Density Field State Space Models: 1-Bit Distillation, Efficient Inference, and Knowledge Organization in Mamba-2
Pith reviewed 2026-07-01 08:53 UTC · model grok-4.3
The pith
A 1-bit scaffold with int8 low-rank correction compresses Mamba-2 1.3B to 278 MB while running 21.4 times faster on GPU and retaining performance within 2-4 points of larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
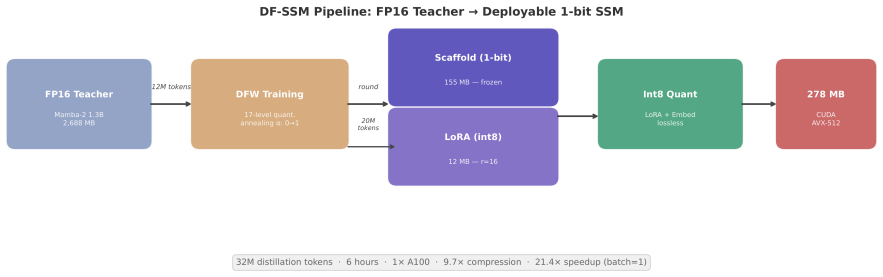
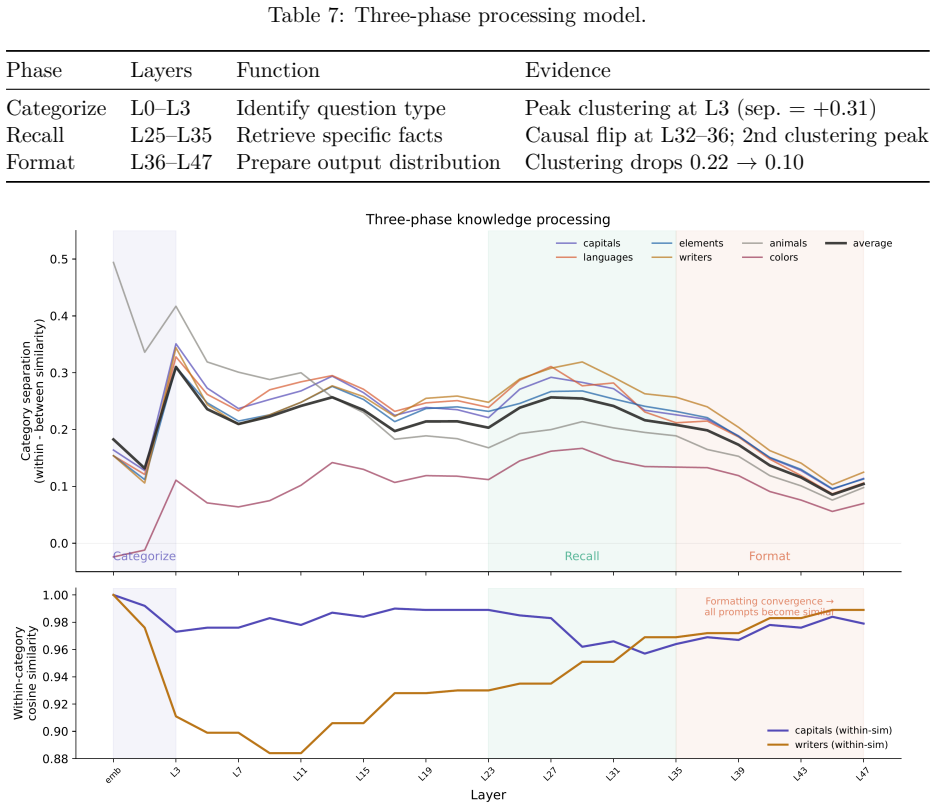
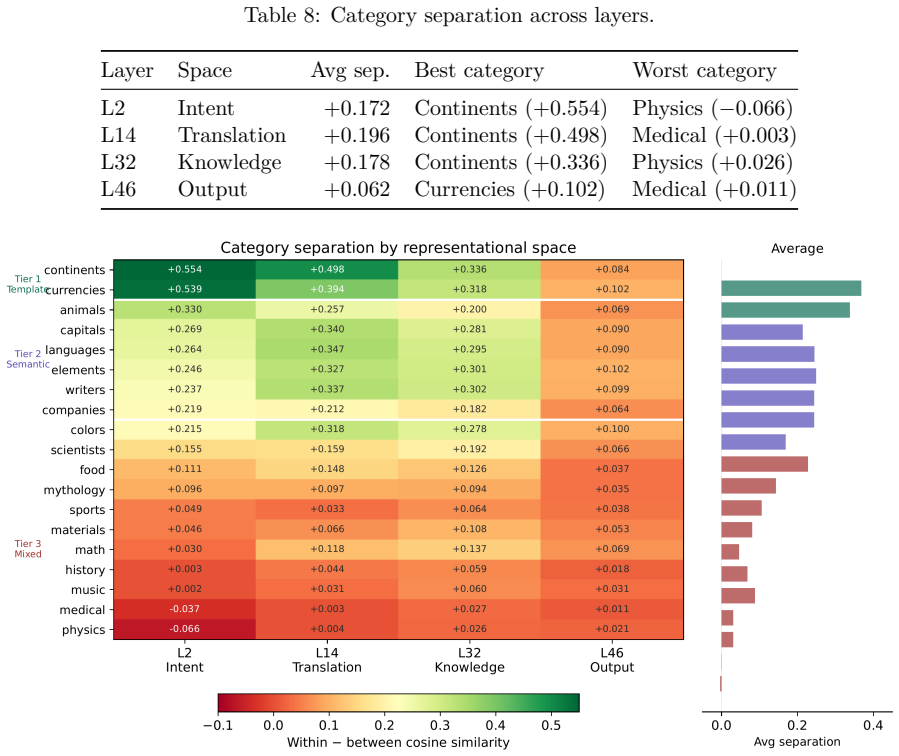
The central claim is that DF-SSM can represent the parameters of an SSM like Mamba-2 on a 1-bit density field scaffold corrected by int8 low-rank terms, allowing distillation from a pretrained FP16 teacher in only 32M tokens to achieve 9.7x size reduction and 21.4x inference speedup while keeping task performance close to that of models trained on far more data, and that the compressed model exhibits distinct phases where early layers classify input intent syntactically, middle layers retrieve facts in a localized window, and late layers handle output formatting.
What carries the argument
The 1-bit density field scaffold with int8 low-rank correction that encodes the state space dynamics for both compression and fast inference.
If this is right
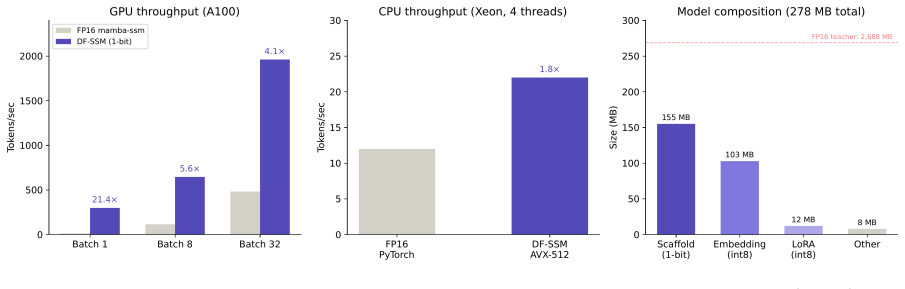
- The resulting 278 MB model maintains downstream task performance within 2-4 percentage points of BitMamba-2 trained on 150B tokens.
- Inference runs 21.4x faster on GPU at batch size 1 using custom CUDA kernels and cuBLAS INT8 tensor cores.
- Factual associations localize to layers 25-35, a 5-layer window.
- Early layers 0-3 perform syntactic classification based on template structure rather than semantic content.
- The full distillation process completes in 6 hours on a single A100 GPU.
Where Pith is reading between the lines
- The phase separation observed in the compressed model might also appear in full precision versions and could be used to guide layer-wise quantization strategies.
- Applying DF-SSM to other state space model variants would test if the compression and phase findings generalize beyond Mamba-2.
- The discovery that organized structure exists even with limited factual recall suggests that factual accuracy can be improved by building on existing representational organization rather than starting from random weights.
- Future experiments could measure whether the syntactic nature of early layers limits the model's ability to handle semantically complex prompts from the start.
Load-bearing premise
The method assumes that a high-quality pretrained FP16 teacher model exists and that its representations can be transferred to the 1-bit scaffold using only 32M tokens of distillation data.
What would settle it
Observing whether a DF-SSM distilled from a low-quality or randomly initialized teacher still achieves performance within 4 points of the reference on downstream tasks would determine if the strong teacher is essential.
Figures
read the original abstract
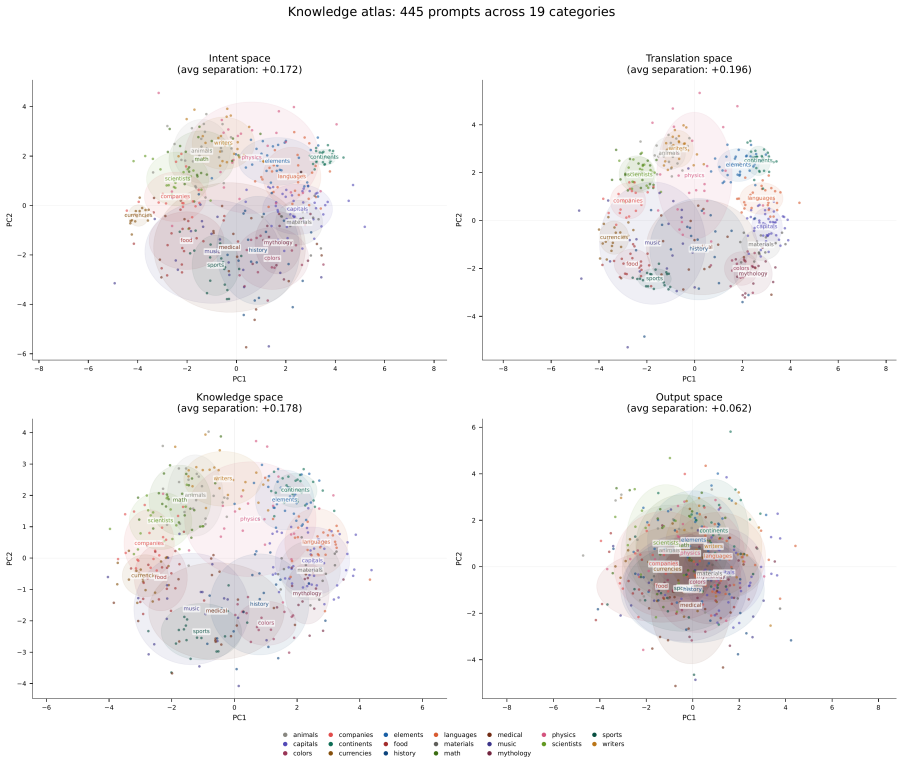
We present Density Field State Space Models (DF-SSM), a framework for compressing SSMs to a 1-bit scaffold with int8 low-rank correction. Applied to Mamba-2 1.3B, we achieve a 278 MB model (9.7x smaller than the 2.7 GB FP16 teacher) that runs at 21.4x faster inference on GPU (batch=1, relative to the mamba-ssm reference implementation) while maintaining downstream task performance within 2-4 percentage points of BitMamba-2, a 1.58-bit model trained from scratch on 150B tokens. The distillation itself requires only 32M tokens and 6 hours on a single A100 GPU, though it presupposes a pretrained FP16 teacher. We develop an optimized inference pipeline combining cuBLAS INT8 tensor cores for the scaffold matmul, custom CUDA kernels for stateful SSM and convolution operations, and an AVX-512 CPU backend for efficient deployment on both GPU and CPU. Beyond compression, we investigate the internal knowledge organization of the resulting model, discovering three distinct processing phases: intent classification (layers 0-3, operating in an abstract space with no vocabulary alignment), knowledge retrieval (layers 25-35, where factual associations localize to a 5-layer window), and output formatting (layers 36-47, where category structure dissolves). Through systematic analysis of 445 factual prompts across 19 categories, we find that early-layer classification is syntactic (driven by template structure) rather than semantic, and that the model exhibits well-organized knowledge representations despite weak factual recall--suggesting that representational structure may precede factual strength.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Density Field State Space Models (DF-SSM), a 1-bit distillation framework with int8 low-rank correction for compressing pretrained Mamba-2 models. Applied to the 1.3B Mamba-2, it reports a 278 MB model (9.7x smaller than the 2.7 GB FP16 teacher) achieving 21.4x faster GPU inference (batch=1) while staying within 2-4 percentage points of BitMamba-2 (a 1.58-bit model trained from scratch on 150B tokens), using only 32M tokens and 6 hours on one A100 for distillation. It also presents an optimized inference stack (cuBLAS INT8, custom CUDA SSM kernels, AVX-512 CPU backend) and an analysis of internal knowledge organization across 445 factual prompts, identifying three phases: intent classification (layers 0-3), knowledge retrieval (layers 25-35), and output formatting (layers 36-47).
Significance. If the compression and performance claims hold under verification, the work offers a data-efficient route to deployable 1-bit SSMs with substantial size and speed gains, plus empirical evidence on layered representational structure that could inform future interpretability studies of recurrent models. The custom kernel pipeline and the scale of the prompt-based knowledge analysis (445 prompts, 19 categories) are concrete strengths.
major comments (2)
- [§3 and abstract] §3 (method) and abstract: the usability claim that the 1-bit scaffold plus int8 low-rank correction 'faithfully reproduces' the teacher's SSM recurrence after 32M-token distillation is load-bearing for the downstream parity result, yet no direct comparison of the discretized state matrix A, selective scan outputs, or state-transition error is provided; without this, the 2-4 pp claim cannot be assessed for longer contexts or OOD inputs.
- [Results] Results section (implied by abstract deltas): the headline performance numbers (size, speed, accuracy) are reported without a benchmark list, per-task scores, error bars, or statistical significance tests against BitMamba-2, undermining evaluation of the 'within 2-4 percentage points' claim.
minor comments (2)
- Notation for the low-rank correction dimension is introduced as a free parameter but its exact value and sensitivity are not tabulated.
- [abstract] The abstract states 'BitMamba-2' as the reference but does not clarify whether this is an external baseline or reimplemented; a citation or implementation note would help.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on verification of the distillation process and evaluation details. We respond to each major comment below.
read point-by-point responses
-
Referee: [§3 and abstract] §3 (method) and abstract: the usability claim that the 1-bit scaffold plus int8 low-rank correction 'faithfully reproduces' the teacher's SSM recurrence after 32M-token distillation is load-bearing for the downstream parity result, yet no direct comparison of the discretized state matrix A, selective scan outputs, or state-transition error is provided; without this, the 2-4 pp claim cannot be assessed for longer contexts or OOD inputs.
Authors: We agree that direct comparisons of the discretized state matrix A, selective scan outputs, and state-transition error would provide stronger support for the 'faithfully reproduces' claim and allow better assessment for longer contexts or OOD inputs. The manuscript currently uses downstream task parity as the primary evidence of effective distillation. In the revision we will add these explicit analyses to §3, including quantitative error metrics and example comparisons. revision: yes
-
Referee: [Results] Results section (implied by abstract deltas): the headline performance numbers (size, speed, accuracy) are reported without a benchmark list, per-task scores, error bars, or statistical significance tests against BitMamba-2, undermining evaluation of the 'within 2-4 percentage points' claim.
Authors: The current results are presented in aggregated form. We will revise the results section to include the full benchmark list, per-task scores, error bars from repeated evaluations, and statistical significance tests versus BitMamba-2. revision: yes
Circularity Check
No significant circularity; empirical results against external references
full rationale
The paper reports direct empirical measurements of model size, inference speed, and downstream accuracy for a distilled 1-bit Mamba-2 variant, benchmarked against external references (FP16 teacher, BitMamba-2 trained from scratch on 150B tokens, mamba-ssm kernel). No equations, fitted parameters, or self-citations are shown that reduce the reported metrics to quantities defined by the same experiment. The distillation process is described as a practical engineering procedure presupposing an external teacher model; the knowledge-organization analysis is observational on factual prompts. The derivation chain is self-contained against external benchmarks with no load-bearing reductions to self-defined inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- low-rank correction dimension
axioms (1)
- domain assumption A high-quality pretrained FP16 Mamba-2 teacher model is available for distillation.
invented entities (1)
-
Density Field State Space Model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The hidden attention of mamba models
Ameen Ali, Itamar Zimerman, and Lior Wolf. The hidden attention of mamba models. arXiv preprint arXiv:2403.01590, 2024
-
[2]
Probing classifiers: Promises, shortcomings, and advances
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 48 0 (1): 0 207--219, 2022
2022
-
[3]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Quip\#: Even better llm quantization with hadamard incoherence and lattice codebooks
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher De Sa. Quip\#: Even better llm quantization with hadamard incoherence and lattice codebooks. In ICML, 2024
2024
-
[5]
Knowledge neurons in pretrained transformers
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. In ACL, 2022
2022
-
[6]
Transformers are ssms: Generalized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality. In ICML, 2024
2024
-
[7]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. In NeurIPS, 2023
2023
-
[8]
Spqr: A sparse-quantized representation for near-lossless llm weight compression
Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. Spqr: A sparse-quantized representation for near-lossless llm weight compression. In ICLR, 2024
2024
-
[9]
Mechanistic interpretability of mamba, 2024
Danielle Ensign and Adri \`a Garriga-Alonso. Mechanistic interpretability of mamba, 2024
2024
-
[10]
Gptq: Accurate post-training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. In ICLR, 2023
2023
-
[11]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher R \'e . Efficiently modeling long sequences with structured state spaces. In ICLR, 2022
2022
-
[13]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[14]
arXiv preprint arXiv:2411.11694 , year=
Haowen Jiang et al. Bi-mamba: Towards accurate 1-bit state space models. arXiv preprint arXiv:2411.11694, 2024
-
[15]
Squeezellm: Dense-and-sparse quantization
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W Mahoney, and Kurt Keutzer. Squeezellm: Dense-and-sparse quantization. In ICML, 2024
2024
-
[16]
Understanding and improving knowledge distillation for quantization-aware training, 2021
Sungrae Kim et al. Understanding and improving knowledge distillation for quantization-aware training, 2021
2021
-
[17]
Awq: Activation-aware weight quantization for llm compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration. In MLSys, 2024
2024
-
[18]
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. The era of 1-bit llms: All large language models are in 1.58 bits. arXiv preprint arXiv:2402.17764, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Locating and editing factual associations in gpt
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. In Advances in Neural Information Processing Systems, 2022
2022
-
[20]
Mass-editing memory in a transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass-editing memory in a transformer. In ICLR, 2023
2023
-
[21]
Interpreting gpt: The logit lens
nostalgebraist. Interpreting gpt: The logit lens. LessWrong, 2020
2020
-
[22]
BitNet: Scaling 1-bit Transformers for Large Language Models
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huishuai Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. Bitnet: Scaling 1-bit transformers for large language models. arXiv preprint arXiv:2310.11453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Q8bert: Quantized 8bit bert
Ofir Zafrir, Guy Boudoukh, Peter Izsak, and Moshe Wasserblat. Q8bert: Quantized 8bit bert. In NeurIPS EMC2 Workshop, 2019
2019
-
[24]
Bitmamba-2: A scalable 1.58-bit state space model, 2025
Zhayr et al. Bitmamba-2: A scalable 1.58-bit state space model, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.