A probabilistic framework for online test-time adaptation
Pith reviewed 2026-06-26 00:23 UTC · model grok-4.3
The pith
A state-space model unifies parameter learning and prediction for online test-time adaptation under distributional shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
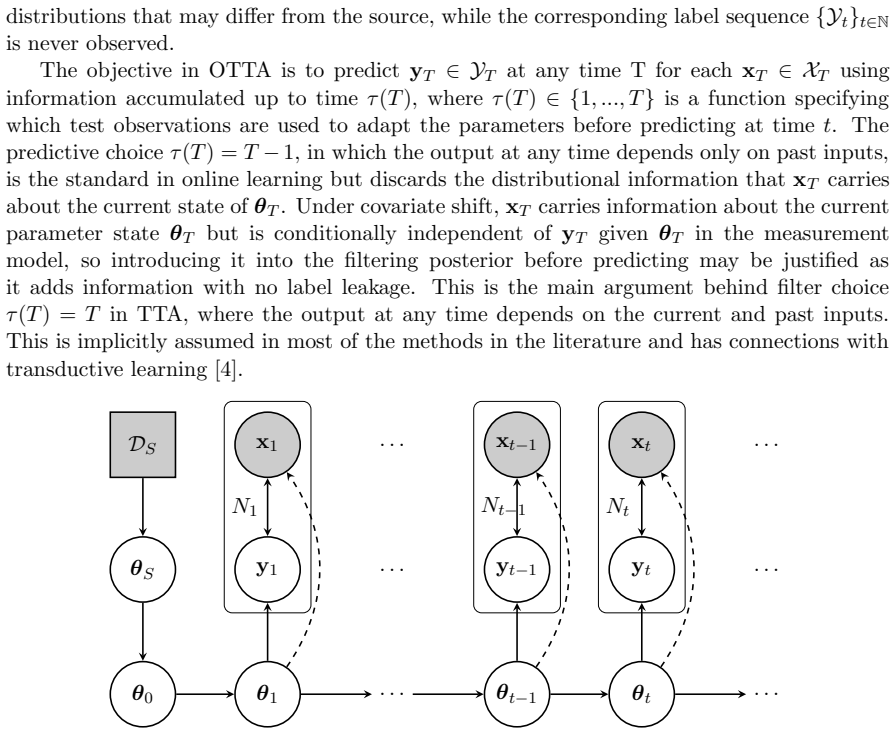
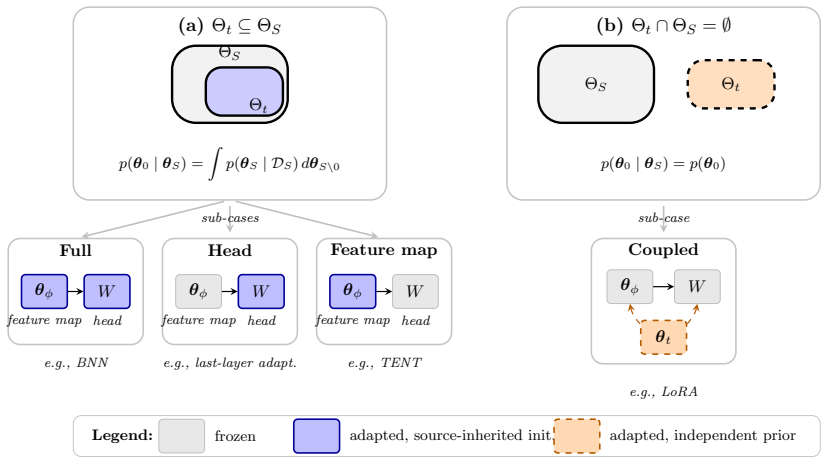
The framework is based on a state-space modelling architecture from which parameter learning, parameter time evolution, prior tuning, and prediction can be characterized for online test-time adaptation under potential distributional shifts.
What carries the argument
state-space modelling architecture that tracks parameter dynamics over time
If this is right
- Parameters can be learned and updated sequentially as new unlabeled data arrives.
- Prior distributions can be tuned based on the state evolution.
- Predictions account for the uncertainty in parameter changes due to shifts.
- Adaptation becomes a filtering problem in the state-space model.
Where Pith is reading between the lines
- Such a model could integrate with existing Bayesian online learning techniques for more robust adaptation.
- Extensions might include handling multiple possible shift types within the state transitions.
Load-bearing premise
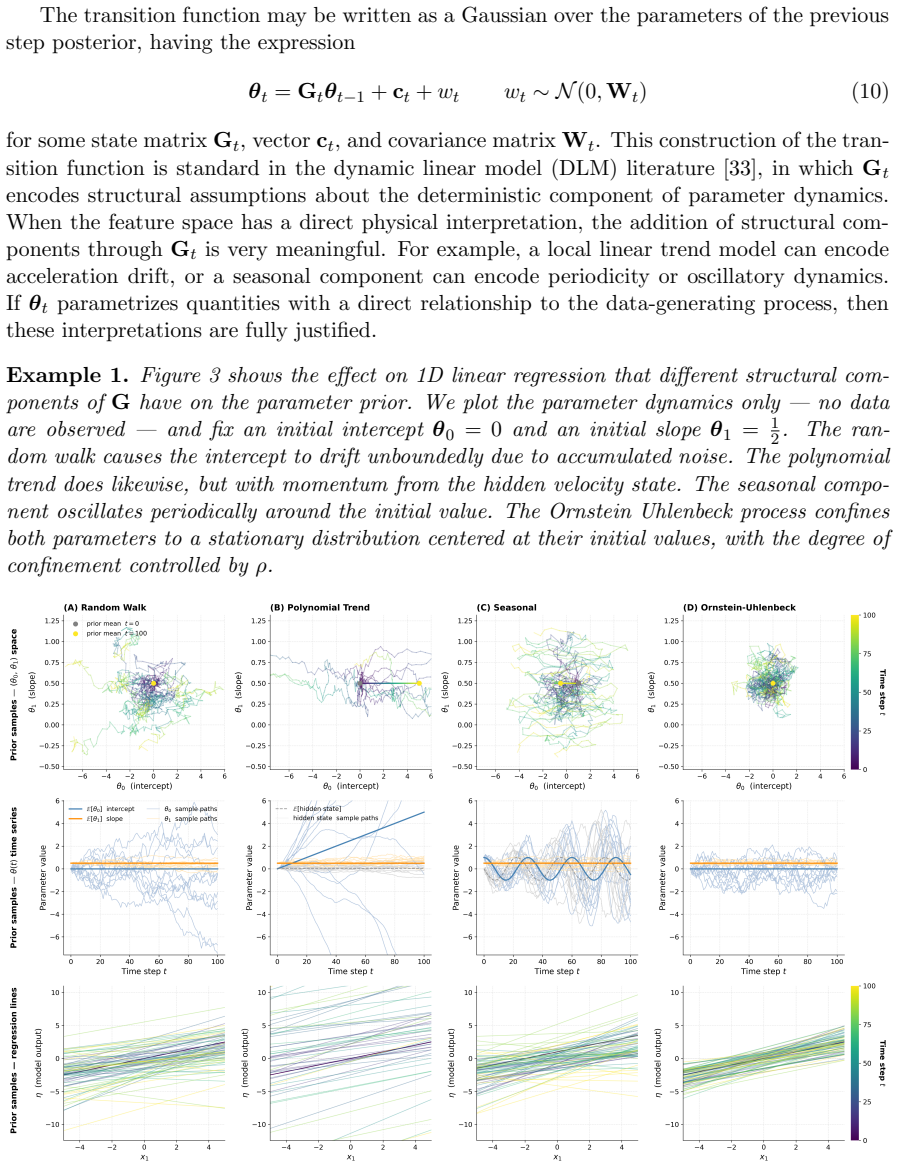
That the dynamics of model parameters during adaptation can be adequately represented by a state-space model.
What would settle it
A comparison where the state-space predictions fail to match observed adaptation performance on datasets with known distributional shifts.
Figures
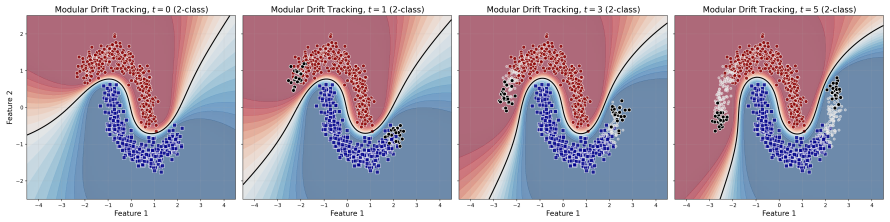
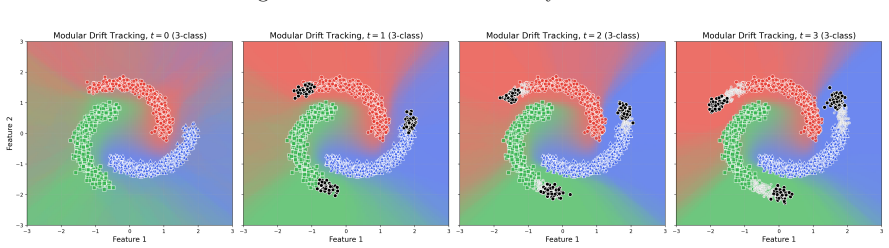
read the original abstract
This paper presents a probabilistic framework for online test-time adaptation problems. In them, a model is trained on labeled data but must adapt to unlabeled data at test time under the assumption that training and test distributions potentially differ, that is, there might have been a distributional shift. The framework is based on a state-space modelling architecture from which parameter learning, parameter time evolution, prior tuning, and prediction can be characterized.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a probabilistic framework for online test-time adaptation problems. A model is trained on labeled data but must adapt to unlabeled data at test time under potential distributional shift. The framework is based on a state-space modelling architecture from which parameter learning, parameter time evolution, prior tuning, and prediction can be characterized.
Significance. If rigorously developed with explicit derivations and validated empirically, such a framework could provide a unified probabilistic treatment of online TTA, enabling principled handling of distributional shift via state-space dynamics. The abstract alone supplies no such development, so significance cannot be assessed.
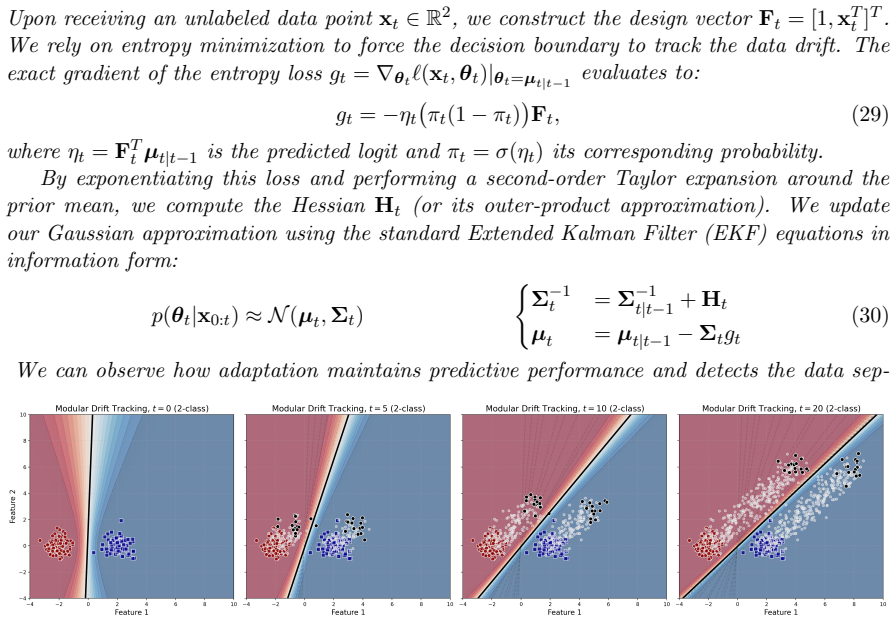
major comments (1)
- [Abstract] Abstract: no equations, state-space model definition, learning rules, or experimental results are supplied, so the central claim that the architecture 'characterizes' parameter learning, time evolution, prior tuning, and prediction cannot be evaluated for soundness or novelty.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: no equations, state-space model definition, learning rules, or experimental results are supplied, so the central claim that the architecture 'characterizes' parameter learning, time evolution, prior tuning, and prediction cannot be evaluated for soundness or novelty.
Authors: We agree that the provided manuscript consists solely of the abstract, which contains no equations, state-space model definition, learning rules, or experimental results. Consequently, the central claim cannot be evaluated for soundness or novelty from the given text. revision: no
- Only the abstract is available, so we cannot supply the state-space model, derivations, or results needed to allow evaluation of the framework.
Circularity Check
No circularity detectable; abstract-only text provides no derivation chain
full rationale
Only the abstract is available, which states the existence of a state-space modelling architecture for characterizing parameter learning, time evolution, prior tuning, and prediction but supplies no equations, self-citations, fitted inputs, or ansatzes. No load-bearing steps exist to inspect for reduction to inputs by construction, self-definition, or self-citation chains. This matches the default case of honest non-finding when the paper is self-contained against external benchmarks and no evidence of circularity is present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. G. Arce, R. Naveiro, and D. R. Insua. Evasion attacks against bayesian predictive models. InProceedings of the Forty-First Conference on Uncertainty in Artificial Intel- ligence, pages 184–202, 2025
2025
-
[2]
C. M. Bishop and N. M. Nasrabadi.Pattern recognition and machine learning, volume 4. Springer, 2006
2006
-
[3]
P. G. Bissiri, C. C. Holmes, and S. G. Walker. A general framework for updating belief distributions.Journal of the Royal Statistical Society Series B: Statistical Methodology, 78(5):1103–1130, 2016
2016
-
[4]
Chapelle, B
O. Chapelle, B. Sch¨ olkopf, and A. Zien, editors.Semi-supervised learning. Adap- tive computation and machine learning. MIT Press, Cambridge, Mass, 2006. ISBN 9780262033589
2006
-
[5]
Daxberger, A
E. Daxberger, A. Kristiadi, A. Immer, R. Eschenhagen, M. Bauer, and P. Hennig. Laplace redux-effortless bayesian deep learning.Advances in neural information processing sys- tems, 34:20089–20103, 2021
2021
-
[6]
G. Duran-Martin, L. S´ anchez-Betancourt, A. Y. Shestopaloff, and K. Murphy. A unifying framework for generalised bayesian online learning in non-stationary environments.arXiv preprint arXiv:2411.10153, 2024
-
[7]
Duran-Martin, L
G. Duran-Martin, L. S´ anchez-Betancourt,´A. Cartea, and K. Murphy. Martingale poste- rior neural networks for fast sequential decision making.Advances in Neural Information Processing Systems, 38:87940–87988, 2026
2026
-
[8]
Goyal, M
S. Goyal, M. Sun, A. Raghunathan, and J. Z. Kolter. Test time adaptation via conjugate pseudo-labels.Advances in Neural Information Processing Systems, 35:6204–6218, 2022
2022
-
[9]
Grandvalet and Y
Y. Grandvalet and Y. Bengio. Semi-supervised learning by entropy minimization.Ad- vances in neural information processing systems, 17, 2004
2004
-
[10]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[11]
Iwasawa and Y
Y. Iwasawa and Y. Matsuo. Test-time classifier adjustment module for model-agnostic domain generalization.Advances in Neural Information Processing Systems, 34:2427– 2440, 2021
2021
-
[12]
Jones, P
M. Jones, P. Chang, and K. Murphy. Bayesian online natural gradient (bong).Advances in Neural Information Processing Systems, 37:131104–131153, 2024
2024
-
[13]
Kirkpatrick, R
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Mi- lan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al. Overcoming catastrophic for- getting in neural networks.Proceedings of the national academy of sciences, 114(13): 3521–3526, 2017
2017
-
[14]
Knoblauch, J
J. Knoblauch, J. Jewson, and T. Damoulas. An optimization-centric view on bayes’ rule: Reviewing and generalizing variational inference.Journal of Machine Learning Research, 23(132):1–109, 2022. 16
2022
-
[15]
P. W. Koh, S. Sagawa, H. Marklund, S. M. Xie, M. Zhang, A. Balsubramani, W. Hu, M. Yasunaga, R. L. Phillips, I. Gao, et al. Wilds: A benchmark of in-the-wild distribution shifts. InInternational conference on machine learning, pages 5637–5664. PMLR, 2021
2021
- [16]
-
[17]
J.-H. Lee. Bayesian weight enhancement with steady-state adaptation for test-time adap- tation in dynamic environments. InForty-second International Conference on Machine Learning, 2025
2025
-
[18]
Lee and J.-H
J.-H. Lee and J.-H. Chang. Continual momentum filtering on parameter space for online test-time adaptation. InThe Twelfth International Conference on Learning Representa- tions, 2024
2024
-
[19]
Lee and J.-H
J.-H. Lee and J.-H. Chang. Stationary latent weight inference for unreliable observations from online test-time adaptation. InForty-first International Conference on Machine Learning, 2024
2024
-
[20]
Liang, D
J. Liang, D. Hu, and J. Feng. Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation. InInternational conference on machine learning, pages 6028–6039. PMLR, 2020
2020
-
[21]
Liang, R
J. Liang, R. He, and T. Tan. A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision, 133(1):31–64, 2025
2025
-
[22]
Y. Liu, P. Kothari, B. Van Delft, B. Bellot-Gurlet, T. Mordan, and A. Alahi. Ttt++: When does self-supervised test-time training fail or thrive?Advances in Neural Infor- mation Processing Systems, 34:21808–21820, 2021
2021
-
[23]
D. J. MacKay. A practical bayesian framework for backpropagation networks.Neural computation, 4(3):448–472, 1992
1992
-
[24]
R. A. Marsden, M. D¨ obler, and B. Yang. Universal test-time adaptation through weight ensembling, diversity weighting, and prior correction. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2555–2565, 2024
2024
-
[25]
J. Martens. New insights and perspectives on the natural gradient method.Journal of Machine Learning Research, 21(146):1–76, 2020
2020
-
[26]
K. P. Murphy.Probabilistic machine learning: Advanced topics. MIT press, 2023
2023
-
[27]
S. Niu, J. Wu, Y. Zhang, Y. Chen, S. Zheng, P. Zhao, and M. Tan. Efficient test-time model adaptation without forgetting. InInternational conference on machine learning, pages 16888–16905. PMLR, 2022
2022
-
[28]
M. Schirmer, D. Zhang, and E. Nalisnick. Temporal Test-Time Adaptation with State- Space Models, Nov. 2025. URLhttp://arxiv.org/abs/2407.12492. arXiv:2407.12492 [cs]
-
[29]
M. Seeger. Learning with labeled and unlabeled data. Technical report, Institute for Adaptive and Neural Computation, University of Edinburgh, 2000
2000
-
[30]
Y. Sun, X. Wang, Z. Liu, J. Miller, A. Efros, and M. Hardt. Test-time training with self-supervision for generalization under distribution shifts. InInternational conference on machine learning, pages 9229–9248. PMLR, 2020. 17
2020
-
[31]
D. Wang, E. Shelhamer, S. Liu, B. Olshausen, and T. Darrell. Tent: Fully test-time adaptation by entropy minimization. InInternational Conference on Learning Represen- tations, 2021
2021
-
[32]
Q. Wang, O. Fink, L. Van Gool, and D. Dai. Continual test-time domain adaptation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7201–7211, 2022
2022
-
[33]
West and J
M. West and J. Harrison.Bayesian forecasting and dynamic models. Springer, 1997
1997
-
[34]
Z. Xiao and C. G. Snoek. Beyond model adaptation at test time: A survey.arXiv preprint arXiv:2411.03687, 2024
-
[35]
Zhang, S
M. Zhang, S. Levine, and C. Finn. Memo: Test time robustness via adaptation and augmentation.Advances in neural information processing systems, 35:38629–38642, 2022
2022
-
[36]
Zhou and S
A. Zhou and S. Levine. Bayesian adaptation for covariate shift.Advances in neural information processing systems, 34:914–927, 2021. 18
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.