Comparing Transformers and Hybrid Models at the Token Level
Pith reviewed 2026-06-26 16:59 UTC · model grok-4.3
The pith
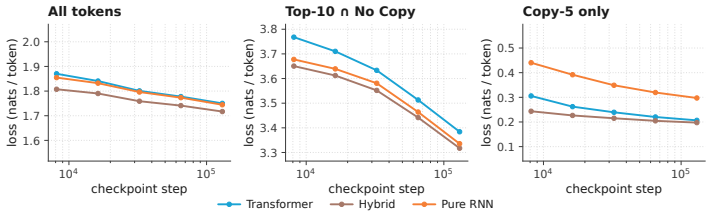
Hybrid models lower loss on semantic state tokens while transformers excel on n-grams and bracket matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
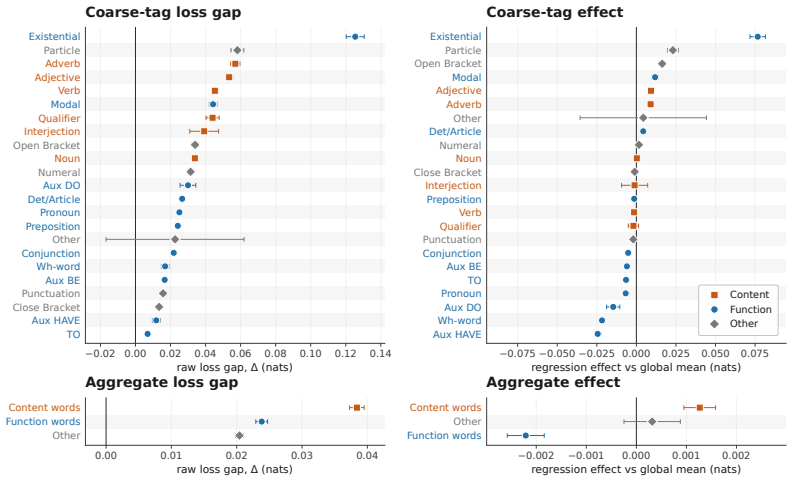
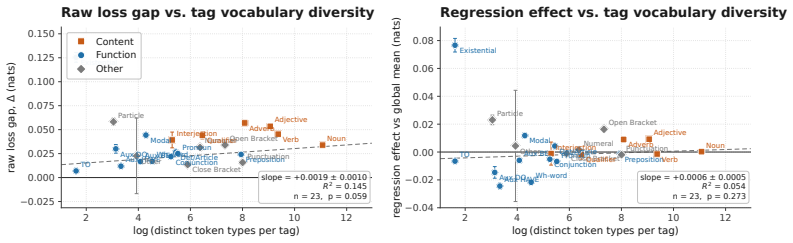
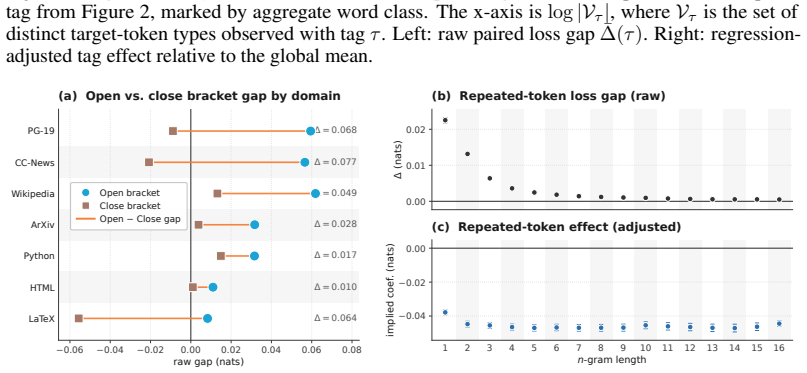
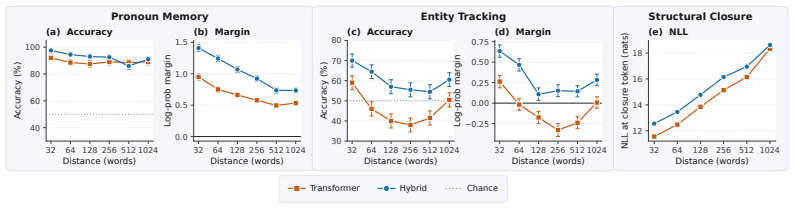
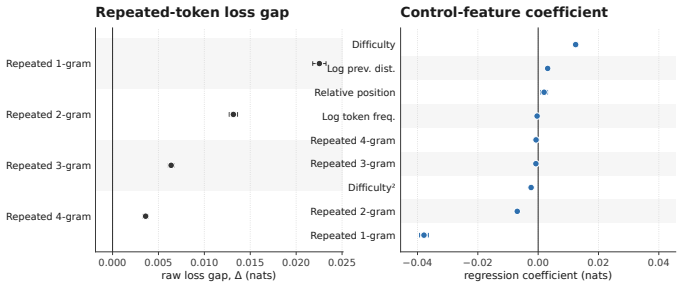
Using the open weights of matched Olmo transformer and Olmo Hybrid models, the authors measure loss at identical target tokens under identical prefixes and stratify results by natural token tags, copy features, delimiter structure, and controlled synthetic probes. The hybrid exhibits lower loss on most tag families, with the largest gains for open-class content words and smaller gains for many closed-class function words. Across prose, code, and markup the hybrid advantage is larger on opening delimiters than on closing delimiters and nearly vanishes on repeated n-grams. Synthetic probes replicate the split: the hybrid is favored on pronoun-memory and entity-tracking tasks, whereas the trans
What carries the argument
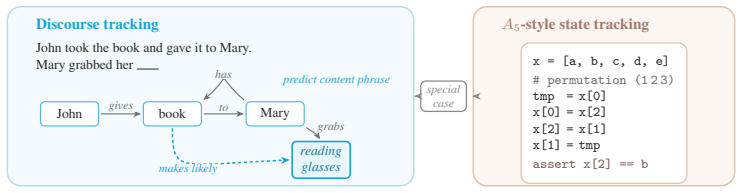
Token-level loss comparison stratified by tag families, delimiter opening versus closing, copy features, and synthetic probes for state tracking versus bracket matching.
If this is right
- Token-level decompositions sharpen pretraining diagnostics by revealing which data types favor each architecture.
- Hybrid models gain most where long-range semantic state must be maintained.
- Pure transformers remain competitive or superior on local syntactic and copying patterns.
- Filtered evaluations on specific token categories can guide architecture selection.
- The non-uniform pattern across delimiters and n-grams suggests targeted use of recurrence rather than uniform replacement of attention.
Where Pith is reading between the lines
- Future designs could route tokens dynamically to recurrent or attention layers based on predicted tag or delimiter type.
- The same stratification method could be applied to larger-scale hybrids to test whether the semantic-versus-syntactic split scales.
- This view raises whether mixed architectures could be trained with loss weighting that emphasizes the token types each component handles best.
- Similar token-level breakdowns might clarify performance gaps in other hybrid variants that combine recurrence with attention.
Load-bearing premise
The transformer and hybrid models are matched closely enough in training data, size, and optimization that observed token-level loss differences can be attributed to the presence of recurrent layers rather than other uncontrolled factors.
What would settle it
Retraining both models from identical random seeds on the exact same data order and observing whether the token-type loss differences remain or disappear.
Figures

read the original abstract
Hybrid language models that mix attention and recurrent layers have shown promise: theoretically, recurrent layers ameliorate the limitations of pure transformers on state tracking, and empirically, hybrids can outperform pure transformers in loss and downstream evaluations \citep{waleffe2024empirical,merrill2026olmohybrid}. Yet it remains unclear which data or capabilities drive these gains, and to what degree they reflect the theoretical advantages motivating hybrid models. We address this question using the open weights from Olmo 3 \citep{olmo2025olmo3} and Olmo Hybrid \citep{merrill2026olmohybrid}: we compare the loss of a matched transformer and hybrid at the same target tokens under the same prefixes, stratifying the results by natural token tags, copy features, delimiter structure, and controlled synthetic probes. The hybrid has lower loss on most tag families, but the gains are not uniform: they are largest for open-class content words and smaller for many closed-class function words. Across prose, code, and markup, the hybrid's loss advantage is larger on opening delimiters than on the corresponding closing delimiters, and nearly vanishes on repeated $n$-grams. Synthetic probes show the same split: the hybrid is favored on pronoun-memory and entity-tracking tasks, whereas the transformer is favored on bracket-matching tasks that require choosing closing delimiters. These patterns suggest that the recurrent layers in hybrids improve predictions that leverage the semantic state of a document, whereas attention helps on tokens predictable by $n$-gram copying or syntactic bracket matching. We conclude with proof-of-concept filtered evaluations showing how token-level decompositions can sharpen pretraining diagnostics for hybrid architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares the token-level cross-entropy loss of a pure transformer (Olmo 3) and a hybrid model (Olmo Hybrid) that interleaves recurrent and attention layers. Using open weights, it stratifies loss differences by token tags, copy features, delimiter structure, and synthetic probes, concluding that recurrent layers aid predictions based on semantic document state while attention aids n-gram copying and syntactic bracket matching.
Significance. If the models are sufficiently matched, this work offers a detailed empirical map of architectural strengths at the token level, directly testing theoretical claims about state tracking in hybrids versus transformers. It could inform future hybrid designs and pretraining diagnostics.
major comments (2)
- Abstract: The central attribution of loss differences to recurrent layers versus attention requires that the Olmo transformer and Olmo Hybrid differ only in layer type. The abstract states the models are 'matched,' but without explicit confirmation of identical parameter counts, training data, optimizer schedules, and initialization, alternative explanations for the observed patterns in tag families, delimiters, and probes cannot be ruled out.
- Abstract: The manuscript reports loss differences across strata but does not mention error bars, variance estimates, or statistical tests. This makes it difficult to determine whether the reported advantages (e.g., larger gains on opening delimiters or pronoun-memory tasks) are statistically reliable.
minor comments (1)
- Abstract: The citation for Olmo Hybrid is given as merrill2026olmohybrid; ensure the year and arXiv details are accurate in the reference list.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on model matching and statistical reporting. We address both points below and will revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: Abstract: The central attribution of loss differences to recurrent layers versus attention requires that the Olmo transformer and Olmo Hybrid differ only in layer type. The abstract states the models are 'matched,' but without explicit confirmation of identical parameter counts, training data, optimizer schedules, and initialization, alternative explanations for the observed patterns in tag families, delimiters, and probes cannot be ruled out.
Authors: The Olmo 3 transformer and Olmo Hybrid models were released as matched configurations (same parameter count, training corpus, optimizer, and schedule) except for the substitution of recurrent layers for some attention layers, as documented in their source papers. We will revise the abstract and add an explicit methods paragraph confirming these details from the original releases to rule out alternative explanations and make the attribution to layer type fully transparent. revision: yes
-
Referee: Abstract: The manuscript reports loss differences across strata but does not mention error bars, variance estimates, or statistical tests. This makes it difficult to determine whether the reported advantages (e.g., larger gains on opening delimiters or pronoun-memory tasks) are statistically reliable.
Authors: We agree that variance estimates and statistical tests would improve interpretability. In revision we will report standard errors computed over document segments or multiple evaluation shards for the stratified losses, and add brief statistical comparisons (e.g., paired t-tests or bootstrap intervals) for the key reported advantages such as opening vs. closing delimiters and the synthetic probes. revision: yes
Circularity Check
No circularity: purely empirical model comparison
full rationale
The paper conducts a direct empirical comparison of token-level losses between two open-weight models (Olmo transformer and Olmo Hybrid) stratified by tags, copy features, delimiters, and synthetic probes. No equations, derivations, or predictions are present that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The central claims rest on observable loss differences from existing models rather than any internal fitting or uniqueness theorem imported from the authors' prior work. Self-citations to model sources are factual references to released weights, not load-bearing justifications for the results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zoology: Measuring and improving recall in efficient language models
Simran Arora, Sabri Eyuboglu, Aman Timalsina, Isys Johnson, Michael Poli, James Zou, Atri Rudra, and Christopher Ré. Zoology: Measuring and improving recall in efficient language models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[2]
Transformers in uniform TC 0.Trans
David Chiang. Transformers in uniform TC 0.Trans. Mach. Learn. Res., 2025,
2025
-
[3]
Riccardo Grazzi, Julien Siems, Arber Zela, Jörg K. H. Franke, Frank Hutter, and Massimiliano Pontil. Unlocking state-tracking in linear rnns through negative eigenvalues. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[4]
Kakade, and Eran Malach
Samy Jelassi, David Brandfonbrener, Sham M. Kakade, and Eran Malach. Repeat after me: Trans- formers are better than state space models at copying. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Forty-first International Conference on Machine Learning, ICML 2024, Vi...
2024
-
[5]
URL https: //aclanthology.org/2022.tacl-1.66/
doi: 10.1162/TACL\_A\ _00562. URLhttps://doi.org/10.1162/tacl_a_00562. William Merrill, Jackson Petty, and Ashish Sabharwal. The illusion of state in state-space models. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Le...
work page internal anchor Pith review doi:10.1162/tacl 2024
-
[6]
URLhttps://arxiv.org/abs/2604.03444. Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznan- ski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Sa...
-
[7]
URLhttps://arxiv.org/abs/2512.13961. Bo Peng, Ruichong Zhang, Daniel Goldstein, Eric Alcaide, Xingjian Du, Haowen Hou, Jiaju Lin, Jiaxing Liu, Janna Lu, William Merrill, Guangyu Song, Kaifeng Tan, Saiteja Utpala, Nathan Wilce, Johan S. Wind, Tianyi Wu, Daniel Wuttke, and Christian Zhou-Zheng. RWKV-7 "goose" with expressive dynamic state evolution.CoRR, ab...
-
[9]
URL https: //openreview.net/forum?id=RDbuSCWhad. Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, and Bryan Catanzaro. An empirical study of mamba-based language models.CoRR, abs...
-
[10]
An Empirical Study of Mamba-based Language Models
doi: 10.48550/ARXIV .2406.07887. URLhttps://doi.org/10.48550/arXiv.2406.07887. Gail Weiss, Yoav Goldberg, and Eran Yahav. Thinking like transformers,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[11]
URL https: //arxiv.org/abs/2106.06981. Songlin Yang, Yikang Shen, Kaiyue Wen, Shawn Tan, Mayank Mishra, Liliang Ren, Rameswar Panda, and Yoon Kim. PaTH attention: Position encoding via accumulating householder transformations. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[12]
main" Textcontent,entityfree-form page text Commentcomment <!– ... –> Punctuationangle_open,angle_close, slash,quote <,>,/,
URL https://arxiv.org/abs/2105. 11115. 14 A Empirical methodology details A.1 Domains, packing, and pairing protocol We evaluate both models on the same evaluation sequences and compute NLL at every position. Text is packed into contiguous sequences of length T= 8192 . Allcomparisons arepairedat the level of a single next-token decision:same checkpoint, s...
1979
-
[13]
The sign convention is the same as in the main text
The raw gaps ask whether the hybrid has lower NLL on a subset in absolute terms; the coefficients ask how each feature shifts the paired hybrid–transformer gap after controlling for domain, tag, word position, sequence position, difficulty, previous-token distance, and target-token frequency. The sign convention is the same as in the main text. Positive r...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.