EComAgentBench: Benchmarking Shopping Agents on Long-Horizon Tasks with Distributed Hidden Intent
Pith reviewed 2026-06-27 00:53 UTC · model grok-4.3
The pith
Shopping agents reach only 57.1 percent accuracy when buyer requirements are scattered across visible queries, hidden profiles, and clarifications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
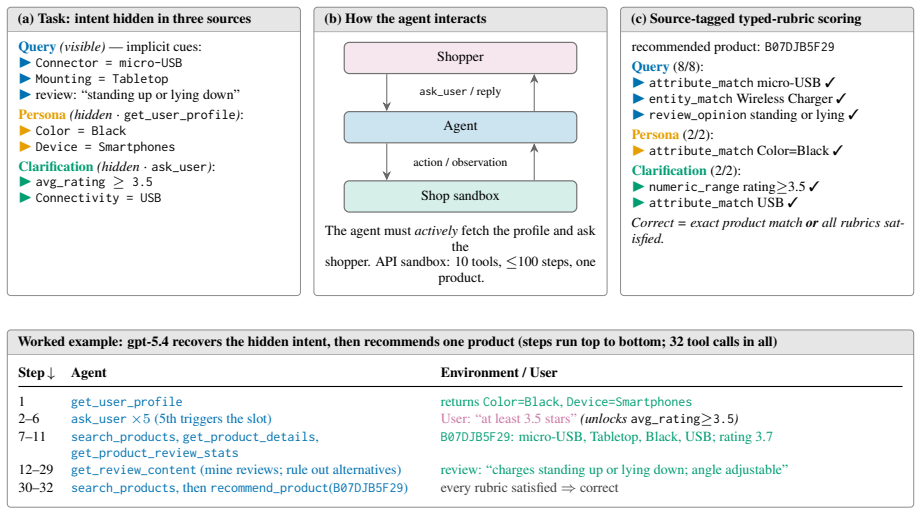
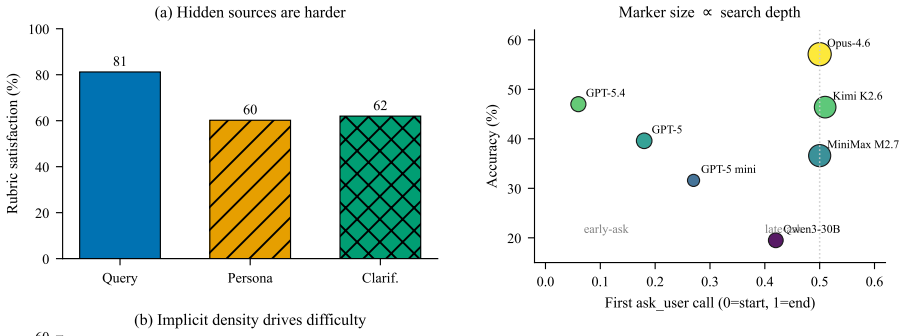
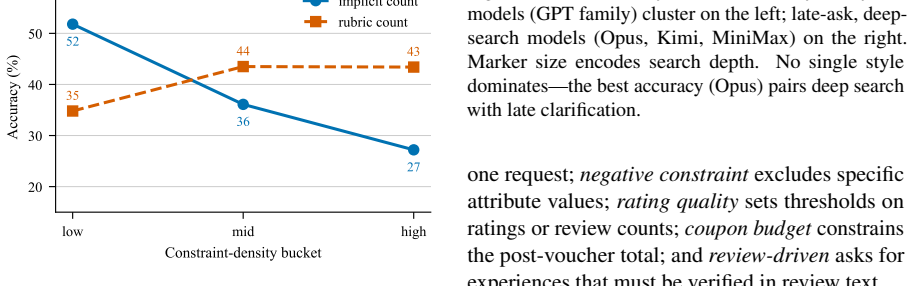
EComAgentBench contains 662 tasks in which requirements are deliberately distributed across a visible query, a tool-gated user profile, and scripted clarification turns. An agent must locate the hidden portions, cross-check candidates against product attributes and review evidence, and commit to one product within a 100-call budget. Source-tagged rubrics then grade each task and attribute every shortfall to the originating requirement and its visibility level. When seven models are evaluated, the strongest reaches 57.1 percent overall accuracy while rubric satisfaction falls steadily from visible to hidden sources.
What carries the argument
Source-tagged rubrics that assign each failure to a concrete requirement and its source (visible query, profile, or clarification).
If this is right
- Agents must incorporate reliable mechanisms for querying gated profiles and issuing clarifying questions across many steps.
- Training data for shopping agents should include examples where intent is only partially stated at the outset.
- Evaluation rubrics can now isolate whether an agent missed a requirement because it was hidden rather than because the product was unsuitable.
- Benchmarks that expose full intent upfront will systematically underestimate the difficulty of realistic shopping assistance.
- Progress on the benchmark requires advances in long-horizon tool use and selective information gathering rather than final-answer accuracy alone.
Where Pith is reading between the lines
- The same distributed-intent pattern appears in other service domains such as travel or financial advice, suggesting the rubric approach could transfer.
- Automated task construction that locks answers in code first may become a template for creating other reproducible long-horizon benchmarks.
- If profile access remains tool-gated, agents will need learned policies for deciding when to query hidden information versus when to ask the user directly.
Load-bearing premise
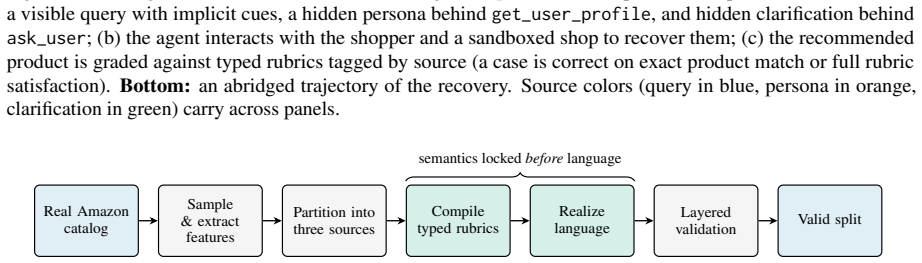
The assumption that automated construction with answers fixed in code before text generation and sample validation produces tasks that reliably reflect real distributed intent without introducing artifacts or biases.
What would settle it
A controlled study in which human shoppers complete the identical 662 tasks using the same tools and show materially different success rates or failure distributions across requirement sources.
Figures
read the original abstract
As LLM-based shopping agents enter production, existing benchmarks fail to capture how a shopper's requirements arrive: stated implicitly in the query, recorded in a profile, or revealed only when the right question is asked. Benchmarks that expose full intent upfront and grade only the final choice can neither pose this long-horizon challenge nor explain which requirement an agent missed. To address this gap, we introduce EComAgentBench, a benchmark of 662 tasks grounded in real Amazon products and reviews. Each task scatters these requirements across a visible query, a tool-gated profile, and scripted clarification; an agent must uncover hidden intent, verify candidates against attributes and review evidence, and commit to a single product within 100 tool calls. Moreover, typed, source-tagged rubrics grade every task, attributing each failure to a requirement and its source. Construction is automated yet reliable, with every answer fixed in code before any text is generated and every sample validated. Our evaluation of seven models reveals that even the strongest attains only 57.1% overall accuracy, and rubric satisfaction degrades from visible to hidden sources. Overall, we believe EComAgentBench will serve as a reproducible foundation for moving shopping agents from single-query search toward dependable assistance over long horizons.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EComAgentBench, a benchmark of 662 tasks grounded in real Amazon products and reviews for evaluating LLM-based shopping agents on long-horizon tasks. Intent is distributed across a visible query, a tool-gated profile, and scripted clarifications; agents must uncover hidden requirements, verify candidates using attributes and reviews, and select one product within 100 tool calls. Typed, source-tagged rubrics attribute failures to specific requirements and sources. Construction is automated by fixing answers in code before text generation followed by sample validation. Evaluation of seven models shows the strongest reaches only 57.1% overall accuracy, with rubric satisfaction degrading from visible to hidden sources.
Significance. If the construction protocol reliably avoids intent leakage or artifacts, the benchmark fills a clear gap by testing distributed hidden intent over extended interactions rather than single-query final-choice grading. The source-tagged rubrics enable precise diagnosis of which requirement and source an agent misses, and the 57.1% ceiling plus visible-to-hidden drop provide concrete, falsifiable evidence of current agent limitations. This supplies a reproducible foundation for progress on dependable long-horizon shopping assistance.
major comments (2)
- [Abstract / Construction] Abstract and Construction section: the claim that construction is 'automated yet reliable, with every answer fixed in code before any text is generated and every sample validated' is load-bearing for attributing the 57.1% accuracy ceiling and visible-to-hidden degradation to agent limitations rather than benchmark artifacts, yet the manuscript supplies no details on the validation process (number of samples checked, validation criteria, detection of generation biases, or inter-rater measures if used).
- [Evaluation / Results] Evaluation / Results section: the reported accuracies (including 57.1% overall and source-specific degradations) are presented without error bars, number of runs per model, or statistical tests for differences across sources; this makes it impossible to assess whether the observed patterns are robust or sensitive to evaluation variance.
minor comments (2)
- [Figures / Tables] Figure and table captions should explicitly define all metrics (e.g., what 'rubric satisfaction' aggregates) and note the total task count (662) for quick reference.
- [Abstract] A few long sentences in the abstract could be split to improve readability without changing content.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify omissions that affect the transparency of the construction protocol and the robustness of the reported results. We address each point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract / Construction] Abstract and Construction section: the claim that construction is 'automated yet reliable, with every answer fixed in code before any text is generated and every sample validated' is load-bearing for attributing the 57.1% accuracy ceiling and visible-to-hidden degradation to agent limitations rather than benchmark artifacts, yet the manuscript supplies no details on the validation process (number of samples checked, validation criteria, detection of generation biases, or inter-rater measures if used).
Authors: We agree that the current manuscript does not provide these validation details, which are needed to substantiate the reliability claim. We will revise the Construction section to describe the validation process, including the number of samples checked, the specific validation criteria applied, steps taken to detect generation biases, and any inter-rater measures used (or note their absence). revision: yes
-
Referee: [Evaluation / Results] Evaluation / Results section: the reported accuracies (including 57.1% overall and source-specific degradations) are presented without error bars, number of runs per model, or statistical tests for differences across sources; this makes it impossible to assess whether the observed patterns are robust or sensitive to evaluation variance.
Authors: We acknowledge that the absence of error bars, run counts, and statistical tests limits assessment of robustness. We will revise the Evaluation and Results sections to include multiple evaluation runs per model, report error bars, and apply statistical tests for differences across sources and models. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark paper introducing 662 tasks with source-tagged rubrics for evaluating shopping agents on long-horizon tasks with distributed hidden intent. Construction relies on fixing answers in code before text generation and sample validation, but no derivations, equations, predictions, or self-citations are present that reduce to inputs by construction. The performance claims (e.g., 57.1% accuracy ceiling) are direct evaluation results against the new benchmark, with no fitted parameters renamed as predictions or uniqueness theorems imported from prior author work. The derivation chain is self-contained as standard benchmark methodology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
ShoppingBench: A Real-World Intent-Grounded Shopping Benchmark for LLM-based Agents , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2026 , doi=
2026
-
[2]
arXiv preprint arXiv:2601.18225 , year=
ShopSimulator: Evaluating and Exploring RL-Driven LLM Agent for Shopping Assistants , author=. arXiv preprint arXiv:2601.18225 , year=
-
[3]
VitaBench: Benchmarking LLM Agents with Versatile Interactive Tasks in Real-world Applications , author=. arXiv preprint arXiv:2509.26490 , year=
-
[4]
Zhang, Yinger and Jiang, Shutong and Li, Renhao and Tu, Jianhong and Su, Yang and Deng, Lianghao and Guo, Xudong and Lv, Chenxu and Lin, Junyang , journal=
-
[5]
Advances in Neural Information Processing Systems , year=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. Advances in Neural Information Processing Systems , year=
-
[6]
Advances in Neural Information Processing Systems, Datasets and Benchmarks Track , year=
Mind2Web: Towards a Generalist Agent for the Web , author=. Advances in Neural Information Processing Systems, Datasets and Benchmarks Track , year=
-
[7]
WebArena: A Realistic Web Environment for Building Autonomous Agents
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. arXiv preprint arXiv:2307.13854 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
-
[9]
arXiv preprint arXiv:2407.15711 , year=
AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks? , author=. arXiv preprint arXiv:2407.15711 , year=
-
[10]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle=. Judging
-
[11]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
Large Language Models are not Fair Evaluators , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
-
[12]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year=
Can Large Language Models Be an Alternative to Human Evaluations? , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year=
- [13]
-
[14]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking
Hou, Yupeng and Li, Jiacheng and Fu, Xiangjun and He, Zhankui and Yan, An and Chen, Xiusi and McAuley, Julian , journal=. Bridging Language and Items for Retrieval and Recommendation: Benchmarking
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.