Scoring Is Not Enough: Addressing Gaps in Utility-fairness Trade-offs for Ranking
Pith reviewed 2026-06-26 00:51 UTC · model grok-4.3
The pith
Scoring functions cannot achieve every utility-fairness trade-off in ranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
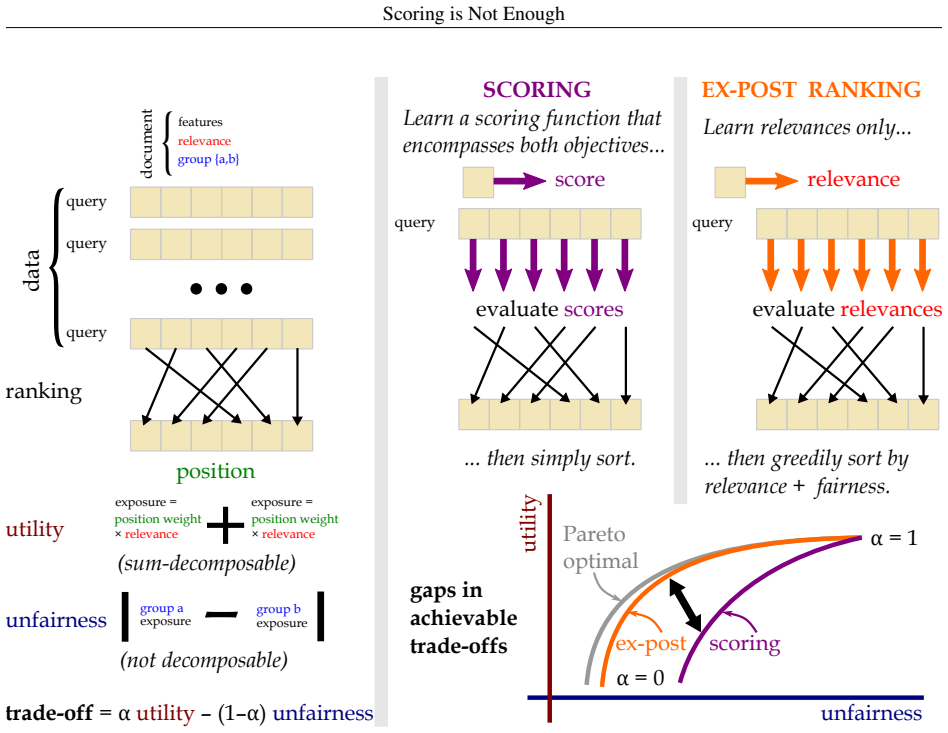
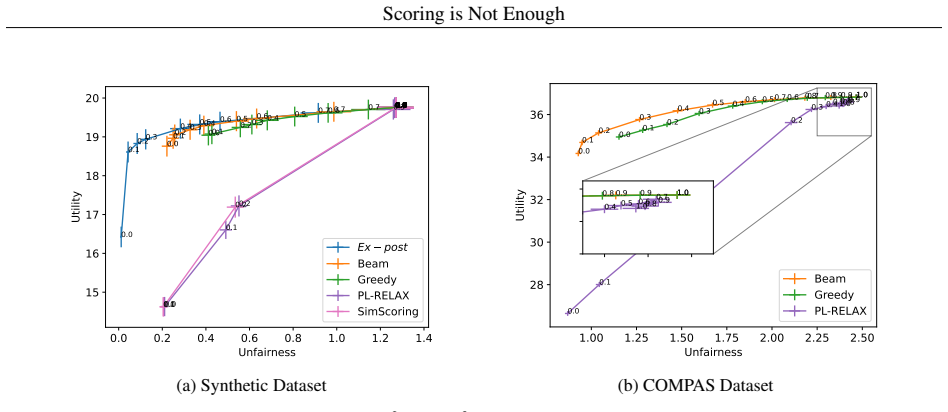
Scoring is sub-optimal in achieving all utility-fairness trade-offs. We establish this with a series of counter-examples with a generic fairness formulation. We show that the issue persists whether we have a deterministic scoring function or a randomized one, or whether we measure fairness at the scope of a single query or across multiple queries. On the positive side, we empirically demonstrate that semi-greedy post-processing has the potential to achieve much better trade-offs, often approaching the ideal of exhaustive post-processing in a tractable way.
What carries the argument
Counter-examples built on a generic fairness formulation that prove scoring functions are sub-optimal for the full set of utility-fairness trade-offs.
If this is right
- Deterministic scoring functions leave some utility-fairness pairs unreachable.
- Randomized scoring functions exhibit the same gaps.
- The gaps appear both when fairness is enforced on individual queries and when it is enforced across multiple queries.
- Semi-greedy post-processing can reach trade-off points that scoring cannot.
- Exhaustive post-processing sets an upper bound that semi-greedy methods often approach.
Where Pith is reading between the lines
- Ranking pipelines may need to move beyond score-based selection toward direct selection or re-ranking steps when fairness constraints are active.
- If many practical fairness definitions turn out to have extra structure, the reported gaps might shrink or disappear.
- Developers could test whether their current fairness metric admits scoring-based solutions before investing in post-processing layers.
Load-bearing premise
The generic fairness formulation used to build the counterexamples captures the fairness notions that actually appear in deployed ranking systems.
What would settle it
A concrete fairness definition drawn from a production ranking system for which every utility-fairness point can be realized by some scoring function would refute the claim of sub-optimality.
Figures
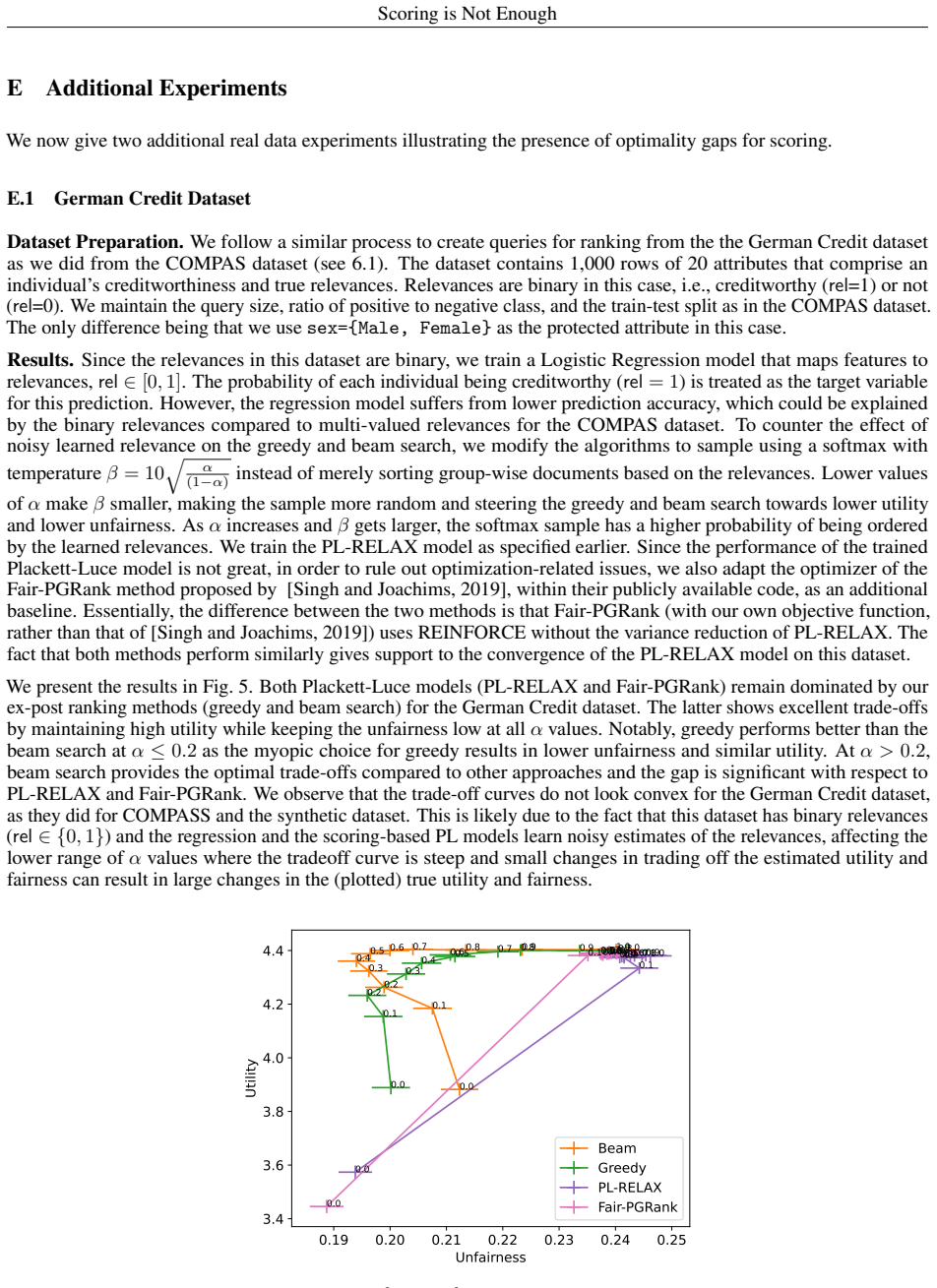
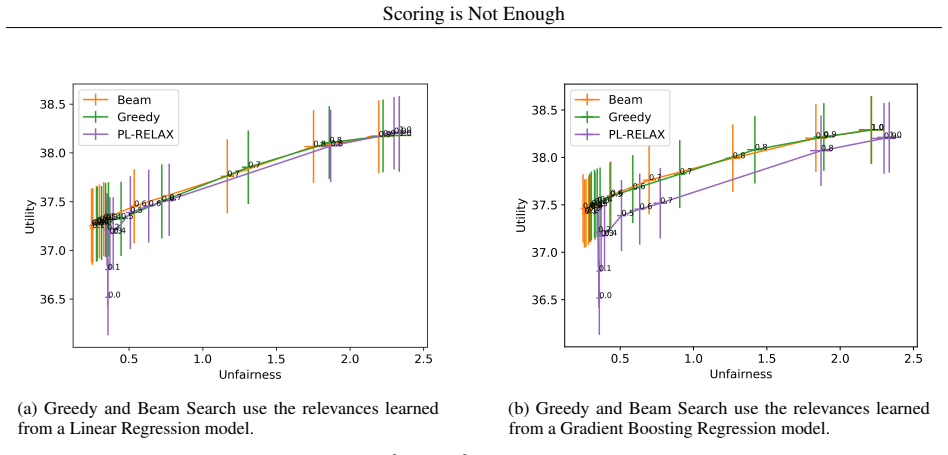
read the original abstract
Scoring functions are used to represent the relevance of individual documents. In modern information retrieval or recommendation systems, they are often learned from data and play a pivotal role in ranking sets of documents or items in a way that maximizes utility to a query or user. With the recent interest in algorithmic fairness, the success of scoring has naturally led to methods that learn scores that simultaneously trade off fairness and utility. In this work, we show that in stark contrast with utility-centric objectives, scoring is sub-optimal in achieving all utility-fairness trade-offs. We establish this with a series of counter-examples with a generic fairness formulation. We show that the issue persists whether we have a deterministic scoring function or a randomized one, or whether we measure fairness at the scope of a single query or across multiple queries. On the positive side, we empirically demonstrate that semi-greedy post-processing has the potential to achieve much better trade-offs, often approaching the ideal of exhaustive post-processing in a tractable way.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that scoring functions (deterministic or randomized) are sub-optimal for achieving the complete set of utility-fairness trade-offs in ranking. This is established via counterexamples under a generic fairness formulation, shown to hold for both single-query and multi-query settings. The authors additionally report that semi-greedy post-processing can achieve trade-offs approaching those of exhaustive search in a tractable manner.
Significance. If the result holds under fairness notions used in practice, the work identifies a structural limitation of score-based ranking that would require shifting from learned scores to direct optimization or post-processing for Pareto-optimal fairness-utility frontiers. The explicit counterexample approach (rather than parameter fitting) provides a clean, falsifiable demonstration of sub-optimality.
major comments (2)
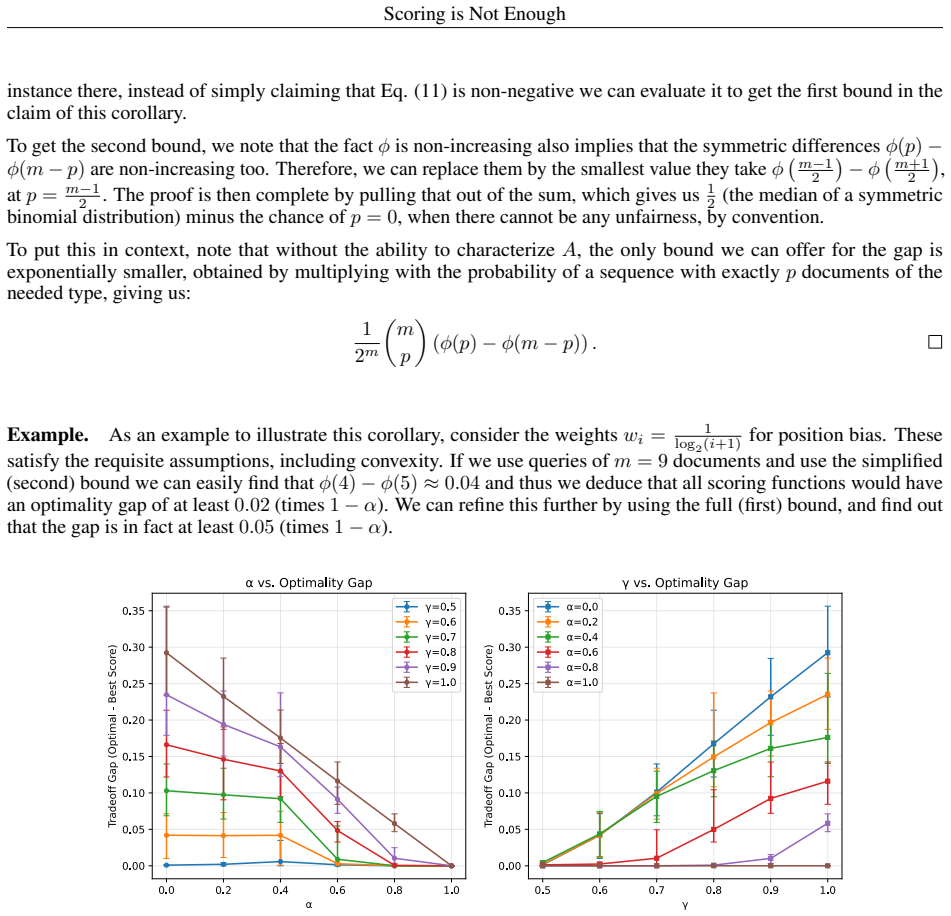
- [Counterexample construction and generic fairness formulation] The central claim rests on counterexamples constructed with a generic fairness formulation that permits arbitrary mappings from ranked lists to fairness values. Practical fairness notions (e.g., exposure disparity, demographic parity on protected groups, or listwise KL-divergence) typically impose additional structure such as monotonicity or dependence only on group proportions. It is not shown whether the constructed counterexamples remain feasible or the sub-optimality persists once these constraints are imposed; a concrete test would be to specialize the generic formulation to one of these deployed metrics and re-run the counterexamples.
- [Multi-query extension] The multi-query setting is addressed, but the paper does not specify how the generic fairness function aggregates across queries (e.g., whether it is a sum, average, or more complex set function). This aggregation choice directly affects whether the single-query counterexamples lift to the multi-query case without additional assumptions.
minor comments (2)
- [Preliminaries] Notation for the fairness function and utility should be introduced with an explicit definition before the counterexamples are presented.
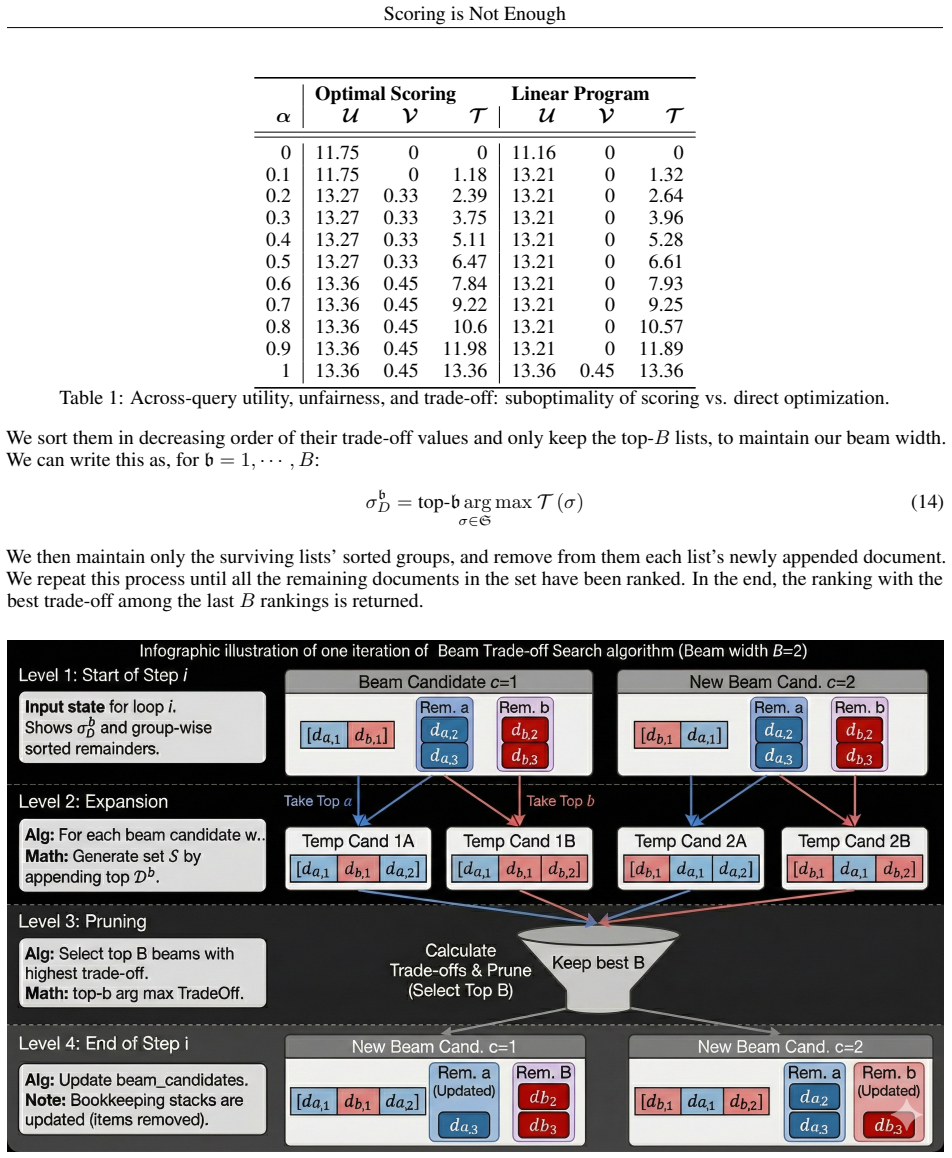
- [Empirical evaluation] The empirical section on semi-greedy post-processing would benefit from reporting the exact computational complexity relative to exhaustive search.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to clarify the scope and strengthen the empirical grounding of the results.
read point-by-point responses
-
Referee: [Counterexample construction and generic fairness formulation] The central claim rests on counterexamples constructed with a generic fairness formulation that permits arbitrary mappings from ranked lists to fairness values. Practical fairness notions (e.g., exposure disparity, demographic parity on protected groups, or listwise KL-divergence) typically impose additional structure such as monotonicity or dependence only on group proportions. It is not shown whether the constructed counterexamples remain feasible or the sub-optimality persists once these constraints are imposed; a concrete test would be to specialize the generic formulation to one of these deployed metrics and re-run the counterexamples.
Authors: The generic formulation establishes that scoring is structurally sub-optimal for achieving the full utility-fairness frontier even in the absence of metric-specific constraints. We agree that demonstrating persistence under practical metrics would increase relevance. We will revise the manuscript to specialize one counterexample to exposure disparity (a monotonic, group-proportion-based metric) and verify that the same scoring sub-optimality holds. revision: yes
-
Referee: [Multi-query extension] The multi-query setting is addressed, but the paper does not specify how the generic fairness function aggregates across queries (e.g., whether it is a sum, average, or more complex set function). This aggregation choice directly affects whether the single-query counterexamples lift to the multi-query case without additional assumptions.
Authors: We will add an explicit definition in the revised manuscript: multi-query fairness is the average of the per-query fairness values under the generic function. Under this aggregation the single-query counterexamples extend directly by replication across queries, without requiring further assumptions. revision: yes
Circularity Check
No circularity; claim established by explicit counterexamples
full rationale
The paper's central claim—that scoring functions are sub-optimal for achieving all utility-fairness trade-offs—is established via a series of constructed counter-examples under a generic fairness formulation. This is a direct theoretical argument by counterexample rather than any reduction to fitted parameters, self-definitional loops, or load-bearing self-citations. No equations or steps in the provided abstract reduce the result to its own inputs by construction. The approach is self-contained against external benchmarks (the counterexamples themselves) and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A generic fairness formulation exists that captures the relevant trade-offs for the counterexamples
Reference graph
Works this paper leans on
-
[1]
Equity and Access in Algorithms, Mechanisms, and Optimization , location =
Fair Decision-Making for Food Inspections , author =. Equity and Access in Algorithms, Mechanisms, and Optimization , location =. doi:10.1145/3551624.3555289 , isbn = 9781450394772, url =
-
[2]
1994 , howpublished =
Hofmann, Hans , title =. 1994 , howpublished =
1994
-
[3]
Agarwal, Aman and Wang, Xuanhui and Li, Cheng and Bendersky, Michael and Najork, Marc , year =. Addressing. The. doi:10.1145/3308558.3313697 , urldate =
-
[4]
Ai, Qingyao and Bi, Keping and Guo, Jiafeng and Croft, W. Bruce , year =. Learning a. The 41st. doi:10.1145/3209978.3209985 , urldate =
-
[5]
Ai, Qingyao and Wang, Xuanhui and Bruch, Sebastian and Golbandi, Nadav and Bendersky, Michael and Najork, Marc , year =. Learning. Proceedings of the 2019. doi:10.1145/3341981.3344218 , urldate =
-
[6]
Asudeh, Abolfazl and Jagadish, H. V. and Stoyanovich, Julia and Das, Gautam , year =. Designing. Proceedings of the 2019. doi:10.1145/3299869.3300079 , urldate =
-
[7]
Asudeh, Abolfazl and Jagadish, H. V. , year =. Responsible. arXiv , langid =:1911.10073 , primaryclass =
arXiv 1911
-
[8]
Bapat, R. B. and Beg, M. I. , year =. Order. Sankhy. 25050725 , eprinttype =
-
[9]
Benjaminson, Emma , urldate =. The
-
[10]
Beutel, Alex and Chen, Jilin and Doshi, Tulsee and Qian, Hai and Wei, Li and Wu, Yi and Heldt, Lukasz and Zhao, Zhe and Hong, Lichan and Chi, Ed H. and Goodrow, Cristos , year =. Fairness in. Proceedings of the 25th. doi:10.1145/3292500.3330745 , urldate =
-
[11]
Biega, Asia J. and Gummadi, Krishna P. and Weikum, Gerhard , year =. Equity of. The 41st. doi:10.1145/3209978.3210063 , urldate =
-
[12]
Individually
Bower, Amanda and Eftekhari, Hamid and Yurochkin, Mikhail and Sun, Yuekai , year =. Individually. International
-
[13]
2024 , month = jan, journal =
Bradley--. 2024 , month = jan, journal =
2024
-
[14]
Bruch, Sebastian and Han, Shuguang and Bendersky, Michael and Najork, Marc , year =. A. Proceedings of the 13th. doi:10.1145/3336191.3371844 , urldate =
-
[15]
Learning to
Burges, Christopher and Ragno, Robert and Le, Quoc , year =. Learning to. Advances in
-
[16]
Burges, Chris and Shaked, Tal and Renshaw, Erin and Lazier, Ari and Deeds, Matt and Hamilton, Nicole and Hullender, Greg , year =. Learning to. Proceedings of the 22nd International Conference on. doi:10.1145/1102351.1102363 , urldate =
-
[17]
Learning to Rank: From Pairwise Approach to Listwise Approach , shorttitle =
Cao, Zhe and Qin, Tao and Liu, Tie-Yan and Tsai, Ming-Feng and Li, Hang , year =. Learning to Rank: From Pairwise Approach to Listwise Approach , shorttitle =. Proceedings of the 24th International Conference on. doi:10.1145/1273496.1273513 , urldate =
-
[18]
Chen, Fumian and Fang, Hui , year =. Learn to Be. Proceedings of the 2023. doi:10.1145/3578337.3605132 , urldate =
-
[19]
Critchlow, Douglas E. and Fligner, Michael A. , year =. Paired Comparison, Triple Comparison, and Ranking Experiments as Generalized Linear Models, and Their Implementation on. Psychometrika , volume =. doi:10.1007/BF02294488 , urldate =
-
[20]
Gadetsky, Artyom and Struminsky, Kirill and Robinson, Christopher and Quadrianto, Novi and Vetrov, Dmitry , year =. Low-Variance. doi:10.48550/arXiv.1911.10036 , urldate =. arXiv , keywords =:1911.10036 , primaryclass =
-
[21]
, year =
Gey, Fredric C. , year =. Inferring Probability of Relevance Using the Method of Logistic Regression , booktitle =
-
[22]
Gorantla, Sruthi and Bhansali, Eshaan and Deshpande, Amit and Louis, Anand , year =. Optimizing. doi:10.48550/arXiv.2308.13242 , urldate =. arXiv , keywords =:2308.13242 , primaryclass =
-
[23]
Gorantla, Sruthi and Deshpande, Amit and Louis, Anand , year =. Sampling. Thirty-. doi:10.24963/ijcai.2023/46 , urldate =
- [24]
-
[25]
Backpropagation through the
Grathwohl, Will and Choi, Dami and Wu, Yuhuai and Roeder, Geoff and Duvenaud, David , year =. Backpropagation through the. International
-
[26]
2019 , month = sep, urldate =
The. 2019 , month = sep, urldate =
2019
-
[27]
Huijben, Iris A. M. and Kool, Wouter and Paulus, Max B. and. A. 2022 , month = mar, number =. doi:10.48550/arXiv.2110.01515 , urldate =. arXiv , keywords =:2110.01515 , primaryclass =
-
[28]
Javed, Syed Ashar , urldate =
-
[29]
Optimizing Search Engines Using Clickthrough Data , booktitle =
Joachims, Thorsten , year =. Optimizing Search Engines Using Clickthrough Data , booktitle =. doi:10.1145/775047.775067 , urldate =
-
[30]
K. Estimation of. Proceedings of the. 2021 , month = apr, series =. doi:10.1145/3442381.3450080 , urldate =
-
[31]
Estimating
Kool, Wouter and. Estimating. 2020 , journal =
2020
-
[32]
Derivative of the
Kurbiel, Thomas , year =. Derivative of the. Medium , urldate =
-
[33]
and Garg, Nikhil and Borgs, Christian , year =
Liu, Lydia T. and Garg, Nikhil and Borgs, Christian , year =. Strategic. arXiv:2109.08240 [cs] , eprint =
-
[34]
1959 , series =
Individual Choice Behavior , author =. 1959 , series =
1959
-
[35]
Carnegie Mellon University , langid =
Lowerre, Bruce T , year =. Carnegie Mellon University , langid =
-
[36]
Learning-to-
Ma, Jiaqi and Yi, Xinyang and Tang, Weijing and Zhao, Zhe and Hong, Lichan and Chi, Ed and Mei, Qiaozhu , year =. Learning-to-. Proceedings of
-
[37]
Memarrast, Omid and Rezaei, Ashkan and Fathony, Rizal and Ziebart, Brian , year =. Fairness for. doi:10.48550/arXiv.2112.06288 , urldate =. arXiv , keywords =:2112.06288 , primaryclass =
-
[38]
Mnih, Andriy and Gregor, Karol , year =. Neural. Proceedings of the 31st
-
[39]
Oosterhuis, Harrie , year =. Computationally. doi:10.48550/arXiv.2105.00855 , urldate =. arXiv , keywords =:2105.00855 , primaryclass =
-
[40]
Oosterhuis, Harrie , year =. Learning-to-. Proceedings of the 45th. doi:10.1145/3477495.3531842 , urldate =. arXiv , keywords =:2204.10872 , primaryclass =
-
[41]
Fairness of
Ovaisi, Zohreh and Saadatpanah, Parsa and Sefati, Shahin and Ohannessian, Mesrob and Zheleva, Elena , year =. Fairness of. ACM Transactions on Recommender Systems , doi =
-
[42]
Pang, Liang and Xu, Jun and Ai, Qingyao and Lan, Yanyan and Cheng, Xueqi and Wen, Jirong , year =. Proceedings of the 43rd. doi:10.1145/3397271.3401104 , urldate =
-
[43]
Plackett, R. L. , year =. The. Applied Statistics , volume =. doi:10.2307/2346567 , urldate =. 2346567 , eprinttype =
-
[44]
Rastogi, Richa and Joachims, Thorsten , year =. Fair. doi:10.48550/arXiv.2309.01610 , urldate =. arXiv , keywords =:2309.01610 , primaryclass =
-
[45]
Saito, Yuta and Joachims, Thorsten , year =. Fair. Proceedings of the 28th. doi:10.1145/3534678.3539353 , urldate =
-
[46]
Gradient Estimation Using Stochastic Computation Graphs , booktitle =
Schulman, John and Heess, Nicolas and Weber, Theophane and Abbeel, Pieter , year =. Gradient Estimation Using Stochastic Computation Graphs , booktitle =
-
[47]
Shafer, Glenn and Vovk, Vladimir , abstract =. A
-
[48]
Singh, Ashudeep and Joachims, Thorsten , year =. Fairness of. Proceedings of the 24th. doi:10.1145/3219819.3220088 , urldate =
-
[49]
Singh, Ashudeep and Joachims, Thorsten , pages =. Policy. 2019 , journal =
2019
-
[50]
Systems, Laboratory for Intelligent Probabilistic , year =. The. Laboratory for Intelligent Probabilistic Systems , urldate =
-
[51]
Markov-Based Ranking Methods , author =
-
[52]
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author =. 1992 , month = may, journal =. doi:10.1007/BF00992696 , urldate =
-
[53]
Xia, Tian and Zhai, Shaodan and Wang, Shaojun , year =. Plackett-. doi:10.48550/arXiv.1909.06722 , urldate =. arXiv , keywords =:1909.06722 , primaryclass =
-
[54]
Xu, Yunpeng and Guo, Wenge and Wei, Zhi , year =. Conformal. doi:10.48550/arXiv.2404.17769 , urldate =. arXiv , keywords =:2404.17769 , primaryclass =
-
[55]
Yang, Ke and Stoyanovich, Julia , year =. Measuring. Proceedings of the 29th. doi:10.1145/3085504.3085526 , urldate =
-
[56]
Zehlike, Meike and Yang, Ke and Stoyanovich, Julia , year =. Fairness in. ACM Computing Surveys , volume =. doi:10.1145/3533379 , urldate =
-
[57]
Zehlike, Meike and Yang, Ke and Stoyanovich, Julia , year =. Fairness in. ACM Computing Surveys , volume =. doi:10.1145/3533380 , urldate =
-
[58]
Zhang, Junzi and Kim, Jongho and O'Donoghue, Brendan and Boyd, Stephen , year =. Sample. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. doi:10.1609/aaai.v35i12.17300 , urldate =
-
[59]
arXiv preprint arXiv:2412.04466 , year=
User-item fairness tradeoffs in recommendations , author=. arXiv preprint arXiv:2412.04466 , year=
-
[60]
Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Probabilistic Permutation Graph Search: Black-Box Optimization for Fairness in Ranking , author=. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[61]
Bekta. Using. 2020 , month = aug, journal =. doi:10.1016/j.cor.2020.104975 , urldate =
-
[62]
Freitag, Markus and. Beam. Proceedings of the. 2017 , month = aug, pages =. doi:10.18653/v1/W17-3207 , urldate =
-
[63]
Proceedings of the fifteenth ACM international conference on web search and data mining , pages=
Toward Pareto efficient fairness-utility trade-off in recommendation through reinforcement learning , author=. Proceedings of the fifteenth ACM international conference on web search and data mining , pages=
-
[64]
Angwin, Julia and Larson, Jeff and Mattu, Surya and Kirchner, Lauren , year =. Machine
-
[65]
Fairness-aware ranking in search & recommendation systems with application to
Geyik, Sahin Cem and Ambler, Stuart and Kenthapadi, Krishnaram , booktitle=. Fairness-aware ranking in search & recommendation systems with application to
-
[66]
Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval , pages=
Measuring and mitigating item under-recommendation bias in personalized ranking systems , author=. Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval , pages=
-
[67]
Information Processing & Management , volume=
Toward creating a fairer ranking in search engine results , author=. Information Processing & Management , volume=. 2020 , publisher=
2020
-
[68]
Harper, F. Maxwell and Konstan, Joseph A. , year = 2016, month = jan, journal =. The. doi:10.1145/2827872 , urldate =
-
[69]
and Deldjoo, Yashar , year = 2022, month = jul, series =
Naghiaei, Mohammadmehdi and Rahmani, Hossein A. and Deldjoo, Yashar , year = 2022, month = jul, series =. Proceedings of the 45th. doi:10.1145/3477495.3531959 , urldate =
-
[70]
and Trichakis, Nikolaos , year = 2013, month = feb, journal =
Bertsimas, Dimitris and Farias, Vivek F. and Trichakis, Nikolaos , year = 2013, month = feb, journal =. Fairness,. doi:10.1287/opre.1120.1138 , urldate =
-
[71]
Cheng, Lingwei and Drayton, Cameron and Chouldechova, Alexandra and Vaithianathan, Rhema , editor =. Algorithm-. Proceedings of the. doi:10.1609/AIES.V7I1.31636 , urldate =
-
[72]
From. Proceedings of the 2017. doi:10.1145/3132847.3132869 , urldate =
-
[73]
Behzad, Tina and Devic, Siddartha and Sharan, Vatsal and Korolova, Aleksandra and Kempe, David , year = 2025, publisher =. An. doi:10.48550/ARXIV.2511.10752 , urldate =
-
[74]
Grbovic, Mihajlo and Cheng, Haibin , year = 2018, month = jul, series =. Real-Time. Proceedings of the 24th. doi:10.1145/3219819.3219885 , urldate =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.