Reasoning Models Don't Just Think Longer, They Move Differently
Pith reviewed 2026-05-19 14:39 UTC · model grok-4.3
The pith
After length correction, reasoning models show distinct hidden-state trajectories on harder problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
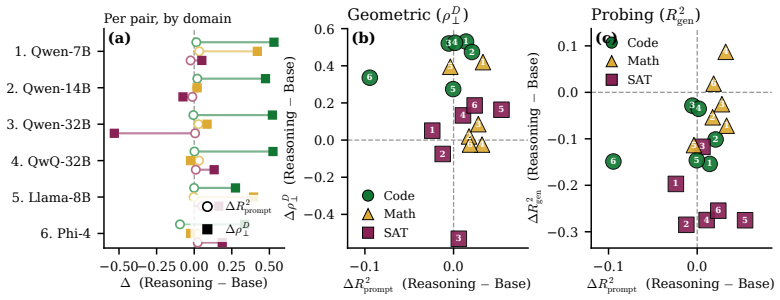
After residualizing trajectory statistics on length, difficulty remains systematically coupled to corrected trajectory geometry across all domains studied. The clearest reasoning-specific separation appears in the code domain, where harder problems show more direct corrected trajectories and less heterogeneous local curvature in reasoning-trained models than in matched instruction-tuned baselines. Corrected difficulty-geometry coupling is weaker, but still present, in mathematics and Boolean satisfiability.
What carries the argument
Length-residualized hidden-state trajectory geometry, which removes mechanical effects of generation length to isolate difficulty-linked path shape and curvature.
If this is right
- Difficulty-geometry coupling after length correction holds across code, mathematics, and Boolean satisfiability.
- Reasoning-trained models produce more direct corrected paths and lower curvature variation than baselines on hard code problems.
- Prompt-stage linear probes do not reproduce the code-domain separation seen during generation.
- Stronger corrected coupling appears together with shifts in reasoning strategy and uncertainty monitoring.
Where Pith is reading between the lines
- The same length-correction approach could be applied to study trajectories in non-reasoning tasks such as creative writing or planning.
- Internal trajectory measures might eventually allow diagnosis of reasoning skill without relying on final answer correctness.
- Domain differences raise the possibility that code reasoning benefits more from direct paths than mathematical reasoning does.
Load-bearing premise
That residualizing raw trajectory statistics on generation length removes every mechanical length effect and leaves only the part due to reasoning strategy or internal computation.
What would settle it
Observing no remaining correlation between difficulty and corrected trajectory geometry in the code domain after length residualization would falsify the claimed reasoning-specific separation.
Figures








read the original abstract
Reasoning-trained language models often spend more tokens on harder problems, but longer chains of thought do not show whether a model is merely computing for more steps or following a different internal trajectory. We study this distinction through hidden-state trajectories during chain-of-thought generation across competitive programming, mathematics, and Boolean satisfiability. Raw trajectory geometry is strongly shaped by generation length: longer generations mechanically alter path statistics, so difficulty-dependent comparisons are misleading without adjustment. After residualizing trajectory statistics on length, difficulty remains systematically coupled to corrected trajectory geometry across all domains studied. The clearest reasoning-specific separation appears in the code domain, where harder problems show more direct corrected trajectories and less heterogeneous local curvature in reasoning-trained models than in matched instruction-tuned baselines. Corrected difficulty-geometry coupling is weaker, but still present, in mathematics and Boolean satisfiability. Prompt-stage linear probes do not mirror the code-domain separation, and behavioral annotations show that stronger corrected coupling co-occurs with strategy shifts and uncertainty monitoring. Together, these findings establish length correction as a prerequisite for generation-time trajectory analysis and show that reasoning training can be associated with distinct corrected trajectory geometry, with the strength of the effect depending on the domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that raw hidden-state trajectory geometry during chain-of-thought generation is strongly shaped by generation length across competitive programming, mathematics, and Boolean satisfiability tasks. After residualizing trajectory statistics (e.g., directness and local curvature heterogeneity) on length, difficulty remains systematically coupled to the corrected geometry in all domains, with the clearest reasoning-specific separation in the code domain: harder problems yield more direct corrected trajectories and less heterogeneous curvature in reasoning-trained models than in matched instruction-tuned baselines. Weaker but present couplings appear in math and SAT; prompt-stage probes do not show the code separation, and behavioral annotations link stronger coupling to strategy shifts.
Significance. If the residualization step is shown to be robust, the work would establish that reasoning training produces distinct internal trajectory geometries beyond mere increases in length, offering a concrete geometric signature for reasoning strategies. The multi-domain design and explicit baseline comparisons are strengths that allow domain-specific effect sizes to be compared directly. The findings could guide future interpretability work that treats trajectory shape, rather than token count, as the primary variable.
major comments (1)
- [Abstract and §3 (residualization procedure)] The central claim that 'difficulty remains systematically coupled to corrected trajectory geometry' after residualization rests on an unshown statistical procedure. No details are provided on the functional form of the length model (linear vs. nonlinear), whether interactions with domain or difficulty were included, the resulting R² or residual variance, or sensitivity checks. This is load-bearing for the reported code-domain separation and the weaker math/SAT results.
minor comments (1)
- [Abstract] The abstract states that prompt-stage linear probes 'do not mirror the code-domain separation' but does not report the probe accuracies or feature sets used, making it hard to interpret the negative result.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The residualization procedure is indeed central to our claims, and we have revised the manuscript to supply the missing methodological details and robustness checks.
read point-by-point responses
-
Referee: [Abstract and §3 (residualization procedure)] The central claim that 'difficulty remains systematically coupled to corrected trajectory geometry' after residualization rests on an unshown statistical procedure. No details are provided on the functional form of the length model (linear vs. nonlinear), whether interactions with domain or difficulty were included, the resulting R² or residual variance, or sensitivity checks. This is load-bearing for the reported code-domain separation and the weaker math/SAT results.
Authors: We agree that the original submission did not provide sufficient detail on the residualization procedure. In the revised manuscript we now specify that a linear regression was fit separately for each trajectory statistic with generation length as the sole predictor; no interactions with domain or difficulty were included after preliminary diagnostics showed that quadratic terms and domain-stratified models produced only marginal changes in the residualized difficulty couplings. We report per-statistic R² values (0.38–0.62) and residual standard deviations in a new appendix table, and we add sensitivity analyses confirming that the code-domain separation and the weaker math/SAT patterns remain statistically significant under both quadratic residualization and leave-one-domain-out checks. These additions make the procedure fully reproducible and directly address its load-bearing role for the reported results. revision: yes
Circularity Check
No significant circularity; residualization is a standard control step
full rationale
The paper's derivation applies residualization of trajectory statistics on generation length as an explicit adjustment to remove mechanical confounds before examining difficulty-geometry coupling. This is presented as a prerequisite correction rather than a fitted prediction or self-definitional step that forces the reported result. No equations reduce the final coupling claim to a parameter chosen to produce that coupling, and no load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The central finding (persistent corrected coupling, stronger in code) is not equivalent to the inputs by construction and remains falsifiable. This is the most common honest outcome for papers using standard statistical adjustments.
Axiom & Free-Parameter Ledger
free parameters (1)
- length residualization model coefficients
axioms (1)
- domain assumption Hidden-state trajectories during token generation form a meaningful geometric object whose statistics can be compared after length correction.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
After residualizing trajectory statistics on length, difficulty remains systematically coupled to corrected trajectory geometry
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Directness D = Δ/L and curvature variability V = sd(κ)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yao Huang, Huanran Chen, Shouwei Ruan, Yichi Zhang, Xingxing Wei, and Yinpeng Dong. Mitigat- ing overthinking in large reasoning models via manifold steering.arXiv preprint arXiv:2505.22411,
-
[2]
Ian T. Jolliffe and Jorge Cadima. Principal component analysis: A review and recent developments. Philosophical Transactions of the Royal Society A, 374(2065):20150202,
work page 2065
-
[3]
arXiv preprint arXiv:2510.05969 , year=
Sunbowen Lee, Qingyu Yin, Chak Tou Leong, Jialiang Zhang, Yicheng Gong, Shiwen Ni, Min Yang, and Xiaoyu Shen. Probing the difficulty perception mechanism of large language models.arXiv preprint arXiv:2510.05969,
-
[4]
LLMs encode how difficult problems are.arXiv preprint arXiv:2510.18147,
William Lugoloobi and Chris Russell. LLMs encode how difficult problems are.arXiv preprint arXiv:2510.18147,
-
[5]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Jinyan Su, Jennifer Healey, Preslav Nakov, and Claire Cardie. Between underthinking and over- thinking: An empirical study of reasoning length and correctness in LLMs.arXiv preprint arXiv:2505.00127,
-
[7]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Datasets and Benchmarks Track, Spotlight. Anjiang Wei, Yuheng Wu, Yingjia Wan, Tarun Suresh, Huanmi Tan, Zhanke Zhou, Sanmi Koyejo, Ke Wang, and Alex Aiken. SATBench: Benchmarking LLMs’ logical reasoning via automated puzzle generation from SAT formulas. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33832–...
work page 2025
-
[9]
SATB ench: Benchmarking LLM s' Logical Reasoning via Automated Puzzle Generation from SAT Formulas
doi: 10.18653/v1/2025.emnlp-main.1716. Zhiyu Xu, Jia Liu, Yixin Wang, and Yuqi Gu. Latency-response theory model: Evaluating large lan- guage models via response accuracy and chain-of-thought length.arXiv preprint arXiv:2512.07019,
-
[10]
Hongli Zhou, Hui Huang, Ziqing Zhao, et al. Lost in benchmarks? Rethinking large language model benchmarking with item response theory.arXiv preprint arXiv:2505.15055,
-
[11]
Per-domain calibration pools contain 32 models on each domain
The remaining 21 models contribute correctness data only and stabilize the IRT difficulty scale. Per-domain calibration pools contain 32 models on each domain. Table 2: All models used in this study. Hidden dimension d and layer count L are shown for the matched-pair models.θ code,θ math,θ sat are pooled binomial Rasch ability estimates per domain. Model ...
work page 2000
-
[12]
SAT has no boundary items in the 32-model calibration pool: all 500 SATBench instances are informative. 1000 1500 2000 2500 Codeforces Glicko-2 rating −5 0 5 IRT difficulty bj Code ½ = 0:552; r = 0:520 (a) L1 L2 L3 L4 L5 MATH level Math ½ = 0:435; H = 100:3 (b) 20 40 SAT clause count SAT ½ = 0:536; r = 0:572 (c) Figure 5: External validation using labels ...
work page 2000
-
[13]
are excluded, and nearest neighbors are computed within the sampled states of the same trajectory. PCA90 dimensionality.PCA90 reports the smallest number of principal components capturing 90% of the variance of the trajectory’s sampled states [Jolliffe and Cadima, 2016]. LetZ∈R T×d be the matrix of sampled trajectory states after centering across the T sa...
work page 2016
-
[14]
Let me try a different approach,
before probing. At each layer for the prompt stage and each (layer, position) cell for the generation stage, we standardize features and fit a Ridge probe [Alain and Bengio, 2017]. RidgeCV selects λ∈ {10−2,10 −1,1,10,10 2,10 3,10 4} by leave-one-out cross-validation, and generalization is estimated by 5-fold cross-validated R2. A surface-feature floor use...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.