Impact of Network Constraints on Fault-Tolerant Distributed Quantum Computing
Pith reviewed 2026-06-27 01:06 UTC · model grok-4.3
The pith
Network constraints create distinct regimes where optimal code distance and resource allocation shift in fault-tolerant distributed quantum computing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
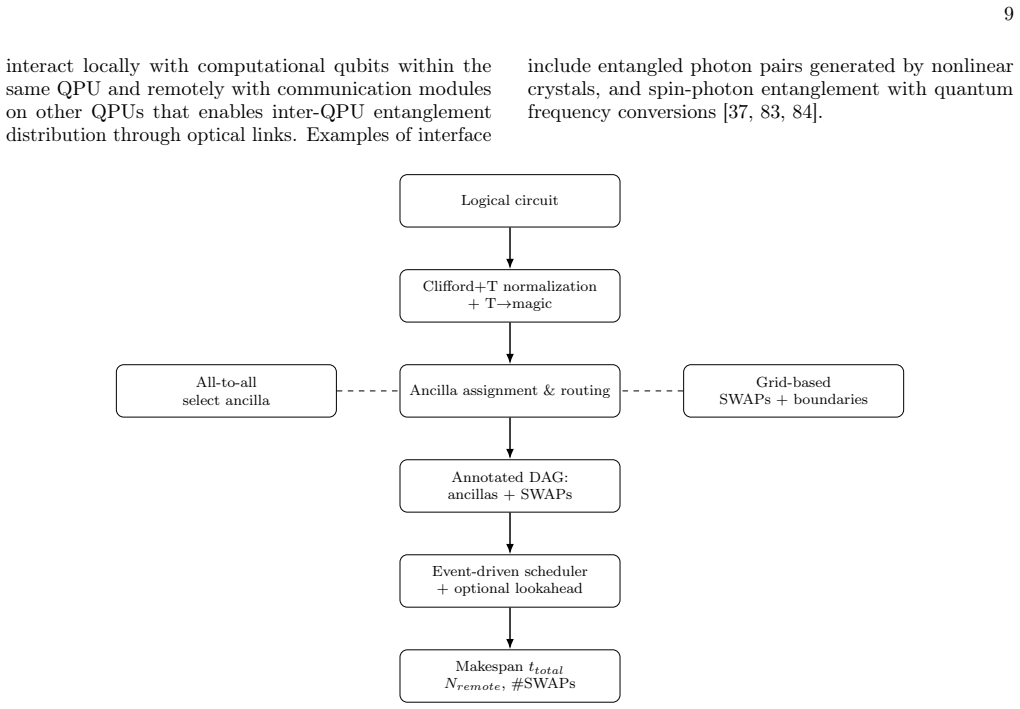
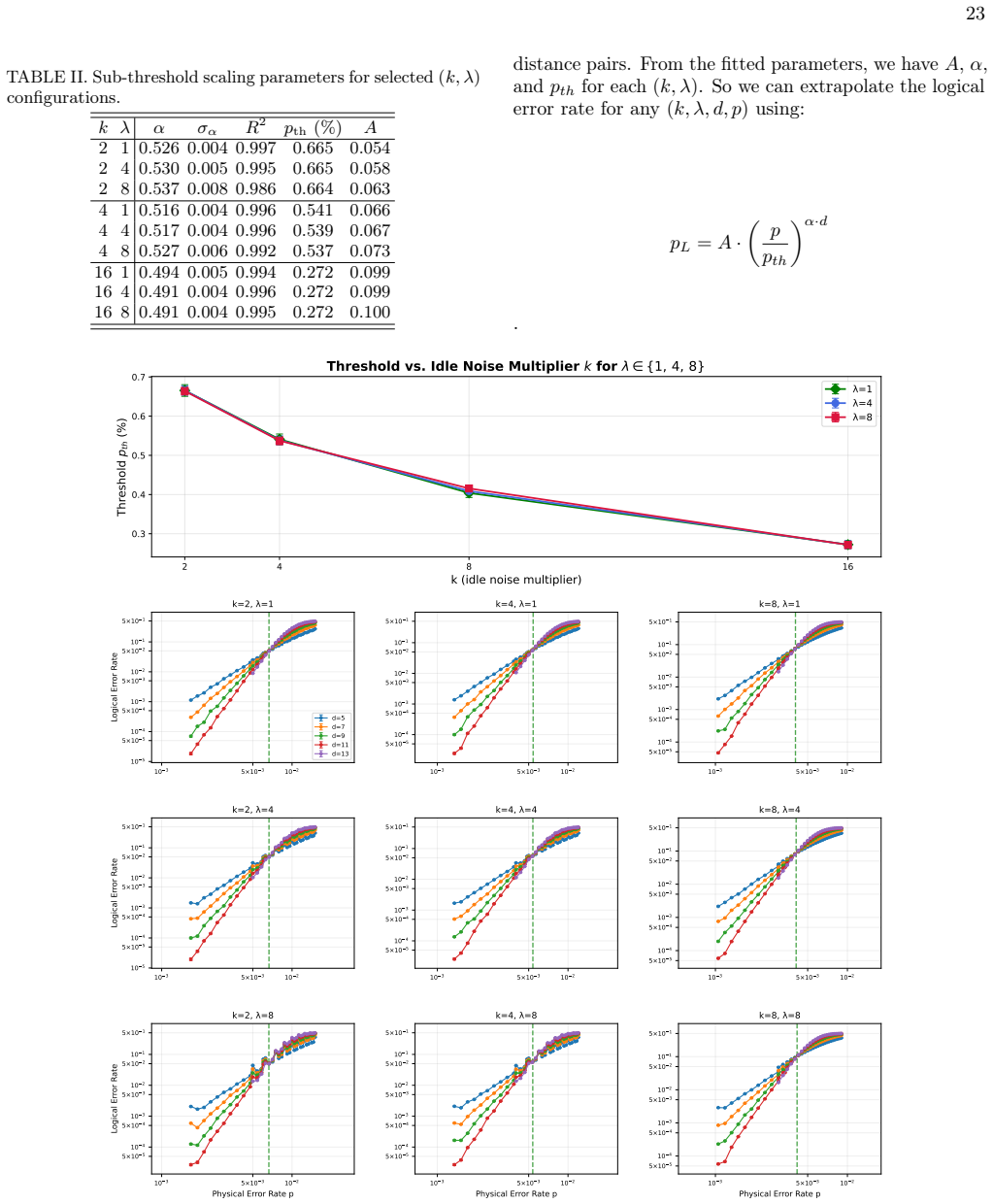
An end-to-end simulation framework jointly models surface-code operations, internal QPU connectivity, and realistic network constraints including finite entanglement generation rates, limited communication qubits, and bandwidth contention. The framework produces execution latency from which logical error rate estimates are obtained and is modular so that routing heuristics, scheduling policies, and network topologies can be swapped independently. Numerical evaluation reveals distinct operating regimes in which the optimal resource allocation and code distance selection shift depending on the network characteristics, exposing tradeoffs in distributed quantum computing architectures that remai
What carries the argument
The modular end-to-end simulation framework that jointly produces execution latency from surface-code operations and network constraints, then derives logical error rates.
If this is right
- Optimal resource allocation between computation and communication qubits changes with network properties.
- Preferred code distance varies across different entanglement generation rates and bandwidth conditions.
- Design tradeoffs appear only when computation and communication are simulated together.
- Modular replacement of routing or scheduling components allows targeted exploration of each regime.
Where Pith is reading between the lines
- Quantum data center planners may need to co-optimize entanglement hardware specifications together with error-correction parameters rather than choosing them sequentially.
- Scheduling policies could be extended to dynamically adjust code distance based on real-time network load measurements.
- The framework's modularity makes it possible to test whether specific routing heuristics remain effective when entanglement rates drop below a threshold.
Load-bearing premise
The mapping from simulated execution latency to logical error rate estimates accurately reflects real hardware behavior under the modeled network constraints.
What would settle it
Compare the framework's predicted logical error rates against measured error rates on a small-scale distributed quantum processor that enforces the same entanglement generation rates and qubit limits.
Figures

read the original abstract
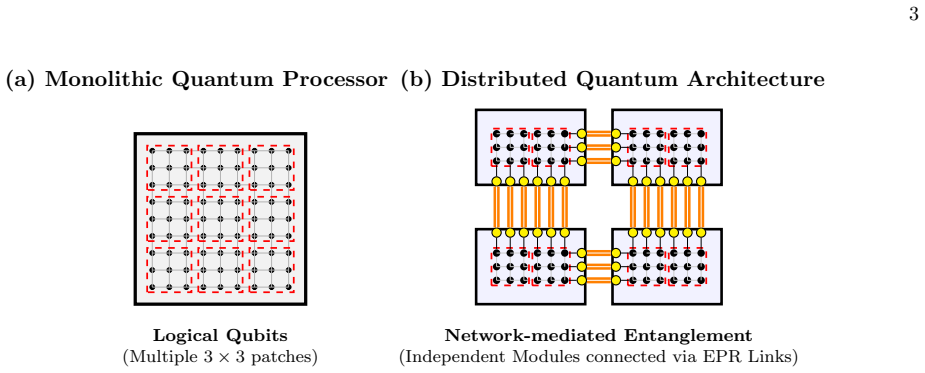
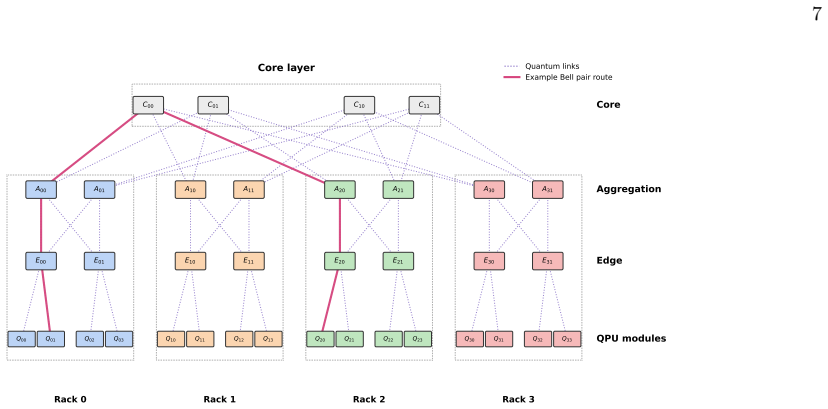
As we move towards scalable and modular quantum computing, quantum data centres become imperative. Existing analyses typically treat network constraints in isolation or through simplified models, leaving the interplay between error correction operations and communication resources underexplored. In this work, we present an end-to-end simulation framework that jointly models surface-code operations, internal QPU connectivity, and realistic network constraints including finite entanglement generation rates, limited communication qubits, and bandwidth contention, producing execution latency, from which logical error rate estimates are obtained. The framework is modular by design, allowing individual components such as routing heuristics, scheduling policies, and network topologies to be independently replaced. Numerical evaluation reveals distinct operating regimes in which the optimal resource allocation and code distance selection shift depending on the network characteristics. These results point to tradeoffs in the design of distributed quantum computing architectures that are not visible when computation and communication are modeled separately.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an end-to-end simulation framework that jointly models surface-code operations, internal QPU connectivity, and network constraints (finite entanglement generation rates, limited communication qubits, bandwidth contention). Execution latency produced by the joint model is converted to logical error rate estimates. Numerical evaluation identifies distinct operating regimes in which optimal resource allocation and code distance selection shift with network characteristics. The framework is designed to be modular, permitting independent substitution of routing heuristics, scheduling policies, and topologies.
Significance. If the latency-to-error mapping is shown to be valid, the work would be significant for highlighting tradeoffs in modular quantum architectures that separate computation and communication models miss. The modular design is a clear strength, enabling future extensions. The identification of network-dependent regimes could inform resource allocation in quantum data centers, provided the results are reproducible and the error model is justified.
major comments (1)
- [Framework description and numerical evaluation (abstract and associated sections)] The conversion from simulated execution latency to logical error rate estimates (central to the numerical evaluation and regime claims) lacks explicit justification or validation. It is unclear whether the mapping incorporates latency-dependent decoherence, timing jitter, or modified syndrome extraction fidelity due to network constraints, or instead applies an unadjusted standard threshold formula p_L(d, p_phys). This step is load-bearing for the claim that regimes shift with network characteristics; without it, the reported optima may not survive a more integrated error model.
minor comments (1)
- [Abstract] The abstract would be strengthened by reporting at least one concrete numerical example (e.g., a specific latency value, code distance, or regime boundary) together with simulation parameters and any baseline comparisons.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Framework description and numerical evaluation (abstract and associated sections)] The conversion from simulated execution latency to logical error rate estimates (central to the numerical evaluation and regime claims) lacks explicit justification or validation. It is unclear whether the mapping incorporates latency-dependent decoherence, timing jitter, or modified syndrome extraction fidelity due to network constraints, or instead applies an unadjusted standard threshold formula p_L(d, p_phys). This step is load-bearing for the claim that regimes shift with network characteristics; without it, the reported optima may not survive a more integrated error model.
Authors: We acknowledge the validity of this observation. The manuscript currently obtains logical error rate estimates by applying the standard threshold formula p_L(d, p_phys) with a fixed baseline physical error rate, without incorporating additional latency-dependent effects such as decoherence during network waits, timing jitter, or altered syndrome fidelity. We agree that this mapping requires explicit justification and that its limitations should be stated clearly to support the regime-shift claims. In the revised version we will insert a dedicated subsection in the methods that (i) states the exact formula and assumptions used, (ii) justifies the first-order approximation for the present study, and (iii) discusses the conditions under which a more integrated error model would be needed. We will also add a short paragraph in the discussion noting that future extensions could couple network latency directly into the error model. These changes will make the scope and robustness of the reported optima transparent. revision: yes
Circularity Check
Simulation framework yields latency-derived error estimates without reduction to input definitions
full rationale
The paper presents an end-to-end modular simulation that jointly models surface-code operations, internal QPU connectivity, and network constraints (finite entanglement rates, limited communication qubits, bandwidth contention) to generate execution latency, from which logical error rate estimates are obtained. Numerical evaluation then identifies operating regimes for resource allocation and code distance. No equations, fitted parameters, or self-citations are exhibited that reduce the reported regimes or error-rate mapping to definitions of the input parameters by construction. The framework is explicitly designed to allow independent replacement of components such as routing heuristics and scheduling policies, rendering the derivation chain self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
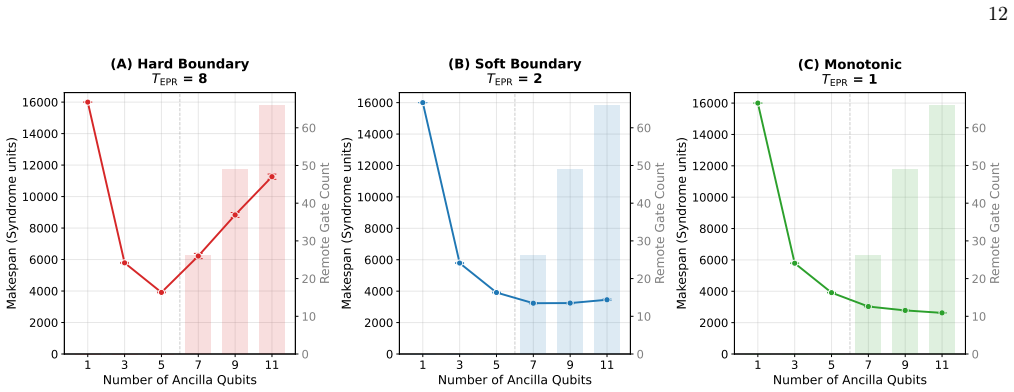
Ancilla Allocation We use the simulation framework to explore how ancilla allocation interacts with entanglement generation latency in determining the makespan of the circuit. Increasing the ancilla allocation improves parallelism by enabling more concurrent lattice-surgery operations, but simul- taneously reduces the effective computational capacity Qeff...
-
[2]
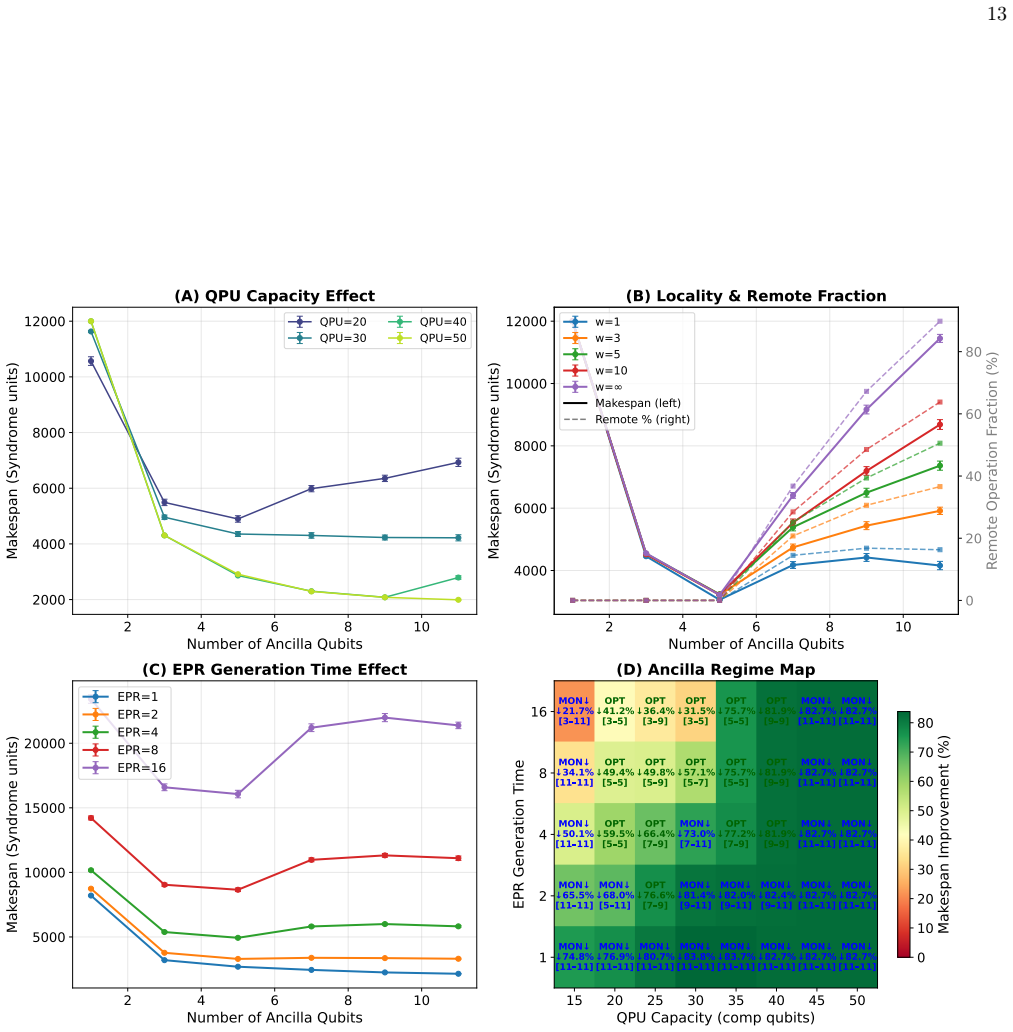
Figure 6 presents four com- plementary perspectives on resource tradeoffs
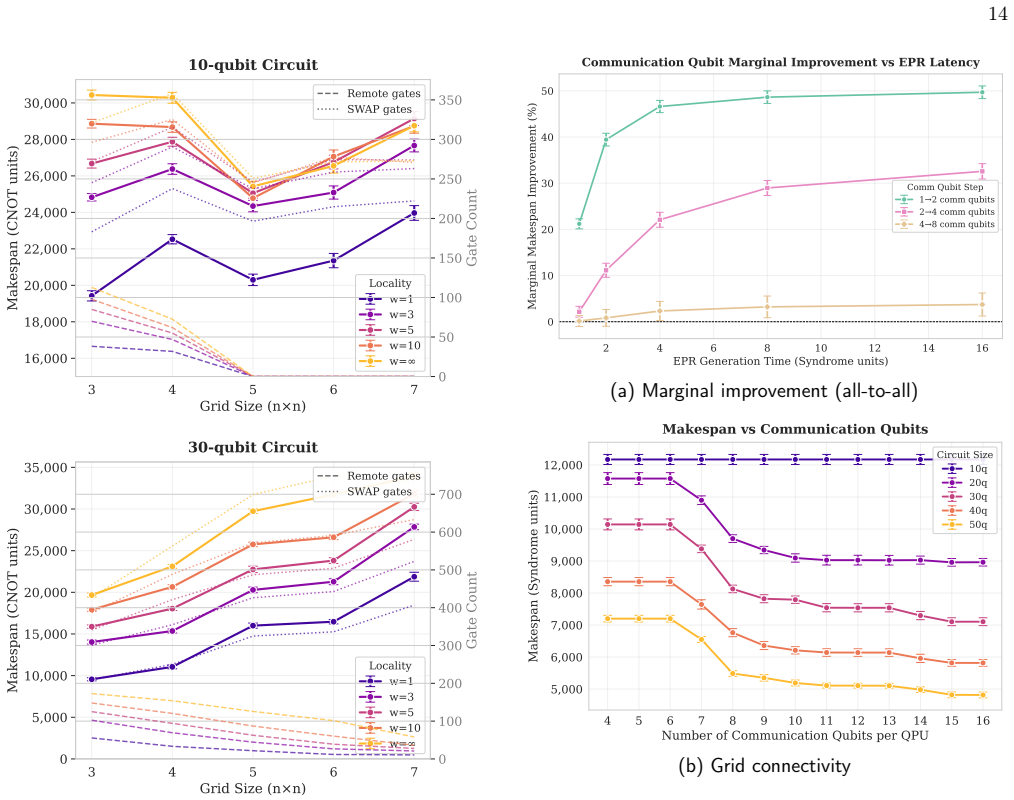
Parameter Space Exploration We now use the framework to systematically vary ar- chitectural parameters and examine their impact on dis- tributed execution latency. Figure 6 presents four com- plementary perspectives on resource tradeoffs. Panel A varies QPU capacity for a fixed circuit size. Smaller QPUs exhibit sharper optima: the transition from local t...
2000
-
[3]
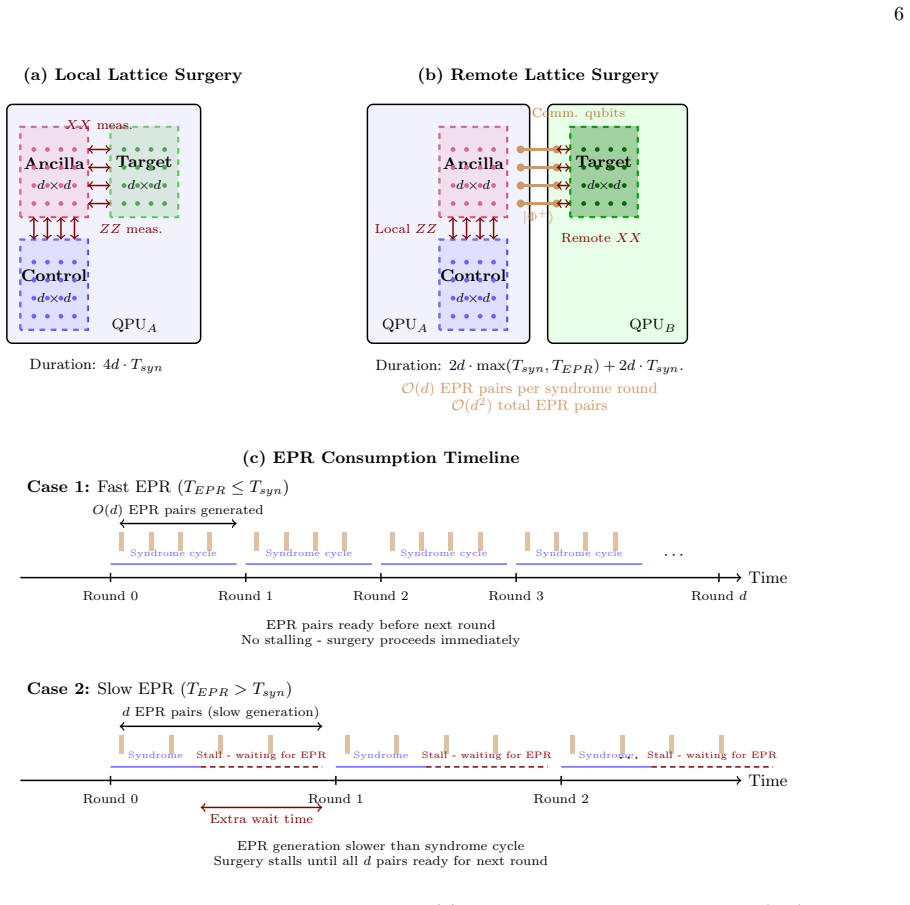
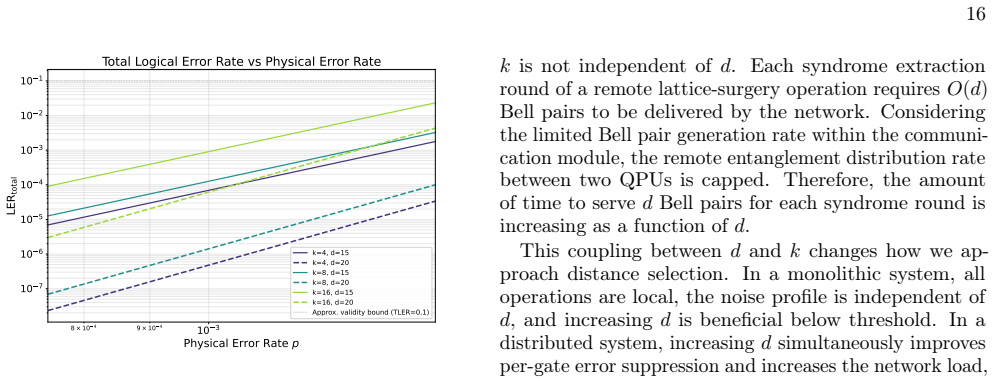
Extended idle times.Scheduling delays and entanglement generation waiting times increase the total idle duration experienced by all logical qubits, requiring additional memory protection rounds and accumulating memory errors
-
[4]
Data qubits participating in the gate experience elevated idle depolarization during these stretched rounds
Stretched syndrome rounds during remote gates.When TEPR > T syn, the entanglement- mediated syndrome rounds of a remote lattice- surgery operation are delayed, extending the ef- fective round duration. Data qubits participating in the gate experience elevated idle depolarization during these stretched rounds. This effect is cap- tured by the asymmetric no...
-
[5]
This effect is captured by the seam noise parameter λ in the asymmetric noise model (Appendix B) and enters the TLER through the per-gateLERg term
Bell pair infidelity.Entangled pairs used to me- diate remote parity measurements are generally of lower fidelity than local two-qubit gates, introduc- ing additional noise at inter-module boundaries. This effect is captured by the seam noise parameter λ in the asymmetric noise model (Appendix B) and enters the TLER through the per-gateLERg term. We appro...
-
[6]
Preskill, Quantum computing in the NISQ era and beyond, Quantum2, 79 (2018)
J. Preskill, Quantum computing in the NISQ era and beyond, Quantum2, 79 (2018)
2018
-
[7]
A. M. Dalzell, A. W. Harrow, D. E. Koh, and R. L. La Placa, How many qubits are needed for quantum computational supremacy?, Quantum4, 264 (2020)
2020
-
[8]
URL http://dx.doi.org/10.1103/RevModPhys.94.015004
K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Degroote, H. Heimonen, J. S. Kottmann, T. Menke, W.-K. Mok, S. Sim, L.-C. Kwek, and A. Aspuru-Guzik, Noisy intermediate-scale quantum algorithms, Reviews of Modern Physics94, 10.1103/revmodphys.94.015004 (2022)
-
[9]
Barral, F
D. Barral, F. J. Cardama, G. Díaz-Camacho, D. Faílde, I. F. Llovo, M. Mussa-Juane, J. Vázquez-Pérez, J. Vil- lasuso, C. Piñeiro, N. Costas, J. C. Pichel, T. F. Pena, and A. Gómez, Review of distributed quantum comput- ing: From single QPU to high performance quantum computing, Computer Science Review57, 100747 (2025)
2025
-
[10]
W. J. Huggins, T. Khattar, A. Xu, M. Harrigan, C. Kang, G. H. Low, A. Fowler, N. C. Rubin, and R. Babbush, The FLuid Allocation of Surface code Qubits (flasq) cost model for early fault-tolerant quantum algorithms (2025), arXiv:2511.08508 [quant-ph]
arXiv 2025
-
[11]
Leblond, R
T. Leblond, R. S. Bennink, J. G. Lietz, and C. M. Seck, TISCC: A Surface Code Compiler and Resource Estima- tor for Trapped-Ion Processors, inProceedings of the SC ’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, SC-W 2023 (ACM, 2023) pp. 1426–1435
2023
-
[12]
Litinski, A Game of Surface Codes: Large-Scale Quan- tum Computing with Lattice Surgery, Quantum3, 128 (2019)
D. Litinski, A Game of Surface Codes: Large-Scale Quan- tum Computing with Lattice Surgery, Quantum3, 128 (2019)
2019
-
[13]
M. E. Beverland, P. Murali, M. Troyer, K. M. Svore, T. Hoefler, V. Kliuchnikov, G. H. Low, M. Soeken, A. Sun- daram, and A. Vaschillo, Assessing requirements to scale to practical quantum advantage (2022), arXiv:2211.07629 [quant-ph]
Pith/arXiv arXiv 2022
-
[14]
M. Otten, B. Kang, D. Fedorov, J.-H. Lee, A. Benali, S. Habib, S. K. Gray, and Y. Alexeev, QREChem: quan- tum resource estimation software for chemistry applica- tions, Frontiers in Quantum Science and Technology2, 10.3389/frqst.2023.1232624 (2023)
-
[15]
van Dam, M
W. van Dam, M. Mykhailova, and M. Soeken, Using Azure Quantum Resource Estimator for Assessing Per- formance of Fault Tolerant Quantum Computation, in Proceedings of the SC ’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, SC-W 2023 (ACM, 2023) pp. 1414– 1419
2023
- [16]
-
[17]
Malinowski, D
M. Malinowski, D. T. C. Allcock, and C. J. Ballance, How to Wire a1000-Qubit Trapped-Ion Quantum Computer, PRX Quantum4, 040313 (2023)
2023
-
[18]
M. AbuGhanem, IBM quantum computers: evolution, performance, and future directions, The Journal of Su- percomputing81, 10.1007/s11227-025-07047-7 (2025)
-
[19]
Eickbusch, M
A. Eickbusch, M. McEwen, V. Sivak, A. Bourassa, J. Ata- laya, J. Claes,et al., Demonstration of dynamic surface codes, Nature Physics21, 1994 (2025)
1994
-
[20]
H. J. Manetsch, G. Nomura, E. Bataille, X. Lv, K. H. Leung, and M. Endres, A tweezer array with 6,100 highly coherent atomic qubits, Nature647, 60 (2025)
2025
-
[21]
S. Dasuet al., Computing with many encoded logi- cal qubits beyond break-even (2026), arXiv:2602.22211 [quant-ph]
arXiv 2026
-
[22]
L. J. Stephenson, D. P. Nadlinger, B. C. Nichol, S. An, P. Drmota, T. G. Ballance, K. Thirumalai, J. F. Goodwin, D. M. Lucas, and C. J. Ballance, High-rate, High-Fidelity Entanglement of Qubits Across an Elementary Quantum Network, Physical Review Letters124, 110501 (2020)
2020
-
[23]
Van Meter and S
R. Van Meter and S. J. Devitt, The Path to Scalable Dis- tributed Quantum Computing, Computer49, 31 (2016)
2016
-
[24]
Z. Yang, M. Zolanvari, and R. Jain, A survey of important issues in quantum computing and communications, IEEE Communications Surveys & Tutorials25, 1059 (2023)
2023
-
[25]
S. Pouryousef, E. Kaur, H. Shapourian, D. Towsley, R. Kompella, and R. Nejabati, Benchmarking Quan- tum Data Center Architectures: A Performance and Scalability Perspective (2026), arXiv:2601.01353, arXiv:2601.01353 [quant-ph]
arXiv 2026
-
[26]
D. L. Parnas, On the criteria to be used in decomposing systems into modules, Communications of the ACM15, 1053 (1972)
1972
-
[27]
J. H. Saltzer, D. P. Reed, and D. D. Clark, End-to- end arguments in system design, ACM Transactions on Computer Systems2, 277 (1984)
1984
-
[28]
Al-Fares, A
M. Al-Fares, A. Loukissas, and A. Vahdat, A scalable, commodity data center network architecture, inProceed- ings of the ACM SIGCOMM 2008 Conference on Data Communication, SIGCOMM ’08 (Association for Com- puting Machinery, 2008) pp. 63–74
2008
-
[29]
S. Wehner, D. Elkouss, and R. Hanson, Quantum internet: A vision for the road ahead, Science362, 10.1126/sci- ence.aam9288 (2018)
-
[30]
Cuomo, M
D. Cuomo, M. Caleffi, and A. S. Cacciapuoti, Towards a distributed quantum computing ecosystem, IET Quan- tum Communication1, 3 (2020)
2020
-
[31]
IBM, IBM quantum roadmap (2024), accessed: 2024-08- 07
2024
-
[32]
IonQ, IonQ achieves critical first step towards developing future quantum networks (2024), accessed: 2024-08-07
2024
-
[33]
C. Monroe, R. Raussendorf, A. Ruthven, K. R. Brown, P. Maunz, L.-M. Duan, and J. Kim, Large-scale mod- ular quantum-computer architecture with atomic mem- ory and photonic interconnects, Physical Review A89, 18 10.1103/physreva.89.022317 (2014)
-
[34]
D. Main, P. Drmota, D. P. Nadlinger, E. M. Ainley, A. Agrawal, B. C. Nichol, R. Srinivas, G. Araneda, and D. M. Lucas, Distributed quantum computing across an optical network link, Nature638, 383 (2025)
2025
-
[35]
Kaushal, B
V. Kaushal, B. Lekitsch, A. Stahl, J. Hilder, D. Pijn, C. Schmiegelow, A. Bermudez, M. Müller, F. Schmidt- Kaler, and U. Poschinger, Shuttling-based trapped-ion quantum information processing, AVS Quantum Science 2(2020)
2020
-
[36]
Magnard, S
P. Magnard, S. Storz, P. Kurpiers, J. Schär, F. Marxer, J. Lütolf, T. Walter, J.-C. Besse, M. Gabureac, K. Reuer, et al., Microwave quantum link between superconducting circuits housed in spatially separated cryogenic systems, Physical Review Letters125, 260502 (2020)
2020
-
[37]
J. Song, S. Yang, P. Liu, H.-L. Zhang, G.-M. Xue, Z.- Y. Mi, W.-G. Zhang, F. Yan, Y.-R. Jin, and H.-F. Yu, Realization of high-fidelity perfect entanglers between remote superconducting quantum processors, Physical Review Letters135, 10.1103/npr7-b7kq (2025)
-
[38]
H. K. Warner, J. Holzgrafe, B. Yankelevich, D. Barton, S. Poletto, C. J. Xin, N. Sinclair, D. Zhu, E. Sete, B. Lan- gley,et al., Coherent control of a superconducting qubit using light, Nature Physics21, 831 (2025)
2025
-
[39]
Tang, A 1-km photonic link connecting superconducting circuits in two dilution refrigerators, Nature Photonics , 1 (2026)
Y.Zhou, Y.Wu, C.Li, M.Shen, L.Yang, J.Xie,andH.X. Tang, A 1-km photonic link connecting superconducting circuits in two dilution refrigerators, Nature Photonics , 1 (2026)
2026
-
[40]
Bluvstein, H
D. Bluvstein, H. Levine, G. Semeghini, T. T. Wang, S. Ebadi, M. Kalinowski, A. Keesling, N. Maskara, H. Pichler, M. Greiner, V. Vuletić, and M. D. Lukin, A quantum processor based on coherent transport of entangled atom arrays, Nature604, 451 (2022)
2022
-
[41]
S. Sunami, S. Tamiya, R. Inoue, H. Yamasaki, and A. Goban, Scalable networking of neutral-atom qubits: Nanofiber-based approach for multiprocessor fault-tolerant quantum computers, PRX Quantum6, 10.1103/prxquantum.6.010101 (2025)
-
[42]
Van Leent, M
T. Van Leent, M. Bock, F. Fertig, R. Garthoff, S. Eppelt, Y. Zhou, P. Malik, M. Seubert, T. Bauer, W. Rosenfeld, et al., Entangling single atoms over 33 km telecom fibre, Nature607, 69 (2022)
2022
-
[43]
Gottesman, Theory of fault-tolerant quantum compu- tation, Physical Review A57, 127 (1998)
D. Gottesman, Theory of fault-tolerant quantum compu- tation, Physical Review A57, 127 (1998)
1998
-
[44]
A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, Surface codes: Towards practical large-scale quantum computation, Physical Review A86, 032324 (2012)
2012
-
[45]
Dennis, A
E. Dennis, A. Kitaev, A. Landahl, and J. Preskill, Topological quantum memory, Journal of Mathematical Physics43, 4452 (2002)
2002
-
[46]
J. Stack, M. Wang, and F. Mueller, Transversal fault tol- erant distributed quantum computing operations (2026), arXiv:2504.05611 [quant-ph]
Pith/arXiv arXiv 2026
-
[47]
Jacinto, E
H. Jacinto, E. Gouzien, and N. Sangouard, Network re- quirements for distributed quantum computation, Physi- cal Review Research8, 013205 (2026)
2026
-
[48]
Horsman, A
D. Horsman, A. G. Fowler, S. Devitt, and R. Van Meter, Surface code quantum computing by lattice surgery, New Journal of Physics14, 123011 (2012)
2012
-
[49]
N. H. Nickerson, Y. Li, and S. C. Benjamin, Topological quantum computing with a very noisy network and local error rates approaching one percent, Nature Communica- tions4, 10.1038/ncomms2773 (2013)
-
[50]
N. H. Nickerson, J. F. Fitzsimons, and S. C. Benjamin, Freely scalable quantum technologies using cells of 5-to-50 qubits with very lossy and noisy photonic links, Physical Review X4, 10.1103/physrevx.4.041041 (2014)
-
[51]
Y. Li and S. C. Benjamin, Hierarchical surface code for network quantum computing with modules of arbitrary size, Physical Review A94, 10.1103/physreva.94.042303 (2016)
-
[52]
Fault-tolerant con- nection of error-corrected qubits with noisy links,
J. Ramette, J. Sinclair, N. P. Breuckmann, and V. Vuletić, Fault-tolerant connection of error-corrected qubits with noisy links, npj Quantum Information10, 10.1038/s41534-024-00855-4 (2024)
-
[53]
A. Márton, L. Colmenarez, L. Bödeker, and M. Müller, Lattice surgery-based logical state teleportation via noisy links, Physical Review Research7, 10.1103/ppng-vbqj (2025)
-
[54]
Sutcliffe, B
E. Sutcliffe, B. Jonnadula, C. Le Gall, A. E. Moylett, and C. M. Westoby, Distributed quantum error correc- tion based on hyperbolic floquet codes, in2025 IEEE International Conference on Quantum Computing and Engineering (QCE)(IEEE, 2025) p. 649–657
2025
-
[55]
N. K. Chandra, D. Tipper, R. Nejabati, E. Kaur, and K. P. Seshadreesan, Distributed Realization of Color Codes for Quantum Error Correction, in2025 IEEE International Conference on Quantum Computing and Engineering (QCE)(IEEE, 2025) p. 2482–2492
2025
-
[56]
N. K. Chandra, E. Kaur, R. Nejabati, and K. P. Se- shadreesan, Distributed quantum error correction with bivariate bicycle codes in a modular architecture (2026), arXiv:2605.04663 [quant-ph]
Pith/arXiv arXiv 2026
-
[57]
J. Ramette, J. Sinclair, Z. Vendeiro, A. Rudelis, M. Cetina, and V. Vuletić, Any-to-any connected cavity- mediated architecture for quantum computing with trapped ions or Rydberg arrays, PRX Quantum3, 10.1103/prxquantum.3.010344 (2022)
-
[58]
H. Shapourian, E. Kaur, T. Sewell, J. Zhao, M. Kilzer, R. Kompella, and R. Nejabati, Quantum data center in- frastructures: A scalable architectural design perspective (2025), arXiv:2501.05598 [quant-ph]
arXiv 2025
-
[60]
S. F. Lin, J. Viszlai, K. N. Smith, G. S. Ravi, C. Yuan, F.T. Chong,andB. J.Brown,Codesign ofquantumerror- correcting codes and modular chiplets in the presence of defects, inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’24 (ACM, 2024) pp. 216–231
2024
-
[61]
Bravyi and A
S. Bravyi and A. Kitaev, Universal quantum computation with ideal Clifford gates and noisy ancillas, Physical Review A71, 022316 (2005)
2005
-
[62]
Bluvstein, S
D. Bluvstein, S. J. Evered, A. A. Geim, S. H. Li, H. Zhou, T. Manovitz, S. Ebadi, M. Cain, M. Kalinowski, D. Hangleiter, J. P. Bonilla Ataides, N. Maskara, I. Cong, X. Gao, P. Sales Rodriguez, T. Karolyshyn, G. Semeghini, M. J. Gullans, M. Greiner, V. Vuletić, and M. D. Lukin, Logical quantum processor based on reconfigurable atom arrays, Nature626, 58 (2023)
2023
-
[63]
Zomorodi-Moghadam, M
M. Zomorodi-Moghadam, M. Houshmand, and M. Housh- mand, Optimizing teleportation cost in distributed quan- tum circuits, International Journal of Theoretical Physics 57, 848–861 (2017)
2017
-
[64]
P. Andrés-Martínez and C. Heunen, Automated distri- bution of quantum circuits via hypergraph partitioning, 19 Physical Review A100, 10.1103/physreva.100.032308 (2019)
-
[65]
Houshmand, Z
M. Houshmand, Z. Mohammadi, M. Zomorodi- Moghadam, and M. Houshmand, An evolutionary ap- proach to optimizing communication cost in distributed quantum computation (2019)
2019
-
[66]
Nikahd, N
E. Nikahd, N. Mohammadzadeh, M. Sedighi, and M. S. Zamani, Automated window-based partitioning of quan- tum circuits, Physica Scripta96, 035102 (2021)
2021
-
[67]
E. Kaur, S. Pouryousef, H. Shapourian, J. Zhao, M. Kilzer, R. Kompella, and R. Nejabati, Optimized quantum circuit partitioning across multiple quantum processors, IEEE Transactions on Quantum Engineering 6, 1–17 (2025)
2025
-
[68]
J. M. Baker, C. Duckering, A. Hoover, and F. T. Chong, Time-sliced quantum circuit partitioning for modular ar- chitectures, inProceedings of the 17th ACM International Conference on Computing Frontiers, CF ’20 (ACM, 2020) p. 98–107
2020
-
[69]
Ferrari, A
D. Ferrari, A. S. Cacciapuoti, M. Amoretti, and M. Cal- effi, Compiler design for distributed quantum computing, IEEE Transactions on Quantum Engineering2, 1–20 (2021)
2021
-
[70]
Cuomo, M
D. Cuomo, M. Caleffi, K. Krsulich, F. Tramonto, G. Agliardi, E. Prati, and A. S. Cacciapuoti, Optimized compilerfordistributedquantumcomputing,ACMTrans- actions on Quantum Computing4, 1–29 (2023)
2023
-
[71]
A. Wu, H. Zhang, G. Li, A. Shabani, Y. Xie, and Y. Ding, Autocomm: A framework for enabling efficient commu- nication in distributed quantum programs, in2022 55th IEEE/ACM International Symposium on Microarchitec- ture (MICRO)(2022) pp. 1027–1041
2022
-
[72]
Clos, A study of non-blocking switching networks, Bell System Technical Journal32, 406 (1953)
C. Clos, A study of non-blocking switching networks, Bell System Technical Journal32, 406 (1953)
1953
-
[73]
J. Kim, W. J. Dally, S. Scott, and D. Abts, Technology- driven, highly-scalable dragonfly topology, in2008 Inter- national Symposium on Computer Architecture(IEEE,
-
[74]
D. Sakuma, T. Tsuno, H. Shimizu, Y. Kurosawa, M. T. Friedrich, K. Teramoto, A. Taherkhani, A. Todd, Y. Ueno, M. Hajdušek, R. Ikuta, R. V. Meter, T. Sasaki, and S. Nagayama, Q-fly: An optical interconnect for modular quantum computers (2024), arXiv:2412.09299, arXiv:2412.09299 [quant-ph]
arXiv 2024
-
[75]
Greenberg, J
A. Greenberg, J. R. Hamilton, N. Jain, S. Kandula, C. Kim, P. Lahiri, D. A. Maltz, P. Patel, and S. Sengupta, VL2: a scalable and flexible data center network, ACM SIGCOMM Computer Communication Review39, 51 (2009)
2009
-
[76]
C. E. Leiserson, Fat-trees: universal networks for hardware-efficient supercomputing, IEEE Transactions on Computers34, 892 (1985)
1985
-
[77]
S. Xu, A. Lu, and Y. Ding, Fat-tree QRAM: A high- bandwidth shared quantum random access memory for parallel queries, inProceedings of the 30th ACM Inter- national Conference on Architectural Support for Pro- gramming Languages and Operating Systems, Volume 2, ASPLOS ’25 (ACM, 2025) pp. 390–406
2025
-
[78]
Alqahtani and B
J. Alqahtani and B. Hamdaoui, Rethinking fat-tree topol- ogy design for cloud data centers, in2018 IEEE Global Communications Conference (GLOBECOM)(IEEE,
-
[79]
J. Zhao, Y. Xu, X. Lu, E. Kaur, M. Kilzer, R. Kompella, R. W. Boyd, and R. Nejabati, Scalable low-latency entan- glement distribution for distributed quantum computing, Optica Quantum3, 606 (2025)
2025
-
[80]
Bernien, B
H. Bernien, B. Hensen, W. Pfaff, G. Koolstra, M. S. Blok, L. Robledo, T. H. Taminiau, M. Markham, D. J. Twitchen, L. Childress, and R. Hanson, Heralded entan- glement between solid-state qubits separated by three metres, Nature497, 86 (2013)
2013
-
[81]
Development of Quantum Interconnects (QuICs) for Next-Generation Information Technologies,
D. Awschalom, K. K. Berggren, H. Bernien, S. Bhave, L. D. Carr, P. Davids, S. E. Economou, D. Englund, A. Faraon, M. Fejer, S. Guha, M. V. Gustafsson, E. Hu, L. Jiang, J. Kim, B. Korzh, P. Kumar, P. G. Kwiat, M. Lončar, M. D. Lukin, D. A. Miller, C. Monroe, S. W. Nam, P. Narang, J. S. Orcutt, M. G. Raymer, A. H. Safavi-Naeini, M. Spiropulu, K. Srinivasan,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.