VERITAS: Verifier-Guided Proof Search for Zero-Shot Formal Theorem Proving
Pith reviewed 2026-06-26 21:36 UTC · model grok-4.3
The pith
VERITAS reaches 40.6% on miniF2F by routing verifier signals into critic-guided MCTS after Best-of-N sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
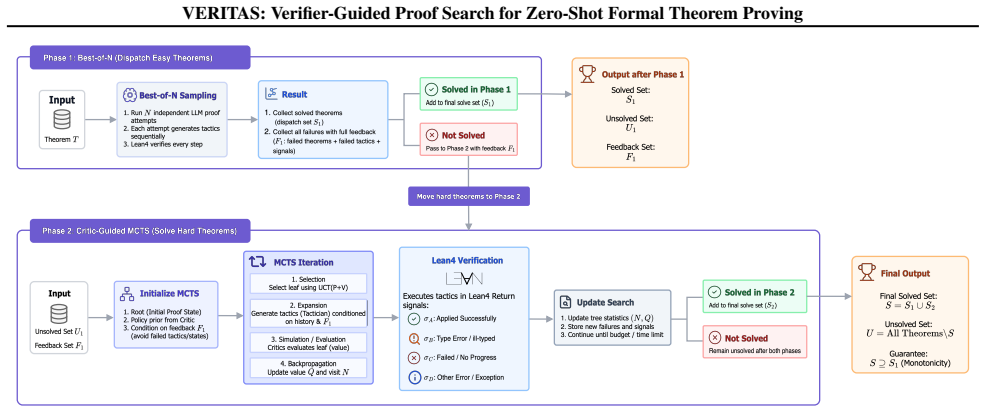
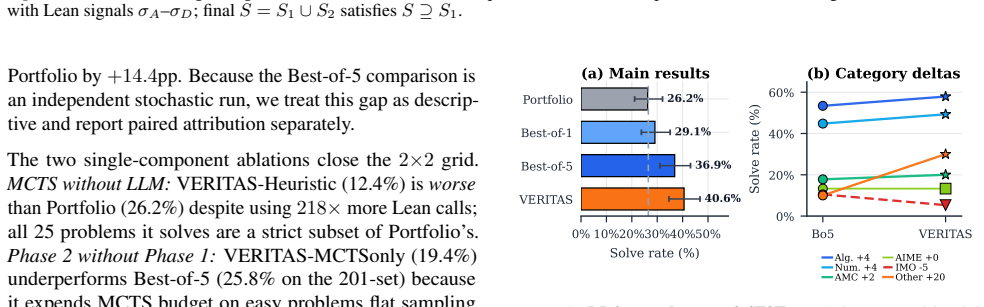
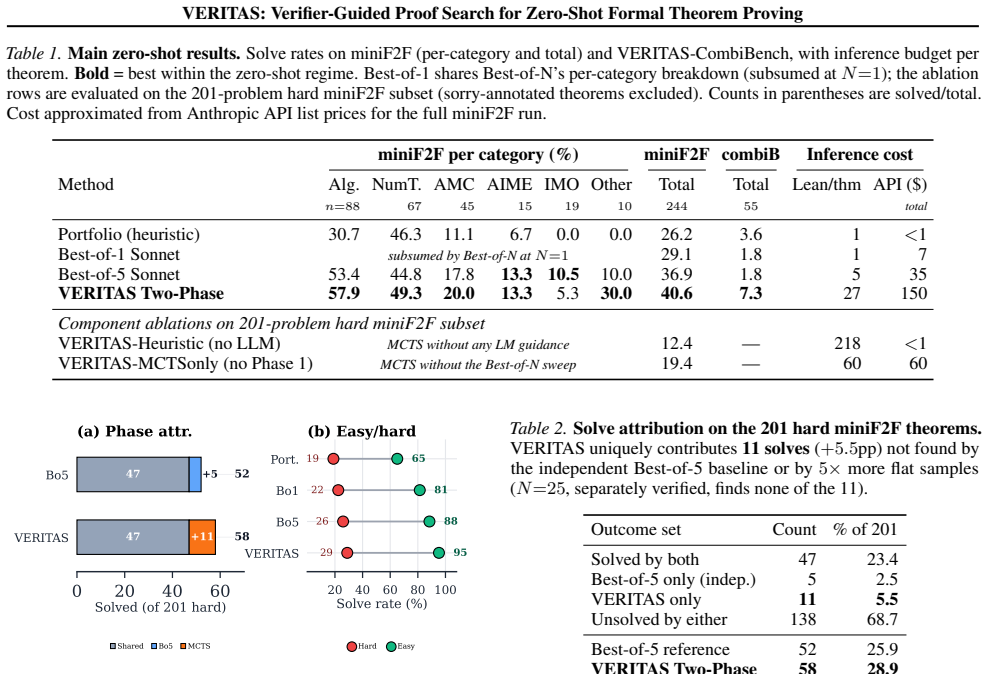
The central claim is that a two-phase zero-shot protocol—Best-of-N sampling followed by a critic that converts Phase-1 verifier failures (syntax errors, type mismatches, partial progress) into explicit negative examples for MCTS—produces additional proofs while preserving all Phase-1 solves, reaching 40.6% on miniF2F and 7.3% on the new VERITAS-CombiBench where Best-of-5 falls to 1.8%.
What carries the argument
The two-phase protocol that ingests every verifier signal as negative examples for critic-guided MCTS after an initial Best-of-N sweep.
If this is right
- Theorems solved by the initial Best-of-N sweep are guaranteed to stay solved after the MCTS pass.
- Unguided sampling underperforms when the correct lemma names must be recovered iteratively from successive verifier messages.
- The released 55-theorem combinatorics benchmark exposes the gap between Best-of-5 and Portfolio methods under feedback-driven conditions.
- Rich verifier signals (syntax, types, partial goals) can be used directly as training signals for the critic without additional human annotation.
Where Pith is reading between the lines
- The same two-phase routing of verifier signals could be tested on other interactive theorem provers that already expose detailed error messages.
- Releasing the combinatorics benchmark creates a controlled setting for measuring how well different search methods recover lemma sequences over multiple turns.
- If the critic can be replaced by a lighter rule-based extractor of failure patterns, the method might run with lower overhead while retaining the reported gains.
Load-bearing premise
A critic model can reliably turn Phase-1 verifier failure signals into useful negative examples that improve MCTS exploration without introducing bias or inefficiency that erases the gains.
What would settle it
Ablating the negative examples derived from Phase-1 failures and measuring whether the additional solves on miniF2F and VERITAS-CombiBench disappear while Phase-1 solves remain unchanged.
Figures

read the original abstract
LLM-based formal provers often collapse rich verifier signals (syntax errors, type mismatches, partial goal progress) into a binary pass/fail bit. We present VERITAS, a zero-shot framework that routes every verifier signal back into proof search through a two-phase protocol: Best-of-N sampling first, then a critic-guided MCTS pass that ingests Phase 1 failures as explicit negative examples. The protocol preserves every theorem solved by its own Phase 1 sweep, so Phase 2's additional solves are attributable to feedback-driven exploration. VERITAS reaches 40.6% on miniF2F (vs. an independently run Best-of-5 at 36.9%, Portfolio 26.2%) and 7.3% on VERITAS-CombiBench, a 55-theorem combinatorics benchmark we release on which Best-of-5 (1.8%) falls below Portfolio (3.6%), exposing that unguided sampling hurts when correct lemma names must be recovered iteratively from verifier feedback. Artifacts are available on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents VERITAS, a zero-shot LLM-based formal theorem proving framework using a two-phase protocol: Best-of-N sampling followed by critic-guided MCTS that ingests Phase-1 verifier failure signals (syntax errors, type mismatches, partial goals) as explicit negative examples. The protocol is designed to preserve all Phase-1 solves so that any additional solves in Phase 2 are attributable to feedback-driven exploration. It reports 40.6% on miniF2F (vs. independently run Best-of-5 at 36.9% and Portfolio at 26.2%) and 7.3% on the released 55-theorem VERITAS-CombiBench (vs. Best-of-5 at 1.8% and Portfolio at 3.6%), with GitHub artifacts provided.
Significance. If the central performance claims hold, the work demonstrates the value of routing rich verifier signals into search rather than collapsing them to binary outcomes, particularly in combinatorics where iterative lemma recovery benefits from guided exploration. The release of VERITAS-CombiBench and the preservation of Phase-1 solves are concrete strengths that enable direct attribution and community reuse.
major comments (2)
- [Methods (Phase-2 protocol)] The description of the critic (how verifier outputs are mapped to negative examples for MCTS) lacks an ablation that removes the critic while exactly matching Phase-2 search budget; without this, the attribution of the 3.7-point miniF2F gain and the CombiBench delta specifically to feedback-driven exploration cannot be isolated from additional search effort.
- [Experimental setup and critic implementation] No details are provided on the critic's prompt template, whether it is zero-shot or fine-tuned, or how negative-example construction avoids systematic bias across proof states (e.g., over-penalizing viable branches with certain lemma styles); this directly affects the weakest assumption that the critic reliably improves exploration without erasing net gains.
minor comments (2)
- [Abstract] The abstract states that artifacts are available on GitHub; the manuscript should include a direct link and a brief description of what is released (models, prompts, benchmark theorems).
- [Results] Table or figure reporting per-theorem results on CombiBench would help readers assess whether the 7.3% aggregate reflects broad improvement or concentration on a few theorems.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the strengths of our work, including the preservation of Phase-1 solves and the release of VERITAS-CombiBench. We respond point-by-point to the major comments below and commit to revisions that directly address the concerns raised.
read point-by-point responses
-
Referee: [Methods (Phase-2 protocol)] The description of the critic (how verifier outputs are mapped to negative examples for MCTS) lacks an ablation that removes the critic while exactly matching Phase-2 search budget; without this, the attribution of the 3.7-point miniF2F gain and the CombiBench delta specifically to feedback-driven exploration cannot be isolated from additional search effort.
Authors: We agree that an ablation isolating the critic's contribution while exactly matching the Phase-2 search budget would strengthen attribution of the observed gains. In the revised manuscript we will add this ablation: Phase-2 will be re-run with the identical number of MCTS simulations and node expansions but without the critic (using uniform selection or a non-feedback baseline), and we will report the resulting solve rates on both miniF2F and VERITAS-CombiBench. This will allow direct comparison and clarify how much of the 3.7-point and CombiBench deltas are due to feedback-driven exploration versus additional search effort. revision: yes
-
Referee: [Experimental setup and critic implementation] No details are provided on the critic's prompt template, whether it is zero-shot or fine-tuned, or how negative-example construction avoids systematic bias across proof states (e.g., over-penalizing viable branches with certain lemma styles); this directly affects the weakest assumption that the critic reliably improves exploration without erasing net gains.
Authors: The critic is implemented as a zero-shot prompt to the same base LLM used elsewhere in the framework; no fine-tuning occurs. We will include the complete prompt template in the appendix of the revised manuscript. Negative examples are constructed by extracting only the specific failed tactic or lemma name from the verifier output and marking solely that branch as negative for the MCTS value function. The prompt is localized to the current proof state and error type, avoiding global penalties. We will add a brief discussion of potential biases (including lemma-style effects) and the design choices intended to limit them. revision: yes
Circularity Check
No circularity: empirical comparisons only
full rationale
The paper reports direct empirical results on miniF2F and a new benchmark using a two-phase protocol versus independently run baselines (Best-of-5, Portfolio). No equations, fitted parameters, or derivations are present that could reduce to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing. The central claims rest on observable performance deltas, which are externally falsifiable and self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zheng, Kunhao and Han, Jesse Michael and Polu, Stanislas , booktitle =
-
[2]
arXiv preprint arXiv:2009.03393 , year =
Generative Language Modeling for Automated Theorem Proving , author =. arXiv preprint arXiv:2009.03393 , year =
Pith/arXiv arXiv 2009
-
[3]
Yang, Kaiyu and Swope, Aidan M and Gu, Alex and Chalamala, Rahul and Song, Peiyang and Yu, Shixing and Godil, Saad and Prenger, Ryan and Anandkumar, Anima , booktitle =
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Lample, Guillaume and Lachaux, Marie-Anne and Lavril, Thibaut and Martinet, Xavier and Hayat, Amaury and Ebner, Gabriel and Rodriguez, Aur. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[5]
and Li, Wenda and Tworkowski, Szymon and Czechowski, Konrad and Odrzyg
Jiang, Albert Q. and Li, Wenda and Tworkowski, Szymon and Czechowski, Konrad and Odrzyg. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[6]
Wang, Haiming and Xin, Huajian and Zheng, Chuanyang and Li, Lin and Liu, Zhengying and Cao, Qingxing and Huang, Yinya and Xiong, Jing and Shi, Han and Xie, Enze and Yin, Jian and Li, Zhenguo and Liao, Heng and Liang, Xiaodan , booktitle =
-
[7]
Wu, Zijian and Huang, Suozhi and Zhou, Zhejian and Ying, Huaiyuan and Wang, Jiayu and Lin, Dahua and Chen, Kai , journal =
-
[8]
Ren, Z. Z. and Shao, Zhihong and Song, Junxiao and Xin, Huajian and Wang, Haocheng and Zhao, Wanjia and Zhang, Liyue and Fu, Zhe and Zhu, Qihao and Yang, Dejian and Wu, Z. F. and Gou, Zhibin and Ma, Shirong and Tang, Hongxuan and Liu, Yuxuan and Gao, Wenjun and Guo, Daya and Ruan, Chong , journal =
-
[9]
2024 , howpublished =
2024
-
[10]
First Conference on Language Modeling (COLM) , year =
An In-Context Learning Agent for Formal Theorem-Proving , author =. First Conference on Language Modeling (COLM) , year =
-
[11]
Kumarappan, Adarsh and Tiwari, Mo and Song, Peiyang and George, Robert Joseph and Xiao, Chaowei and Anandkumar, Anima , booktitle =
-
[12]
and Deng, Jia and Biderman, Stella and Welleck, Sean , booktitle =
Azerbayev, Zhangir and Schoelkopf, Hailey and Paster, Keiran and Dos Santos, Marco and McAleer, Stephen and Jiang, Albert Q. and Deng, Jia and Biderman, Stella and Welleck, Sean , booktitle =
-
[13]
and Radev, Dragomir and Avigad, Jeremy , journal =
Azerbayev, Zhangir and Piotrowski, Bartosz and Schoelkopf, Hailey and Ayers, Edward W. and Radev, Dragomir and Avigad, Jeremy , journal =
-
[14]
Xin, Huajian and Guo, Daya and Shao, Zhihong and Ren, Z. Z. and Zhu, Qihao and Liu, Bo and Ruan, Chong and Li, Wenda and Liang, Xiaodan , journal =
-
[15]
Xin, Huajian and Ren, Z. Z. and Song, Junxiao and Shao, Zhihong and Zhao, Wanjia and Wang, Haocheng and Liu, Bo and Zhang, Liyue and Lu, Xuan and Du, Qiushi and Gao, Wenjun and Zhang, Haowei and Zhu, Qihao and Yang, Dejian and Gou, Zhibin and Wu, Z. F. and Luo, Fuli and Ruan, Chong , booktitle =
-
[16]
Lin, Yong and Tang, Shange and Lyu, Bohan and Wu, Jiayun and Lin, Hongzhou and Yang, Kaiyu and Li, Jia and Xia, Mengzhou and Chen, Danqi and Arora, Sanjeev and Jin, Chi , journal =
-
[17]
International Conference on Learning Representations (ICLR) , year =
Proof Artifact Co-Training for Theorem Proving with Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[18]
International Conference on Machine Learning (ICML) , year =
Formal Mathematics Statement Curriculum Learning , author =. International Conference on Machine Learning (ICML) , year =
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Autoformalization with Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[20]
International Conference on Learning Representations (ICLR) , year =
Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs , author =. International Conference on Learning Representations (ICLR) , year =
-
[21]
Proceedings of the 12th ACM SIGPLAN International Conference on Certified Programs and Proofs (CPP) , pages =
Limperg, Jannis and From, Asta Halkj. Proceedings of the 12th ACM SIGPLAN International Conference on Certified Programs and Proofs (CPP) , pages =
-
[22]
de Moura, Leonardo and Ullrich, Sebastian , booktitle =. The. 2021 , publisher =
2021
-
[23]
Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs (CPP) , pages =
The. Proceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs (CPP) , pages =
-
[24]
International Conference on Machine Learning (ICML) , pages =
Learning to Prove Theorems via Interacting with Proof Assistants , author =. International Conference on Machine Learning (ICML) , pages =
-
[25]
Huang, Daniel and Dhariwal, Prafulla and Song, Dawn and Sutskever, Ilya , booktitle =
-
[26]
and Rabe, Markus N
Bansal, Kshitij and Loos, Sarah M. and Rabe, Markus N. and Szegedy, Christian and Wilcox, Stewart , booktitle =
-
[27]
Bandit Based
Kocsis, Levente and Szepesv. Bandit Based. 17th European Conference on Machine Learning (ECML) , pages =
-
[28]
Machine Learning , volume =
Finite-Time Analysis of the Multiarmed Bandit Problem , author =. Machine Learning , volume =
-
[29]
A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and
Silver, David and Hubert, Thomas and Schrittwieser, Julian and Antonoglou, Ioannis and Lai, Matthew and Guez, Arthur and Lanctot, Marc and Sifre, Laurent and Kumaran, Dharshan and Graepel, Thore and Lillicrap, Timothy and Simonyan, Karen and Hassabis, Demis , journal =. A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and
-
[30]
Nature , volume =
Solving Olympiad Geometry Without Human Demonstrations , author =. Nature , volume =
-
[31]
Chervonyi, Yuri and Trinh, Trieu H. and Ol. Gold-medalist Performance in Solving Olympiad Geometry with. arXiv preprint arXiv:2502.03544 , year =
-
[32]
International Conference on Learning Representations (ICLR) , year =
Let's Verify Step by Step , author =. International Conference on Learning Representations (ICLR) , year =
-
[33]
arXiv preprint arXiv:2110.14168 , year =
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
-
[34]
arXiv preprint arXiv:2211.14275 , year =
Solving Math Word Problems with Process- and Outcome-Based Feedback , author =. arXiv preprint arXiv:2211.14275 , year =
-
[35]
Fang, Zihan and Zhang, Yifan and Zhang, Yueke and Leach, Kevin and Huang, Yu , journal =
-
[36]
Shinn, Noah and Cassano, Federico and Berman, Edward and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , booktitle =
-
[37]
Zhang, Yifan and Li, Jieyu and Pei, Kexin and Huang, Yu and Leach, Kevin , journal =
-
[38]
Zhang, Yueke and Zhang, Yifan and Leach, Kevin and Huang, Yu , journal =
-
[39]
International Conference on Learning Representations (ICLR) , year =
Generating Sequences by Learning to Self-Correct , author =. International Conference on Learning Representations (ICLR) , year =
-
[40]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[41]
International Conference on Learning Representations (ICLR) , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[42]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[43]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =
-
[44]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Large Language Models are Zero-Shot Reasoners , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[45]
Measuring Mathematical Problem Solving with the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving with the
-
[46]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Solving Quantitative Reasoning Problems with Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[47]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , journal =
-
[48]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Zhang, Ruoyu and Xu, Runxin and Zhu, Qihao and Ma, Shirong and Wang, Peiyi and Bi, Xiao and others , journal =
-
[49]
International Conference on Learning Representations (ICLR) , year =
Hong, Sirui and Zhuge, Mingchen and Chen, Jiaqi and Zheng, Xiawu and Cheng, Yuheng and Zhang, Ceyao and Wang, Jinlin and Wang, Zili and Yau, Steven Ka Shing and Lin, Zijuan and Zhou, Liyang and Ran, Chenyu and Xiao, Lingfeng and Wu, Chenglin and Schmidhuber, J. International Conference on Learning Representations (ICLR) , year =
-
[50]
and Burger, Doug and Wang, Chi , booktitle =
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and Awadallah, Ahmed Hassan and White, Ryen W. and Burger, Doug and Wang, Chi , booktitle =
-
[51]
Zhang, Yifan and Ganapavarapu, Giridhar and Jayaraman, Srideepika and Agrawal, Bhavna and Patel, Dhaval and Fokoue, Achille , booktitle =
-
[52]
Li, Guohao and Hammoud, Hasan Abed Al Kader and Itani, Hani and Khizbullin, Dmitrii and Ghanem, Bernard , booktitle =
-
[53]
Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author =. Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[54]
arXiv preprint arXiv:2107.03374 , year =
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , year =
-
[55]
Competition-Level Code Generation with
Li, Yujia and Choi, David and Chung, Junyoung and Kushman, Nate and Schrittwieser, Julian and Leblond, R. Competition-Level Code Generation with. Science , volume =
-
[56]
Rozi. Code. arXiv preprint arXiv:2308.12950 , year =
-
[57]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[58]
arXiv preprint arXiv:2303.08774 , year =
-
[59]
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , journal =
-
[60]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[61]
Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Dense Passage Retrieval for Open-Domain Question Answering , author =. Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
-
[62]
Irving, Geoffrey and Szegedy, Christian and Alemi, Alexander A. and E. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[63]
and Blanchette, Jasmin C
Paulson, Lawrence C. and Blanchette, Jasmin C. , booktitle =. Three Years of Experience with
-
[64]
Gauthier, Thibault and Kaliszyk, Cezary and Urban, Josef and Kumar, Ramana and Norrish, Michael , journal =
-
[65]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Reinforcement Learning of Theorem Proving , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[66]
Proceedings of the 4th ACM SIGPLAN International Workshop on Machine Learning and Programming Languages (MAPL) , pages =
Generating Correctness Proofs with Neural Networks , author =. Proceedings of the 4th ACM SIGPLAN International Workshop on Machine Learning and Programming Languages (MAPL) , pages =
-
[67]
and Ringer, Talia and Brun, Yuriy , booktitle =
First, Emily and Rabe, Markus N. and Ringer, Talia and Brun, Yuriy , booktitle =
-
[68]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Thinking Fast and Slow with Deep Learning and Tree Search , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[69]
, booktitle =
Zelikman, Eric and Wu, Yuhuai and Mu, Jesse and Goodman, Noah D. , booktitle =
-
[70]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[71]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[72]
arXiv preprint arXiv:2601.20802 , year =
Reinforcement Learning via Self-Distillation , author =. arXiv preprint arXiv:2601.20802 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.