EmoDistill: Offline Emotion Skill Distillation for Language Model Agents in Adversarial Negotiation
Pith reviewed 2026-06-29 18:46 UTC · model grok-4.3
The pith
EmoDistill distills strategic emotion use into small language models by separating selection via IQL from expression via LoRA, yielding higher negotiation utility than baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
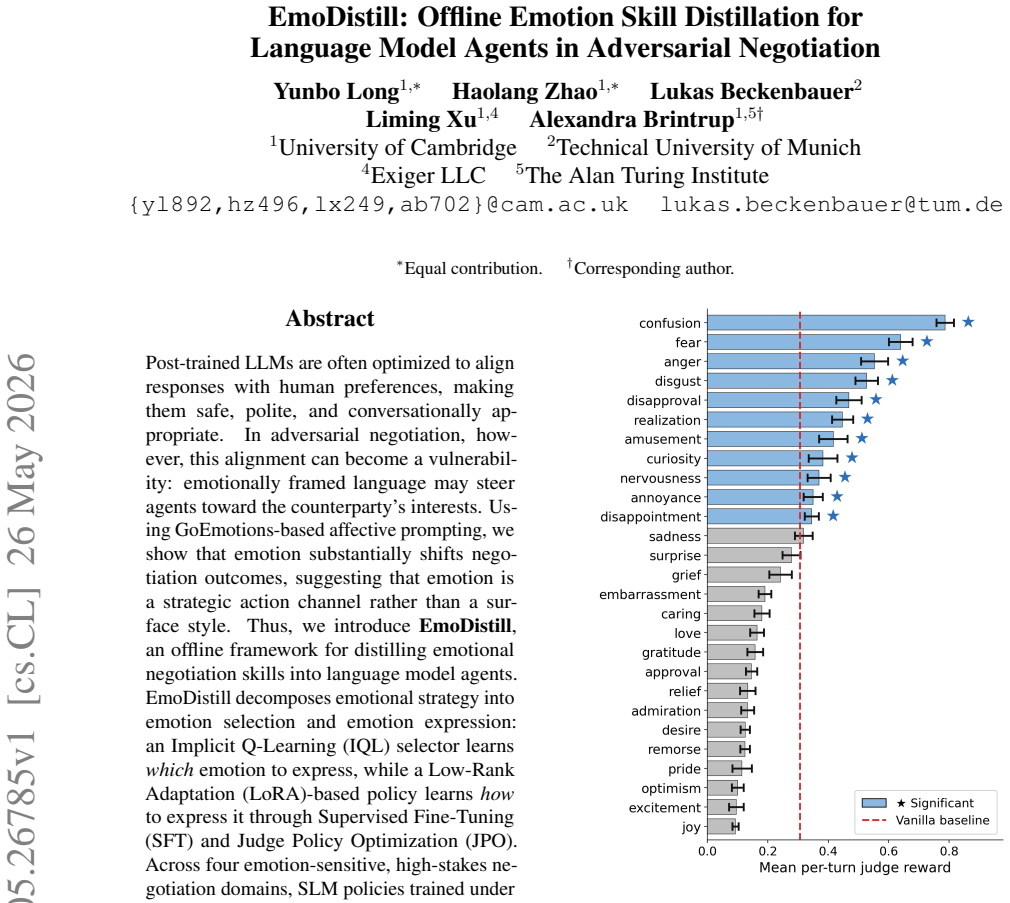
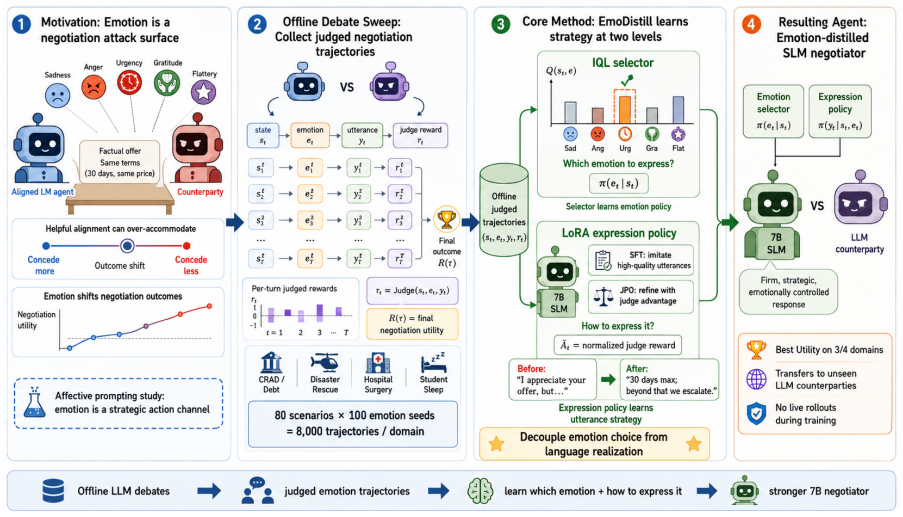
EmoDistill decomposes emotional negotiation strategy into an Implicit Q-Learning selector that learns which emotion to express and a LoRA-based policy that learns how to express it through Supervised Fine-Tuning and Judge Policy Optimization. Small language model policies trained under this framework record the highest utility across four emotion-sensitive high-stakes negotiation domains, outperforming vanilla SLM and LLM baselines as well as IQL-only emotion selection. Ablations establish that emotion conditioning is required for the gains, while transfer experiments show generalization to new domains, unseen counterparties, and trained-versus-trained settings.
What carries the argument
EmoDistill framework, which decomposes emotion strategy into IQL-based selection and LoRA-based expression learned from offline data.
If this is right
- Agents trained with the full EmoDistill pipeline record higher utility than both standard language models and partial IQL-only approaches.
- Emotion conditioning proves essential, as its removal drops performance to baseline levels.
- Distilled skills transfer to unseen domains, new counterparties, and direct agent-versus-agent tournaments.
- All training occurs from static offline data, removing any requirement for live online negotiation episodes.
Where Pith is reading between the lines
- The same separation of selection and expression could be applied to other strategic dialogue elements such as persuasion tactics or information withholding.
- Targeted relaxation of alignment constraints might become feasible for narrow task domains while preserving safety elsewhere.
- The offline nature of the method could lower the barrier to creating specialized agents for repeated high-stakes interactions.
- Generalization across domains hints that the learned emotional skills capture transferable patterns rather than domain-specific artifacts.
Load-bearing premise
Emotion can be isolated and treated as a separable strategic component whose selection and expression can be learned independently from offline interaction data.
What would settle it
A head-to-head evaluation in any of the four negotiation domains in which EmoDistill-trained agents fail to exceed the utility of either vanilla baselines or IQL-only emotion selection would falsify the central performance claim.
Figures
read the original abstract
Post-trained LLMs are often optimized to align responses with human preferences, making them safe, polite, and conversationally appropriate. In adversarial negotiation, however, this alignment can become a vulnerability: emotionally framed language may steer agents toward the counterparty's interests. Using GoEmotions-based affective prompting, we show that emotion substantially shifts negotiation outcomes, suggesting that emotion is a strategic action channel rather than a surface style. Thus, we introduce \textbf{EmoDistill}, an offline framework for distilling emotional negotiation skills into language model agents. EmoDistill decomposes emotional strategy into emotion selection and emotion expression: an Implicit Q-Learning (IQL) selector learns \emph{which} emotion to express, while a Low-Rank Adaptation (LoRA)-based policy learns \emph{how} to express it through Supervised Fine-Tuning (SFT) and Judge Policy Optimization (JPO). Across four emotion-sensitive, high-stakes negotiation domains, SLM policies trained under the EmoDistill framework achieve the highest utility, outperforming vanilla SLM/LLM baselines and IQL-only emotion selection. Ablations show that emotion conditioning is essential, and transfer studies demonstrate generalization across domains, unseen counterparties, and trained-vs-trained tournaments. Overall, EmoDistill learns skills from offline agent-to-agent interactions, avoiding costly online negotiation during training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EmoDistill, an offline distillation framework for emotional negotiation skills in language model agents. Using GoEmotions-based affective prompting, it first demonstrates that emotion shifts negotiation outcomes. The method decomposes emotional strategy into an Implicit Q-Learning (IQL) selector for choosing which emotion to express and a LoRA-adapted policy for how to express it, trained via Supervised Fine-Tuning (SFT) and Judge Policy Optimization (JPO). The central claim is that SLM agents trained under this framework achieve the highest utility across four emotion-sensitive high-stakes negotiation domains, outperforming vanilla SLM/LLM baselines and IQL-only selection, with ablations confirming the necessity of emotion conditioning and transfer experiments showing generalization to new domains, unseen counterparties, and trained-vs-trained settings. The approach relies entirely on offline trajectories to avoid online negotiation during training.
Significance. If the reported performance gains and generalization hold under rigorous verification, the work would establish emotion as a strategic action channel in adversarial settings and demonstrate a practical offline pipeline for distilling such skills. Positive elements include the explicit use of offline agent-to-agent data (avoiding online RL costs) and the inclusion of transfer studies across domains and tournament settings.
major comments (2)
- [Abstract] Abstract: The central empirical claim that 'SLM policies trained under the EmoDistill framework achieve the highest utility' and that 'ablations show that emotion conditioning is essential' is stated without any numerical utility values, baseline scores, effect sizes, statistical significance tests, variance estimates, or data exclusion rules. This prevents direct assessment of the magnitude or reliability of the performance advantage against the manuscript's own evidence.
- [Method (pipeline decomposition)] Method section describing the two-stage pipeline: The decomposition of emotion selection (IQL) from expression (LoRA SFT+JPO) is load-bearing for the framework and the reported gains over IQL-only, yet no analysis, ablation, or comparison to a joint end-to-end policy is provided to test whether the IQL Q-values remain valid once the downstream expression policy is trained separately. If optimal phrasing for a given emotion depends on the selected emotion and counterparty state, the separability assumption risks understating the true performance ceiling.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below, indicating where revisions will strengthen the manuscript and where we maintain our original design choices with additional justification.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that 'SLM policies trained under the EmoDistill framework achieve the highest utility' and that 'ablations show that emotion conditioning is essential' is stated without any numerical utility values, baseline scores, effect sizes, statistical significance tests, variance estimates, or data exclusion rules. This prevents direct assessment of the magnitude or reliability of the performance advantage against the manuscript's own evidence.
Authors: We agree that the abstract would be strengthened by including key numerical results. In the revised manuscript we will insert concise utility values (with baseline comparisons) and note that full tables, variance estimates, and statistical details appear in the experimental section. Space constraints preclude exhaustive reporting in the abstract itself, but the addition of headline numbers will allow readers to gauge effect magnitude directly from the abstract. revision: yes
-
Referee: [Method (pipeline decomposition)] Method section describing the two-stage pipeline: The decomposition of emotion selection (IQL) from expression (LoRA SFT+JPO) is load-bearing for the framework and the reported gains over IQL-only, yet no analysis, ablation, or comparison to a joint end-to-end policy is provided to test whether the IQL Q-values remain valid once the downstream expression policy is trained separately. If optimal phrasing for a given emotion depends on the selected emotion and counterparty state, the separability assumption risks understating the true performance ceiling.
Authors: The two-stage decomposition is motivated by the offline setting: IQL produces stable emotion-selection Q-values from fixed trajectories, after which the LoRA policy is trained to realize those emotions without requiring further online negotiation. Our ablations already show that emotion-conditioned expression improves over IQL-only selection, and transfer results across domains support the practical utility of the separation. A joint end-to-end policy would require re-deriving Q-values under the updated expression distribution, which is outside the offline constraint we target. We will add an explicit discussion of this separability assumption and its limitations in the revised method section. revision: partial
Circularity Check
Empirical pipeline with no self-referential reductions
full rationale
The paper describes an offline training pipeline (IQL selector + LoRA SFT/JPO expression policy) whose central claims are measured utilities on four negotiation domains. No equations, fitted parameters, or uniqueness theorems are invoked that would reduce the reported performance numbers to quantities defined inside the same work. The decomposition into selection and expression is presented as an empirical design choice validated by ablations and transfer experiments rather than derived from prior self-citations or self-definitions. Results are obtained by training on offline trajectories and evaluating against external baselines, rendering the reported outcomes independent of any internal circular construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Implicit Q-Learning and LoRA fine-tuning behave as described in their original references when applied to emotion-labeled negotiation trajectories.
Reference graph
Works this paper leans on
-
[1]
AgreeMate: Teaching LLMs to haggle.arXiv preprint arXiv:2412.18690. DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingx- uan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, and 181 others. 2025. Deepseek-v3 technical report. Prep...
-
[2]
InACL, pages 4040–4054
GoEmotions: A dataset of fine-grained emo- tions. InACL, pages 4040–4054. Xiaoxue Gao, Chen Zhang, Yiming Chen, Huayun Zhang, and Nancy F Chen. 2025. Emo-DPO: Con- trollable emotional speech synthesis through direct preference optimization. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEE...
2025
-
[3]
Trustless autonomy: Understanding moti- vations, benefits and governance dilemma in self- sovereign decentralized ai agents.arXiv preprint arXiv:2505.09757. Yin Jou Huang and Rafik Hadfi. 2024. How personality traits influence negotiation outcomes? a simulation based on large language models. InFindings of the Association for Computational Linguistics: EM...
-
[4]
Emodynamix: Emotional support dialogue strategy prediction by modelling mixed emotions and discourse dynamics. InProceedings of the 2025 Con- ference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 1678–1695. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.