Redact or Keep? A Fully Local AI Cascade for Educational Dialogue De-Identification
Pith reviewed 2026-06-27 00:51 UTC · model grok-4.3
The pith
A fully local two-stage cascade reaches 0.958 macro F1 for educational dialogue de-identification by using context to decide redact or keep.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
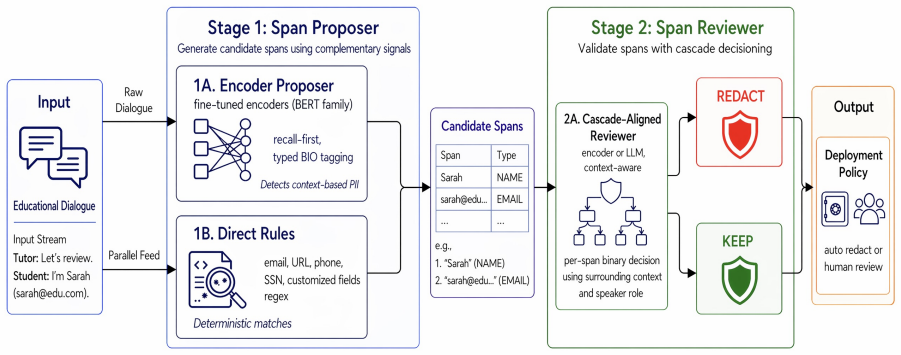
The central claim is that reframing de-identification as privacy triage with a recall-first union proposer followed by a context-aware reviewer allows a fully local system to reach 0.958 macro F1 on educational transcripts, exceeding both same-family LLM-only baselines and commercial APIs while preserving data governance.
What carries the argument
The context-aware reviewer, which makes binary Redact/Keep decisions for each candidate span using surrounding dialogue and speaker role.
If this is right
- Educational data can be de-identified at high accuracy without transmitting transcripts to third parties.
- Over-generation of candidates followed by context review reduces erroneous redaction of curricular terms that resemble names.
- Performance on ambiguous name cases stays stable when the reviewer has access to dialogue turns and speaker identity.
- Single-laptop deployment becomes feasible for processing large collections of tutoring transcripts.
Where Pith is reading between the lines
- The staged approach may transfer to other settings where domain terms overlap with personal names, such as medical notes or legal transcripts.
- Lowering the need for large models through explicit proposer-reviewer separation could cut energy use for privacy-sensitive text processing.
- Adding speaker-turn features or simple role labels might further stabilize reviewer decisions on edge cases the paper does not test.
Load-bearing premise
Surrounding dialogue context plus speaker role alone is sufficient for the reviewer to make reliable Redact/Keep decisions on ambiguous names without external knowledge or larger models.
What would settle it
A test set of dialogues in which names cannot be classified as personal or curricular from transcript context and speaker role alone, on which the cascade macro F1 falls below the reported 0.958 level.
Figures
read the original abstract
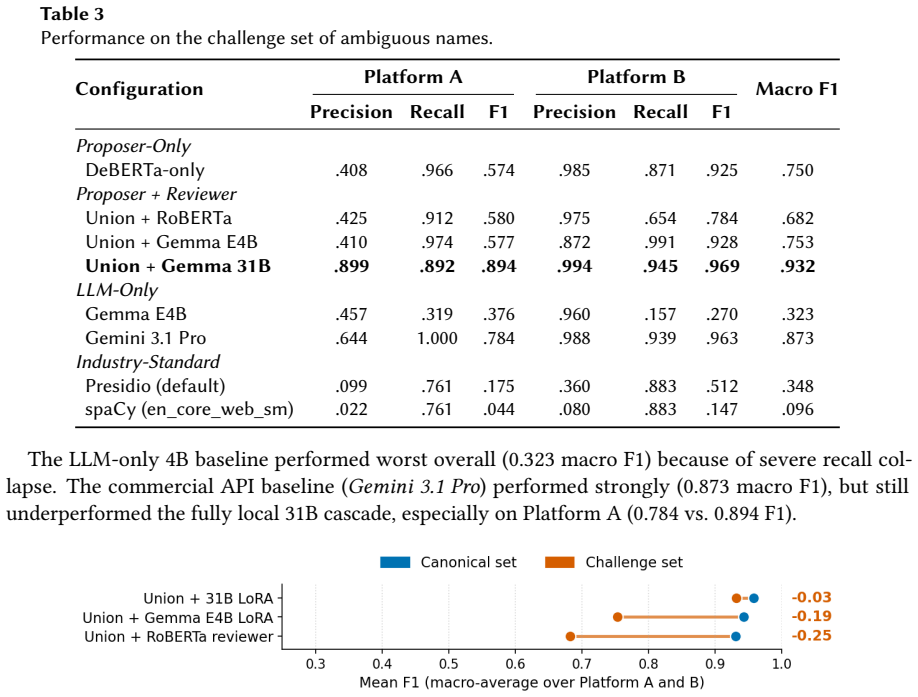
Educational dialogue is a valuable but sensitive resource for research: the same transcripts that capture authentic learning often capture personally identifiable information (PII) entangled with curricular content, where "Riemann" may refer to a real student or to a mathematical concept. Existing approaches force a tradeoff between governance and accuracy. Commercial Large Language Models (LLMs) can handle this ambiguity but require sending student data to third parties, while local named entity recognition (NER) systems preserve governance but over-redact curricular terms. We propose a fully local cascade framework that reframes de-identification from open-ended entity recognition to constrained privacy triage. A recall-first union proposer combines two lightweight encoders with deterministic rules to over-generate candidate spans; a context-aware reviewer then makes a binary Redact/Keep decision for each candidate using surrounding dialogue and speaker role. We evaluate three reviewer configurations against same-family LLM-only baselines and a commercial API on math tutoring transcripts from two large platforms. The strongest local configuration reaches 0.958 macro F1, compared with 0.767 for a same-family LLM-only baseline and 0.706 for the commercial API, while running entirely on a single laptop. On a targeted challenge set of curricular-personal name ambiguity, the same configuration degrades by only 0.03 F1 versus 0.19 to 0.25 for smaller reviewers. These results suggest that for educational de-identification, problem formulation matters more than model scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a fully local cascade for de-identifying educational dialogues by reframing the task as privacy triage. A recall-first union proposer generates candidate spans using lightweight encoders and deterministic rules, and a context-aware reviewer makes binary Redact/Keep decisions based on surrounding dialogue and speaker role. On math tutoring transcripts from two platforms, the strongest configuration achieves 0.958 macro F1, outperforming a same-family LLM baseline (0.767) and a commercial API (0.706). On a targeted challenge set for curricular-personal name ambiguity, it degrades by only 0.03 F1 compared to 0.19-0.25 for smaller reviewers.
Significance. If the results are reproducible, this work demonstrates that a local, multi-stage approach can achieve high accuracy in handling ambiguous PII in educational data without relying on external APIs, addressing both privacy governance and performance. The inclusion of a targeted challenge set provides a concrete test of the method's robustness to name ambiguity. Strengths include the fully local execution on a single laptop and the empirical comparison showing the value of the cascade formulation over scale alone.
major comments (3)
- [Abstract] Abstract: The reported performance metrics (0.958 macro F1, 0.03 degradation) are presented without details on dataset sizes, exact model architectures, training procedures, or statistical significance tests, which are necessary to evaluate the reliability of the central empirical claims.
- [Methods (reviewer component)] Methods (reviewer component): The claim that the reviewer can reliably decide Redact/Keep using only surrounding dialogue and speaker role is load-bearing for the advantage over LLM baselines, but the manuscript does not provide analysis or examples of cases where this local context is insufficient for resolving curricular vs. personal name ambiguity.
- [Evaluation] Evaluation: The construction and size of the 'targeted challenge set of curricular-personal name ambiguity' is not described, undermining the interpretation of the 0.03 F1 degradation result as evidence of robustness.
minor comments (1)
- [Abstract] Abstract: The term 'smaller reviewers' is used without definition or reference to specific configurations.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment point by point below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported performance metrics (0.958 macro F1, 0.03 degradation) are presented without details on dataset sizes, exact model architectures, training procedures, or statistical significance tests, which are necessary to evaluate the reliability of the central empirical claims.
Authors: The abstract is intentionally concise to highlight the core contribution. Full details on the two-platform dataset sizes, exact encoder and reviewer architectures, training procedures, and evaluation protocol appear in the Methods and Evaluation sections. We agree that the abstract would benefit from additional specificity and will revise it to include dataset sizes, model family details, and a statement on statistical significance (computed via bootstrap resampling over the test transcripts). revision: yes
-
Referee: [Methods (reviewer component)] Methods (reviewer component): The claim that the reviewer can reliably decide Redact/Keep using only surrounding dialogue and speaker role is load-bearing for the advantage over LLM baselines, but the manuscript does not provide analysis or examples of cases where this local context is insufficient for resolving curricular vs. personal name ambiguity.
Authors: We acknowledge that the manuscript would be strengthened by explicit discussion of the reviewer's limitations. While the quantitative results on the challenge set already demonstrate robustness relative to smaller reviewers, we will add a qualitative analysis subsection containing representative examples of curricular-personal name ambiguity, cases where speaker role and dialogue context suffice for correct decisions, and any observed failure modes where additional context would be required. revision: yes
-
Referee: [Evaluation] Evaluation: The construction and size of the 'targeted challenge set of curricular-personal name ambiguity' is not described, undermining the interpretation of the 0.03 F1 degradation result as evidence of robustness.
Authors: The challenge set is referenced in the Evaluation section, but we agree that its construction, size, and selection criteria require fuller description to support the robustness claim. We will expand the relevant paragraph to detail how instances were identified (names appearing in both curricular and personal contexts), the total number of spans, annotation process, and how the set was held out from training. revision: yes
Circularity Check
No circularity: empirical head-to-head evaluation on external transcripts
full rationale
The paper reports macro F1 scores from direct evaluation of a proposed local cascade (proposer + reviewer) against same-family LLM baselines and a commercial API on math tutoring transcripts. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the derivation chain. The central claims rest on measured performance differences (0.958 vs. 0.767/0.706) and degradation on a challenge set, which are falsifiable against the held-out data rather than constructed from the method itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- reviewer decision threshold
axioms (1)
- domain assumption Dialogue context and speaker role suffice to disambiguate curricular versus personal names
Reference graph
Works this paper leans on
-
[1]
S. Singhal, A. F. Zambrano, M. Pankiewicz, X. Liu, C. Porter, R. S. Baker, De-identifying student personally identifying information with GPT-4, in: Proceedings of the 17th International Con- ference on Educational Data Mining, International Educational Data Mining Society, Atlanta, Georgia, USA, 2024, pp. 559–565. URL: https://educationaldatamining.org/e...
-
[2]
Z. Ji, Y. Shen, K. R. Koedinger, J. Lin, Enhancing the de-identification of personally identifiable information in educational data, Journal of Educational Data Mining (2025). URL: https://jedm. educationaldatamining.org/index.php/JEDM/article/view/936. doi:10.5281/zenodo.17114271
-
[3]
Z. Zhou, K. Vanacore, B. Ahtisham, J. Lee, D. Pietrzak, D. Hedley, J. Dias, C. Shaw, R. Schäfer, R. F. Kizilcec, Utility-preserving de-identification for math tutoring: Investigating numeric ambiguity in the MathEd-PII benchmark dataset, arXiv preprint arXiv:2602.16571 (2026). URL: https://arxiv.org/abs/2602.16571
Pith/arXiv arXiv 2026
-
[4]
A. Stubbs, C. Kotfila, Ö. Uzuner, Automated systems for the de-identification of longitudinal clinical narratives: Overview of 2014 i2b2/UTHealth shared task track 1, Journal of Biomedical Informatics 58 (2015) S11–S19. URL: https://pubmed.ncbi.nlm.nih.gov/26225918/. doi:10.1016/j. jbi.2015.06.007
work page doi:10.1016/j 2014
-
[5]
A. Kovačević, B. Bašaragin, N. Milošević, G. Nenadić, De-identification of clinical free text using natural language processing: A systematic review of current approaches, Artificial Intelligence in Medicine 151 (2024) 102845. URL: https://doi.org/10.1016/j.artmed.2024.102845. doi:10.1016/j. artmed.2024.102845
-
[6]
M. Zent, D. Smith, S. Woodhead, PIIvot: A lightweight NLP anonymization framework for question- anchored tutoring dialogues, in: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Suzhou, China, 2025, pp. 27479–27488. URL: https://aclanthology.org/2025.emnlp-main.1397/. doi:10...
-
[7]
Holmes, J
L. Holmes, J. Wang, S. Crossley, W. Zhang, The cleaned repository of annotated personally identifiable information, in: Proceedings of the 17th International Conference on Educational Data Mining, 2024. URL: https://educationaldatamining.org/edm2024/proceedings/2024.EDM-posters. 88/index.html
2024
-
[8]
Honnibal, I
M. Honnibal, I. Montani, S. Van Landeghem, A. Boyd, spacy: Industrial-strength natural language processing in python, Software, 2020. URL: https://spacy.io
2020
-
[9]
URL: https://microsoft.github.io/presidio/
Microsoft, Presidio: Data protection and de-identification sdk, Software documentation, 2024. URL: https://microsoft.github.io/presidio/
2024
-
[10]
P. Awasthy, T. Moon, N. Jian, R. Florian, Cascaded models for better fine-grained named entity recognition, arXiv preprint arXiv:2009.07317 (2020). URL: https://arxiv.org/abs/2009.07317
arXiv 2009
-
[11]
P. Huang, X. Zhao, M. Hu, Z. Tan, W. Xiao, T2-NER: A two-stage span-based framework for unified named entity recognition with templates, Transactions of the Association for Computational Linguistics 11 (2023) 1265–1282. URL: https://aclanthology.org/2023.tacl-1.72. doi:10.1162/tacl_ a_00602
-
[12]
Y. Li, Y. Yu, T. Qian, Type-aware decomposed framework for few-shot named entity recognition, arXiv preprint arXiv:2302.06397 (2023). URL: https://arxiv.org/abs/2302.06397
arXiv 2023
- [13]
-
[14]
P. He, J. Gao, W. Chen, DeBERTaV3: Improving DeBERTa using ELECTRA-style pre-training with gradient-disentangled embedding sharing, in: The Eleventh International Conference on Learning Representations, 2023. URL: https://openreview.net/forum?id=sE7-XhLxHA
2023
-
[15]
B. Warner, A. Chaffin, B. Clavié, O. Weller, O. Hallström, S. Taghadouini, A. Gallagher, R. Biswas, F. Ladhak, T. Aarsen, N. Cooper, G. Adams, J. Howard, I. Poli, Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference, arXiv preprint arXiv:2412.13663 (2024). URL: https://arxiv....
Pith/arXiv arXiv 2024
-
[16]
T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense object detection, in: Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 2980–2988. URL: https://openaccess.thecvf.com/content_iccv_2017/html/Lin_Focal_Loss_for_ICCV_2017_ paper.html. doi:10.1109/ICCV.2017.324
-
[17]
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, V. Stoyanov, RoBERTa: A robustly optimized BERT pretraining approach, arXiv preprint arXiv:1907.11692 (2019). URL: https://arxiv.org/abs/1907.11692
Pith/arXiv arXiv 1907
-
[18]
URL: https://blog
Gemma Team, Google DeepMind, Gemma 4: Open models for on-device and local deployment, Model release; model cards for gemma-4-E4B-it and gemma-4-31B-it, 2026. URL: https://blog. google/technology/developers/gemma-4/
2026
-
[19]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, LoRA: Low-rank adaptation of large language models, in: International Conference on Learning Representations,
-
[20]
URL: https://openreview.net/forum?id=nZeVKeeFYf9
-
[21]
T. Dettmers, A. Pagnoni, A. Holtzman, L. Zettlemoyer, QLoRA: Efficient finetuning of quantized LLMs, Advances in Neural Information Processing Systems 36 (2023) 10088–10115. URL: https: //arxiv.org/abs/2305.14314
Pith/arXiv arXiv 2023
-
[22]
Jordan has 15 apples
Google, Gemini 3.1 pro preview model card, Google AI for Developers, 2026. URL: https://ai.google. dev/gemini-api/docs/models. A. Methodology Notes Candidate spans are divided into two pools with different inference paths. (1)Direct-rule pool(18 rows on Platform A, 0 on Platform B): structured identifiers matched by deterministic rules (e.g., email, phone...
2026
-
[23]
A word-problem note instructingKeepwhen a candidate name appears in a mathematical scenario
-
[24]
Hi, I’m Morgan
Pedagogical direct-address counter-examples (“Hi, I’m Morgan”, “Thanks, Taylor!”) using names chosen specifically to not overlap with the test-set failure cases, to avoid overfitting the prompt to specific evaluation spans. Prompt text (verbatim). You are a PII verification analyst for educational de-identification. You will receive one candidate span pro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.