OASIF: An Efficient Obfuscation-Aware Self-Improving Framework for LLM-Based Assembly Code Instruction Following and Comprehension
Pith reviewed 2026-06-30 02:53 UTC · model grok-4.3
The pith
OASIF improves LLM success rates on obfuscated assembly code by 5.8 to 16.9 percentage points via three-phase self-evolving training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
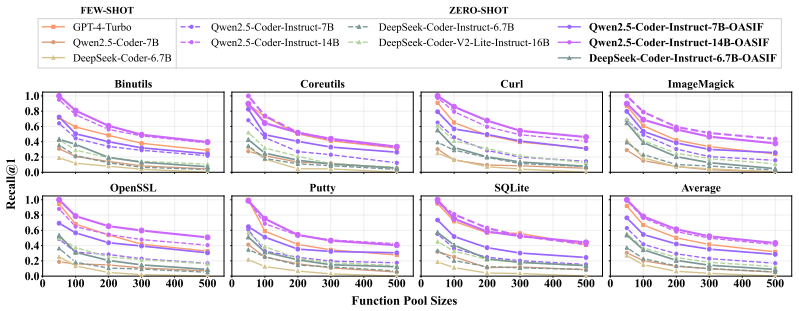
OASIF couples a token-efficient assembly encoder with a lightweight projector and follows three-phase training of feature-space alignment, supervised instruction fine-tuning, and online self-evolving reinforcement learning with hybrid rewards. This produces stable gains on VMISA-Bench, where Qwen2.5-Coder-Instruct-14B records success-rate lifts of 15.9, 5.8, and 16.9 percentage points against Code Virtualizer, Themida v3.0.7, and VMProtect v3.5, plus a 9.8-point average lift on OASIF-Bench, while also showing stable gains on seven BCSD benchmarks and no loss on HumanEval, VulBench, and HumanEval-Decompile.
What carries the argument
The online self-evolving reinforcement learning phase with hybrid rewards that drives continual adaptation after the initial alignment and fine-tuning stages.
Load-bearing premise
The online self-evolving reinforcement learning phase produces stable continual adaptation with only minimal manual verification and without reward hacking or distribution shift.
What would settle it
A controlled run in which the self-evolving reinforcement learning phase is disabled or replaced by standard RL and the resulting model shows no gain or a drop on the three commercial obfuscators in VMISA-Bench.
Figures

read the original abstract
Large Language Models (LLMs) have recently shown promise in automated binary analysis, yet they remain brittle under commercial-grade obfuscation. We present OASIF, an Obfuscation-Aware Self-evolving Instruction-Following framework for obfuscated assembly comprehension. OASIF couples a token-efficient assembly encoder with a lightweight projector to expose long obfuscated code to a pretrained code LLM under a bounded context budget and follows a three-phase training: (i) feature-space alignment, (ii) supervised instruction fine-tuning, and (iii) online self-evolving reinforcement learning with hybrid rewards, enabling continual adaptation with minimal manual verification. On VMISA-Bench, a challenging out-of-distribution suite featuring three commercial VM-based obfuscators, OASIF consistently improves open-source backbones; Qwen2.5-Coder-Instruct-14B attains Success Rate gains of +15.9, +5.8, and +16.9 percentage points (pp) on Code Virtualizer, Themida (v3.0.7), and VMProtect (v3.5), respectively, and improves the OASIF-Bench average by +9.8. OASIF further delivers stable gains across seven standard BCSD benchmarks while preserving general and domain-relevant capabilities on HumanEval, VulBench, and HumanEval-Decompile.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents OASIF, an Obfuscation-Aware Self-evolving Instruction-Following framework for LLMs in assembly code comprehension under obfuscation. It features a token-efficient encoder and projector for bounded context, and a three-phase training pipeline: (i) feature-space alignment, (ii) supervised instruction fine-tuning, and (iii) online self-evolving reinforcement learning with hybrid rewards for continual adaptation with minimal manual verification. The paper reports success rate improvements of +15.9, +5.8, and +16.9 percentage points on VMISA-Bench for Code Virtualizer, Themida (v3.0.7), and VMProtect (v3.5) respectively using Qwen2.5-Coder-Instruct-14B, along with +9.8 on OASIF-Bench average, and stable gains on seven BCSD benchmarks while maintaining performance on HumanEval, VulBench, and HumanEval-Decompile.
Significance. If the empirical results hold under rigorous scrutiny, this work could have significant implications for automated binary analysis and reverse engineering by making LLMs more robust to commercial-grade obfuscation. The self-evolving RL component with hybrid rewards offers a novel approach to continual learning in this domain with reduced human oversight. The preservation of general capabilities is noteworthy. However, the lack of detailed experimental information limits the current assessment of its impact.
major comments (3)
- [Abstract] Abstract: The hybrid reward formulation for the online self-evolving reinforcement learning phase (phase iii) is not provided. This is load-bearing for the central claim because the abstract explicitly credits this phase for stable continual adaptation under minimal manual verification, yet without the reward definition, online sampling loop, or verification process it is impossible to evaluate the risk of reward hacking or distribution shift that could explain the reported gains rather than the supervised stages.
- [Abstract] Abstract: No details are supplied on baselines, statistical significance testing, error bars, data splits, or the precise experimental protocol for the VMISA-Bench results. This undermines assessment of the +15.9 / +5.8 / +16.9 pp gains and the attribution of those gains to the full three-phase OASIF pipeline.
- [Abstract] Abstract: No ablations are described that isolate the contribution of phase (iii) from phases (i) and (ii). Without such controls, the headline improvements cannot be confidently linked to the self-evolving RL component that the manuscript presents as the key enabler of continual adaptation.
minor comments (1)
- [Abstract] The abstract would be strengthened by a one-sentence outline of the hybrid reward components even at high level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in the abstract. We address each major comment below and will revise the manuscript accordingly to improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The hybrid reward formulation for the online self-evolving reinforcement learning phase (phase iii) is not provided. This is load-bearing for the central claim because the abstract explicitly credits this phase for stable continual adaptation under minimal manual verification, yet without the reward definition, online sampling loop, or verification process it is impossible to evaluate the risk of reward hacking or distribution shift that could explain the reported gains rather than the supervised stages.
Authors: The hybrid reward formulation, online sampling loop, and verification process are defined in Section 3.3 of the manuscript as a weighted combination of task-success, token-efficiency, and obfuscation-robustness terms, with PPO updates on high-reward trajectories requiring only spot-check verification. To address the concern that this is not immediately accessible from the abstract, we will add a concise description of the hybrid reward to the abstract in the revision. revision: yes
-
Referee: [Abstract] Abstract: No details are supplied on baselines, statistical significance testing, error bars, data splits, or the precise experimental protocol for the VMISA-Bench results. This undermines assessment of the +15.9 / +5.8 / +16.9 pp gains and the attribution of those gains to the full three-phase OASIF pipeline.
Authors: The Experimental Setup (Section 5) specifies the baselines, 5-seed protocol with standard-deviation error bars and paired significance tests, VMISA-Bench splits, and evaluation procedure. We will revise the abstract to include a brief statement on the evaluation protocol and statistical testing so that the reported gains can be assessed directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract: No ablations are described that isolate the contribution of phase (iii) from phases (i) and (ii). Without such controls, the headline improvements cannot be confidently linked to the self-evolving RL component that the manuscript presents as the key enabler of continual adaptation.
Authors: We agree that an explicit ablation isolating phase (iii) would strengthen attribution of the gains. The current results focus on the complete pipeline; we will add an ablation study in the revised manuscript that compares the full OASIF pipeline against the model after only phases (i) and (ii) on VMISA-Bench. revision: yes
Circularity Check
No significant circularity: empirical benchmark claims without derivations or self-referential fitting.
full rationale
The paper describes an empirical three-phase training pipeline (feature alignment, supervised fine-tuning, online self-evolving RL) and reports measured success-rate gains on VMISA-Bench and BCSD benchmarks. No equations, uniqueness theorems, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. All central claims reduce to externally observable benchmark deltas rather than any derivation that collapses to its own inputs by construction. This is the normal, non-circular case for an applied ML systems paper whose validity rests on reproducible experimental results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Themida overview.https://www.oreans.com/themida.php,
Accessed: 2019-04-12. Themida overview.https://www.oreans.com/themida.php,
2019
-
[2]
Vmprotect software protection.https://www.vmpsoft.com/,
Accessed: 2019-04-12. Vmprotect software protection.https://www.vmpsoft.com/,
2019
-
[3]
Aur (en) - home.https://aur.archlinux.org/,
Accessed: 2019-04-12. Aur (en) - home.https://aur.archlinux.org/,
2019
-
[4]
Arch linux - package search
Accessed: 2025-05-06. Arch linux - package search. https://archlinux.org/packages/,
2025
-
[5]
Microsoft security copilot — microsoft security
Accessed: 2025-05-06. Microsoft security copilot — microsoft security. https://www.microsoft.com/en-us/ security/business/ai-machine-learning/microsoft-security-copilot ,
2025
-
[6]
Ac- cessed: 2025-05-06. Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Bert: Pre-training of deep bidirectional transformers for language understanding
11 Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186,
2019
-
[10]
Asm2vec: Boosting static representa- tion robustness for binary clone search against code obfuscation and compiler optimization
Steven HH Ding, Benjamin CM Fung, and Philippe Charland. Asm2vec: Boosting static representa- tion robustness for binary clone search against code obfuscation and compiler optimization. In 2019 ieee symposium on security and privacy (sp), pages 472–489. IEEE,
2019
-
[11]
How far have we gone in vulnerability detection using large language models,
Zeyu Gao, Hao Wang, Yuchen Zhou, Wenyu Zhu, and Chao Zhang. How far have we gone in vulnerability detection using large language models.arXiv preprint arXiv:2311.12420,
-
[12]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. Deepseek-coder: When the large language model meets programming–the rise of code intelligence.arXiv preprint arXiv:2401.14196,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Nova: Generative language models for binaries.arXiv preprint arXiv:2311.13721,
Nan Jiang, Chengxiao Wang, Kevin Liu, Xiangzhe Xu, Lin Tan, and Xiangyu Zhang. Nova: Generative language models for binaries.arXiv preprint arXiv:2311.13721,
-
[16]
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct.arXiv preprint arXiv:2306.08568,
-
[17]
The convergence of source code and binary vulnerability discovery–a case study
Alessandro Mantovani, Luca Compagna, Yan Shoshitaishvili, and Davide Balzarotti. The convergence of source code and binary vulnerability discovery–a case study. InProceedings of the 2022 ACM on Asia Conference on Computer and Communications Security, pages 602–615,
2022
-
[18]
Disassembling obfuscated executables with llm.arXiv preprint arXiv:2407.08924,
Huanyao Rong, Yue Duan, Hang Zhang, XiaoFeng Wang, Hongbo Chen, Shengchen Duan, and Shen Wang. Disassembling obfuscated executables with llm.arXiv preprint arXiv:2407.08924,
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Llm4decompile: Decompiling binary code with large language models.arXiv preprint arXiv:2403.05286,
Hanzhuo Tan, Qi Luo, Jing Li, and Yuqun Zhang. Llm4decompile: Decompiling binary code with large language models.arXiv preprint arXiv:2403.05286,
-
[21]
Anton Tkachenko, Dmitrij Suskevic, and Benjamin Adolphi. Deconstructing obfuscation: A four- dimensional framework for evaluating large language models assembly code deobfuscation capa- bilities.arXiv preprint arXiv:2505.19887,
-
[22]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi `ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Xinyi Wang, Jiashui Wang, Jinbo Su, Ke Wang, Peng Chen, Yanming Liu, Long Liu, Xiang Li, Yangdong Wang, Qiyuan Chen, et al. Asma-tune: Unlocking llms’ assembly code comprehension via structural-semantic instruction tuning.arXiv preprint arXiv:2503.11617,
-
[24]
Vmhunt: A verifiable approach to partially- virtualized binary code simplification
Dongpeng Xu, Jiang Ming, Yu Fu, and Dinghao Wu. Vmhunt: A verifiable approach to partially- virtualized binary code simplification. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, pages 442–458,
2018
-
[25]
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y Wu, Yukun Li, Huazuo Gao, Shirong Ma, et al. Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence.arXiv preprint arXiv:2406.11931,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Beyond the aggregate sizes reported in Sec
None (no obfuscation) 79,920 SUB (Instruction Substitution)b 2,651 FLA (Control-Flow Flattening)c 58,578 BCF (Bogus Control Flow)d 79,920 ALL (SUB+FLA+BCF)e 79,920 Training Data Dalign (simp) 430,027 Dsft (detail/conv/reason) 11,750 Drl (reason+) 4,244 a Includesub/fla/bcf/all b SUB-mllvm-sub c FLA-mllvm-fla-mllvm-perFLA=100 d BCF-mllvm-bcf-mllvm-boguscf-...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.