WatchAct: A Benchmark for Behavior-Grounded Robot Manipulation
Pith reviewed 2026-06-26 01:08 UTC · model grok-4.3
The pith
The WatchAct benchmark shows that current robot systems achieve only 16.3% success when manipulation tasks require reasoning from human action videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
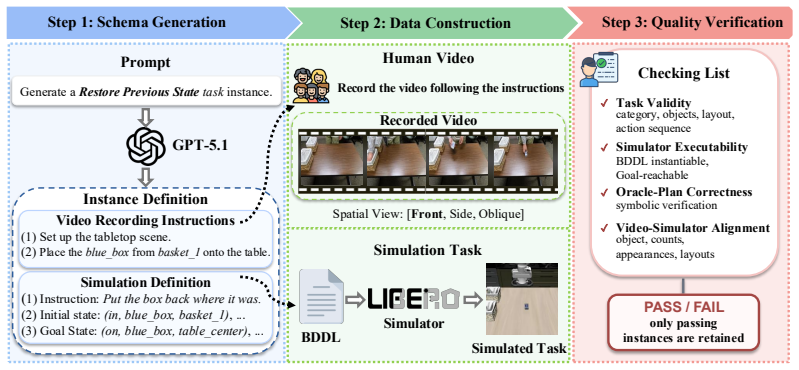
WatchAct provides 3000 long-horizon instances across 14 tasks in four cognitive domains drawn from watching another agent. The benchmark aligns videos with simulator scenes and executable tasks, allowing separate measurement of planning from video, execution under oracle plans, and full task completion. Current systems remain far from solving it, with the best pipeline at 16.3% success rate in simulation and 14.0% on the real robot.
What carries the argument
The WatchAct benchmark consisting of paired human-action videos and aligned LIBERO simulator tasks, together with the disentangled evaluation protocol that isolates video-to-plan reasoning, oracle-plan execution, and integrated planner-policy performance.
If this is right
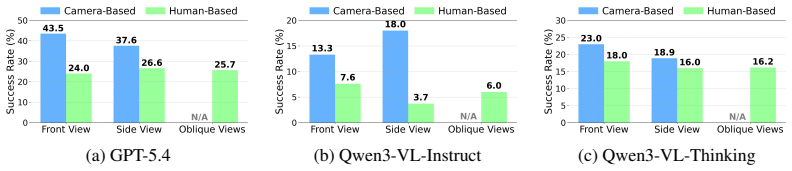
- Vision-language models attain 36.8% plan success rate on the benchmark compared to 97.1% for humans.
- Policy execution reaches 21.5% task success rate under oracle plans but falls to 10.6% in out-of-domain scenarios.
- The benchmark supports evaluation in both simulation and on physical robots using the same tasks.
- Four distinct capability domains test parsing events, recovering procedural structure, inferring unstated intent, and tracking scene changes.
Where Pith is reading between the lines
- If video-to-plan reasoning improves, it could raise overall task success when paired with better policies.
- Out-of-domain drops suggest that generalization from observed behavior remains a key challenge beyond the benchmark tasks.
- Alignment of video and simulator scenes may allow testing whether video understanding transfers directly to robot control.
- The focus on long-horizon tasks highlights the need for models that maintain memory of past actions across multiple steps.
Load-bearing premise
The 3000 instances and four capability domains accurately capture the cognitive demands of watching another agent and the evaluation protocol isolates those capabilities without biases in task selection or video-simulator alignment.
What would settle it
Demonstration of a pipeline that achieves over 50% success rate on the full task completion metric across both simulation and real-robot evaluations would indicate that current systems are closer to solving the benchmark than claimed.
Figures





read the original abstract
A robot working alongside people must reason about what they have done, in what order, and with what intent. Video carries the spatial layouts, object histories, and gestures that language leaves underspecified, yet today's manipulation benchmarks pair an instruction with a single current image, offering no way to evaluate reasoning over observed human behavior. We introduce WatchAct, a benchmark for robot manipulation grounded in observed human behavior. Each instance pairs a real-world human-action video and a language instruction with an aligned simulator scene and an executable LIBERO task, enabling scalable and reproducible evaluation. WatchAct comprises 3,000 long-horizon instances across 14 tasks in four capability domains drawn from the cognitive demands of watching another agent: parsing events (Event Grounding), recovering procedural structure (Procedural Reasoning), inferring unstated intent (Implicit Intent Inference), and tracking how the scene was changed (Episodic Reasoning). We further propose a disentangled evaluation protocol that separately measures (i)~video-to-plan reasoning by vision-language models, (ii)~policy execution under oracle plans, and (iii)~full task completion by integrated planner--policy pipelines. In both simulation and on a Franka Research 3 robot, current systems remain far from solving WatchAct. The best pipeline, Gemini-3.1-Pro with $\pi_{0.5}$, reaches only 16.3% Success Rate (SR) in simulation and 14.0% on the real robot. Gemini-3.1-Pro attains just 36.8% Plan SR (vs. 97.1% for humans), while $\pi_{0.5}$ reaches only 21.5% Task SR under oracle plans and drops to 10.6% on out-of-domain scenarios. Dataset and code are available at https://baiqi-li.github.io/watchact_page/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WatchAct, a benchmark of 3,000 long-horizon robot manipulation instances that pair real human-action videos and language instructions with aligned LIBERO simulator scenes. Instances span 14 tasks across four domains (Event Grounding, Procedural Reasoning, Implicit Intent Inference, Episodic Reasoning) drawn from the cognitive demands of observing another agent. A disentangled protocol separately evaluates VLM video-to-plan reasoning, policy execution under oracle plans, and end-to-end planner-policy pipelines. Experiments on simulation and a Franka Research 3 robot show current systems remain far from solving the benchmark, with the best pipeline (Gemini-3.1-Pro + π0.5) reaching 16.3% SR in simulation and 14.0% on the real robot; Gemini-3.1-Pro achieves 36.8% Plan SR (vs. 97.1% human) and π0.5 reaches 21.5% Task SR under oracle plans, dropping to 10.6% OOD. Dataset and code are released.
Significance. If the video-simulator alignments and task selection are valid, the benchmark and disentangled protocol would provide a reproducible, scalable testbed that isolates planning versus execution failures in behavior-grounded manipulation, a clear advance over instruction-only benchmarks. The public release of the 3,000 instances, code, and real-robot results strengthens potential impact for the field.
major comments (2)
- [§3 (dataset construction)] §3 (dataset construction) and abstract: The central claim that 'current systems remain far from solving WatchAct' (16.3% sim SR / 14.0% real SR) is load-bearing on the assumption that the 3,000 instances and four domains accurately capture the targeted cognitive demands without systematic bias from video-simulator misalignment, action ordering errors, or intent labeling. The manuscript reports no quantitative alignment error statistics, inter-annotator agreement on domain labels, or verification metrics for the 3,000 instances beyond the 10.6% OOD drop.
- [Evaluation protocol and results] Evaluation protocol description and results tables: The disentangled protocol (VLM Plan SR, oracle-plan policy SR, end-to-end SR) is presented as cleanly isolating capabilities, yet without reported checks on whether simulator state mismatches or video alignment failures differentially affect plan SR (36.8%) versus policy SR (21.5%), the attribution of low end-to-end performance to specific capability gaps remains unverified.
minor comments (1)
- [§3] Clarify the exact mapping between the 14 tasks and the four capability domains in the main text or a table for reader traceability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on dataset construction and the evaluation protocol. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [§3 (dataset construction)] §3 (dataset construction) and abstract: The central claim that 'current systems remain far from solving WatchAct' (16.3% sim SR / 14.0% real SR) is load-bearing on the assumption that the 3,000 instances and four domains accurately capture the targeted cognitive demands without systematic bias from video-simulator misalignment, action ordering errors, or intent labeling. The manuscript reports no quantitative alignment error statistics, inter-annotator agreement on domain labels, or verification metrics for the 3,000 instances beyond the 10.6% OOD drop.
Authors: We agree that explicit quantitative verification metrics would strengthen the central claim. The reported human Plan SR of 97.1% and the 10.6% OOD drop already provide evidence that the instances are well-defined and test the intended cognitive demands rather than alignment artifacts. However, to directly address the concern about potential biases, we will add to the revised manuscript: inter-annotator agreement on domain labels for a sampled subset and quantitative alignment error statistics from manual inspection of 100 random instances. These additions will be reported in §3. revision: yes
-
Referee: [Evaluation protocol and results] Evaluation protocol description and results tables: The disentangled protocol (VLM Plan SR, oracle-plan policy SR, end-to-end SR) is presented as cleanly isolating capabilities, yet without reported checks on whether simulator state mismatches or video alignment failures differentially affect plan SR (36.8%) versus policy SR (21.5%), the attribution of low end-to-end performance to specific capability gaps remains unverified.
Authors: Oracle plans are generated from the aligned simulator states and manually verified for executability, which limits differential impact from alignment failures on policy SR. The observed drops (plan SR 36.8% → oracle-policy SR 21.5% → end-to-end 16.3%) are consistent with separate gaps in reasoning and control. We nevertheless acknowledge the value of explicit verification. In the revision we will add a failure-mode analysis that categorizes errors by source (plan, execution, or alignment) to confirm the protocol's isolation holds. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivation chain
full rationale
The paper presents a new benchmark (WatchAct) consisting of 3000 video-simulator paired instances and reports empirical success rates for existing VLMs and policies. No equations, fitted parameters, predictions, or uniqueness theorems are claimed; the central result (16.3% sim / 14.0% real SR) is a direct measurement rather than a reduction to self-referential inputs. The disentangled protocol (plan SR, oracle-plan SR, end-to-end SR) is defined by construction from the benchmark instances without any self-citation load-bearing or ansatz smuggling. This is a standard empirical benchmark paper whose claims rest on external model performance, not internal circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ciocarlie, K
M. Ciocarlie, K. Hsiao, A. Leeper, and D. Gossow. Mobile manipulation through an assistive home robot. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5313–5320. IEEE, 2012
2012
-
[2]
J. Wu, R. Antonova, A. Kan, M. Lepert, A. Zeng, S. Song, J. Bohg, S. Rusinkiewicz, and T. Funkhouser. Tidybot: Personalized robot assistance with large language models.Autonomous Robots, 47(8):1087–1102, 2023
2023
-
[3]
E. A. Sisbot, L. F. Marin-Urias, R. Alami, and T. Simeon. A human aware mobile robot motion planner.IEEE Transactions on Robotics, 23(5):874–883, 2007
2007
-
[4]
J. M. Zacks and K. M. Swallow. Event segmentation.Current directions in psychological science, 16(2):80–84, 2007
2007
-
[5]
Csibra and G
G. Csibra and G. Gergely. Natural pedagogy.Trends in Cognitive Sciences, 13(4):148–153,
-
[6]
doi:10.1016/j.tics.2009.01.005
-
[7]
C. L. Baker, R. Saxe, and J. B. Tenenbaum. Action understanding as inverse planning.Cognition, 113(3):329–349, 2009. doi:10.1016/j.cognition.2009.07.005
-
[8]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36: 44776–44791, 2023
2023
-
[9]
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
Pith/arXiv arXiv 2024
-
[10]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[11]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, et al. Libero-plus: In- depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[12]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. Libero-pro: Towards robust and fair evaluation of vision-language-action models beyond memorization.arXiv preprint arXiv:2510.03827, 2025
Pith/arXiv arXiv 2025
-
[13]
Jiang, A
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan. Vima: General robot manipulation with multimodal prompts. InFortieth International Conference on Machine Learning, 2023
2023
-
[14]
B. Wang, J. Zhang, S. Dong, I. Fang, and C. Feng. Vlm see, robot do: Human demo video to robot action plan via vision language model. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 17215–17222. IEEE, 2025
2025
-
[15]
J. Son, J. Kim, K. Kam, J. Coholich, S. J. Kim, J. Kim, C. D. Kim, J. Cho, D. Fox, and Z. Kira. Seetraceact: Visibility-aware latent planning from cross-embodiment demonstration videos. arXiv preprint arXiv:2606.02745, 2026. 9
Pith/arXiv arXiv 2026
-
[16]
Y . Dai, H. Fu, J. Lee, Y . Liu, H. Zhang, J. Yang, C. Finn, N. Fazeli, and J. Chai. Robomme: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026
Pith/arXiv arXiv 2026
-
[17]
Y . Hong, J. Liu, H. Yin, M. Li, L. Guibas, L. Fei-Fei, J. Wu, and Y . Choi. ESI-Bench: Towards embodied spatial intelligence that closes the perception–action loop.arXiv preprint arXiv:2605.18746, 2026
Pith/arXiv arXiv 2026
-
[18]
Gemini 3.1 pro
Google. Gemini 3.1 pro. https://blog.google/innovation-and-ai/ models-and-research/gemini-models/gemini-3-1-pro/ , 2026. Accessed: 2026-05- 29
2026
-
[19]
Franka research 3
Franka Robotics. Franka research 3. https://franka.de/franka-research-3, 2026. Accessed: 2026-05-29
2026
-
[20]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Martin-Martin, C. Wang, G. Levine, W. Ai, B. Martinez, H. Yin, M. Lingelbach, M. Hwang, A. Hiranaka, S. Garlanka, A. Aydin, S. Lee, J. Sun, M. Anvari, M. Sharma, D. Bansal, S. Hunter, K.-Y . Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, Y . Li, S. Savarese, H. Gweon, C. ...
Pith/arXiv arXiv 2024
-
[21]
Zhang, Z
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jiang, et al. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11142–11152, 2025
2025
-
[22]
E. Cherepanov, N. Kachaev, A. K. Kovalev, and A. I. Panov. Memory, benchmark & robots: A benchmark for solving complex tasks with reinforcement learning.arXiv preprint arXiv:2502.10550, 2025
arXiv 2025
-
[23]
S. Han, B. Qiu, Y . Liao, S. Huang, C. Gao, S. Yan, and S. Liu. Robocerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation.arXiv preprint arXiv:2506.06677, 2025
arXiv 2025
-
[24]
Shridhar, J
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox. ALFRED: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10740–10749, 2020
2020
-
[25]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[26]
T. Chen, Y . Wang, M. Li, Y . Qin, H. Shi, Z. Li, Y . Hu, Y . Zhang, K. Wang, Y . Chen, et al. Rmbench: Memory-dependent robotic manipulation benchmark with insights into policy design. arXiv preprint arXiv:2603.01229, 2026
arXiv 2026
-
[27]
H. Fang, M. Grotz, W. Pumacay, Y . R. Wang, D. Fox, R. Krishna, and J. Duan. Sam2act: Integrating visual foundation model with a memory architecture for robotic manipulation.arXiv preprint arXiv:2501.18564, 2025
arXiv 2025
-
[28]
J. Li, Y . Zhu, Y . Xie, Z. Jiang, M. Seo, G. Pavlakos, and Y . Zhu. Okami: Teaching humanoid robots manipulation skills through single video imitation.arXiv preprint arXiv:2410.11792, 2024
arXiv 2024
-
[29]
Heppert, M
N. Heppert, M. Argus, T. Welschehold, T. Brox, and A. Valada. Ditto: Demonstration imitation by trajectory transformation. In2024 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 7565–7572. IEEE, 2024. 10
2024
-
[30]
S. Park, H. Bharadhwaj, and S. Tulsiani. Demodiffusion: One-shot human imitation using pre-trained diffusion policy.arXiv preprint arXiv:2506.20668, 2025
arXiv 2025
-
[31]
C. Wang, L. Fan, J. Sun, R. Zhang, L. Fei-Fei, D. Xu, Y . Zhu, and A. Anandkumar. MimicPlay: Long-horizon imitation learning by watching human play. InConference on Robot Learning (CoRL), 2023
2023
-
[32]
R. Shah, S. Liu, Q. Wang, Z. Jiang, S. Kumar, M. Seo, R. Martín-Martín, and Y . Zhu. Mimic- droid: In-context learning for humanoid manipulation from human play videos. 2026
2026
-
[33]
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. π0.5: A vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[34]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[35]
L. X. Shi, B. Ichter, M. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, et al. Hi robot: Open-ended instruction following with hierarchical vision-language- action models.arXiv preprint arXiv:2502.19417, 2025
Pith/arXiv arXiv 2025
-
[36]
Y . Li, Y . Deng, J. Zhang, J. Jang, M. Memmel, R. Yu, C. R. Garrett, F. Ramos, D. Fox, A. Li, A. Gupta, and A. Goyal. HAMSTER: Hierarchical action models for open-world robot manipulation. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[37]
Zhang, Y
J. Zhang, Y . Guo, X. Chen, Y .-J. Wang, Y . Hu, C. Shi, and J. Chen. HiRT: Enhancing robotic control with hierarchical robot transformers. InProceedings of the 8th Conference on Robot Learning (CoRL), volume 270 ofPMLR, pages 933–946, 2025
2025
-
[38]
Y . Yang, S. Gao, Q. Bu, L. Chen, and D. N. Metaxas. Seeing farther and smarter: Value-guided multi-path reflection for vlm policy optimization.arXiv preprint arXiv:2602.19372, 2026
arXiv 2026
-
[39]
C. A. Kurby and J. M. Zacks. Segmentation in the perception and memory of events.Trends in cognitive sciences, 12(2):72–79, 2008
2008
-
[40]
G. D. Abowd, A. K. Dey, P. J. Brown, N. Davies, M. Smith, and P. Steggles. Towards a better understanding of context and context-awareness. InInternational symposium on handheld and ubiquitous computing, pages 304–307. Springer, 1999
1999
-
[41]
Sebanz, H
N. Sebanz, H. Bekkering, and G. Knoblich. Joint action: bodies and minds moving together. Trends in cognitive sciences, 10(2):70–76, 2006
2006
-
[42]
R. A. Zwaan, M. C. Langston, and A. C. Graesser. The construction of situation models in narrative comprehension: An event-indexing model.Psychological science, 6(5):292–297, 1995
1995
-
[43]
R. C. Schank and R. P. Abelson.Scripts, plans, goals, and understanding: An inquiry into human knowledge structures. Psychology press, 2013
2013
-
[44]
Gpt-5.1 model
OpenAI. Gpt-5.1 model. https://developers.openai.com/api/docs/models/gpt-5. 1, 2026. Accessed: 2026-05-29
2026
-
[45]
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[46]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 11
Pith/arXiv arXiv 2025
-
[47]
Graesser and P
L. Graesser and P. Xu. Gemini robotics-er 1.6: Powering real-world robotics tasks through enhanced embodied reasoning. https://deepmind.google/blog/gemini-robotics-er-1-6/, Apr
-
[48]
Google DeepMind blog
-
[49]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[50]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[51]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[52]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945, 2024. 12 Appendix 1 Benchmark Details Benchmark Statistics.WatchAct comprises 3,000 instances across 14 tasks organized into fo...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.