ReSET: Accurate Latency-Critical NVFP4 Reasoning via Step-Aware Temperature Scaling
Pith reviewed 2026-06-27 07:38 UTC · model grok-4.3
The pith
ReSET recovers up to 2 points of reasoning accuracy lost under NVFP4 quantization by scaling temperature with step-level entropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
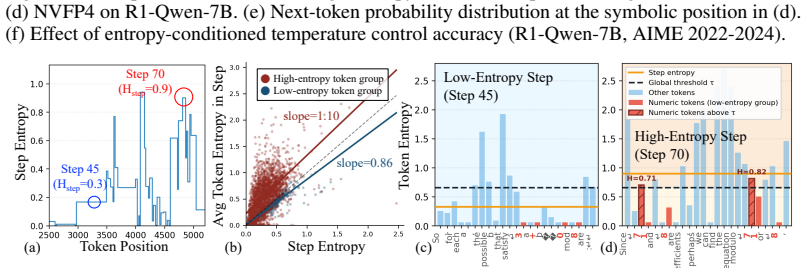
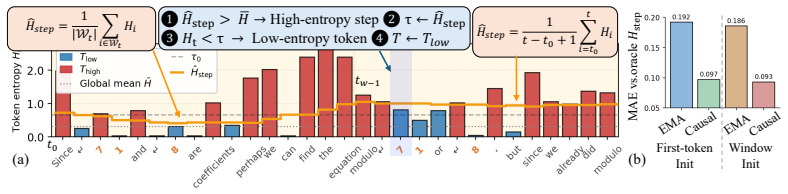
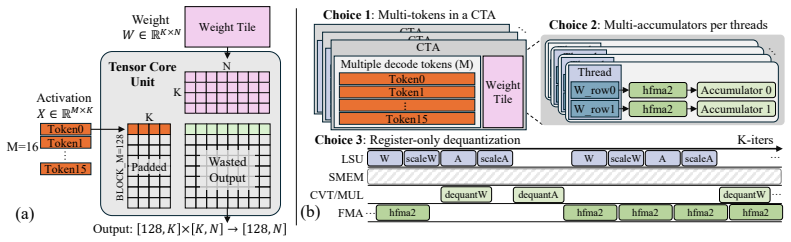
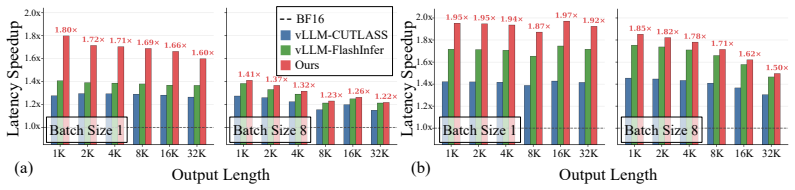
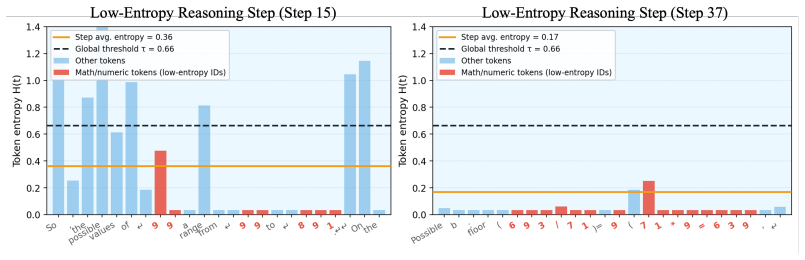
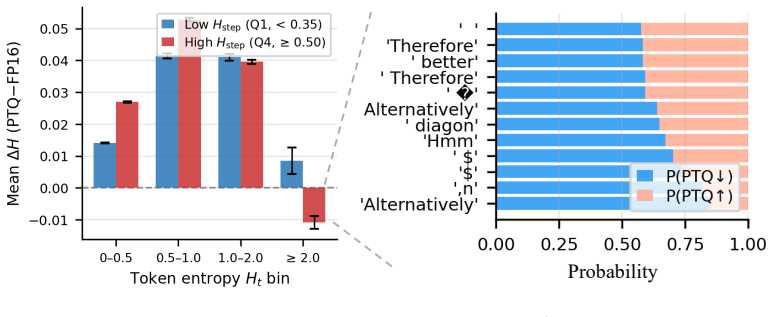
ReSET estimates step-level uncertainty online from entropy and adapts decoding temperature with both token-level and step-level signals; this counters the specific sampling distortions introduced by NVFP4 quantization. Across benchmarks and model scales the approach raises reasoning accuracy by up to approximately 2 points relative to the plain NVFP4 baseline. A new CUDA-core small-M kernel supplies up to 2.5 times kernel-level speedup over NVFP4 vLLM and roughly 2 times end-to-end decoding speedup over BF16.
What carries the argument
ReSET, the reasoning-step entropy-based temperature-scaling method that adapts decoding temperature using both token-level and step-level entropy signals.
If this is right
- NVFP4 can be applied to long reasoning traces while keeping accuracy loss small.
- Step-level entropy provides a usable online signal for controlling sampling behavior during autoregressive decoding.
- The small-M CUDA kernel closes the latency gap that previously limited NVFP4 use in latency-critical settings.
- Accuracy and speed gains hold across multiple model scales and reasoning benchmarks.
Where Pith is reading between the lines
- The same entropy-driven adjustment might reduce accuracy loss under other low-bit formats if their uncertainty distortions follow similar patterns.
- ReSET could be combined with existing speculative decoding or early-exit techniques to further cut compute on long traces.
- If step entropy proves stable across domains, the method might transfer to non-reasoning tasks that still require long coherent outputs.
Load-bearing premise
Online estimates of step-level uncertainty derived from entropy signals will reliably guide temperature adjustments to reduce incorrect sampling without creating offsetting errors elsewhere in the reasoning trace.
What would settle it
Run the same reasoning benchmarks with and without ReSET under identical NVFP4 settings; if accuracy does not rise by a measurable margin or falls, the central claim is false.
Figures
read the original abstract
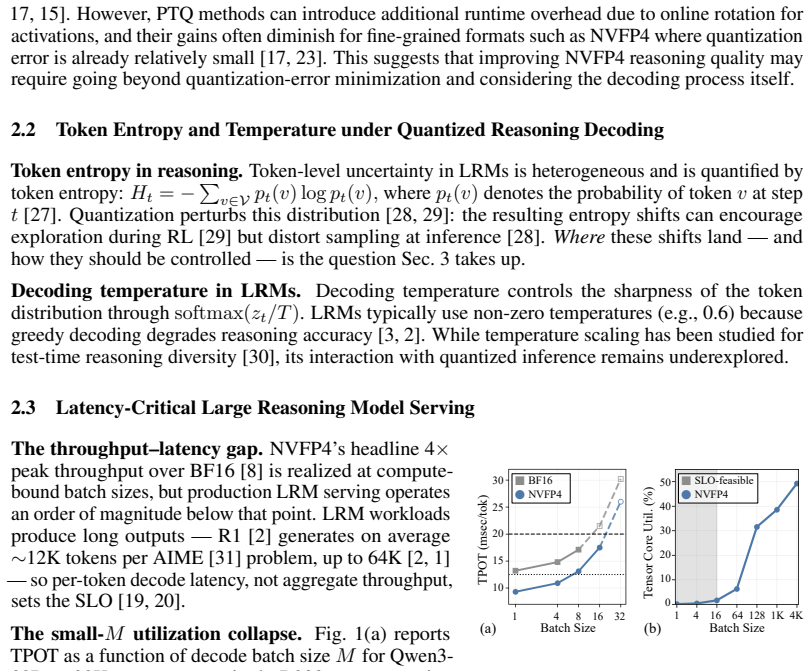
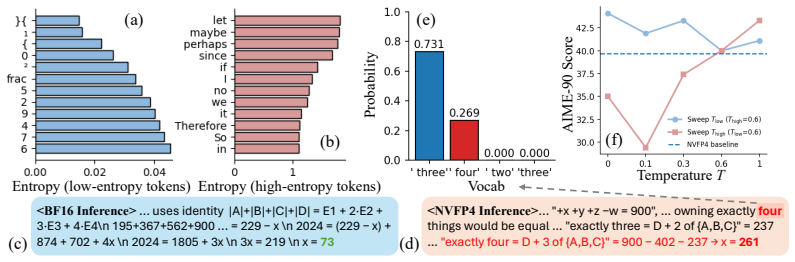
Large reasoning models (LRMs) improve complex problem-solving by generating long intermediate reasoning traces, but this substantially increases inference costs. NVFP4 inference offers a promising approach to reduce both computational and memory costs through hardware-supported low-precision execution. However, directly applying NVFP4 to LRMs introduces two practical limitations: reasoning accuracy degrades under quantization, and existing NVFP4 kernels do not fully realize latency benefits in small-batch autoregressive decoding. In this work, we analyze the effect of NVFP4 quantization on token-level uncertainty during reasoning. We show that quantization increases incorrect sampling at low-entropy symbolic tokens, while causing over-concentration on a small set of tokens in high-uncertainty reasoning steps. Based on this observation, we propose \textbf{ReSET}, a reasoning-step entropy-based temperature-scaling method that estimates step-level uncertainty online and adapts the decoding temperature using both token-level and step-level entropy signals. To address the latency gap, we further design a CUDA-core small-$M$ NVFP4 kernel for latency-critical autoregressive decoding. Across reasoning benchmarks and model scales, ReSET improves NVFP4 reasoning accuracy by up to $\sim\!$2 points over the NVFP4 baseline. Our CUDA-core small-$M$ kernel further improves latency-critical decoding, delivering up to $2.5\!\times$ kernel-level speedup over NVFP4 vLLM and approximately $2\!\times$ end-to-end decoding speedup over BF16. Code is available at https://github.com/aiha-lab/ReSET.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes how NVFP4 quantization affects token-level uncertainty in long reasoning traces of large reasoning models, identifying increased incorrect sampling at low-entropy tokens and over-concentration at high-uncertainty steps. It introduces ReSET, which estimates step-level uncertainty online from entropy signals and adapts decoding temperature using both token- and step-level signals, plus a custom CUDA-core small-M NVFP4 kernel. The central claims are accuracy gains of up to ~2 points over an NVFP4 baseline across reasoning benchmarks and model scales, together with up to 2.5× kernel speedup versus NVFP4 vLLM and ~2× end-to-end decoding speedup versus BF16.
Significance. If the empirical results hold under rigorous verification, the work would be significant for practical deployment of latency-critical reasoning models: it offers a lightweight, online correction for quantization-induced sampling errors without retraining and pairs it with a hardware-aware kernel that closes the latency gap for small-batch autoregressive decoding. The combination of an entropy-driven adaptive decoding rule with a specialized low-precision kernel addresses two orthogonal bottlenecks in LRM inference.
major comments (2)
- [ReSET method description] The headline accuracy claim (up to ~2 points over the NVFP4 baseline) rests on the premise that step-level entropy signals can be mapped to temperature adjustments that reduce incorrect sampling without introducing offsetting errors elsewhere in long traces. The manuscript presents this mapping as following directly from the observed quantization effects, yet provides no explicit functional form, ablation isolating the step-level component, or analysis showing the adjustment remains beneficial across trace lengths; this is load-bearing for the reported gains.
- [Experimental results] The experimental section reports accuracy and latency numbers but does not include statistical significance tests, variance across random seeds, or explicit confirmation that baseline comparisons used identical prompting, sampling parameters, and model checkpoints; without these, the ~2-point accuracy delta and the 2× end-to-end speedup cannot be assessed for robustness.
minor comments (2)
- [Method] Notation for the entropy signals (token-level vs. step-level) should be defined with explicit formulas early in the method section to avoid ambiguity when the temperature-scaling rule is later stated.
- [Abstract / Results] The abstract states speedups relative to both NVFP4 vLLM and BF16; the corresponding tables or figures should make the exact batch sizes, sequence lengths, and hardware platform explicit so readers can reproduce the latency comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and commit to revisions that strengthen the presentation of the ReSET method and the experimental results.
read point-by-point responses
-
Referee: [ReSET method description] The headline accuracy claim (up to ~2 points over the NVFP4 baseline) rests on the premise that step-level entropy signals can be mapped to temperature adjustments that reduce incorrect sampling without introducing offsetting errors elsewhere in long traces. The manuscript presents this mapping as following directly from the observed quantization effects, yet provides no explicit functional form, ablation isolating the step-level component, or analysis showing the adjustment remains beneficial across trace lengths; this is load-bearing for the reported gains.
Authors: We agree that an explicit functional form and targeted ablations would improve clarity and verifiability. In the revised manuscript we will state the precise temperature adjustment rule (including how step-level entropy is combined with token-level signals), add an ablation that isolates the step-level component, and report accuracy trends broken down by reasoning trace length to confirm the adjustment remains beneficial. revision: yes
-
Referee: [Experimental results] The experimental section reports accuracy and latency numbers but does not include statistical significance tests, variance across random seeds, or explicit confirmation that baseline comparisons used identical prompting, sampling parameters, and model checkpoints; without these, the ~2-point accuracy delta and the 2× end-to-end speedup cannot be assessed for robustness.
Authors: We concur that these elements are necessary for assessing robustness. The revised manuscript will add statistical significance tests on the accuracy deltas, report standard deviations across at least three random seeds, and include an explicit statement confirming that all compared methods used identical prompts, sampling hyperparameters, and model checkpoints. revision: yes
Circularity Check
No circularity: empirical analysis and method proposal with independent experimental validation
full rationale
The paper conducts an empirical analysis of NVFP4 quantization effects on uncertainty (increased incorrect sampling at low-entropy tokens and over-concentration at high-uncertainty steps), then proposes ReSET as a temperature-scaling heuristic based on those observations. Reported accuracy gains (~2 points) and speedups are presented as direct experimental outcomes across benchmarks, with no equations, fitted parameters, or self-citation chains that reduce the claimed results to inputs by construction. The derivation chain is self-contained as an observation-driven engineering response rather than a closed mathematical loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondri...
Pith/arXiv arXiv 2024
-
[2]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[3]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[4]
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, Liangyu Chen, Zaid Khan, Eric Frankel, Sachin Grover, Caroline Choi, Niklas Muennighoff, Shiye Su, Wanjia Zhao, John Yang, Shreyas Pimpalgaonkar, Kartik Sharma, Charlie Cheng-Jie Ji, ...
Pith/arXiv arXiv 2025
-
[5]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. In P. Gibbons, G. Pekhimenko, and C. De Sa, editors,Proceedings of Machine Learning and Systems, volume 6, pages 87–100, 2024. URL htt...
2024
-
[6]
Atom: Low-bit quantization for efficient and accurate llm serving
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. Atom: Low-bit quantization for efficient and accurate llm serving. In P. Gibbons, G. Pekhimenko, and C. De Sa, editors,Proceedings of Machine Learning and Systems, volume 6, pages 196–209, 2024. URL https://proceeding s.ml...
2024
-
[7]
nvidia/deepseek-r1-nvfp4
Nvidia. nvidia/deepseek-r1-nvfp4. 2025. URL https://huggingface.co/nvidia/DeepSe ek-R1-NVFP4
2025
-
[8]
Nvidia blackwell architecture technical brief
Nvidia. Nvidia blackwell architecture technical brief. 2024. URL https://resources.nvid ia.com/en-us-blackwell-architecture
2024
-
[9]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xiong- Hui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, 11 Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. InThe Thirty- ninth Annual ...
2025
-
[10]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=v8L0pN6EOi
2024
-
[11]
Quantization hurts reasoning? an empirical study on quantized reasoning models
Ruikang Liu, Yuxuan Sun, Manyi Zhang, Haoli Bai, Xianzhi Yu, Tiezheng YU, Chun Yuan, and Lu Hou. Quantization hurts reasoning? an empirical study on quantized reasoning models. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/for um?id=BM192Ps5Nv
2025
-
[12]
What makes low-bit quantization-aware training work for reasoning llms? a systematic study, 2026
Keyu Lv, Manyi Zhang, Xiaobo Xia, Jingchen Ni, Shannan Yan, Xianzhi Yu, Lu Hou, Chun Yuan, and Haoli Bai. What makes low-bit quantization-aware training work for reasoning llms? a systematic study, 2026. URLhttps://arxiv.org/abs/2601.14888
arXiv 2026
-
[13]
Quantization-aware distillation for nvfp4 inference accuracy recovery
NVIDIA. Quantization-aware distillation for nvfp4 inference accuracy recovery. 2026
2026
-
[14]
Duquant++: Fine-grained rotation enhances microscaling fp4 quantization, 2026
Haokun Lin, Xinle Jia, Haobo Xu, Bingchen Yao, Xianglong Guo, Yichen Wu, Zhichao Lu, Ying Wei, Qingfu Zhang, and Zhenan Sun. Duquant++: Fine-grained rotation enhances microscaling fp4 quantization, 2026. URLhttps://arxiv.org/abs/2604.17789
Pith/arXiv arXiv 2026
-
[15]
Four over six: More accurate nvfp4 quantization with adaptive block scaling, 2025
Jack Cook, Junxian Guo, Guangxuan Xiao, Yujun Lin, and Song Han. Four over six: More accurate nvfp4 quantization with adaptive block scaling, 2025. URL https://arxiv.org/ab s/2512.02010
Pith/arXiv arXiv 2025
-
[16]
Block rotation is all you need for mxfp4 quantization, 2025
Yuantian Shao, Peisong Wang, Yuanteng Chen, Chang Xu, Zhihui Wei, and Jian Cheng. Block rotation is all you need for mxfp4 quantization, 2025. URL https://arxiv.org/abs/2511 .04214
2025
-
[17]
Castro, Denis Kuznedelev, Andrei Panferov, Eldar Kurtic, Shubhra Pandit, Alexandre Noll Marques, Mark Kurtz, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh
Vage Egiazarian, Roberto L. Castro, Denis Kuznedelev, Andrei Panferov, Eldar Kurtic, Shubhra Pandit, Alexandre Noll Marques, Mark Kurtz, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Bridging the gap between promise and performance for microscaling FP4 quantization. InThe F ourteenth International Conference on Learning Representations, 2026. URLhttp...
2026
-
[18]
Janghwan Lee, Jiwoong Park, Jinseok Kim, Yongjik Kim, Jungju Oh, Jinwook Oh, and Jung- wook Choi. AMXFP4: Taming activation outliers with asymmetric microscaling floating-point for 4-bit LLM inference. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mo- hammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 20...
-
[19]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming throughput-latency tradeoff in llm inference with sarathi-serve. InProceedings of the 18th USENIX Conference on Operating Systems Design and Implementation, OSDI’24, USA, 2024. USENIX Association. ISBN 978-1-939133-40-3
2024
-
[20]
DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, Santa Clara, CA, July 2024. USENIX Association. ISBN 978-1- 9391...
2024
-
[21]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating 12 Systems Principles, SOSP ’23, page 611–626, New York, NY , USA, 2023. Association for Computing Mac...
-
[22]
Microscaling data formats for deep learning, 2023
Bita Darvish Rouhani, Ritchie Zhao, Ankit More, Mathew Hall, Alireza Khodamoradi, Summer Deng, Dhruv Choudhary, Marius Cornea, Eric Dellinger, Kristof Denolf, Stosic Dusan, Venmugil Elango, Maximilian Golub, Alexander Heinecke, Phil James-Roxby, Dharmesh Jani, Gaurav Kolhe, Martin Langhammer, Ada Li, Levi Melnick, Maral Mes- makhosroshahi, Andres Rodrigue...
arXiv 2023
-
[23]
Introducing nvfp4 for efficient and accurate low-precision inference
NVIDIA. Introducing nvfp4 for efficient and accurate low-precision inference. https: //developer.nvidia.com/blog/introducing-nvfp4-for-efficient-and-accurat e-low-precision-inference/, 2025. Accessed: 2026-05-05
2025
-
[24]
Nvidia model-optimizer
NVIDIA. Nvidia model-optimizer. 2025. URL https://github.com/NVIDIA/Model-Opt imizer
2025
-
[25]
OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mark Chen, Enoch Cheung, Aidan Clark, Dan Cook, Marat Dukhan, Casey Dvorak, Kevin Fives, V...
Pith/arXiv arXiv 2025
-
[26]
nvidia/nvidia-nemotron-nano-9b-v2-nvfp4
NVIDIA. nvidia/nvidia-nemotron-nano-9b-v2-nvfp4. 2025. URL https://huggingface.co /nvidia/NVIDIA-Nemotron-Nano-9B-v2-NVFP4
2025
-
[27]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xiong- Hui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. InThe Thirty- ninth Annual Con...
2026
-
[28]
Janghwan Lee, Seongmin Park, Sukjin Hong, Minsoo Kim, Du-Seong Chang, and Jung- wook Choi. Improving conversational abilities of quantized large language models via di- rect preference alignment. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (V olume 1: ...
-
[29]
QeRL: Beyond efficiency - quantization-enhanced reinforcement learning for LLMs
Wei Huang, Yi Ge, Shuai Yang, Yicheng Xiao, Huizi Mao, Yujun Lin, Hanrong Ye, Sifei Liu, Ka Chun Cheung, Hongxu Yin, Yao Lu, Xiaojuan Qi, Song Han, and Yukang Chen. QeRL: Beyond efficiency - quantization-enhanced reinforcement learning for LLMs. InThe F ourteenth International Conference on Learning Representations, 2026. URL https://openreview.n et/forum...
2026
-
[30]
On the role of temperature sampling in test-time scaling, 2025
Yuheng Wu, Azalia Mirhoseini, and Thierry Tambe. On the role of temperature sampling in test-time scaling, 2025. URLhttps://arxiv.org/abs/2510.02611
arXiv 2025
-
[31]
Aime dataset
Maxwell-Jia. Aime dataset. 2024. URL https://huggingface.co/datasets/Maxwell-J ia/AIME_2024
2024
-
[32]
Adaserve: Accelerating multi-slo llm serving with slo-customized speculative decoding
Zikun Li, Zhuofu Chen, Remi Delacourt, Gabriele Oliaro, Zeyu Wang, Qinghan Chen, Shuhuai Lin, April Yang, Zhihao Zhang, Zhuoming Chen, Yi-Hsiang Lai, Xinhao Cheng, Xupeng Miao, and Zhihao Jia. Adaserve: Accelerating multi-slo llm serving with slo-customized speculative decoding. InProceedings of the 21st European Conference on Computer Systems, EUROSYS ’2...
-
[33]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023. URLhttps://arxiv.org/abs/2311.12022
Pith/arXiv arXiv 2023
-
[34]
Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint, 2024
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint, 2024
2024
-
[35]
Numinamath
Jia LI, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. Numinamath. [https://huggingface.co /datasets/AI-MO/NuminaMath-1.5](https://github.com/project-numina/aimo -progress-prize/blob/main...
2024
-
[36]
SEAL: Steerable reasoning calibration of large language models for free
Runjin Chen, Zhenyu Zhang, Junyuan Hong, Souvik Kundu, and Zhangyang Wang. SEAL: Steerable reasoning calibration of large language models for free. InSecond Conference on Language Modeling, 2025. URLhttps://openreview.net/forum?id=klPszYDIRT
2025
-
[37]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.arXiv e-prints, 2019
2019
-
[38]
Alternatively
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models, 2016. A Microscaling Formats Format Element Type Block Scale Global Scale Block Size MXFP4 FP4 (E2M1) FP8 (E8M0) – 32 NVFP4 FP4 (E2M1) FP8 (E4M3) FP32 16 Table 7: Configuration details of MXFP4 and NVFP4 formats. Table 7 lists the key configuration paramete...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.