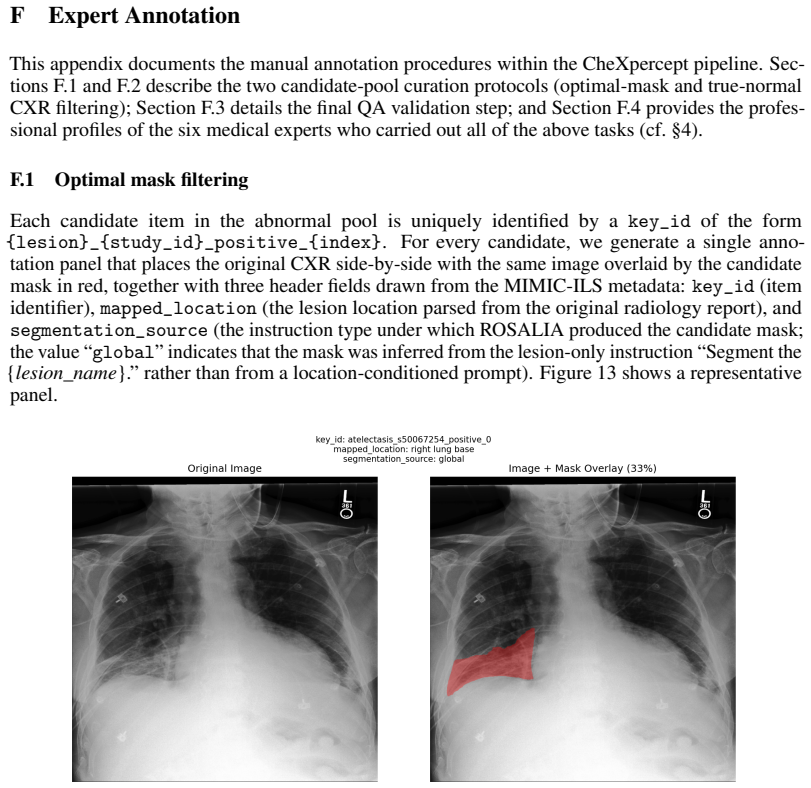
- [Methods / Dataset Construction] Dataset construction (described in the methods): the semi-automated pipeline with six-expert review is presented as ensuring clinical fidelity, but no inter-rater agreement statistics, no comparison against fully manual expert annotations, and no ablation on cueing or ambiguity in fine-level contour/semantic questions are reported. This directly bears on the central claim that performance degradation reflects true perceptual deficits rather than benchmark construction artifacts.
- [Experiments / Results] Results section: the headline finding of 'almost no perceptual advantage' for medical VLMs and 'precipitous' degradation on deeper tasks is presented without error bars, per-model breakdowns by lesion type, or controls for question difficulty distribution across the three levels. These omissions make it impossible to assess whether the observed pattern is robust or driven by a subset of items.
minor comments (2)
- [Abstract] Abstract states headline results but supplies no quantitative scores or exclusion criteria; moving a concise summary table or key metrics into the abstract would improve readability.
- [Introduction / Benchmark Design] Notation for the three perception levels is introduced without an explicit diagram or example QA triple per level; adding one would clarify the sequential workflow claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Methods / Dataset Construction] Dataset construction (described in the methods): the semi-automated pipeline with six-expert review is presented as ensuring clinical fidelity, but no inter-rater agreement statistics, no comparison against fully manual expert annotations, and no ablation on cueing or ambiguity in fine-level contour/semantic questions are reported. This directly bears on the central claim that performance degradation reflects true perceptual deficits rather than benchmark construction artifacts.
Authors: We agree that inter-rater agreement statistics would strengthen validation of clinical fidelity and will compute and report them from the expert review process in the revised methods section. We will also add ablations examining cueing effects and question ambiguity to the supplementary material. A direct comparison to fully manual annotations was not performed due to the design of the semi-automated pipeline for scalability; we will explicitly discuss this as a limitation in the revision. revision: partial
-
Referee: [Experiments / Results] Results section: the headline finding of 'almost no perceptual advantage' for medical VLMs and 'precipitous' degradation on deeper tasks is presented without error bars, per-model breakdowns by lesion type, or controls for question difficulty distribution across the three levels. These omissions make it impossible to assess whether the observed pattern is robust or driven by a subset of items.
Authors: We agree these additions are needed to demonstrate robustness. We will add error bars to all reported metrics, include per-model breakdowns by lesion type in the results, and provide an analysis of question difficulty distribution across the three levels to rule out imbalance as a confounding factor. revision: yes
- Direct comparison against fully manual expert annotations
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential predictions
full rationale
The paper introduces CheXpercept as a new benchmark dataset and evaluates existing VLMs on it. The abstract and provided text describe a semi-automated QA generation pipeline reviewed by experts, followed by model benchmarking. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear. The central claims rest on empirical results from the benchmark rather than any derivation chain that reduces to its own construction by definition. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mimic-ext-mimic-cxr-vqa: a complex, diverse, and large-scale visual question answering dataset for chest x-ray images.PhysioNet, 2024
Seongsu Bae, Daeun Kyung, Jaehee Ryu, Eunbyeol Cho, Gyubok Lee, Sunjun Kweon, Jungwoo Oh, Lei JI, Eric Chang, Tackeun Kim, et al. Mimic-ext-mimic-cxr-vqa: a complex, diverse, and large-scale visual question answering dataset for chest x-ray images.PhysioNet, 2024
2024
-
[2]
Maira-2: Grounded radiology report generation.arXiv preprint arXiv:2406.04449, 2024
Shruthi Bannur, Kenza Bouzid, Daniel C Castro, Anton Schwaighofer, Anja Thieme, Sam Bond-Taylor, Maximilian Ilse, Fernando Pérez-García, Valentina Salvatelli, Harshita Sharma, et al. Maira-2: Grounded radiology report generation.arXiv preprint arXiv:2406.04449, 2024
arXiv 2024
-
[3]
Overview of the vqa-med task at imageclef 2021: Visual question answering and generation in the medical domain
Asma Ben Abacha, Mourad Sarrouti, Dina Demner-Fushman, Sadid A Hasan, and Henning Müller. Overview of the vqa-med task at imageclef 2021: Visual question answering and generation in the medical domain. InProceedings of the CLEF 2021 Conference and Labs of the Evaluation Forum-working notes. 21-24 September 2021, 2021
2021
-
[4]
Radiotransformer: A cascaded global-focal transformer for visual attention–guided disease classification
Moinak Bhattacharya, Shubham Jain, and Prateek Prasanna. Radiotransformer: A cascaded global-focal transformer for visual attention–guided disease classification. InEuropean Conference on Computer Vision, pages 679–698. Springer, 2022
2022
-
[5]
Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[6]
Towards injecting medical visual knowledge into multimodal llms at scale
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Zhenyang Cai, Ke Ji, Xiang Wan, et al. Towards injecting medical visual knowledge into multimodal llms at scale. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 7346–7370, 2024
2024
-
[7]
Zhihong Chen, Maya Varma, Justin Xu, Magdalini Paschali, Dave Van Veen, Andrew Johnston, Alaa Youssef, Louis Blankemeier, Christian Bluethgen, Stephan Altmayer, et al. A vision-language foundation model to enhance efficiency of chest x-ray interpretation.arXiv preprint arXiv:2401.12208, 2024
arXiv 2024
-
[8]
Geon Choi, Hangyul Yoon, Hyunju Shin, Hyunki Park, Sang Hoon Seo, Eunho Yang, and Edward Choi. Instruction-guided lesion segmentation for chest x-rays with automatically generated large-scale dataset. arXiv preprint arXiv:2511.15186, 2025
arXiv 2025
-
[9]
MIMIC-CXR-Ext-ILS: Lesion Segmentation Masks and Instruction-Answer Pairs for Chest X-rays
Geon Choi, Hangyul Yoon, Hyunju Shin, Hyunki Park, Sang Hoon Seo, Eunho Yang, and Edward Choi. MIMIC-CXR-Ext-ILS: Lesion Segmentation Masks and Instruction-Answer Pairs for Chest X-rays. PhysioNet, March 2026. doi: 10.13026/8ejy-4t06. URL https://doi.org/10.13026/8ejy-4t06. Version 1.0.0
-
[10]
Matias Cosarinsky, Nicolas Gaggion, Rodrigo Echeveste, and Enzo Ferrante. Chexmask-u: Quantifying uncertainty in landmark-based anatomical segmentation for x-ray images.arXiv preprint arXiv:2512.10715, 2025
arXiv 2025
-
[11]
Perceptual and interpretive error in diagnostic radiology—causes and potential solutions.Academic radiology, 26(6):833–845, 2019
Andrew J Degnan, Emily H Ghobadi, Peter Hardy, Elizabeth Krupinski, Elena P Scali, Lindsay Stratchko, Adam Ulano, Eric Walker, Ashish P Wasnik, and William F Auffermann. Perceptual and interpretive error in diagnostic radiology—causes and potential solutions.Academic radiology, 26(6):833–845, 2019
2019
-
[12]
Medrax: Medical reasoning agent for chest x-ray.arXiv preprint arXiv:2502.02673, 2025
Adibvafa Fallahpour, Jun Ma, Alif Munim, Hongwei Lyu, and Bo Wang. Medrax: Medical reasoning agent for chest x-ray.arXiv preprint arXiv:2502.02673, 2025
arXiv 2025
-
[13]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
Pith/arXiv arXiv 2025
-
[14]
Expert knowledge-aware image difference graph representation learning for difference-aware medical visual question answering
Xinyue Hu, Lin Gu, Qiyuan An, Mengliang Zhang, Liangchen Liu, Kazuma Kobayashi, Tatsuya Harada, Ronald M Summers, and Yingying Zhu. Expert knowledge-aware image difference graph representation learning for difference-aware medical visual question answering. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4156–...
2023
-
[15]
Stephanie L Hyland, Shruthi Bannur, Kenza Bouzid, Daniel C Castro, Mercy Ranjit, Anton Schwaighofer, Fernando Pérez-García, Valentina Salvatelli, Shaury Srivastav, Anja Thieme, et al. Maira-1: A specialised large multimodal model for radiology report generation.arXiv preprint arXiv:2311.13668, 2023
arXiv 2023
-
[16]
Songtao Jiang, Yuan Wang, Sibo Song, Tianxiang Hu, Chenyi Zhou, Bin Pu, Yan Zhang, Zhibo Yang, Yang Feng, Joey Tianyi Zhou, et al. Hulu-med: A transparent generalist model towards holistic medical vision-language understanding.arXiv preprint arXiv:2510.08668, 2025. 10
arXiv 2025
-
[17]
MIMIC-CXR-JPG - chest radiographs with structured labels.PhysioNet, March 2024
Alistair Johnson, Matthew Lungren, Yifan Peng, Zhiyong Lu, Roger Mark, Seth Berkowitz, and Steven Horng. MIMIC-CXR-JPG - chest radiographs with structured labels.PhysioNet, March 2024. doi: 10.13026/jsn5-t979. URLhttps://doi.org/10.13026/jsn5-t979. Version 2.1.0
-
[18]
Mimic-cxr database
Alistair Johnson, Tom Pollard, Roger Mark, Seth Berkowitz, and Steven Horng. Mimic-cxr database. PhysioNet10, 13026(C2JT1Q):5, 2024
2024
-
[19]
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
2019
-
[20]
A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1):180251, 2018
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1):180251, 2018
2018
-
[21]
Hyungyung Lee, Geon Choi, Jung-Oh Lee, Hangyul Yoon, Hyuk Gi Hong, and Edward Choi. Cxrea- sonbench: A benchmark for evaluating structured diagnostic reasoning in chest x-rays.arXiv preprint arXiv:2505.18087, 2025
arXiv 2025
-
[22]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Nau- mann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
2023
-
[23]
Gemex: A large-scale, groundable, and explainable medical vqa benchmark for chest x-ray diagnosis
Bo Liu, Ke Zou, Li-Ming Zhan, Zexin Lu, Xiaoyu Dong, Yidi Chen, Chengqiang Xie, Jiannong Cao, Xiao- Ming Wu, and Huazhu Fu. Gemex: A large-scale, groundable, and explainable medical vqa benchmark for chest x-ray diagnosis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21310–21320, 2025
2025
-
[24]
Jong Hak Moon, Geon Choi, Paloma Rabaey, Min Gwan Kim, Hyuk Gi Hong, Jung-Oh Lee, Hangyul Yoon, Eun Woo Doe, Jiyoun Kim, Harshita Sharma, et al. Lunguage: A benchmark for structured and sequential chest x-ray interpretation.arXiv preprint arXiv:2505.21190, 2025
Pith/arXiv arXiv 2025
-
[25]
Reasoning visual language model for chest x-ray analysis.arXiv preprint arXiv:2510.23968, 2025
Andriy Myronenko, Dong Yang, Baris Turkbey, Mariam Aboian, Sena Azamat, Esra Akcicek, Hongxu Yin, Pavlo Molchanov, Marc Edgar, Yufan He, et al. Reasoning visual language model for chest x-ray analysis.arXiv preprint arXiv:2510.23968, 2025
arXiv 2025
-
[26]
Rexvqa: A large-scale visual question answering benchmark for generalist chest x-ray understanding
Ankit Pal, Jung-Oh Lee, Xiaoman Zhang, Malaikannan Sankarasubbu, Seunghyeon Roh, Won Jung Kim, Meesun Lee, and Pranav Rajpurkar. Rexvqa: A large-scale visual question answering benchmark for generalist chest x-ray understanding. InBiocomputing 2026: Proceedings of the Pacific Symposium, pages 251–264. World Scientific, 2025
2026
-
[27]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https://qwen.ai/ blog?id=qwen3.5
2026
-
[28]
Qwen3.6-27B: Flagship-level coding in a 27B dense model, April 2026
Qwen Team. Qwen3.6-27B: Flagship-level coding in a 27B dense model, April 2026. URL https: //qwen.ai/blog?id=qwen3.6-27b
2026
-
[29]
Interpretation of plain chest roentgenogram.Chest, 141(2):545–558, 2012
Suhail Raoof, David Feigin, Arthur Sung, Sabiha Raoof, Lavanya Irugulpati, and Edward C Rosenow III. Interpretation of plain chest roentgenogram.Chest, 141(2):545–558, 2012
2012
-
[30]
Constantin Seibold, Alexander Jaus, Matthias A Fink, Moon Kim, Simon Reiß, Ken Herrmann, Jens Kleesiek, and Rainer Stiefelhagen. Accurate fine-grained segmentation of human anatomy in radiographs via volumetric pseudo-labeling.arXiv preprint arXiv:2306.03934, 2023
arXiv 2023
-
[31]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report. arXiv preprint arXiv:2507.05201, 2025
Pith/arXiv arXiv 2025
-
[32]
Medgemma 1.5 technical report.arXiv preprint arXiv:2604.05081, 2026
Andrew Sellergren, Chufan Gao, Fereshteh Mahvar, Timo Kohlberger, Fayaz Jamil, Madeleine Traverse, Alberto Tono, Bashir Sadjad, Lin Yang, Charles Lau, et al. Medgemma 1.5 technical report.arXiv preprint arXiv:2604.05081, 2026
Pith/arXiv arXiv 2026
-
[33]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[34]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 11
Pith/arXiv arXiv 2023
-
[35]
Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
Pith/arXiv arXiv 2024
-
[36]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[37]
Shaoxuan Wu, Jingkun Chen, Chong Ma, Cong Shen, Xiao Zhang, and Jun Feng. Following the di- agnostic trace: Visual cognition-guided cooperative network for chest x-ray diagnosis.arXiv preprint arXiv:2602.21657, 2026
arXiv 2026
-
[38]
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044, 2025
Pith/arXiv arXiv 2025
-
[39]
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc- vqa: Visual instruction tuning for medical visual question answering.arXiv preprint arXiv:2305.10415, 2023
Pith/arXiv arXiv 2023
-
[40]
None” fraction in Stage 3 is strictly capped below 50% by design, ensuring that a naive always-“None
Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Medxpertqa: Benchmarking expert-level medical reasoning and understanding.arXiv preprint arXiv:2501.18362, 2025. 12 A Benchmark Statistics A.1 Per-lesion composition Table 4 reports the per-lesion composition of CheXpercept. Each lesion contributes...
Pith/arXiv arXiv 2025
-
[41]
38 Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.