MedCRP-CL: Continual Medical Image Segmentation via Bayesian Nonparametric Semantic Modality Discovery
Pith reviewed 2026-05-21 07:31 UTC · model grok-4.3
The pith
MedCRP-CL uses the Chinese Restaurant Process on clinical text prompts to discover semantic modality groupings for continual medical image segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
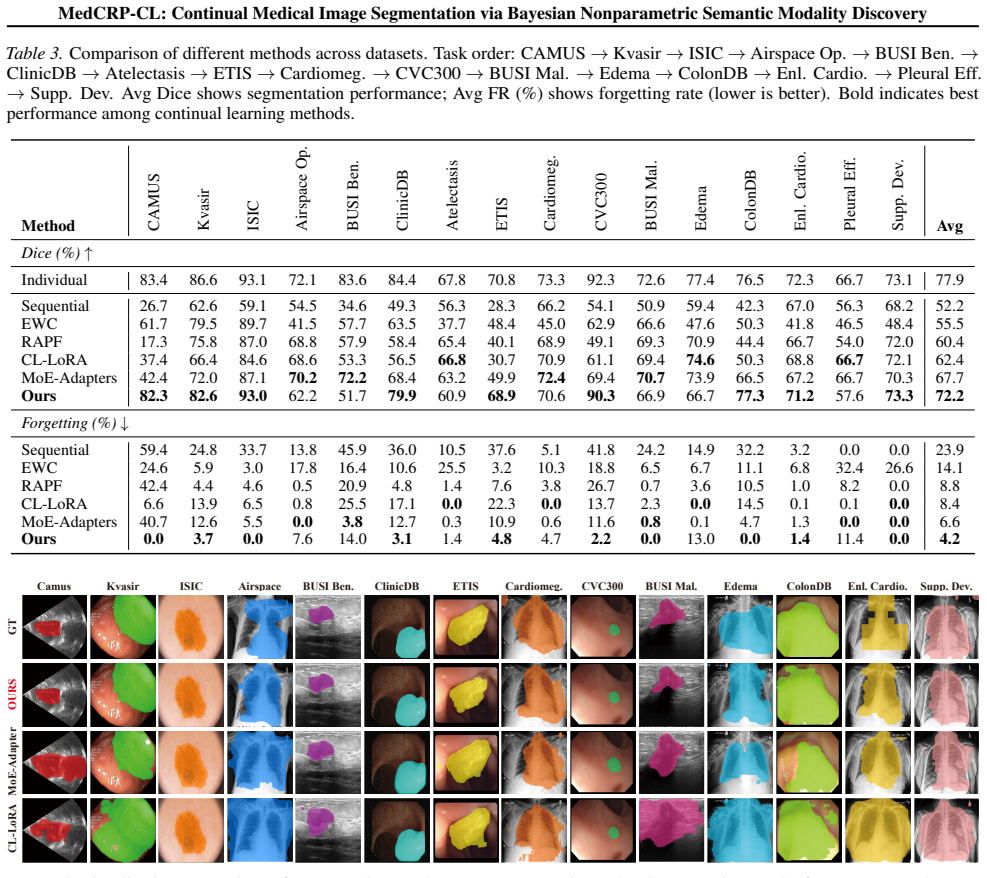
The central claim is that semantic modalities inferred via the Chinese Restaurant Process from clinical text prompts enable semantic-modality-specific LoRA adapters regularized by intra-modality EWC, producing 73.3% Dice score with 4.1% forgetting on 16 tasks while using 6 times fewer parameters than the best baseline.
What carries the argument
The Chinese Restaurant Process, which dynamically assigns arriving tasks to semantic modality clusters based on clinical text prompts describing anatomical regions and pathological context.
If this is right
- Parameter isolation across dissimilar semantic modalities combined with sharing inside modalities reduces interference while preserving knowledge transfer.
- Replay-free operation is possible by storing only aggregate statistics rather than raw images.
- The framework scales to an arbitrary number of future tasks because the CRP does not require a pre-specified number of clusters.
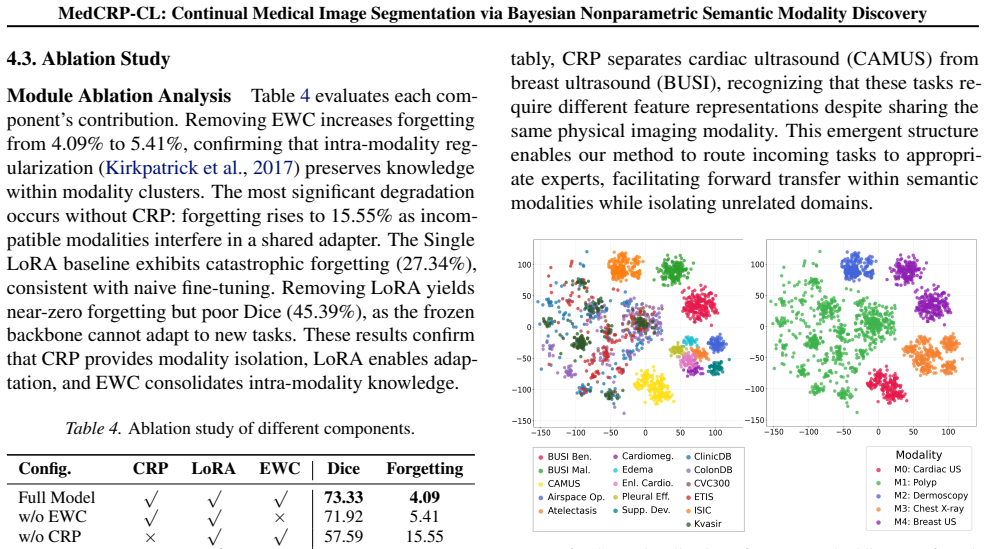
- Performance gains hold across four physical imaging modalities when the discovered semantic groupings cut across them.
Where Pith is reading between the lines
- The same text-prompt CRP mechanism could be tested on non-medical continual learning problems where task descriptions are available in natural language.
- If the inferred groupings prove stable across different prompt styles, the method might reduce reliance on expert-defined task taxonomies in medical imaging pipelines.
- Extending the approach to include image-derived features alongside text could test whether purely textual prompts are the minimal sufficient signal.
Load-bearing premise
Clinical text prompts contain sufficient reliable information about anatomical regions and pathological context to let the Chinese Restaurant Process infer meaningful semantic modality groupings without future tasks or predefined cluster counts.
What would settle it
An experiment showing that the groupings produced by the CRP on clinical text do not improve Dice scores or forgetting rates over a single shared model or over random groupings on the same 16-task sequence.
Figures




read the original abstract
Medical image segmentation faces a fundamental challenge in continual learning: data arrives sequentially from heterogeneous sources, yet effective continual learning requires discovering which tasks share sufficient structure to benefit from joint learning. Existing methods either apply uniform constraints across all tasks, causing catastrophic forgetting when tasks conflict, or require predefined task groupings that cannot anticipate future task diversity. We introduce MedCRP-CL, a framework that performs online task structure discovery and structure-aware continual learning. Leveraging the Chinese Restaurant Process (CRP), our method dynamically infers task groupings from clinical text prompts as tasks arrive, without requiring predefined cluster counts or access to future tasks. We term these discovered groupings semantic modalities, as they capture finer-grained structure than physical imaging modalities by integrating anatomical region and pathological context. Guided by this discovered structure, we maintain semantic modality-specific LoRA adapters regularized by intra-modality EWC, ensuring parameter isolation across dissimilar task groups while facilitating knowledge transfer within similar ones. The framework is also replay-free, storing only aggregate statistics rather than raw patient data. Experiments on 16 medical segmentation tasks across four imaging modalities demonstrate that MedCRP-CL achieves 73.3% Dice score with only 4.1% forgetting, outperforming the best baseline by 8.0% while requiring 6$\times$ fewer parameters. Code is available at https://github.com/zygao930/MedCRP-CL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedCRP-CL for continual medical image segmentation. It uses the Chinese Restaurant Process (CRP) to dynamically discover semantic modalities from clinical text prompts as tasks arrive online. These groupings inform the maintenance of semantic modality-specific LoRA adapters regularized by intra-modality EWC. The approach is replay-free and is evaluated on 16 tasks across four modalities, achieving 73.3% Dice score with 4.1% forgetting, outperforming the best baseline by 8.0% with 6× fewer parameters.
Significance. If the results hold and the discovered groupings are meaningful, this represents a significant advance in continual learning for medical imaging by enabling nonparametric, text-guided task structure discovery without predefined clusters or future task knowledge. It balances parameter efficiency, privacy (no replay), and performance in heterogeneous settings.
major comments (2)
- The abstract states performance numbers (73.3% Dice, 4.1% forgetting, 8.0% improvement) but supplies no experimental protocol, baseline details, statistical tests, or ablation results. This prevents verification that the reported gains are attributable to the claimed CRP-based semantic modality discovery mechanism.
- The framework assigns tasks to semantic modalities via CRP on clinical text prompts, but the specific embedding process, likelihood model, or similarity kernel for the CRP is not detailed. Without this, it is unclear if the online decisions produce groupings that align with imaging task similarities rather than superficial text features.
minor comments (2)
- The distinction between 'semantic modalities' and standard imaging modalities could be illustrated with a concrete example of how text prompts lead to different groupings.
- Consider adding a table or figure showing the discovered cluster assignments across the 16 tasks to allow readers to assess the quality of the CRP inferences.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, clarifying details present in the manuscript and indicating where revisions have been made to improve verifiability and technical exposition.
read point-by-point responses
-
Referee: The abstract states performance numbers (73.3% Dice, 4.1% forgetting, 8.0% improvement) but supplies no experimental protocol, baseline details, statistical tests, or ablation results. This prevents verification that the reported gains are attributable to the claimed CRP-based semantic modality discovery mechanism.
Authors: The abstract is a concise summary; the complete experimental protocol (16 tasks across four modalities with the specified task arrival order), baseline descriptions (including replay-based and parameter-isolation methods), statistical tests (paired t-tests with p-values reported), and ablations (isolating CRP discovery, EWC regularization, and LoRA adapter allocation) appear in Sections 4 and 5. To address the concern directly, we have added a short clause to the abstract referencing the 16-task heterogeneous evaluation and inserted a results summary table with standard deviations and significance markers in the revised manuscript. revision: partial
-
Referee: The framework assigns tasks to semantic modalities via CRP on clinical text prompts, but the specific embedding process, likelihood model, or similarity kernel for the CRP is not detailed. Without this, it is unclear if the online decisions produce groupings that align with imaging task similarities rather than superficial text features.
Authors: Section 3.2 already specifies that clinical text prompts are encoded with a frozen BioBERT model, that the CRP uses a concentration parameter of 1.0, and that table assignment employs a cosine-similarity kernel on the resulting embeddings under a diagonal-Gaussian likelihood. To eliminate any ambiguity, we have expanded this section with the exact embedding dimensionality, the posterior sampling procedure, and a new qualitative table showing that discovered semantic modalities group tasks by anatomical region and pathology rather than lexical overlap. revision: yes
Circularity Check
No significant circularity; standard CRP applied to external prompts
full rationale
The paper applies the standard Chinese Restaurant Process as a Bayesian nonparametric prior to infer groupings from clinical text prompts, without any equations or steps that define outputs in terms of the method's own fitted parameters or predictions. The described framework uses these groupings to assign modality-specific LoRA adapters with intra-modality EWC, but the central claims rest on empirical results across 16 tasks rather than any self-definitional reduction, fitted-input prediction, or load-bearing self-citation chain. No uniqueness theorems, ansatzes, or renamings are invoked in a manner that collapses the derivation to its inputs by construction. The approach is self-contained against external benchmarks with independent content from the CRP application.
Axiom & Free-Parameter Ledger
free parameters (1)
- CRP concentration parameter
axioms (1)
- domain assumption Clinical text prompts encode sufficient anatomical and pathological information to support meaningful task grouping via CRP
invented entities (1)
-
semantic modalities
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On Tiny Episodic Memories in Continual Learning
Chaudhry, A., Rohrbach, M., Elhoseiny, M., Ajanthan, T., Dokania, P. K., Torr, P. H. S., and Ranzato, M. On tiny episodic memories in Continual Learning.arXiv preprint arXiv:1902.10486,
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[2]
Low-rank mixture-of-experts for continual medical image segmentation
Chen, Q., Zhu, L., He, H., Zhang, X., Zeng, S., Ren, Q., and Lu, Y . Low-rank mixture-of-experts for continual medical image segmentation. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2024, volume LNCS 15008, pp. 382–392. Springer Nature Switzerland,
work page 2024
-
[3]
Codella, N. C. F., Gutman, D., Celebi, M. E., Helba, B., Marchetti, M. A., Dusza, S. W., Kalloo, A., Liopyris, K., Mishra, N., Kittler, H., and Halpern, A. Skin lesion anal- ysis toward melanoma detection: A challenge at the 2017 International Symposium on Biomedical Imaging (ISBI), hosted by the International Skin Imaging Collaboration (ISIC). InIEEE Int...
work page 2017
-
[4]
Eslami, S., Meinel, C., and de Melo, G. Pubmedclip: How much does clip benefit visual question answering in the medical domain? InFindings of the Association for Computational Linguistics: EACL 2023, pp. 1181–1193,
work page 2023
-
[5]
Rebuffi, S.-A., Kolesnikov, A., Sperl, G., and Lampert, C. H. iCaRL: Incremental classifier and representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2001– 2010,
work page 2001
-
[6]
Rusu, A. A., Rabinowitz, N. C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., and Had- sell, R. Progressive neural networks.arXiv preprint arXiv:1606.04671,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Trace: Temporally reliable anatomically-conditioned 3d ct gen- eration with enhanced efficiency
Shao, M., Miao, X., Duan, H., Wang, Z., Chen, J., Huang, Y ., Wu, X., Deng, J., Long, Y ., and Zheng, Y . Trace: Temporally reliable anatomically-conditioned 3d ct gen- eration with enhanced efficiency. InMedical Image Computing and Computer Assisted Intervention – MIC- CAI 2025, volume LNCS 15963. Springer, 2025a. doi: 10.1007/978-3-032-04965-0
-
[8]
Shao, M., Wang, Z., Duan, H., Huang, Y ., Zhai, B., Wang, S., Long, Y ., and Zheng, Y . Rethinking brain tumor seg- mentation from the frequency domain perspective.IEEE Transactions on Medical Imaging, 44(11):4536–4553, 2025b. doi: 10.1109/TMI.2025.3579213. Silva, J., Histace, A., Romain, O., Dray, X., and Granado, B. Toward embedded detection of polyps i...
-
[9]
J., Fern ´andez- Esparrach, G., L ´opez, A
V´azquez, D., Bernal, J., S ´anchez, F. J., Fern ´andez- Esparrach, G., L ´opez, A. M., Romero, A., Drozdzal, M., and Courville, A. A benchmark for endoluminal scene segmentation of colonoscopy images. InJournal of Healthcare Engineering, volume 2017, pp. 4037190,
work page 2017
-
[10]
Yoon, J., Yang, E., Lee, J., and Hwang, S
doi: 10.1609/aaai.v39i8.32953. Yoon, J., Yang, E., Lee, J., and Hwang, S. J. Lifelong learning with dynamically expandable networks. InPro- ceedings of the International Conference on Learning Representations,
-
[11]
Zhang, S., Xu, Y ., Usuyama, N., Xu, H., Bagga, J., Tinn, R., Preston, S., Rao, R., Wei, M., Valluri, N., Wong, C., Tupini, A., Wang, Y ., Mazzola, M., Shukla, S., Liden, L., Gao, J., Crabtree, A., Piening, B., Bifulco, C., Lungren, M. P., Naumann, T., Wang, S., and Poon, H. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen mill...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
The log-likelihood ratio ℓ(s) defined in Eq
Proof. The log-likelihood ratio ℓ(s) defined in Eq. 5 acts as a binary classifier between same-modality and different-modality hypotheses. Under the Gaussian assumption, the optimal decision boundary is at: s∗ = µintraσ2 inter +µ interσ2 intra σ2 intra +σ 2 inter (16) The classification error is bounded by: Perror =P(s intra < s ∗) +P(s inter > s ∗)≤2 exp...
work page 2017
-
[13]
By Taylor expansion: Lt(θ(m) k )− L ∗ t ≈ 1 2(θ(m) k −θ (0) k )⊤Ht(θ(m) k −θ (0) k )(20) UsingH t ⪯ ¯Fk (Fisher information approximates Hessian at convergence) and∥x∥ 2 ¯Fk ≥λ min( ¯Fk)∥x∥2: Lt(θ(m) k )− L ∗ t ≤ 1 2λmin( ¯Fk) ∥θ(m) k −θ (0) k ∥2 ¯Fk ≤ 1 λ·λ min( ¯Fk) mX j=1 ∥∇θk Lt+j∥2 (21) Critically, this bound involves only tasks within modalityk. Tas...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.