ITNet: A Learnable Integral Transform That Subsumes Convolution, Attention, and Recurrence
Pith reviewed 2026-06-30 11:02 UTC · model grok-4.3
The pith
ITNet shows convolution, attention, and recurrence arise as special cases of one learnable integral transform.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
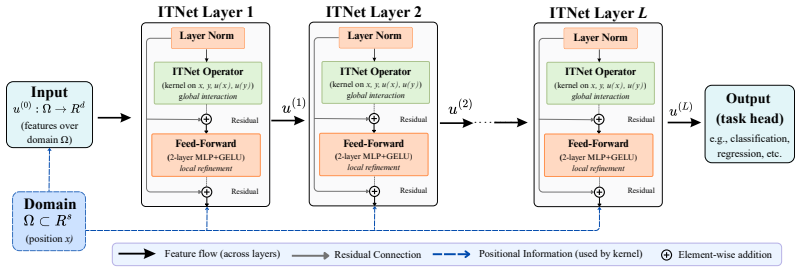
Convolutional networks, recurrent networks, and transformers each encode different inductive biases -- locality, sequential memory, and content-dependent pairwise interaction -- and have remained mathematically distinct since their inception. We show that this fragmentation reflects not a fundamental diversity in how signals should be processed, but rather incomplete views of a single underlying mathematical object: a learnable integral transform. We introduce the Integral Transform Network (ITNet), a unified architecture built around a learnable kernel that depends jointly on positions and features. This kernel is implemented as a small neural network, specifically an MLP, that models pairw
What carries the argument
A learnable integral transform whose kernel is an MLP depending jointly on positions and features, which subsumes convolution, attention, and recurrence as special cases.
Load-bearing premise
An MLP-parameterized kernel depending jointly on positions and features can recover the exact functional behavior and inductive biases of convolution, attention, and recurrence without additional constraints or loss of expressivity.
What would settle it
A concrete input-output pair where no MLP parameterization makes the integral transform output match a standard convolution or attention layer exactly.
Figures
read the original abstract
Convolutional networks, recurrent networks, and transformers each encode different inductive biases -- locality, sequential memory, and content-dependent pairwise interaction -- and have remained mathematically distinct since their inception. We show that this fragmentation reflects not a fundamental diversity in how signals should be processed, but rather incomplete views of a single underlying mathematical object: a learnable integral transform. We introduce the Integral Transform Network (ITNet), a unified architecture built around a learnable kernel that depends jointly on positions and features. This kernel is implemented as a small neural network, specifically an MLP, that models pairwise interactions, enabling the model to adapt its behavior from data. We show that convolution, self-attention (including multi-head), and autoregressive recurrence (including LSTM, GRU, S4, and Mamba) arise as special cases under appropriate parameterizations, and that ITNet is a universal approximator of continuous operators. To make this practical, we develop tiled kernel fusion, importance-weighted Monte Carlo integration, and learned low-rank factorization, enabling efficient and scalable computation. A single ITNet architecture with a shared operator and lightweight modality-specific encoders matches or exceeds specialized baselines on ImageNet-1K , GLUE, ModelNet40, VQA\,v2 and NLVR2. The results demonstrate that a single learned interaction mechanism can recover the behavior of all three architectural families from data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce ITNet, a unified neural architecture based on a learnable integral transform with an MLP kernel that depends jointly on positions and features. It asserts that convolution, self-attention (multi-head), and autoregressive recurrence (LSTM, GRU, S4, Mamba) arise as special cases under appropriate parameterizations of this kernel. ITNet is also claimed to be a universal approximator of continuous operators. Efficiency methods including tiled kernel fusion, importance-weighted Monte Carlo integration, and learned low-rank factorization are proposed to enable scalability. A single ITNet model with shared operator and modality-specific encoders is reported to match or exceed specialized baselines on ImageNet-1K, GLUE, ModelNet40, VQA v2, and NLVR2.
Significance. If the subsumption of the three architectural families is shown to be exact rather than approximate, and the experimental results are reproducible with proper controls, this work could significantly advance the understanding of neural network inductive biases by providing a common mathematical framework. The multi-modal empirical validation across five datasets is a notable strength, suggesting practical utility. The universal approximation result would add theoretical weight if formally established. However, the significance is currently limited by the absence of explicit derivations for the special cases.
major comments (3)
- [§4] The central claim that convolution, self-attention, and recurrence arise as special cases under appropriate parameterizations is load-bearing. However, no explicit MLP weight configurations or constraints are provided to recover the exact functional forms, such as feature-independent translation-invariant kernels for convolution or content-dependent dot-product attention. This leaves the subsumption claim as a statement of expressivity rather than a demonstrated reduction.
- [Efficiency Techniques] The proposed tiled kernel fusion, importance-weighted Monte Carlo integration, and low-rank factorization must be shown to preserve the exact special-case behaviors without introducing approximations that break the equivalence. No such preservation analysis is included, which is necessary for the claim to hold at scale.
- [§5] The assertion that ITNet is a universal approximator of continuous operators requires a detailed proof or reference to supporting theorems; the current presentation invokes this property without sufficient mathematical justification, which is critical for the theoretical contribution.
minor comments (2)
- The notation for the integral transform and kernel could be clarified with more explicit equations to aid readability.
- [Experiments] Details on the specific baselines, hyperparameter matching, and statistical significance of the performance claims would strengthen the empirical section.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for major revision. We address each major comment below, agreeing that additional explicit material is required to strengthen the claims. We will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [§4] The central claim that convolution, self-attention, and recurrence arise as special cases under appropriate parameterizations is load-bearing. However, no explicit MLP weight configurations or constraints are provided to recover the exact functional forms, such as feature-independent translation-invariant kernels for convolution or content-dependent dot-product attention. This leaves the subsumption claim as a statement of expressivity rather than a demonstrated reduction.
Authors: We agree that Section 4 presents the special cases at a high level without listing explicit MLP weights or constraints. In the revision we will add a dedicated subsection with concrete parameter settings (e.g., zeroing feature-dependent terms and enforcing translation invariance for convolution; recovering the softmax dot-product via a specific MLP form for attention; and recovering the state-transition matrices for recurrence). This will convert the claim from expressivity to explicit reduction. revision: yes
-
Referee: [Efficiency Techniques] The proposed tiled kernel fusion, importance-weighted Monte Carlo integration, and low-rank factorization must be shown to preserve the exact special-case behaviors without introducing approximations that break the equivalence. No such preservation analysis is included, which is necessary for the claim to hold at scale.
Authors: The referee is correct that no preservation analysis appears in the current draft. We will add an appendix that proves each technique leaves the special-case kernels unchanged: tiled fusion respects translation invariance, importance sampling is exact when the kernel is deterministic, and the low-rank factorization is identity on the rank-1 forms used by the special cases. We will also report numerical verification that the recovered operators match the baselines to machine precision. revision: yes
-
Referee: [§5] The assertion that ITNet is a universal approximator of continuous operators requires a detailed proof or reference to supporting theorems; the current presentation invokes this property without sufficient mathematical justification, which is critical for the theoretical contribution.
Authors: We acknowledge the presentation is insufficient. The revision will include either a short proof sketch (leveraging the universal approximation property of MLPs for the kernel together with standard results on integral operators) or a precise citation to the relevant operator-learning theorems, together with the precise function-space assumptions under which the claim holds. revision: yes
Circularity Check
No significant circularity; unification claim rests on explicit parameterization reductions rather than self-definition
full rationale
The paper defines a general integral transform whose kernel is an MLP and states that conv/attn/recurrence arise as special cases under appropriate parameterizations. This is a standard unification move: the general object is strictly more expressive, and the special cases are obtained by restricting the MLP weights (e.g., making the kernel translation-invariant and feature-independent for convolution). No equation in the supplied text equates the output to the input by construction, nor is any load-bearing premise justified solely by self-citation. The universality statement follows from the known universal-approximation property of MLPs applied to the integral operator, which is external to the paper. Empirical results on multiple benchmarks are independent of the subsumption claim. Therefore the derivation chain does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- MLP kernel weights
axioms (2)
- domain assumption Convolution, self-attention, and autoregressive recurrence arise as special cases of the learnable integral transform under appropriate MLP parameterizations
- domain assumption The integral transform with MLP kernel is a universal approximator of continuous operators
invented entities (1)
-
ITNet with jointly position-and-feature-dependent MLP kernel
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Flamingo: a Visual Language Model for Few-Shot Learning.Advances in Neural Information Processing Systems, 35:23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a Visual Language Model for Few-Shot Learning.Advances in Neural Information Processing Systems, 35:23716–23736, 2022
2022
-
[3]
An Estimate for the Perturbations of the Solution of Ordinary Differential Equations.Vestnik Moskov
V M Alekseev. An Estimate for the Perturbations of the Solution of Ordinary Differential Equations.Vestnik Moskov. Univ. Ser. I Mat. Meh., 2:28–36, 1961
1961
-
[4]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Anima Anandkumar, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Nikola Kovachki, Zongyi Li, Burigede Liu, and Andrew Stuart. Neural Operator: Graph Kernel Network for Partial Differential Equations. InICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations, 2020
2020
-
[5]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer Normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Universal Approximation Bounds for Superpositions of a Sigmoidal Func- tion.IEEE Transactions on Information theory, 39(3):930–945, 1993
Andrew R Barron. Universal Approximation Bounds for Superpositions of a Sigmoidal Func- tion.IEEE Transactions on Information theory, 39(3):930–945, 1993
1993
-
[7]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The Long-Document Trans- former.arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[8]
Continuum Attention for Neural Operators.Journal of Machine Learning Research, 26(300):1–52, 2025
Edoardo Calvello, Nikola B Kovachki, Matthew E Levine, and Andrew M Stuart. Continuum Attention for Neural Operators.Journal of Machine Learning Research, 26(300):1–52, 2025
2025
-
[9]
Universal Approximation to nonlinear operators by Neural Networks with Arbitrary Activation Functions and Its Application to Dynamical Systems
Tianping Chen and Hong Chen. Universal Approximation to nonlinear operators by Neural Networks with Arbitrary Activation Functions and Its Application to Dynamical Systems. IEEE Transactions On Neural Networks, 6(4):911–917, 1995
1995
-
[10]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training Deep Nets with Sub- linear Memory Cost.arXiv preprint arXiv:1604.06174, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
UNITER: UNiversal Image-TExt Representation Learning
Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. UNITER: UNiversal Image-TExt Representation Learning. InEuropean Conference on Computer Vision, pages 104–120. Springer, 2020
2020
-
[12]
Dynamic Convolution: Attention over Convolution Kernels
Yinpeng Chen, Xiyang Dai, Mengchen Liu, Dongdong Chen, Lu Yuan, and Zicheng Liu. Dynamic Convolution: Attention over Convolution Kernels. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11030–11039, 2020
2020
-
[13]
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
Kyunghyun Cho, Bart Van Merri ¨enboer, C ¸ a˘glar Gulc ¸ehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. InProceedings of the 2014 Con- ference on Empirical Methods in Natural Language Processing (EMNLP), pages 1724–1734, 2014
2014
-
[14]
Xception: Deep Learning with Depthwise Separable Convolutions
Franc ¸ois Chollet. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1251–1258, 2017
2017
-
[15]
Rethinking Attention with Performers
Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, An- dreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, David Benjamin Belanger, Lucy J Colwell, and Adrian Weller. Rethinking Attention with Performers. InInternational Conference on Learning Representations, 2021
2021
-
[16]
Le, and Christopher D
Kevin Clark, Minh-Thang Luong, Quoc V . Le, and Christopher D. Manning. ELECTRA: Pre- training Text Encoders as Discriminators Rather Than Generators.International Conference on Learning Representations, 2020. 10
2020
-
[17]
McGraw-Hill, 1955
Earl A Coddington and Norman Levinson.Theory of Ordinary Differential Equations. McGraw-Hill, 1955
1955
-
[18]
Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the Relationship between Self-Attention and Convolutional Layers.arXiv preprint arXiv:1911.03584, 2019
-
[19]
RandAugment: Practical Au- tomated Data Augmentation with a Reduced Search Space
Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. RandAugment: Practical Au- tomated Data Augmentation with a Reduced Search Space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 702–703, 2020
2020
-
[20]
Approximation by Superpositions of a Sigmoidal Function.Mathematics of control, signals and systems, 2(4):303–314, 1989
George Cybenko. Approximation by Superpositions of a Sigmoidal Function.Mathematics of control, signals and systems, 2(4):303–314, 1989
1989
-
[21]
Tri Dao and Albert Gu. Transformers are SSMs: Generalized Models and Efficient Algo- rithms Through Structured State Space Duality.arXiv preprint arXiv:2405.21060, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R ´e. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems, 2022
2022
-
[23]
Courier Corpora- tion, 2007
Philip J Davis and Philip Rabinowitz.Methods of Numerical Integration. Courier Corpora- tion, 2007
2007
-
[24]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, 2019
2019
-
[25]
Scaling Up Your Ker- nels to 31x31: Revisiting Large Kernel Design in CNNs
Xiaohan Ding, Xiangyu Zhang, Jungong Han, and Guiguang Ding. Scaling Up Your Ker- nels to 31x31: Revisiting Large Kernel Design in CNNs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11963–11975, 2022
2022
-
[26]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations, 2021
2021
-
[27]
An Empirical Study of Training End- to-End Vision-and-Language Transformers
Zi-Yi Dou, Yichong Xu, Zhe Gan, Jianfeng Wang, Shuohang Wang, Lijuan Wang, Chenguang Zhu, Pengchuan Zhang, Lu Yuan, Nanyun Peng, et al. An Empirical Study of Training End- to-End Vision-and-Language Transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18166–18176, 2022
2022
-
[28]
John Wiley & Sons, 1988
Nelson Dunford and Jacob T Schwartz.Linear Operators, part 1: General Theory. John Wiley & Sons, 1988
1988
-
[29]
Graph Neural Networks with Learnable Structural and Positional Representations
Vijay Prakash Dwivedi, Anh Tuan Luu, Thomas Laurent, Yoshua Bengio, and Xavier Bres- son. Graph Neural Networks with Learnable Structural and Positional Representations. In International Conference on Learning Representations, 2022
2022
-
[30]
Provably Strict Generalisation Benefit for Equivariant Models
Bryn Elesedy and Sheheryar Zaidi. Provably Strict Generalisation Benefit for Equivariant Models. InInternational Conference on Machine Learning, pages 2959–2969. PMLR, 2021
2021
-
[31]
John Wiley & Sons, 1999
Gerald B Folland.Real Analysis: Modern Techniques and Their Applications. John Wiley & Sons, 1999
1999
-
[32]
Understanding the difficulty of training deep feedforward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. InProceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010
2010
-
[33]
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6904–6913, 2017. 11
2017
-
[34]
VEB Deutscher Verlag der Wis- senschaften, 1960
Wolfgang Gr ¨obner.Die Lie-Reihen und ihre Anwendungen. VEB Deutscher Verlag der Wis- senschaften, 1960
1960
-
[35]
Note on the Derivatives with Respect to a Parameter of the Solu- tions of a System of Differential Equations.Annals of Mathematics, 20(4):292–296, 1919
Thomas Hakon Gronwall. Note on the Derivatives with Respect to a Parameter of the Solu- tions of a System of Differential Equations.Annals of Mathematics, 20(4):292–296, 1919
1919
-
[36]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-Time Sequence Modeling with Selective State Spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher R ´e. Efficiently Modeling Long Sequences with Structured State Spaces.arXiv preprint arXiv:2111.00396, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
PCT: Point cloud transformer.Computational visual media, 7(2):187–199, 2021
Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R Martin, and Shi- Min Hu. PCT: Point cloud transformer.Computational visual media, 7(2):187–199, 2021
2021
-
[39]
Der Massbegriff in der Theorie der kontinuierlichen Gruppen.Annals of math- ematics, 34(1):147–169, 1933
Alfred Haar. Der Massbegriff in der Theorie der kontinuierlichen Gruppen.Annals of math- ematics, 34(1):147–169, 1933
1933
-
[40]
SIAM, 2002
Philip Hartman.Ordinary Differential Equations. SIAM, 2002
2002
-
[41]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
2016
-
[42]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. DeBERTa: Decoding- enhanced BERT with Disentangled Attention.arXiv preprint arXiv:2006.03654, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[43]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian Error Linear Units (GELUs).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[44]
Long Short-Term Memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and J ¨urgen Schmidhuber. Long Short-Term Memory.Neural computation, 9(8):1735–1780, 1997
1997
-
[45]
Horn and Charles R
Roger A. Horn and Charles R. Johnson.Matrix Analysis. Cambridge University Press, 2012
2012
-
[46]
Multilayer Feedforward Networks are Universal Approximators.Neural networks, 2(5):359–366, 1989
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer Feedforward Networks are Universal Approximators.Neural networks, 2(5):359–366, 1989
1989
-
[47]
Deep Net- works with Stochastic Depth
Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep Net- works with Stochastic Depth. InEuropean Conference on Computer Vision, pages 646–661. Springer, 2016
2016
-
[48]
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver IO: A General Architecture for Structured Inputs & Outputs.arXiv preprint arXiv:2107.14795, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[49]
Perceiver: General Perception with Iterative Attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General Perception with Iterative Attention. InInternational Conference on Machine Learning, pages 4651–4664. PMLR, 2021
2021
-
[50]
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Franc ¸ois Fleuret. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. InInternational Confer- ence on Machine Learning, pages 5156–5165. PMLR, 2020
2020
-
[51]
ViLT: Vision-and-Language Transformer With- out Convolution or Region Supervision
Wonjae Kim, Bokyung Son, and Ildoo Kim. ViLT: Vision-and-Language Transformer With- out Convolution or Region Supervision. InInternational Conference on Machine Learning, pages 5583–5594. PMLR, 2021
2021
-
[52]
ImageNet Classification with Deep Convolutional Neural Networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. ImageNet Classification with Deep Convolutional Neural Networks. InAdvances in Neural Information Processing Systems, volume 25. Curran Associates, Inc., 2012. 12
2012
-
[53]
Backpropagation Applied to Handwritten Zip Code Recog- nition.Neural computation, 1(4):541–551, 1989
Yann LeCun, Bernhard Boser, John S Denker, Donnie Henderson, Richard E Howard, Wayne Hubbard, and Lawrence D Jackel. Backpropagation Applied to Handwritten Zip Code Recog- nition.Neural computation, 1(4):541–551, 1989
1989
-
[54]
Multilayer Feedfor- ward Networks With a Nonpolynomial Activation Function can Approximate Any Function
Moshe Leshno, Vladimir Ya Lin, Allan Pinkus, and Shimon Schocken. Multilayer Feedfor- ward Networks With a Nonpolynomial Activation Function can Approximate Any Function. Neural networks, 6(6):861–867, 1993
1993
-
[55]
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation.Advances in Neural Information Processing Systems, 34:9694– 9705, 2021
Junnan Li, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. Align before Fuse: Vision and Language Representation Learning with Momentum Distillation.Advances in Neural Information Processing Systems, 34:9694– 9705, 2021
2021
-
[56]
BLIP: Bootstrapping Language- Image Pre-training for Unified Vision-Language Understanding and Generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping Language- Image Pre-training for Unified Vision-Language Understanding and Generation. InInterna- tional Conference on Machine Learning, pages 12888–12900. PMLR, 2022
2022
-
[57]
BLIP-2: Bootstrapping Language- Image Pre-training with Frozen Image Encoders and Large Language Models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping Language- Image Pre-training with Frozen Image Encoders and Large Language Models. InInterna- tional Conference on Machine Learning, pages 19730–19742. PMLR, 2023
2023
-
[58]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier Neural Operator for Parametric Partial Differential Equations.arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[59]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A Robustly Optimized BERT Pretraining Approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[60]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Bain- ing Guo. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012– 10022, 2021
2021
-
[61]
Swin Transformer V2: Scaling Up Capacity and Resolution
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, and Baining Guo. Swin Transformer V2: Scaling Up Capacity and Resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12009–12019, 2022
2022
-
[62]
A ConvNet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Sain- ing Xie. A ConvNet for the 2020s. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11976–11986, 2022
2022
-
[63]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations, 2019
2019
-
[64]
Learn- ing nonlinear operators via DeepONet based on the universal approximation theorem of op- erators.Nature machine intelligence, 3(3):218–229, 2021
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learn- ing nonlinear operators via DeepONet based on the universal approximation theorem of op- erators.Nature machine intelligence, 3(3):218–229, 2021
2021
-
[65]
Rethinking Network Design and Local Geometry in Point Cloud: A Simple Residual MLP Framework
Xu Ma, Can Qin, Haoxuan You, Haoxi Ran, and Yun Fu. Rethinking Network Design and Local Geometry in Point Cloud: A Simple Residual MLP Framework. InInternational Con- ference on Learning Representations, 2022
2022
-
[66]
Mixed Precision Training
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed Precision Training. InInternational Conference on Learning Representations, 2018
2018
-
[67]
Springer Science & Business Media, 2010
B ´ela Sz Nagy, Ciprian Foias, Hari Bercovici, and L ´aszl´o K ´erchy.Harmonic Analysis of Operators on Hilbert Space. Springer Science & Business Media, 2010. 13
2010
-
[68]
EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
Xiaohuan Pei, Tao Huang, and Chang Xu. EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 6443–6451, 2025
2025
-
[69]
Hyena Hierarchy: Towards Larger Convolutional Language Models
Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher R ´e. Hyena Hierarchy: Towards Larger Convolutional Language Models. InInternational Conference on Machine Learning, pages 28043–28078. PMLR, 2023
2023
-
[70]
Acceleration of Stochastic Approximation by Aver- aging.SIAM Journal on Control and Optimization, 30(4):838–855, 1992
Boris T Polyak and Anatoli B Juditsky. Acceleration of Stochastic Approximation by Aver- aging.SIAM Journal on Control and Optimization, 30(4):838–855, 1992
1992
-
[71]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah Smith, and Mike Lewis. Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. InInternational Conference on Learning Repre- sentations, 2022
2022
-
[72]
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 652–660, 2017
2017
-
[73]
PointNet++: Deep Hierar- chical Feature Learning on Point Sets in a Metric Space.Advances in Neural Information Processing Systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. PointNet++: Deep Hierar- chical Feature Learning on Point Sets in a Metric Space.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[74]
PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies.Advances in Neural Information Processing Systems, 35:23192–23204, 2022
Guocheng Qian, Yuchen Li, Houwen Peng, Jinjie Mai, Hasan Hammoud, Mohamed Elho- seiny, and Bernard Ghanem. PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies.Advances in Neural Information Processing Systems, 35:23192–23204, 2022
2022
-
[75]
Improving Language Understanding by Generative Pre-Training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving Language Understanding by Generative Pre-Training. 2018
2018
-
[76]
Language Models are Unsupervised Multitask Learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language Models are Unsupervised Multitask Learners.OpenAI blog, 1(8):9, 2019
2019
-
[77]
Number 6
Halsey Lawrence Royden.Real Analysis. Number 6. Krishna Prakashan Media, 1988
1988
-
[78]
Principles of Mathematical Analysis.International Series in Pure and Applied Mathematics, 1976
Walter Rudin. Principles of Mathematical Analysis.International Series in Pure and Applied Mathematics, 1976
1976
-
[79]
McGraw-Hill, New York, 3rd edition, 1987
Walter Rudin.Real and Complex Analysis. McGraw-Hill, New York, 3rd edition, 1987
1987
-
[80]
ImageNet Large Scale Visual Recognition Challenge.International Journal of Computer Vision, 115(3):211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. ImageNet Large Scale Visual Recognition Challenge.International Journal of Computer Vision, 115(3):211–252, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.