Recognizing Co-Speech Gestures in-the-Wild
Pith reviewed 2026-06-28 23:12 UTC · model grok-4.3
The pith
The GRW dataset is the first large-scale benchmark for recognizing semantic co-speech gestures with word mappings and precise timing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
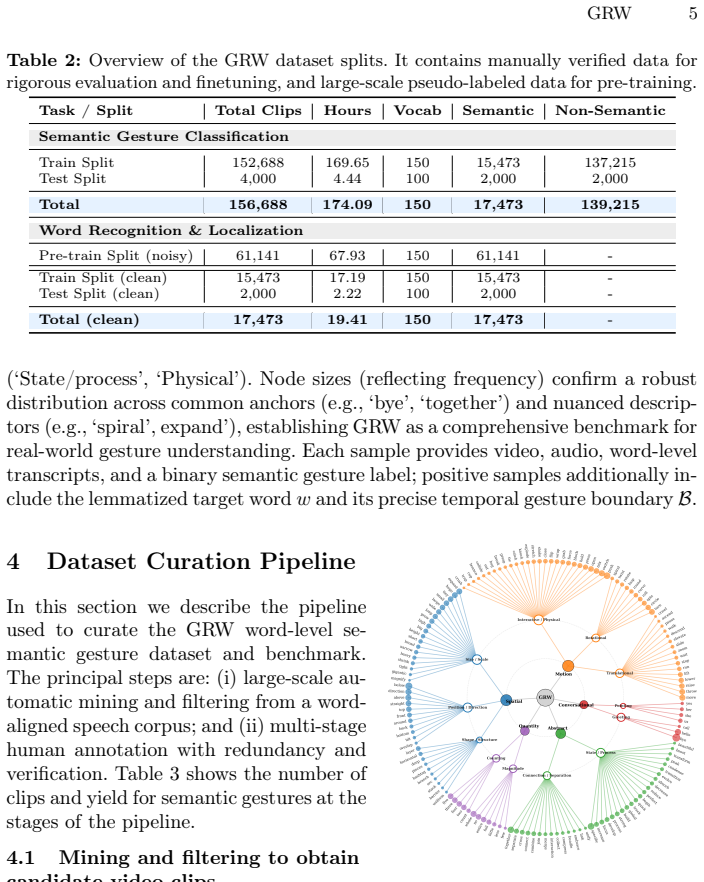
The central discovery is the creation of the GRW dataset comprising 156,688 manually annotated video clips that map unconstrained human gestures to a 150-word taxonomy of physical actions, spatial descriptors, and abstract concepts, with frame-accurate temporal boundaries, enabling benchmarks for classifying semantic gestures, word recognition, and temporal localization.
What carries the argument
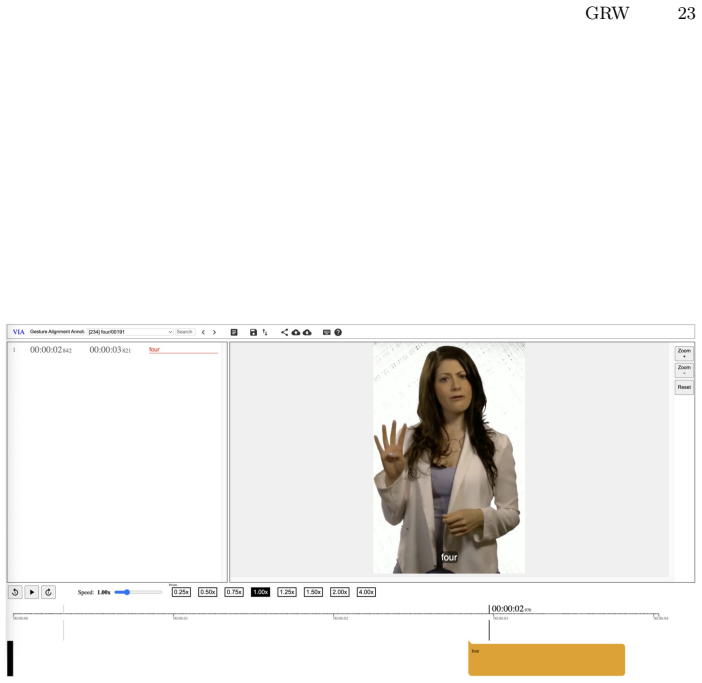
The GRW dataset, which provides manually annotated video clips linking gestures to specific words with precise start and end frames.
If this is right
- Video models can be trained to classify whether a gesture is semantic or not.
- Models can recognize the specific word corresponding to a co-speech gesture.
- Models can temporally localize the gesture within the video.
- Benchmarks are established for these three tasks using the dataset.
Where Pith is reading between the lines
- This dataset could improve the performance of virtual assistants or video analysis tools in understanding contextual gestures.
- It opens the possibility for integrating gesture recognition into real-time speech translation systems.
- Future work might extend the taxonomy to include more words or different languages.
Load-bearing premise
The manual annotations are sufficiently accurate, consistent, and representative of real-world co-speech gestures across diverse videos and the 150-word taxonomy.
What would settle it
A study showing that different annotators disagree significantly on the gesture boundaries or word mappings, or that models trained on GRW fail to generalize to new videos not in the dataset.
Figures





read the original abstract
While humans naturally gesture during speech, only a sparse subset of these movements are visually depictive and semantically linked to specific spoken words. Current multimodal models struggle to capture these semantic co-speech gestures, heavily bottlenecked by a lack of precisely annotated training data. To address this, we introduce the Gesture Recognition in the Wild (GRW) dataset, the first large-scale benchmark designed to map unconstrained human gestures to specific words with frame-accurate temporal boundaries. Comprising 156,688 manually annotated video clips, GRW spans a highly diverse 150-word taxonomy of physical actions, spatial descriptors, and abstract concepts. We leverage GRW to train video models to (a) classify gestures as semantic or not, (b) recognize the word corresponding to a co-speech gesture, and (c) temporally localize the gesture. We also use GRW to establish benchmarks for these three tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the GRW dataset is the first large-scale benchmark designed to map unconstrained human gestures to specific words with frame-accurate temporal boundaries. It comprises 156,688 manually annotated video clips spanning a highly diverse 150-word taxonomy of physical actions, spatial descriptors, and abstract concepts, and is used to define and benchmark three tasks: classifying gestures as semantic or not, recognizing the corresponding word, and temporally localizing the gesture.
Significance. If the annotations are shown to be accurate and consistent, the GRW dataset would address a clear data gap for semantic co-speech gesture understanding in multimodal models, providing scale and diversity that could support reproducible benchmarks across the three tasks.
major comments (2)
- [Abstract] Abstract: the central claim that GRW supplies 'frame-accurate temporal boundaries' for the three tasks rests on the quality of the manual annotations, yet the abstract supplies no annotation protocol, number of annotators per clip, adjudication process, or quantitative agreement statistics (e.g., temporal IoU or label kappa).
- [Abstract] Abstract: without reported inter-annotator agreement or boundary-precision metrics, the weakest assumption—that the 156,688 clips are sufficiently accurate and representative—remains unverified, rendering the benchmark claims for semantic classification, word recognition, and localization unevaluable.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the abstract. We agree that the abstract should more explicitly support the annotation quality underlying the 'frame-accurate' claim and will revise it accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that GRW supplies 'frame-accurate temporal boundaries' for the three tasks rests on the quality of the manual annotations, yet the abstract supplies no annotation protocol, number of annotators per clip, adjudication process, or quantitative agreement statistics (e.g., temporal IoU or label kappa).
Authors: We agree that the abstract would be stronger if it briefly referenced the annotation protocol. The full manuscript (Section 4) describes the multi-annotator process and adjudication. In revision we will add one concise sentence to the abstract summarizing the protocol, annotator count, and agreement statistics. revision: yes
-
Referee: [Abstract] Abstract: without reported inter-annotator agreement or boundary-precision metrics, the weakest assumption—that the 156,688 clips are sufficiently accurate and representative—remains unverified, rendering the benchmark claims for semantic classification, word recognition, and localization unevaluable.
Authors: We acknowledge the point: the current abstract does not report these metrics, making the claims harder to evaluate at a glance. The manuscript body provides annotation details; we will revise the abstract to include a short statement on inter-annotator agreement and boundary precision so the benchmark claims are more directly verifiable. revision: yes
Circularity Check
No circularity: empirical dataset paper with no derivations or fitted predictions.
full rationale
The paper introduces the GRW dataset of 156,688 manually annotated clips and defines three downstream tasks (semantic classification, word recognition, temporal localization). No equations, parameters, or closed-form claims appear anywhere in the provided text. The contribution is a new benchmark definition rather than a derivation that reduces to its own inputs. No self-citations, ansatzes, or uniqueness theorems are invoked to support any mathematical result. Annotation quality concerns (protocol, agreement metrics) affect verifiability but do not constitute circularity under the defined patterns, as there is no reduction of a claimed prediction to a fitted input or self-referential definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manual annotations provide accurate frame-accurate temporal boundaries for gestures.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.22554 (2025)
Agrawal, V., Akinyemi, A., Alvero, K., Behrooz, M., Buffalini, J., Carlucci, F.M., Chen, J., Chen, J., Chen, Z., Cheng, S., et al.: Seamless interaction: Dyadic audio- visual motion modeling and large-scale dataset. arXiv preprint arXiv:2506.22554 (2025)
-
[2]
In: Findings of the association for computational linguistics: EMNLP 2020
Ahuja, C., Lee, D.W., Ishii, R., Morency, L.P.: No gestures left behind: Learning relationships between spoken language and freeform gestures. In: Findings of the association for computational linguistics: EMNLP 2020. pp. 1884–1895 (2020)
2020
-
[3]
arXiv (2021)
Albanie, S., Varol, G., Momeni, L., Bull, H., Afouras, T., Chowdhury, H., Fox, N., Woll, B., Cooper, R., McParland, A., Zisserman, A.: BOBSL: BBC-Oxford British Sign Language Dataset. arXiv (2021)
2021
-
[4]
Alexanderson, S., Henter, G.E., Kucherenko, T., Beskow, J.: Style-controllable speech-driven gesture synthesis using normalising flows39(2), 487–496 (2020)
2020
-
[5]
ACM Transac- tions on Graphics (TOG)41(6), 1–19 (2022)
Ao, T., Gao, Q., Lou, Y., Chen, B., Liu, L.: Rhythmic gesticulator: Rhythm-aware co-speech gesture synthesis with hierarchical neural embeddings. ACM Transac- tions on Graphics (TOG)41(6), 1–19 (2022)
2022
-
[6]
Personality and social psychology bulletin21(4), 394–405 (1995)
Bavelas, J.B., Chovil, N., Coates, L., Roe, L.: Gestures specialized for dialogue. Personality and social psychology bulletin21(4), 394–405 (1995)
1995
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Duarte, A., Palaskar, S., Ventura, L., Ghadiyaram, D., DeHaan, K., Metze, F., Torres, J., Giro-i Nieto, X.: How2sign: a large-scale multimodal dataset for con- tinuous american sign language. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2735–2744 (2021)
2021
-
[8]
In: Proceedings of the 27th ACM International Conference on Multimedia
Dutta, A., Zisserman, A.: The VIA annotation software for images, audio and video. In: Proceedings of the 27th ACM International Conference on Multimedia. MM ’19, ACM, New York, NY, USA (2019).https://doi.org/10.1145/3343031. 3350535,https://doi.org/10.1145/3343031.3350535
-
[9]
ACM Transactions on Graphics (TOG)37(4), 1–11 (2018)
Ephrat, A., Mosseri, I., Lang, O., Dekel, T., Wilson, K., Hassidim, A., Free- man, W.T., Rubinstein, M.: Looking to listen at the cocktail party: a speaker- independent audio-visual model for speech separation. ACM Transactions on Graphics (TOG)37(4), 1–11 (2018)
2018
-
[10]
In: Proceedings of the 18th international conference on intelligent virtual agents
Ferstl, Y., McDonnell, R.: Investigating the use of recurrent motion modelling for speech gesture generation. In: Proceedings of the 18th international conference on intelligent virtual agents. pp. 93–98 (2018)
2018
-
[11]
Computer Animation and Virtual Worlds 32(3-4), e2016 (2021) 16 S Hegde et al
Ferstl, Y., Neff, M., McDonnell, R.: Expressgesture: Expressive gesture generation from speech through database matching. Computer Animation and Virtual Worlds 32(3-4), e2016 (2021) 16 S Hegde et al
2021
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ginosar, S., Bar, A., Kohavi, G., Chan, C., Owens, A., Malik, J.: Learning individ- ual styles of conversational gesture. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3497–3506 (2019)
2019
-
[13]
Google: Gemini 3.https://blog.google/products-and-platforms/products/ gemini/gemini-3/(2026), accessed: 2026-03-06
2026
-
[14]
In: Proceedings of the 63rd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers) (2025)
Gueuwou, S., Du, X., Shakhnarovich, G., Livescu, K., Liu, A.H.: Shubert: Self- supervised sign language representation learning via multi-stream cluster predic- tion. In: Proceedings of the 63rd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers) (2025)
2025
-
[15]
In: BMVC (2023)
Hegde, S., Zisserman, A.: Gestsync: Determining who is speaking without a talking head. In: BMVC (2023)
2023
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hegde, S.B., Prajwal, K., Kwon, T., Zisserman, A.: Understanding co-speech ges- tures in-the-wild. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9977–9987 (2025)
2025
-
[17]
arXiv preprint arXiv:2602.09146 (2026)
Huberman, S., Goldberg, K., Patashnik, O., Benaim, S., Mokady, R.: Semanticmo- ments: Training-free motion similarity via third moment features. arXiv preprint arXiv:2602.09146 (2026)
-
[18]
In: 2019 14th IEEE interna- tional conference on automatic face & gesture recognition (FG 2019)
Köpüklü, O., Gunduz, A., Kose, N., Rigoll, G.: Real-time hand gesture detection and classification using convolutional neural networks. In: 2019 14th IEEE interna- tional conference on automatic face & gesture recognition (FG 2019). IEEE (2019)
2019
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lee, G., Deng, Z., Ma, S., Shiratori, T., Srinivasa, S.S., Sheikh, Y.: Talking with hands 16.2 m: A large-scale dataset of synchronized body-finger motion and audio for conversational motion analysis and synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 763–772 (2019)
2019
-
[20]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Li, D., Rodriguez, C., Yu, X., Li, H.: Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 1459– 1469 (2020)
2020
-
[21]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 5971– 5984 (2024)
2024
-
[22]
In: European conference on computer vision
Liu, H., Zhu, Z., Iwamoto, N., Peng, Y., Li, Z., Zhou, Y., Bozkurt, E., Zheng, B.: Beat: A large-scale semantic and emotional multi-modal dataset for conversa- tional gestures synthesis. In: European conference on computer vision. pp. 612–630. Springer (2022)
2022
-
[23]
MediaPipe: A Framework for Building Perception Pipelines
Lugaresi, C., Tang, J., Nash, H., McClanahan, C., Uboweja, E., Hays, M., Zhang, F., Chang, C.L., Yong, M.G., Lee, J., et al.: Mediapipe: A framework for building perception pipelines. arXiv preprint arXiv:1906.08172 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[24]
Neuro- computing508, 293–304 (2022)
Luo, H., Ji, L., Zhong, M., Chen, Y., Lei, W., Duan, N., Li, T.: Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neuro- computing508, 293–304 (2022)
2022
-
[25]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision workshops (2019)
Materzynska, J., Berger, G., Bax, I., Memisevic, R.: The jester dataset: A large- scale video dataset of human gestures. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision workshops (2019)
2019
-
[26]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Molchanov, P., Yang, X., Gupta, S., Kim, K., Tyree, S., Kautz, J.: Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4207–4215 (2016) GRW 17
2016
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Mughal, M.H., Dabral, R., Habibie, I., Donatelli, L., Habermann, M., Theobalt, C.:Convofusion:Multi-modalconversationaldiffusionforco-speechgesturesynthe- sis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1388–1398 (2024)
2024
-
[28]
Nyatsanga, S., Kucherenko, T., Ahuja, C., Henter, G.E., Neff, M.: A comprehensive review of data-driven co-speech gesture generation42(2), 569–596 (2023)
2023
-
[29]
In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Prajwal, K., Hegde, S., Zisserman, A.: Scaling multilingual visual speech recogni- tion. In: ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2025)
2025
-
[30]
Quiros, L.C., Tax, D.M.J., Hung, H.: Gestures in-the-wild: Detecting conversa- tional hand gestures in crowded scenes using a multimodal fusion of bags of video trajectories and body worn acceleration. IEEE Trans. Multim.22(1), 138–147 (2020).https://doi.org/10.1109/TMM.2019.2922122,https://doi.org/10. 1109/TMM.2019.2922122
-
[31]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Su, J., Lu, Y., Pan, S., Wen, B., Liu, Y.: Roformer: Enhanced transformer with rotary position embedding. CoRRabs/2104.09864(2021),https://arxiv.org/ abs/2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Advances in Neural Information Pro- cessing Systems pp
Uthus, D., Tanzer, G., Georg, M.: Youtube-asl: A large-scale, open-domain amer- ican sign language-english parallel corpus. Advances in Neural Information Pro- cessing Systems pp. 29029–29047 (2023)
2023
-
[33]
In: Proceed- ings of the IEEE conference on computer vision and pattern recognition workshops
Wan, J., Zhao, Y., Zhou, S., Guyon, I., Escalera, S., Li, S.Z.: Chalearn looking at people rgb-d isolated and continuous datasets for gesture recognition. In: Proceed- ings of the IEEE conference on computer vision and pattern recognition workshops. pp. 56–64 (2016)
2016
-
[34]
In: European conference on computer vision
Wang, C.Y., Yeh, I.H., Mark Liao, H.Y.: Yolov9: Learning what you want to learn using programmable gradient information. In: European conference on computer vision. pp. 1–21. Springer (2024)
2024
-
[35]
In: European Conference on Computer Vision
Wang, Y., Li, K., Li, Y., He, Y., Huang, B., Zhao, Z., Yin, H., Chen, J., Jin, T., Wu, J., et al.: Internvideo2: Scaling video foundation models for multimodal video understanding. In: European Conference on Computer Vision. Springer (2024)
2024
-
[36]
IEEE Transactions on Multimedia pp
Zhang, Y., Cao, C., Cheng, J., Lu, H.: Egogesture: A new dataset and benchmark for egocentric hand gesture recognition. IEEE Transactions on Multimedia pp. 1038–1050 (2018)
2018
-
[37]
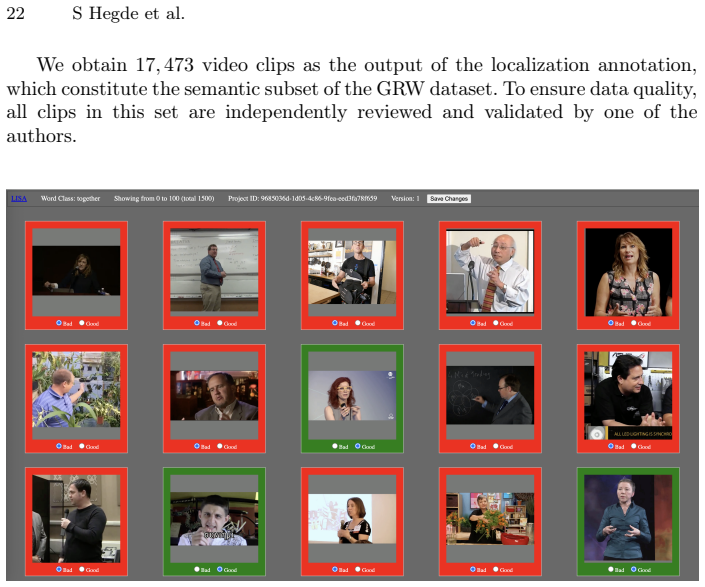
Zhu, B., Lin, B., Ning, M., Yan, Y., Cui, J., Wang, H., Pang, Y., Jiang, W., Zhang, J.,Li,Z.,etal.:Languagebind:Extendingvideo-languagepretrainington-modality by language-based semantic alignment. arXiv preprint arXiv:2310.01852 (2023) 18 S Hegde et al. A Dataset A.1 Data samples Fig 8 illustrates representative samples from the semantic subset of our man...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
No semantic gestures present in the video
-
[39]
Semantic gesture may be present, but is not clear and/or is not fully visible
-
[40]
Yes” (gesture found) or “No
Semantic gesture present, and is clearly visible. –Make a decision: “Yes” (gesture found) or “No” (gesture not found). The decision will be “Yes” only if category 3 occurs as explained above. –Give the confidence score between 0 and 1, 0 being the least confident and 1 being the most confident. –Provide a short reasoning. Output Format: Gesture present: <...
-
[41]
Analyze all the frames of the video together and produce one final gesture description that best represents what the hands are gesturing throughout these frames
-
[42]
Based on the description, rank a given set of 100 possible word classes with confidence scores (between 0 and 1) such that they sum to approximately 1.0
-
[43]
raising hand then pointing forward
Predict the start and end time of the gesture in seconds (gesture boundary) for the recognized target word. Classes:bye, below, push, move, direction, specific, together, whole, hello, straight, above, switch, five, turn, expand, throw, open, huge, raise, large, tiny, long, mix, circle, no, two, three, entire, top, four, lower, full, press, small, grab, g...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.