A Primer in Post-Training Reasoning Data: What We Know About How It Works
Pith reviewed 2026-06-28 14:38 UTC · model grok-4.3
The pith
A four-question framework organizes the literature on post-training reasoning data to enable attribution of model gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
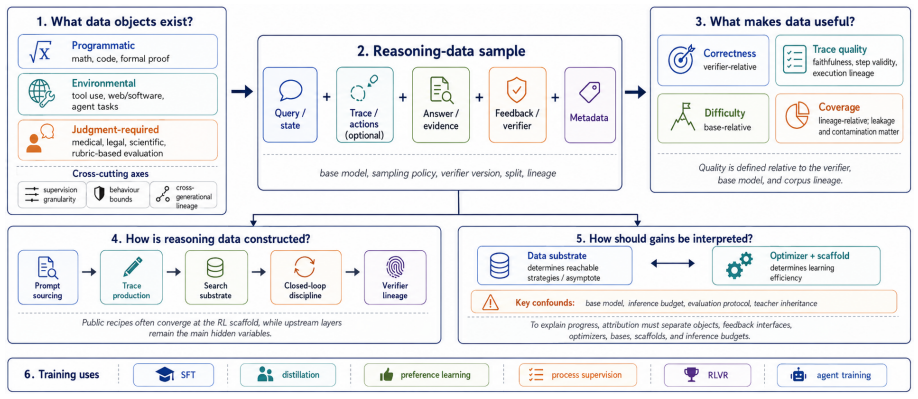
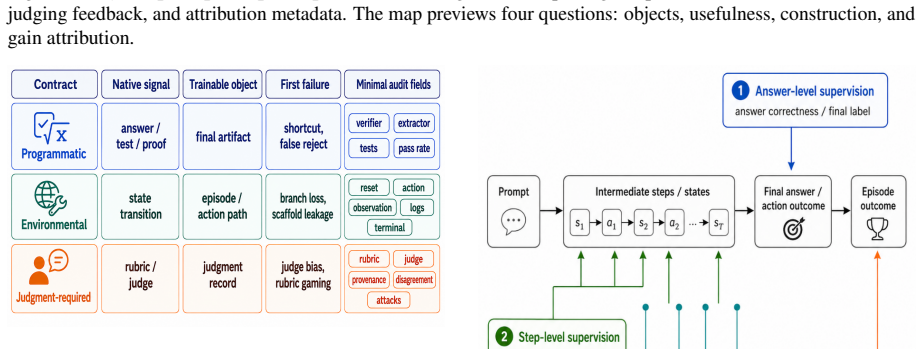
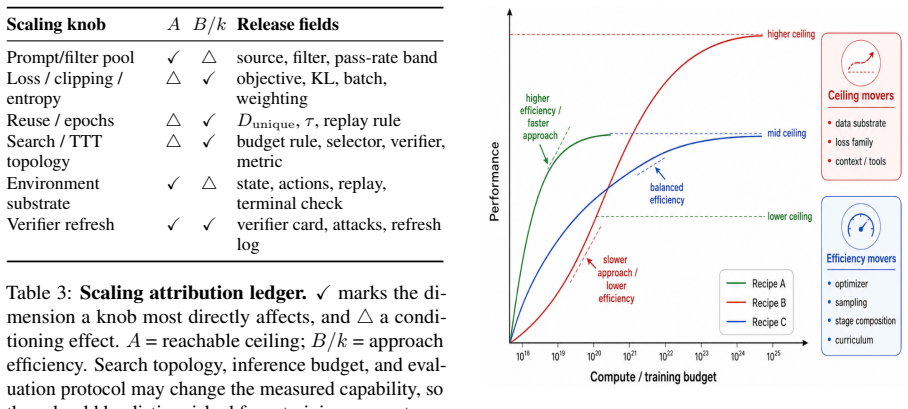
This paper claims to be the first primer that pulls together more than 150 studies across dataset papers, reinforcement-learning recipes, reward-model work, benchmarks, and frontier reports, then organizes them around four questions on data objects, usefulness, construction, and scaling to supply an attribution framework for future reasoning-data releases and post-training recipes.
What carries the argument
The four-question attribution framework that maps existing work onto data objects, usefulness, construction, and scaling.
If this is right
- New reasoning datasets can be released with explicit documentation against the four questions.
- Post-training recipes can diagnose success or failure by tracing back to specific data properties.
- Reward-model and benchmark papers can be compared using the same structure.
- Frontier system reports can be used to update or refine the framework over time.
Where Pith is reading between the lines
- The framework could be applied to test whether a proposed new dataset fills gaps across all four questions.
- Similar four-question structures might be tested on post-training data for alignment or safety tasks.
- Controlled experiments could check if data choices predicted to be useful by the framework actually produce larger gains.
Load-bearing premise
The selected set of over 150 studies is representative of the field and the four questions capture the load-bearing variables without omitting critical unexamined factors.
What would settle it
A new empirical study on post-training reasoning data whose results cannot be mapped to any of the four questions or whose outcomes contradict attributions made by the framework.
Figures




read the original abstract
Post-training has become a primary driver of recent progress in large reasoning models, and reasoning data are often the key variable determining whether this stage succeeds. Work on post-training reasoning data has grown rapidly, yet this literature remains scattered across dataset papers, reinforcement-learning recipes, reward-model studies, benchmarks, and frontier system reports. This paper is the first primer to synthesize over 150 key public studies and system reports on post-training reasoning data. We organize the field around four questions: what data objects exist, what makes them useful, how they are constructed, and how they scale. Together, this organization provides an attribution framework for future reasoning-data releases and post-training recipes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to be the first primer synthesizing over 150 key public studies and system reports on post-training reasoning data. It organizes the literature around four questions—what data objects exist, what makes them useful, how they are constructed, and how they scale—thereby providing an attribution framework for future reasoning-data releases and post-training recipes.
Significance. If the synthesis is accurate and representative and the four-question organization captures the dominant causal variables, the work would supply a structured overview of a rapidly expanding but scattered literature. This could help attribute performance gains in reasoning models to specific data choices and guide the design of future post-training pipelines. The breadth of coverage (over 150 studies) would be a notable strength if supported by transparent selection methods.
major comments (2)
- Introduction: The claim to synthesize 'over 150 key public studies' is presented without any disclosed literature search protocol, inclusion/exclusion criteria, or coverage audit. This is load-bearing for the central claim of delivering a representative attribution framework, because it leaves open whether studies on data contamination, multimodal reasoning data, or interactions with base-model pre-training distributions were systematically included or omitted.
- Four-question organization (sections describing data objects, usefulness, construction, and scaling): The framework does not explicitly examine interactions between post-training reasoning data and either the base model's pre-training distribution or reward-model specifics. If these interactions are load-bearing for reasoning performance, the attribution framework is incomplete by construction.
minor comments (1)
- Abstract and introduction: The target audience and the precise ways in which this primer differs from prior surveys on RLHF or general post-training could be stated more explicitly.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify opportunities to improve transparency and scope in our literature synthesis. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: Introduction: The claim to synthesize 'over 150 key public studies' is presented without any disclosed literature search protocol, inclusion/exclusion criteria, or coverage audit. This is load-bearing for the central claim of delivering a representative attribution framework, because it leaves open whether studies on data contamination, multimodal reasoning data, or interactions with base-model pre-training distributions were systematically included or omitted.
Authors: We agree that the absence of an explicit literature search protocol is a limitation. In the revised manuscript we will add a dedicated appendix (or methods subsection) that describes the search strategy, primary sources (arXiv, ACL/NeurIPS/ICLR proceedings, and system reports), inclusion criteria centered on post-training reasoning data, and a brief coverage audit. We will also note areas such as multimodal reasoning data and contamination studies that were included opportunistically rather than through exhaustive systematic review. revision: yes
-
Referee: Four-question organization (sections describing data objects, usefulness, construction, and scaling): The framework does not explicitly examine interactions between post-training reasoning data and either the base model's pre-training distribution or reward-model specifics. If these interactions are load-bearing for reasoning performance, the attribution framework is incomplete by construction.
Authors: The four-question structure is intentionally scoped to the properties and behaviors of the reasoning data itself. Interactions with pre-training distributions and reward models are referenced where supported by existing studies (particularly within the scaling and usefulness sections), but we concur that a more explicit treatment would strengthen the attribution claims. We will add a concise subsection on cross-stage interactions, drawing on available evidence, while preserving the primer's focus on post-training data. revision: yes
Circularity Check
No circularity: synthesis paper with no derivations or self-referential reductions
full rationale
The paper is a literature review that synthesizes over 150 existing studies and organizes them around four questions (data objects, usefulness, construction, scaling) to provide an attribution framework. It contains no equations, fitted parameters, predictions, or derivations that could reduce to inputs by construction. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing premises for any result. The central claim is the value of the organizational synthesis itself, which is independent of the paper's own inputs and does not match any of the enumerated circularity patterns. This is a self-contained review against external literature.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
RealClawBench: Live OpenClaw Benchmarks from Real Developer-Agent Sessions
RealClawBench turns 281 real OpenClaw sessions into reproducible tasks that preserve the original distribution and shows the best of 14 models solves only 65.8 percent.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.13388
R3: Robust rubric-agnostic reward models. arXiv preprint arXiv:2505.13388. Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Pre- ston Bowman, Joaquin Quiñonero-Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, An- drea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. 2025. Healthbench: Evaluating large language models towards improved ...
arXiv 2025
-
[2]
Distillation scaling laws.arXiv preprint arXiv:2502.08606. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, and 39 others
-
[3]
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374. Yixing Chen, Yiding Wang, Siqi Zhu, Haofei Yu, Tao Feng, Muhan Zhang, Mostofa Patwary, and Jiaxuan You. 2025. Multi-agent evolve: Llm self-improve through co-evolution.arXiv preprint arXiv:2510.23595. Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan L...
Pith/arXiv arXiv 2025
-
[4]
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2024. Ultrafeedback: Boosting language models with scaled ai feedback.arXiv preprint arXiv:2310.01377. Ganqu Cui, Lifan Yuan, Z...
Pith/arXiv arXiv 2024
-
[5]
Mind2web: Towards a generalist agent for the web.arXiv preprint arXiv:2306.06070. Yihong Dong, Xue Jiang, Yongding Tao, Huanyu Liu, Kechi Zhang, Lili Mou, Rongyu Cao, Yingwei Ma, 10 Jue Chen, Binhua Li, Zhi Jin, Fei Huang, Yongbin Li, and Ge Li. 2026. Rl-plus: Countering capability boundary collapse of llms in reinforcement learn- ing with hybrid-policy o...
Pith/arXiv arXiv 2026
-
[6]
Yixiong Fang, Tianran Sun, Yuling Shi, Min Wang, and Xiaodong Gu
Workarena: How capable are web agents at solving common knowledge work tasks?arXiv preprint arXiv:2403.07718. Yixiong Fang, Tianran Sun, Yuling Shi, Min Wang, and Xiaodong Gu. 2025. Lastingbench: Defend bench- marks against knowledge leakage.arXiv preprint arXiv:2506.21614. Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D. Goodma...
Pith/arXiv arXiv 2025
-
[7]
Rubrics as rewards: Reinforcement learn- ing beyond verifiable domains.arXiv preprint arXiv:2507.17746. Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. 2024. Wildguard: Open one-stop mod- eration tools for safety risks, jailbreaks, and refusals of llms.arXiv preprint arXiv:2406.18495. Zi...
Pith/arXiv arXiv 2024
-
[8]
arXiv preprint arXiv:2602.00846
Omni-rrm: Advancing omni reward modeling via automatic rubric-grounded preference synthesis. arXiv preprint arXiv:2602.00846. Masahiro Koreeda and Christopher Manning. 2021. Contractnli: A dataset for document-level natural language inference for contracts. InEMNLP. Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Ch...
arXiv 2021
-
[9]
Stephanie Lin, Jacob Hilton, and Owain Evans
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Truthfulqa: Measuring how models mimic human falsehoods.arXiv preprint arXiv:2109.07958. Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui- Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, Jiayun Wu, Jiri Gesi, Ximing Lu, Dav...
Pith/arXiv arXiv 2022
-
[10]
arXiv preprint arXiv:2410.05229
Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229. Mistral-AI, :, Abhinav Rastogi, Albert Q. Jiang, Andy Lo, Gabrielle Berrada, Guillaume Lample, Jason Rute, Joep Barmentlo, Karmesh Yadav, Kartik Khan- delwal, Khyathi Raghavi Chandu, Léonard Blier, Lu- cile Saulnier, Matthieu Di...
-
[11]
Kaixiang Mo, Yuxin Shi, Weiwei Weng, Zhiqiang Zhou, Shuman Liu, Haibo Zhang, and Anxiang Zeng
Magistral.arXiv preprint arXiv:2506.10910. Kaixiang Mo, Yuxin Shi, Weiwei Weng, Zhiqiang Zhou, Shuman Liu, Haibo Zhang, and Anxiang Zeng. 2025. Mid-training of large language models: A survey. arXiv preprint arXiv:2510.06826. Ivan Moshkov, Darragh Hanley, Ivan Sorokin, Shubham Toshniwal, Christof Henkel, Benedikt Schifferer, Wei Du, and Igor Gitman. 2025....
arXiv 2025
-
[12]
Androidworld: A dynamic benchmarking en- vironment for autonomous agents.arXiv preprint arXiv:2405.14573. David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Di- rani, Julian Michael, and Samuel R. Bowman. 2023. Gpqa: A graduate-level google-proof q&a bench- mark.arXiv preprint arXiv:2311.12022. Z. Z. Ren, Zhihong S...
Pith/arXiv arXiv 2023
-
[13]
arXiv preprint arXiv:2407.18901
Appworld: A controllable world of apps and people for benchmarking interactive coding agents. arXiv preprint arXiv:2407.18901. George Tsatsaronis, Georgios Balikas, Prodromos Malakasiotis, Ioannis Partalas, Matthias Zschunke, Michael R. Alvers, Dirk Weissenborn, Anastasia Krithara, Sergios Petridis, Dimitris Polychronopou- los, Yannis Almirantis, John Pav...
arXiv 2015
-
[14]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F
Math-shepherd: Verify and reinforce llms step- by-step without human annotations.arXiv preprint arXiv:2312.08935. Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyu...
Pith/arXiv arXiv 2025
-
[15]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang
Naturalreasoning: Reasoning in the wild with 2.8m challenging questions.arXiv preprint arXiv:2502.13124. Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. 2025. Does reinforcement learning really incentivize rea- soning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837. 16 Eric Zelikman, Yu...
arXiv 2025
-
[16]
InThe Tenth In- ternational Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022
minif2f: a cross-system benchmark for for- mal olympiad-level mathematics. InThe Tenth In- ternational Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. Open- Review.net. Lucia Zheng, Neel Guha, Brandon R. Anderson, Peter Henderson, and Daniel E. Ho. 2021. When does pre- training help?: assessing self-supervised learning...
2022
-
[17]
OpenReview.net. Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. 2021. Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance.arXiv preprint arXiv:2105.07624. Lianghui Zhu, Xinggang Wang, and Xinlong Wang
arXiv 2021
-
[18]
Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631. Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, Thong Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kad- dour, Ming Xu, Zhihan ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.