PoLAR: Factorizing Extent and Mode in Latent Actions for Robot Policy Learning
Pith reviewed 2026-06-26 14:27 UTC · model grok-4.3
The pith
PoLAR structures latent actions radially in hyperbolic space so radius encodes transition extent via temporal offset while direction retains mode.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
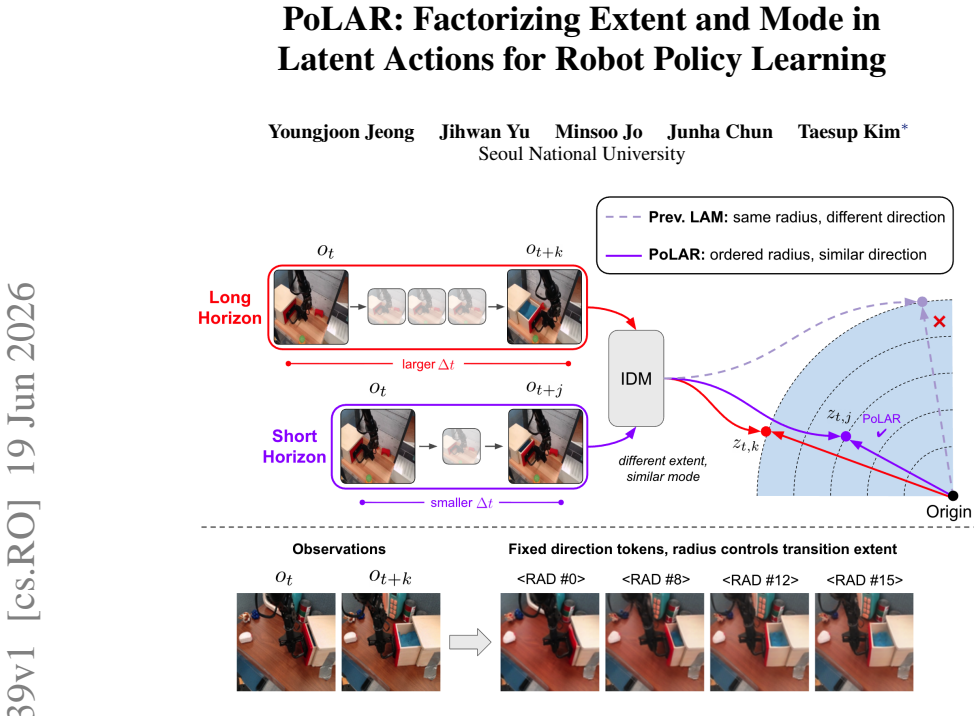
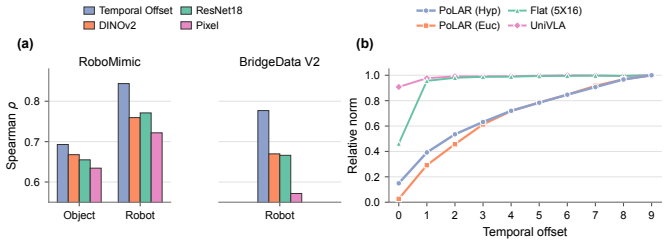
PoLAR imposes a radial-direction structure on latent actions in hyperbolic space, encouraging radius to encode transition extent guided by temporal offset between observation pairs and direction to retain transition mode, with the expanding volume of hyperbolic space naturally fitting more diverse modes at larger extents.
What carries the argument
Radial structure in hyperbolic space for latent actions, with radius for extent and direction for mode.
If this is right
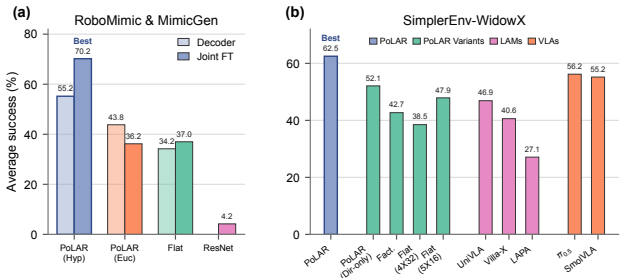
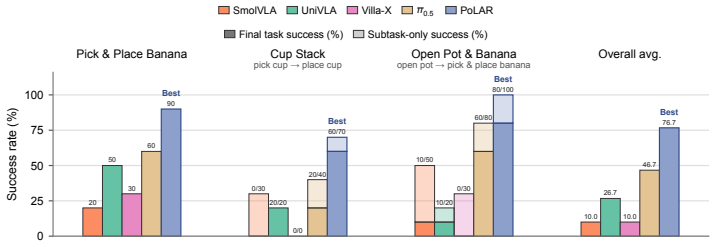
- Downstream robot policies achieve higher performance in simulation experiments.
- Downstream robot policies achieve higher performance in real-world experiments.
- PoLAR outperforms prior latent action pretraining baselines.
- PoLAR outperforms strong pretrained vision-language-action models.
- The geometry chosen for the latent action space affects how well visual pretraining transfers to robot control.
Where Pith is reading between the lines
- The same radial factorization might transfer to other domains that have natural extent signals, such as video prediction or navigation without robot hardware.
- Replacing the temporal-offset proxy with a learned or distance-based extent signal could be tested to see whether the gains persist without the weak-supervision assumption.
- If the volume property of hyperbolic space is essential, equivalent performance should not appear when the identical radial constraint is applied in Euclidean space.
Load-bearing premise
Temporal offset between two observations serves as a usable weak proxy for transition extent.
What would settle it
A comparison experiment in which PoLAR is retrained with temporal offsets randomly shuffled before radius assignment, which should remove the reported performance gains over baselines if the proxy is load-bearing.
Figures

read the original abstract
Latent action pretraining learns representations of visual change from pairs of observations, but existing methods typically encode each transition as a single unstructured representation that entangles transition extent and transition mode. We introduce Polar Latent Actions with Radial structure (PoLAR), which imposes a radial-direction structure on latent actions, encouraging radius to encode transition extent and direction to retain transition mode. PoLAR uses temporal offset between two observations as a weak proxy for transition extent, encouraging latent action from observation pairs separated by larger temporal gaps to occupy larger radii. We instantiate this structure in hyperbolic space, whose expanding volume with radius offers a natural fit for more diverse transition modes at larger extents. Across in-task and large-scale pretraining settings, PoLAR improves downstream policy performance in simulation and real-world robot experiments, outperforming latent action baselines and strong pretrained VLAs. These results suggest that the geometry of the latent action space is an important design choice for transferring visual pretraining to downstream robot policy learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PoLAR, a method that structures latent actions in hyperbolic space so that radius encodes transition extent (via temporal offset between observation pairs as a weak proxy) while direction encodes transition mode, with the goal of reducing entanglement in latent action pretraining for robot policies. It claims this geometric factorization improves downstream policy performance over latent action baselines and pretrained VLAs in both in-task and large-scale pretraining regimes, supported by simulation and real-robot experiments.
Significance. If the empirical claims hold, the work highlights that the geometry of the latent action space is a consequential design choice for visual pretraining transfer to robot control, offering a concrete mechanism (radial structure in hyperbolic space) to separate extent from mode. The use of an observable signal (temporal offset) to supervise the factorization is a strength, as is the explicit motivation from hyperbolic geometry's volume growth.
major comments (2)
- [§3.2] §3.2 (and the large-scale pretraining experiments): the central modeling choice that temporal offset serves as a usable proxy for transition extent is load-bearing for the factorization claim, yet the manuscript reports no correlation statistics or validation between offset and measured physical displacement (e.g., end-effector travel or optical flow magnitude) on the heterogeneous pretraining corpus; without this, radius may still entangle mode in variable-speed video data.
- [§4] §4 (Experiments): the abstract and introduction assert consistent outperformance over latent-action baselines and strong VLAs in both simulation and real-world settings, but the provided evaluation details do not include quantitative tables, baseline configurations, ablation studies on the hyperbolic vs. Euclidean choice, or error bars; this prevents assessment of whether the reported gains are statistically reliable or attributable to the radial structure.
minor comments (2)
- [§3.1] Notation for the hyperbolic embedding and the radial loss term should be introduced with an explicit equation reference in §3.1 rather than inline prose.
- [Figure 2] Figure 2 caption should clarify whether the visualized radii correspond to the learned latent actions or to the temporal-offset supervision signal.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of the temporal offset proxy and more detailed experimental reporting. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (and the large-scale pretraining experiments): the central modeling choice that temporal offset serves as a usable proxy for transition extent is load-bearing for the factorization claim, yet the manuscript reports no correlation statistics or validation between offset and measured physical displacement (e.g., end-effector travel or optical flow magnitude) on the heterogeneous pretraining corpus; without this, radius may still entangle mode in variable-speed video data.
Authors: We agree that explicit validation would strengthen the factorization claim. In the revised manuscript, we will add correlation statistics between temporal offsets and physical displacement measures (end-effector travel in simulation subsets and optical flow magnitude on real video data) computed across the pretraining corpus. This will quantify how well the weak proxy captures extent despite variable speeds, while retaining the stated motivation that temporal offset provides accessible supervision without requiring additional sensors. The hyperbolic volume growth is intended to support mode diversity at larger radii, but the added statistics will directly address potential entanglement concerns. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract and introduction assert consistent outperformance over latent-action baselines and strong VLAs in both simulation and real-world settings, but the provided evaluation details do not include quantitative tables, baseline configurations, ablation studies on the hyperbolic vs. Euclidean choice, or error bars; this prevents assessment of whether the reported gains are statistically reliable or attributable to the radial structure.
Authors: We acknowledge that the current experimental presentation lacks sufficient detail for full assessment. The revised version will include quantitative tables with performance metrics, explicit baseline configurations and hyperparameters, error bars from multiple random seeds, and a dedicated ablation comparing hyperbolic radial structure against an equivalent Euclidean embedding. These additions will clarify statistical reliability and isolate the contribution of the radial factorization. The abstract claims are grounded in the conducted experiments, but we will make the supporting evidence more transparent and reproducible. revision: yes
Circularity Check
No circularity; design choices use external observables without self-reduction
full rationale
The paper's core construction imposes radial structure on latent actions via temporal offset as a weak proxy for extent and hyperbolic geometry for mode diversity. This is presented as a modeling choice grounded in observable data (temporal gaps between observation pairs) rather than any derivation that reduces to fitted parameters renamed as predictions or self-citations. No equations or claims in the provided text exhibit self-definitional loops, uniqueness theorems imported from the same authors, or ansatzes smuggled via prior work. The approach remains self-contained against external benchmarks like downstream policy performance, with the temporal offset serving as an independent signal. This aligns with the default expectation for non-circular papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporal offset between observations is a usable weak proxy for transition extent
Reference graph
Works this paper leans on
-
[1]
Schmidt and M
D. Schmidt and M. Jiang. Learning to act without actions. InThe Twelfth International Con- ference on Learning Representations (ICLR), 2024
2024
-
[2]
S. Ye, J. Jang, B. Jeon, S. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, et al. Latent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2024
Pith/arXiv arXiv 2024
-
[3]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[4]
J. Bruce, M. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, Y . Aytar, S. Bechtle, F. Behbahani, S. Chan, N. Heess, L. Gonzalez, S. Osindero, S. Ozair, S. Reed, J. Zhang, K. Zolna, J. Clune, N. de Freitas, S. Singh, and T. Rockt¨aschel. Genie: Generative interactive environments, 2024. URLhttps://...
arXiv 2024
-
[5]
Q. Garrido, T. Nagarajan, B. Terver, N. Ballas, Y . LeCun, and M. Rabbat. Learning latent action world models in the wild, 2026. URLhttps://arxiv.org/abs/2601.05230
arXiv 2026
-
[6]
X. Chen, H. Wei, P. Zhang, C. Zhang, K. Wang, Y . Guo, R. Yang, Y . Wang, X. Xiao, L. Zhao, J. Chen, and J. Bian. villa-x: Enhancing latent action modeling in vision-language-action models.arXiv preprint arXiv: 2507.23682, 2025
Pith/arXiv arXiv 2025
-
[7]
Jeong, J
Y . Jeong, J. Chun, and T. Kim. Learning to act robustly with view-invariant latent actions,
-
[8]
URLhttps://arxiv.org/abs/2601.02994
-
[9]
J. M. Lee, D. Lee, S. Ju, T. Cho, J. W. Koo, L. Zhao, S. Hong, and J. Lee. Mvp-lam: Learning action-centric latent action via cross-viewpoint reconstruction, 2026. URLhttps://arxiv. org/abs/2602.03668
Pith/arXiv arXiv 2026
-
[10]
A. Liang, P. Czempin, M. Hong, Y . Zhou, E. Biyik, and S. Tu. Clam: Continuous latent action models for robot learning from unlabeled demonstrations, 2025. URLhttps://arxiv.org/ abs/2505.04999
Pith/arXiv arXiv 2025
-
[11]
A. Nikulin, I. Zisman, D. Tarasov, N. Lyubaykin, A. Polubarov, I. Kiselev, and V . Kurenkov. Latent action learning requires supervision in the presence of distractors.arXiv preprint arXiv:2502.00379, 2025
arXiv 2025
-
[12]
M. Nickel and D. Kiela. Poincar ´e embeddings for learning hierarchical representations, 2017. URLhttps://arxiv.org/abs/1705.08039
Pith/arXiv arXiv 2017
-
[13]
O.-E. Ganea, G. B ´ecigneul, and T. Hofmann. Hyperbolic neural networks, 2018. URLhttps: //arxiv.org/abs/1805.09112
Pith/arXiv arXiv 2018
-
[14]
S. Ge, S. Mishra, S. Kornblith, C.-L. Li, and D. Jacobs. Hyperbolic contrastive learning for visual representations beyond objects. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 6840–6849, June 2023
2023
-
[15]
Desai, M
K. Desai, M. Nickel, T. Rajpurohit, J. Johnson, and S. R. Vedantam. Hyperbolic image-text representations. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 7694–7731. PMLR, 23–29 Jul 2023....
2023
-
[16]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, L. Magne, A. Mandlekar, A. Narayan, Y . L. Tan, G. Wang, J. Wang, Q. Wang, Y . Xu, X. Zeng, K. Zheng, R. Zheng, M.-Y . Liu, L. Zettlemoyer, D. Fox, J. Kautz, S. Reed, Y . Zhu, and L. Fan. Dreamgen: Unlocking generalization in robot learning through video world...
Pith/arXiv arXiv 2025
-
[17]
NVIDIA, :, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z...
Pith/arXiv arXiv 2025
-
[18]
van den Oord, O
A. van den Oord, O. Vinyals, and K. Kavukcuoglu. Neural discrete representation learning,
-
[19]
URLhttps://arxiv.org/abs/1711.00937
-
[20]
S. Gao, S. Zhou, Y . Du, J. Zhang, and C. Gan. Adaworld: Learning adaptable world models with latent actions, 2025. URLhttps://arxiv.org/abs/2503.18938
arXiv 2025
-
[21]
Y . Jiang, Y . Gu, I. W. Tsang, and M. Z. Shou. Olaf-world: Orienting latent actions for video world modeling.arXiv preprint arXiv:2602.10104, 2026
Pith/arXiv arXiv 2026
- [22]
-
[23]
AgiBot-World-Contributors, Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang, S. Jiang, Y . Jiang, C. Jing, H. Li, J. Li, C. Liu, Y . Liu, Y . Lu, J. Luo, P. Luo, Y . Mu, Y . Niu, Y . Pan, J. Pang, Y . Qiao, G. Ren, C. Ruan, J. Shan, Y . Shen, C. Shi, M. Shi, M. Shi, C. Sima, J. Song, H. Wang, W. Wang, D. Wei, C. Xie, G. Xu...
Pith/arXiv arXiv 2025
-
[24]
P. Sermanet, C. Lynch, Y . Chebotar, J. Hsu, E. Jang, S. Schaal, and S. Levine. Time-contrastive networks: Self-supervised learning from video, 2018. URLhttps://arxiv.org/abs/ 1704.06888
Pith/arXiv arXiv 2018
-
[25]
D. Dwibedi, Y . Aytar, J. Tompson, P. Sermanet, and A. Zisserman. Temporal cycle-consistency learning, 2019. URLhttps://arxiv.org/abs/1904.07846
Pith/arXiv arXiv 2019
-
[26]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual represen- tation for robot manipulation, 2022. URLhttps://arxiv.org/abs/2203.12601
Pith/arXiv arXiv 2022
-
[27]
Y . J. Ma, W. Liang, V . Som, V . Kumar, A. Zhang, O. Bastani, and D. Jayaraman. Liv: Language-image representations and rewards for robotic control, 2023. URLhttps:// arxiv.org/abs/2306.00958
arXiv 2023
-
[28]
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training, 2023. URLhttps: //arxiv.org/abs/2210.00030
Pith/arXiv arXiv 2023
-
[29]
D. Yang, D. Tjia, J. Berg, D. Damen, P. Agrawal, and A. Gupta. Rank2reward: Learning shaped reward functions from passive video, 2024. URLhttps://arxiv.org/abs/2404.14735
arXiv 2024
-
[30]
S. Park, T. Kreiman, and S. Levine. Foundation policies with hilbert representations, 2024. URLhttps://arxiv.org/abs/2402.15567
arXiv 2024
-
[31]
F. Wang, X. Xiang, J. Cheng, and A. L. Yuille. Normface: L2 hypersphere embedding for face verification. InProceedings of the 25th ACM international conference on Multimedia, MM ’17, page 1041–1049. ACM, Oct. 2017. doi:10.1145/3123266.3123359. URLhttp: //dx.doi.org/10.1145/3123266.3123359
-
[32]
W. Liu, Y . Wen, Z. Yu, M. Li, B. Raj, and L. Song. Sphereface: Deep hypersphere embedding for face recognition, 2018. URLhttps://arxiv.org/abs/1704.08063. 10
Pith/arXiv arXiv 2018
-
[33]
H. Wang, Y . Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu. Cosface: Large margin cosine loss for deep face recognition, 2018. URLhttps://arxiv.org/abs/1801.09414
Pith/arXiv arXiv 2018
-
[34]
J. Deng, J. Guo, J. Yang, N. Xue, I. Kotsia, and S. Zafeiriou. Arcface: Additive angular margin loss for deep face recognition.IEEE Transactions on Pattern Analysis and Machine Intel- ligence, 44(10):5962–5979, Oct. 2022. ISSN 1939-3539. doi:10.1109/tpami.2021.3087709. URLhttp://dx.doi.org/10.1109/TPAMI.2021.3087709
-
[35]
T. Wang and P. Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere, 2022. URLhttps://arxiv.org/abs/2005.10242
arXiv 2022
-
[36]
J. Park, J. C. L. Chai, J. Yoon, and A. B. J. Teoh. Understanding the feature norm for out-of- distribution detection, 2023. URLhttps://arxiv.org/abs/2310.05316
arXiv 2023
-
[37]
Z. Liu, Z. Miao, X. Zhan, J. Wang, B. Gong, and S. X. Yu. Large-scale long-tailed recognition in an open world, 2019. URLhttps://arxiv.org/abs/1904.05160
Pith/arXiv arXiv 2019
-
[38]
Oyama, S
M. Oyama, S. Yokoi, and H. Shimodaira. Norm of word embedding encodes information gain,
-
[39]
URLhttps://arxiv.org/abs/2212.09663
-
[40]
O.-E. Ganea, G. B ´ecigneul, and T. Hofmann. Hyperbolic entailment cones for learning hierar- chical embeddings, 2018. URLhttps://arxiv.org/abs/1804.01882
Pith/arXiv arXiv 2018
- [41]
- [42]
-
[43]
Z. Zhang, D. Li, I. Reid, and R. Hartley. Geoworld: Geometric world models, 2026. URL https://arxiv.org/abs/2602.23058
Pith/arXiv arXiv 2026
-
[44]
M. Jo, D. Yang, and T. Kim. Angular gradient sign method: Uncovering vulnerabilities in hyperbolic networks.Proceedings of the AAAI Conference on Artificial Intelligence, 40(7): 5566–5574, Mar. 2026. ISSN 2159-5399. doi:10.1609/aaai.v40i7.37475. URLhttp://dx. doi.org/10.1609/aaai.v40i7.37475
-
[45]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[46]
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InarXiv preprint arXiv:2108.03298, 2021
Pith/arXiv arXiv 2021
-
[47]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. In7th Annual Conference on Robot Learning, 2023
2023
-
[48]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without sup...
Pith/arXiv arXiv 2024
-
[49]
S. Karamcheti, S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models, 2024. URLhttps: //arxiv.org/abs/2402.07865. 11
arXiv 2024
-
[50]
Walke, K
H. Walke, K. Black, A. Lee, M. J. Kim, M. Du, C. Zheng, T. Zhao, P. Hansen-Estruch, Q. Vuong, A. He, V . Myers, K. Fang, C. Finn, and S. Levine. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning (CoRL), 2023
2023
-
[51]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, S. Levine, J. Wu, C. Finn, H. Su, Q. Vuong, and T. Xiao. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
Pith/arXiv arXiv 2024
-
[52]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385
Pith/arXiv arXiv 2015
-
[53]
O. X.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Her- zog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakr- ishna, A. W...
Pith/arXiv arXiv 2023
-
[54]
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, M. Martin, T. Nagarajan, I. Radosavovic, S. K. Ramakrishnan, F. Ryan, J. Sharma, M. Wray, M. Xu, E. Z. Xu, C. Zhao, S. Bansal, D. Batra, V . Cartillier, S. Crane, T. Do, M. Doulaty, A. Erapalli, C. Feichtenhofer, A. Fragomeni, Q. Fu, A. Gebreselas...
arXiv 2022
-
[55]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
Pith/arXiv arXiv 2025
-
[56]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, S. Alibert, M. Cord, T. Wolf, and R. Cadene. Smolvla: A vision-language-action model for affordable and efficient robotics, 2025. URLhttps: //arxiv.org/abs/2506.01844
Pith/arXiv arXiv 2025
-
[57]
Cadene, S
R. Cadene, S. Aliberts, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal, S. Palma, M. Shukor, J. Moss, A. Soare, D. Aubakirova, Q. Lhoest, Q. Gallou´edec, and T. Wolf. Lerobot: An open-source library for end-to-end robot learning,
-
[58]
URLhttps://arxiv.org/abs/2602.22818
-
[59]
Barber and F
D. Barber and F. Agakov. Information maximization in noisy channels : A variational ap- proach. In S. Thrun, L. Saul, and B. Sch ¨olkopf, editors,Advances in Neural Information Pro- cessing Systems, volume 16. MIT Press, 2003. URLhttps://proceedings.neurips.cc/ paper_files/paper/2003/file/a6ea8471c120fe8cc35a2954c9b9c595-Paper.pdf
2003
-
[60]
A. van den Oord, Y . Li, and O. Vinyals. Representation learning with contrastive predictive coding, 2019. URLhttps://arxiv.org/abs/1807.03748
Pith/arXiv arXiv 2019
-
[61]
B. Poole, S. Ozair, A. van den Oord, A. A. Alemi, and G. Tucker. On variational bounds of mutual information, 2019. URLhttps://arxiv.org/abs/1905.06922
Pith/arXiv arXiv 2019
-
[62]
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y . LeCun, M. Assran, and N. Bal- las. Revisiting feature prediction for learning visual representations from video, 2024. URL https://arxiv.org/abs/2404.08471. 13 Appendix A Implementation Details A.1 Latent Action Pretraining PoLAR pretraining on RoboMimic & MimicGen.Table A.1 summarizes the hyperpara...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.