Investigation into In-Context Learning Capabilities of Transformers
Pith reviewed 2026-05-20 23:41 UTC · model grok-4.3
The pith
Transformers succeed at in-context binary classification when input dimension, signal strength, and contextual information satisfy specific geometric thresholds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
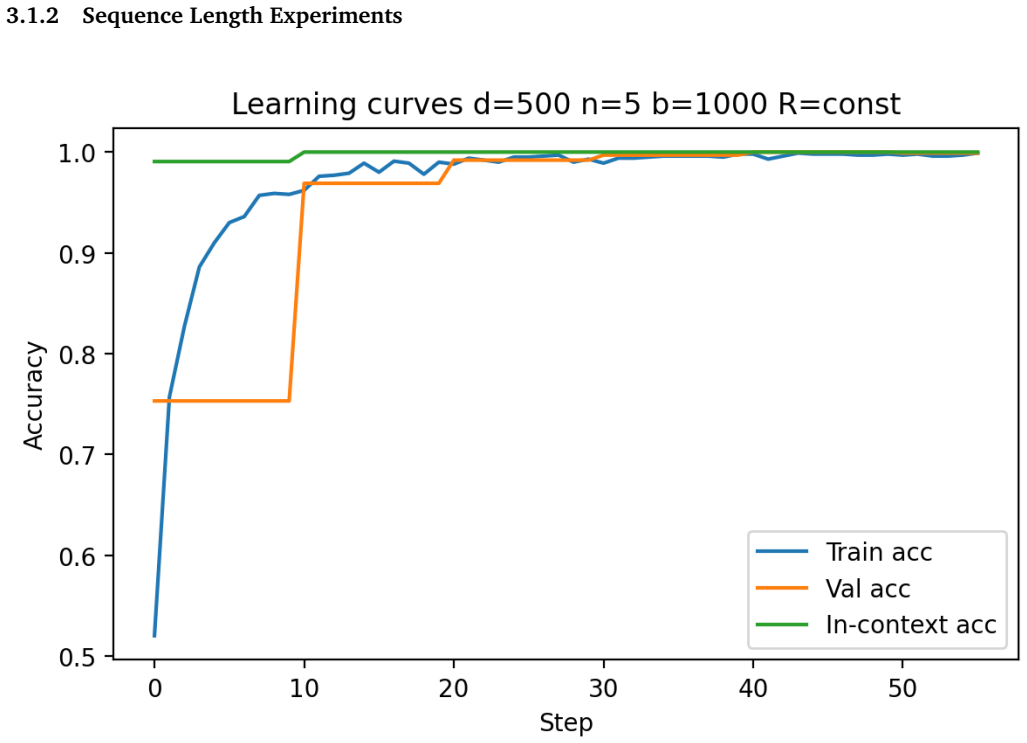
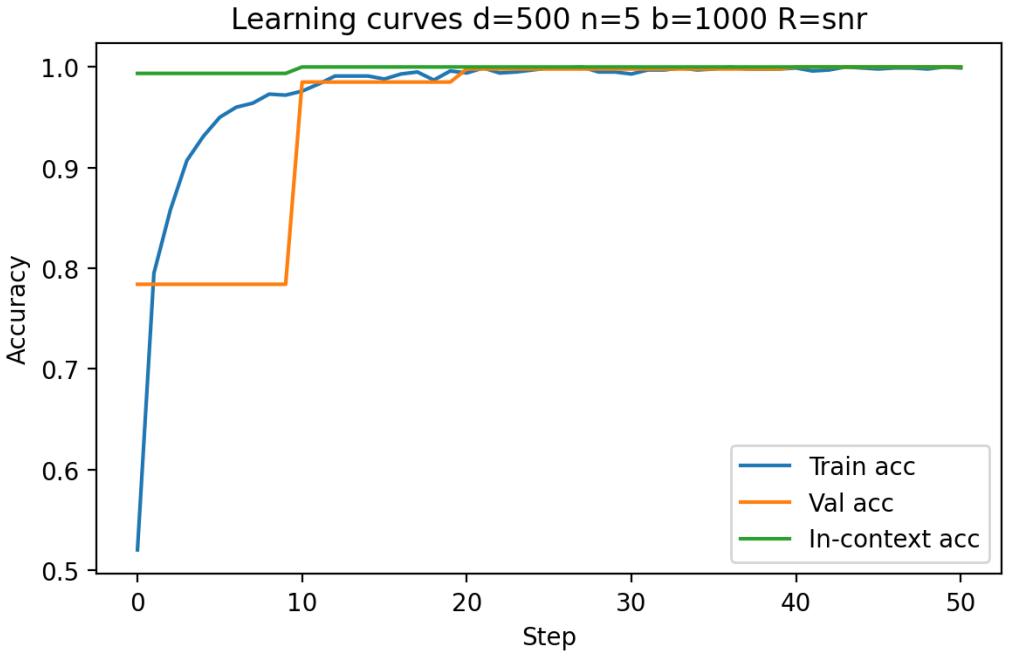
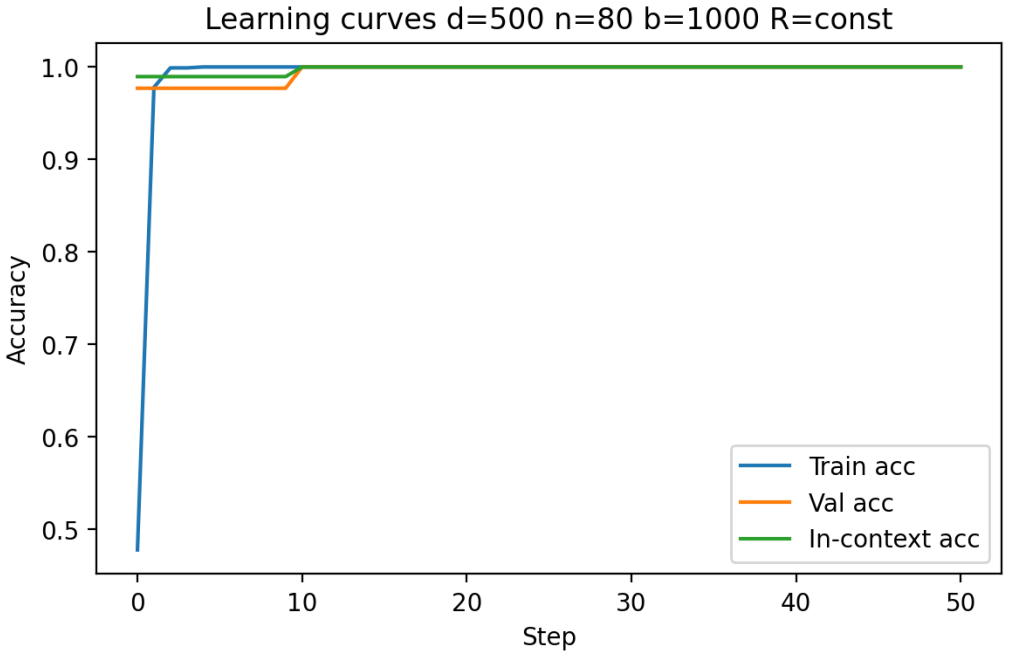
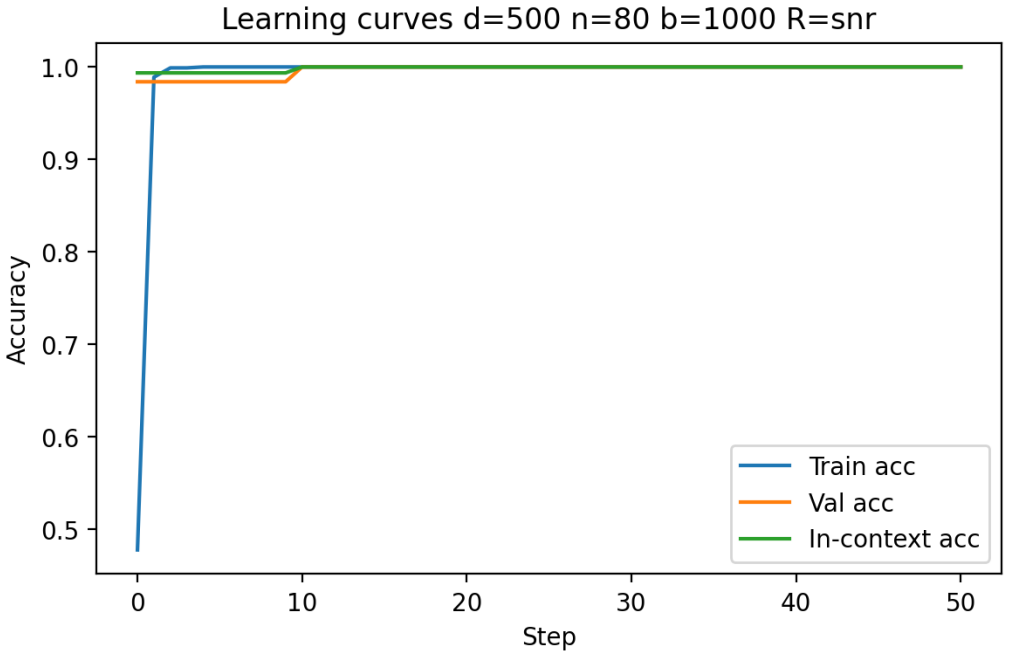
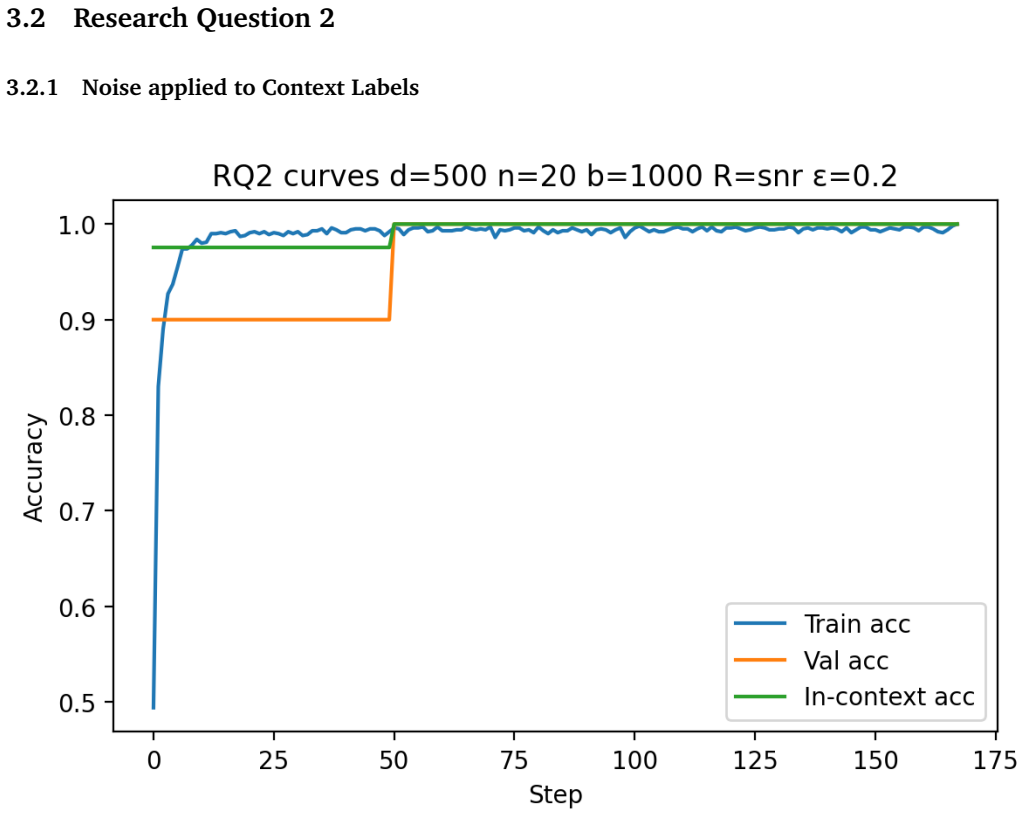
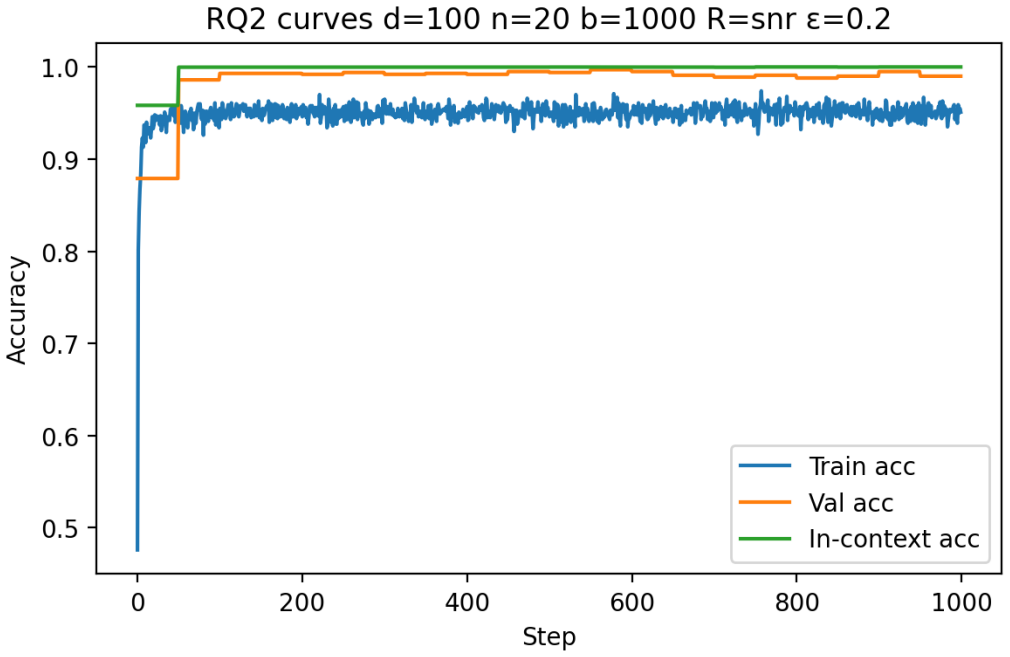
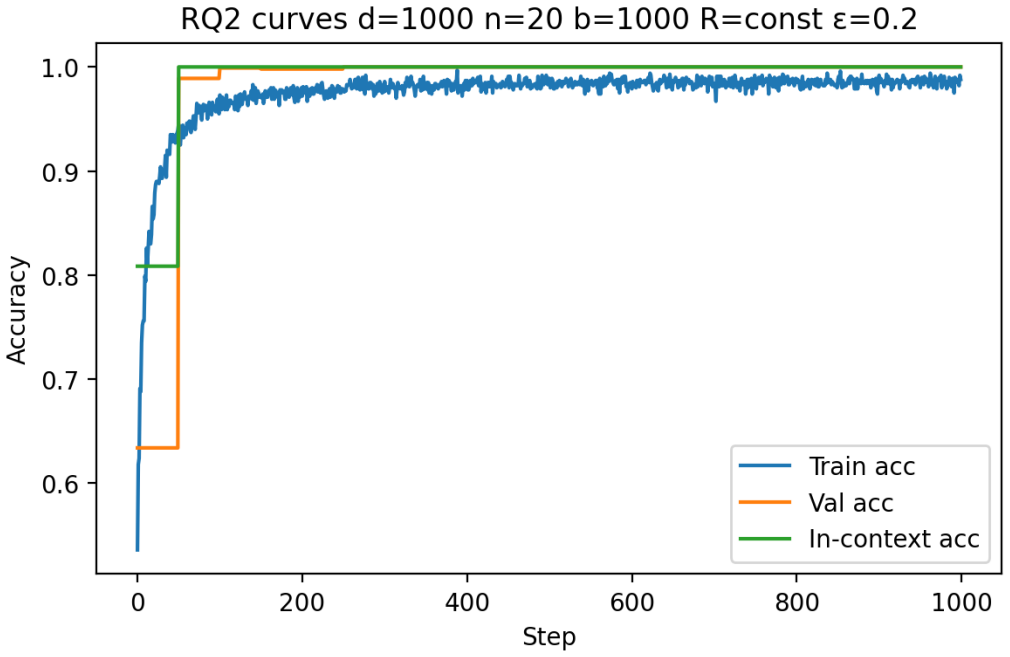
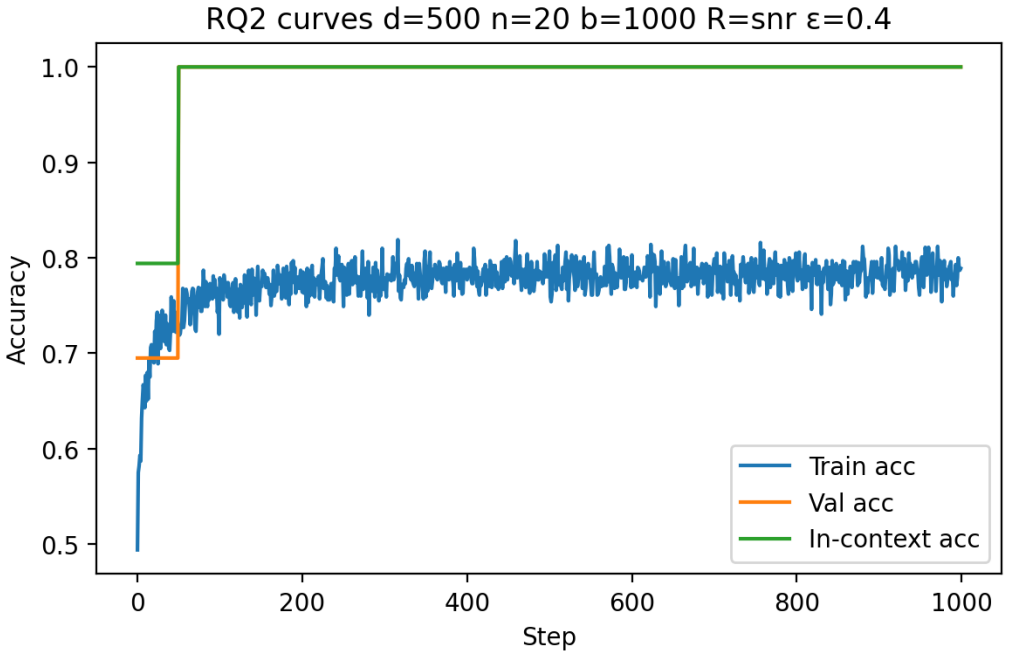
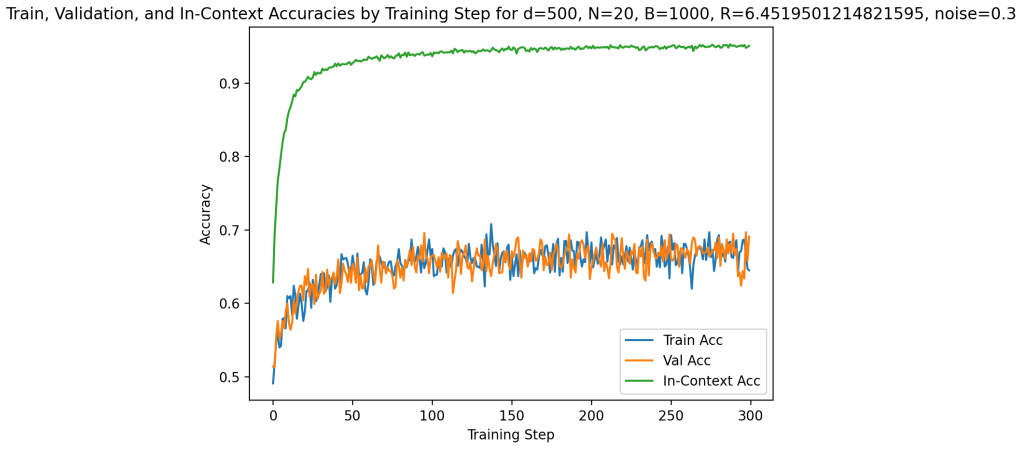
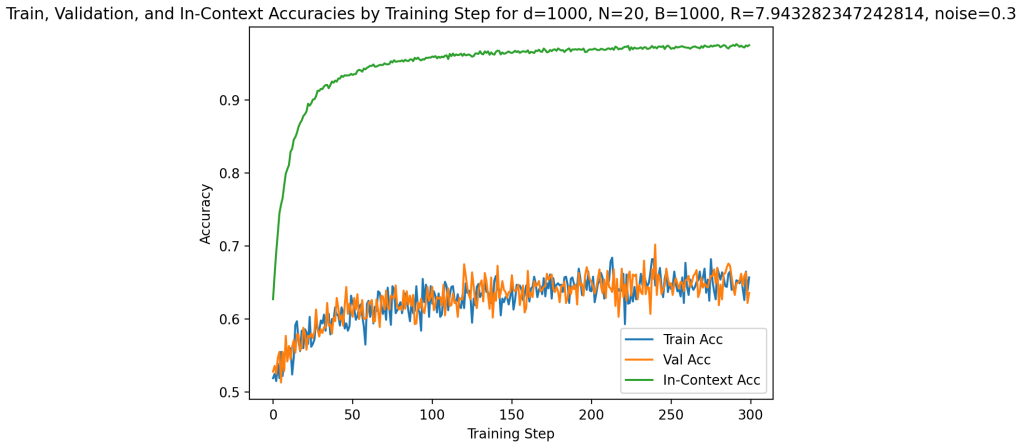
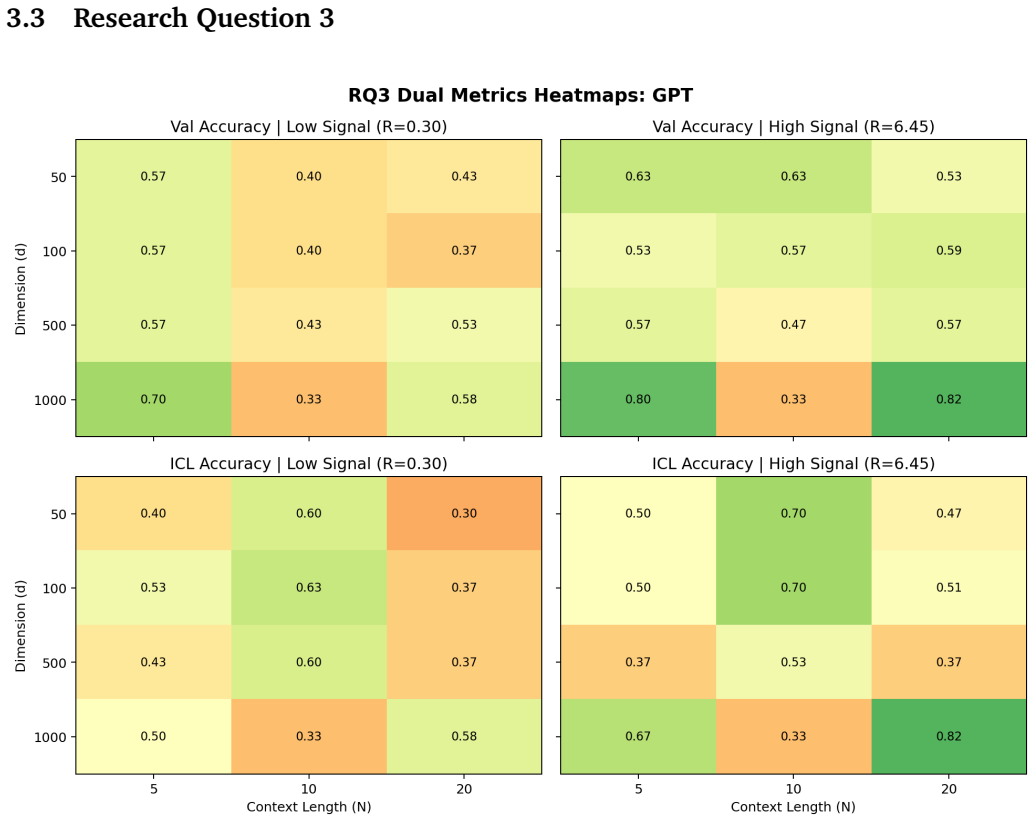
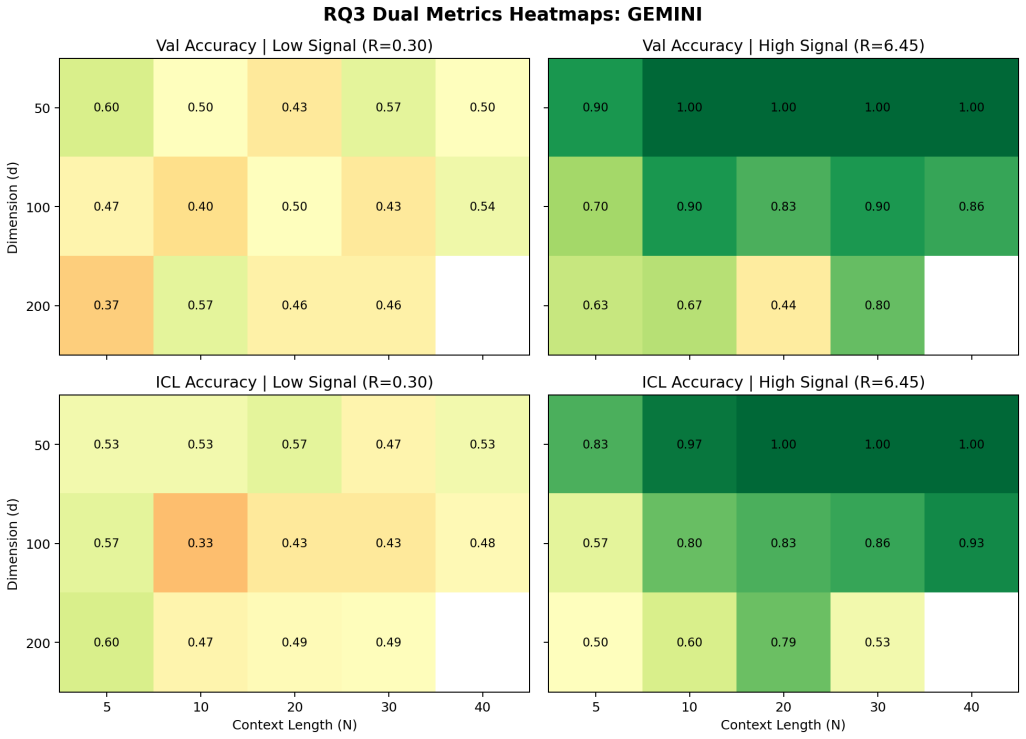
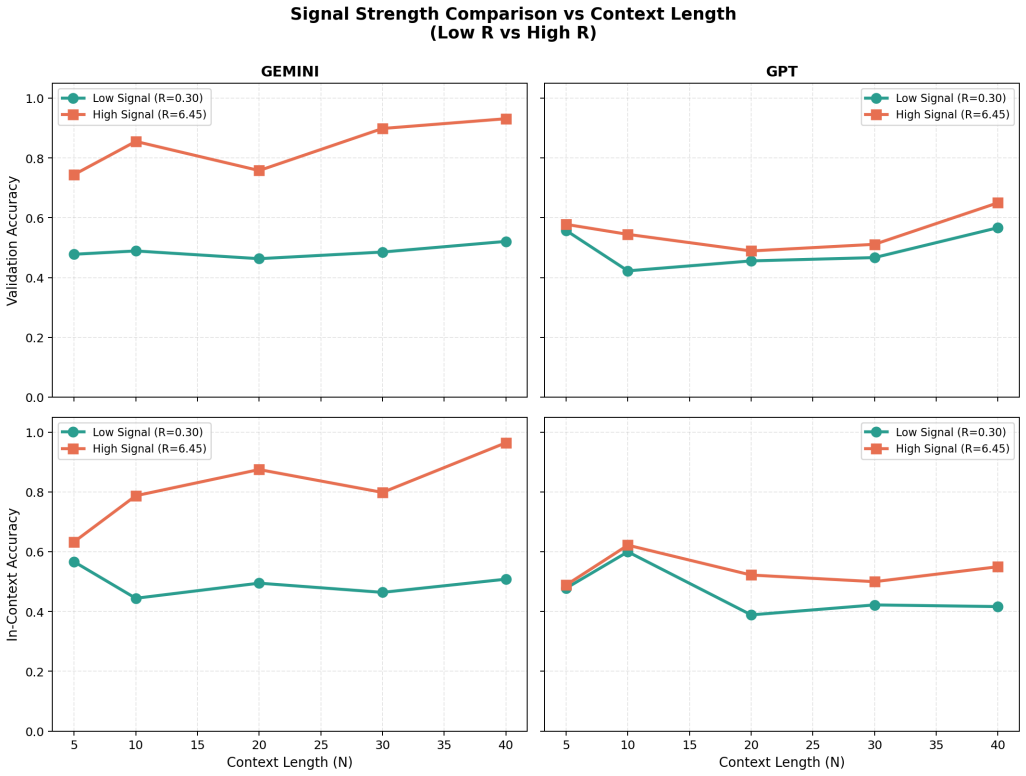
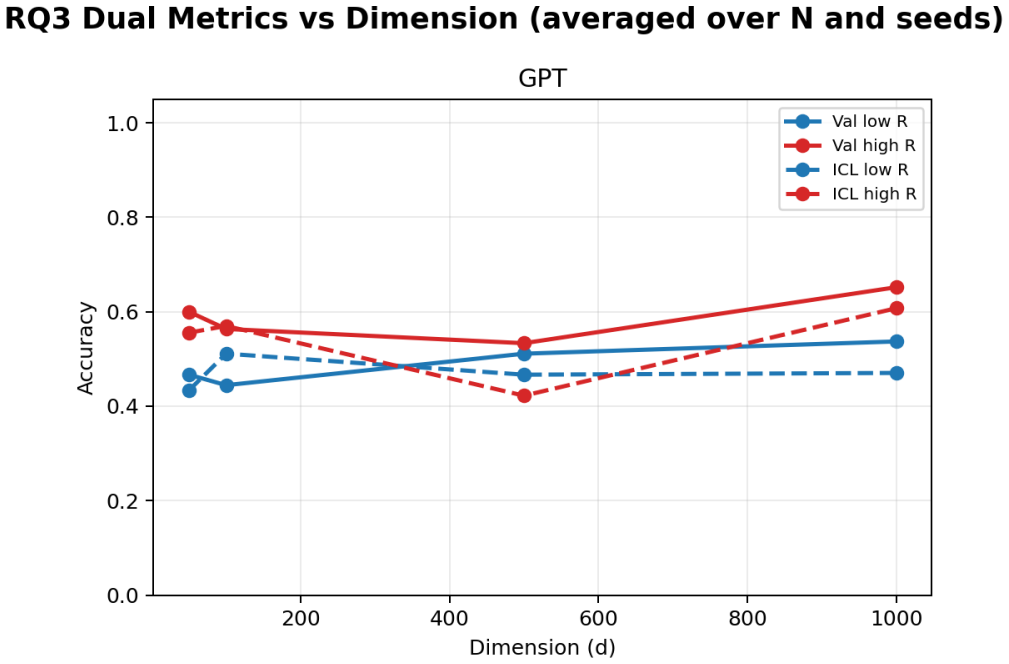
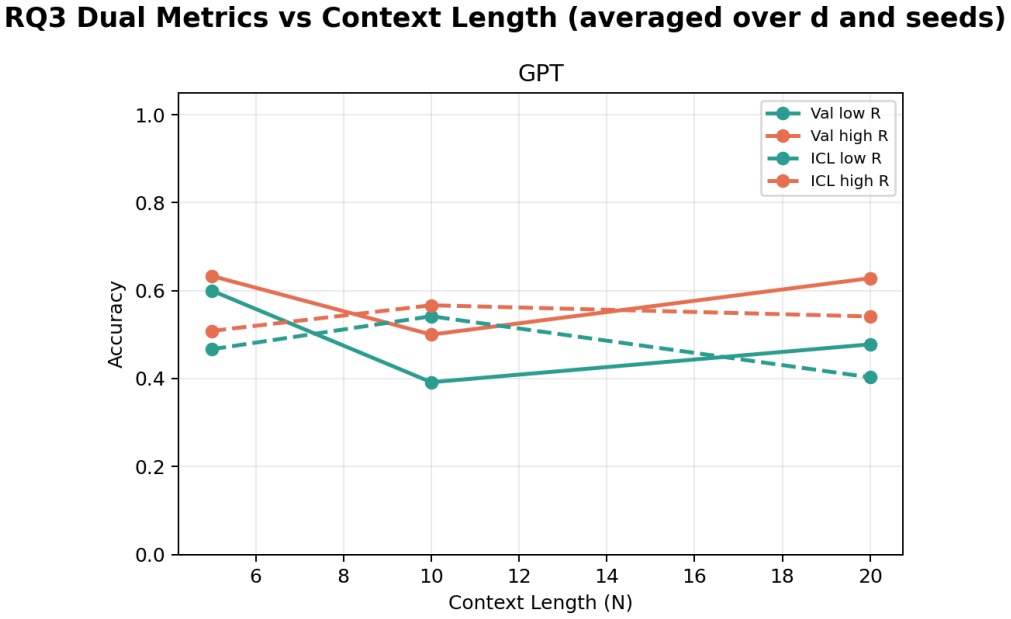
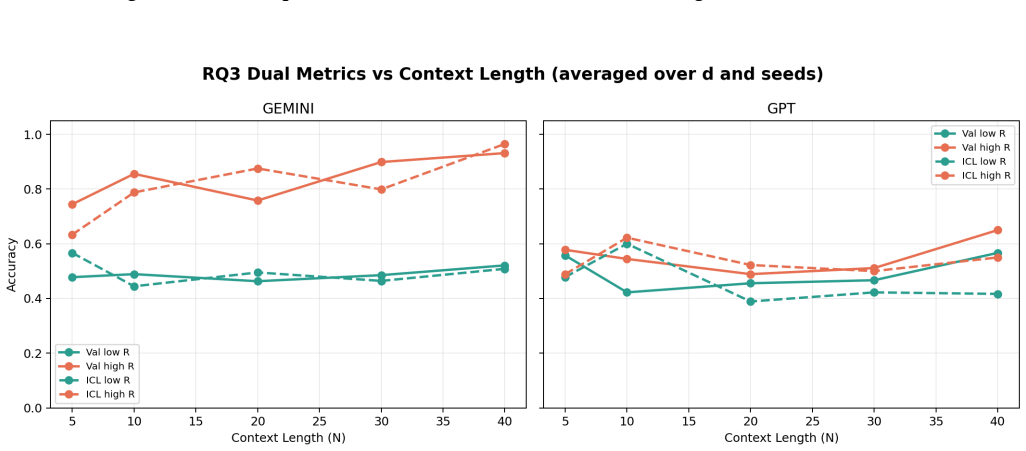
Building on the linear in-context classifier framework, the authors demonstrate through systematic sweeps that in-context test accuracy for Gaussian-mixture classification is governed by the interplay of dimensionality, signal-to-noise ratio, and the volume of contextual information, producing a detailed map of parameter regions where transformers successfully extract and apply task structure from examples at inference time.
What carries the argument
Linear in-context classifier formulation inside a controlled synthetic Gaussian-mixture data setup that isolates the geometric conditions for inferring task structure from context alone.
If this is right
- In-context accuracy rises with more examples only up to a limit set by the input dimension relative to signal strength.
- Benign overfitting appears reliably in intermediate signal-to-noise and dimensionality ranges, preserving generalization on clean data despite noisy in-context labels.
- Greater diversity of pre-training tasks expands the region where context alone suffices to recover the underlying classification rule.
- Failure occurs predictably when dimensionality grows faster than the available signal or contextual information.
Where Pith is reading between the lines
- If these scaling patterns transfer to natural data, practitioners could estimate required context length from simple dimension and signal measurements before deployment.
- The same geometric view might explain why in-context learning sometimes emerges suddenly with scale in other sequence modeling settings.
- Testing the map on nonlinear or multi-class variants of the mixture model would show whether the linear approximation is the main driver or merely a convenient proxy.
Load-bearing premise
A linear classifier applied to the synthetic Gaussian-mixture examples is sufficient to reveal the actual conditions under which transformers perform in-context learning.
What would settle it
Running the same Gaussian-mixture tasks on actual transformer models and finding that test accuracy scales differently from the reported map once dimensionality exceeds the number of in-context examples by a large margin.
Figures
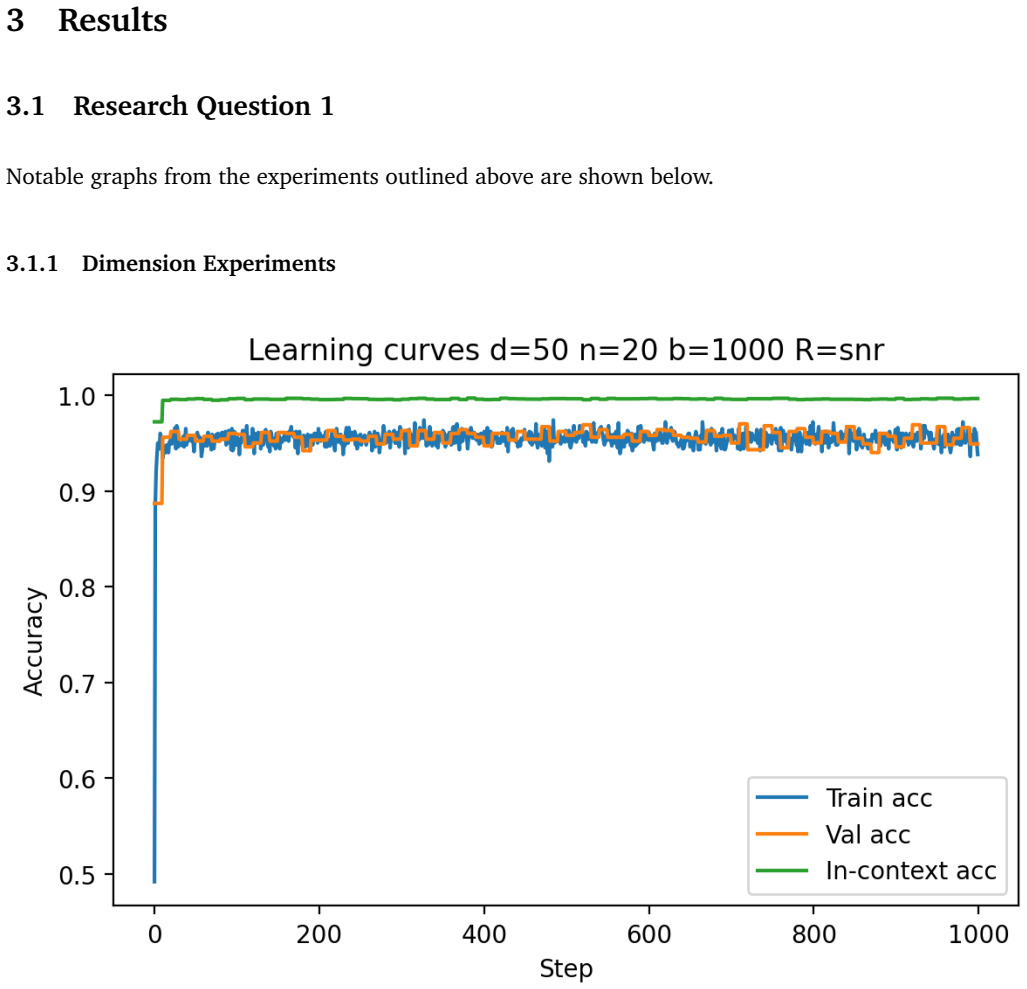
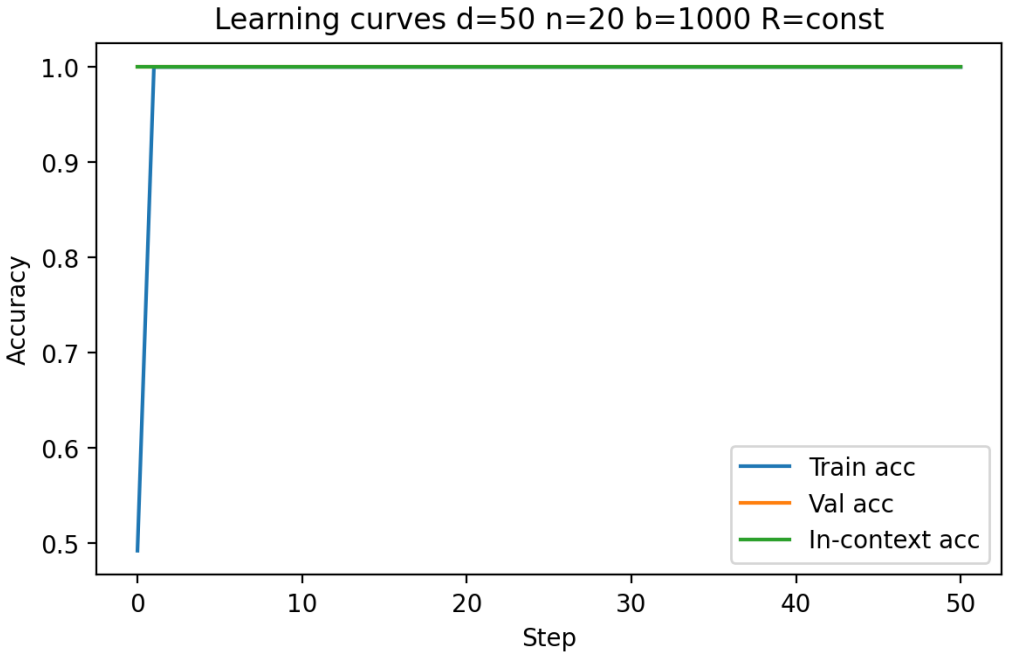
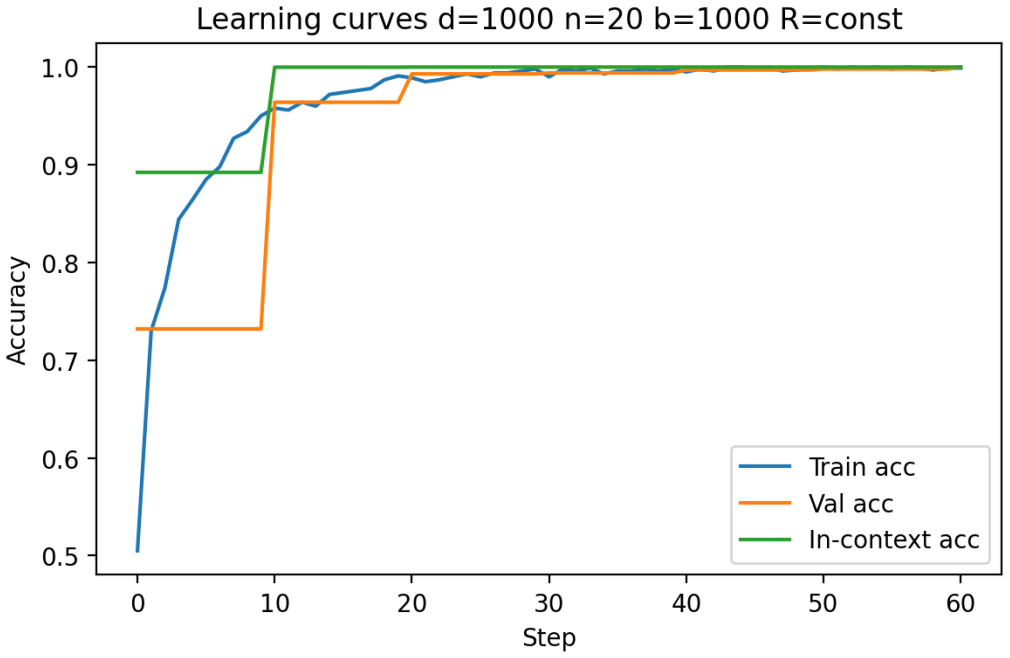
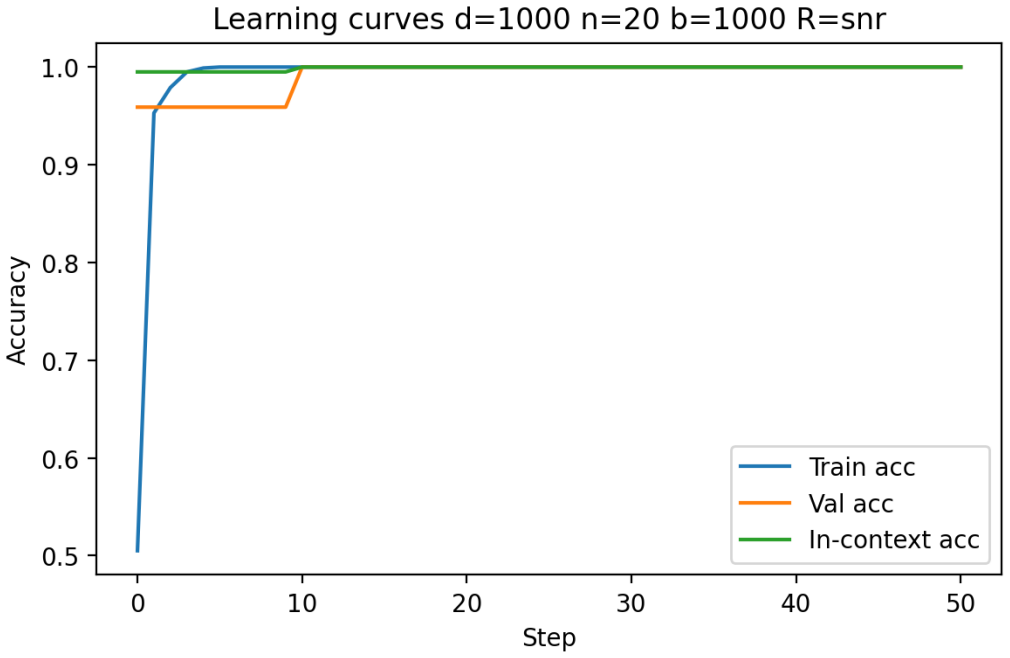
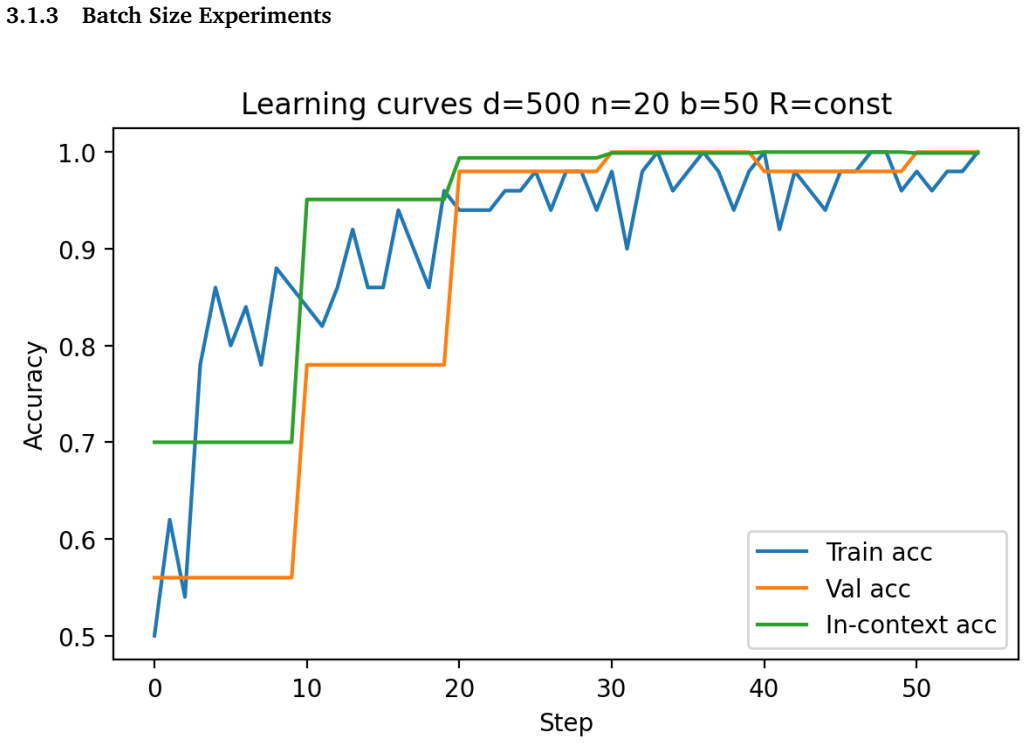
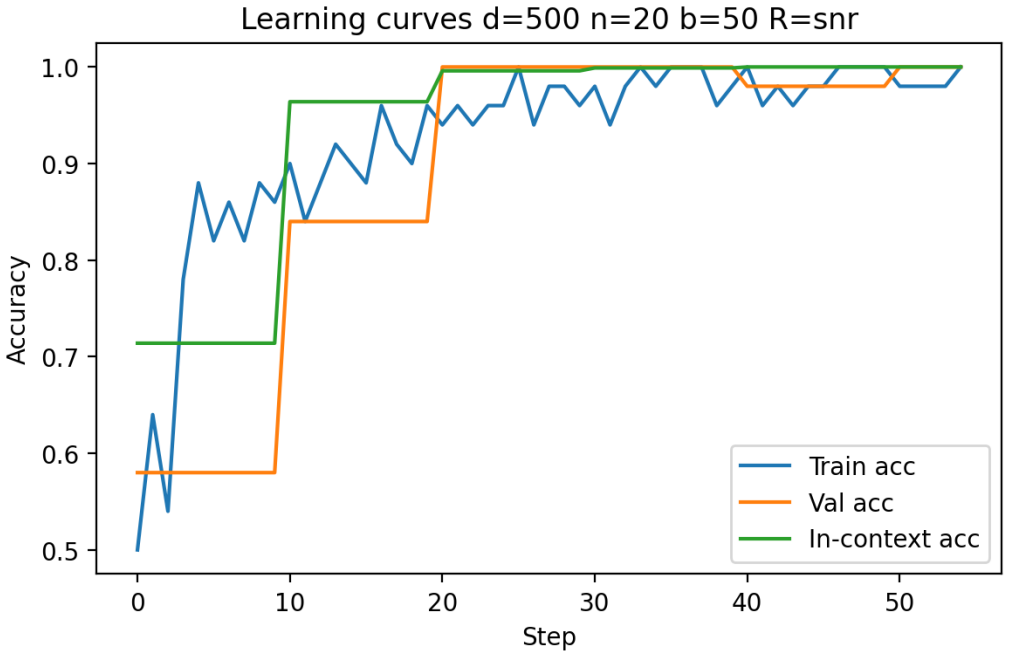
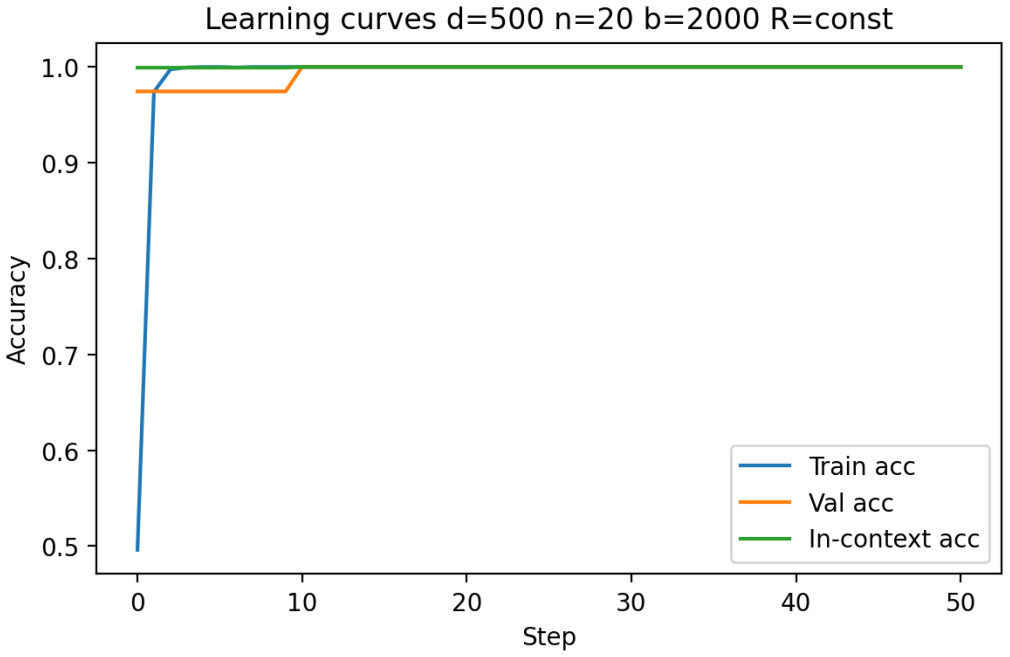
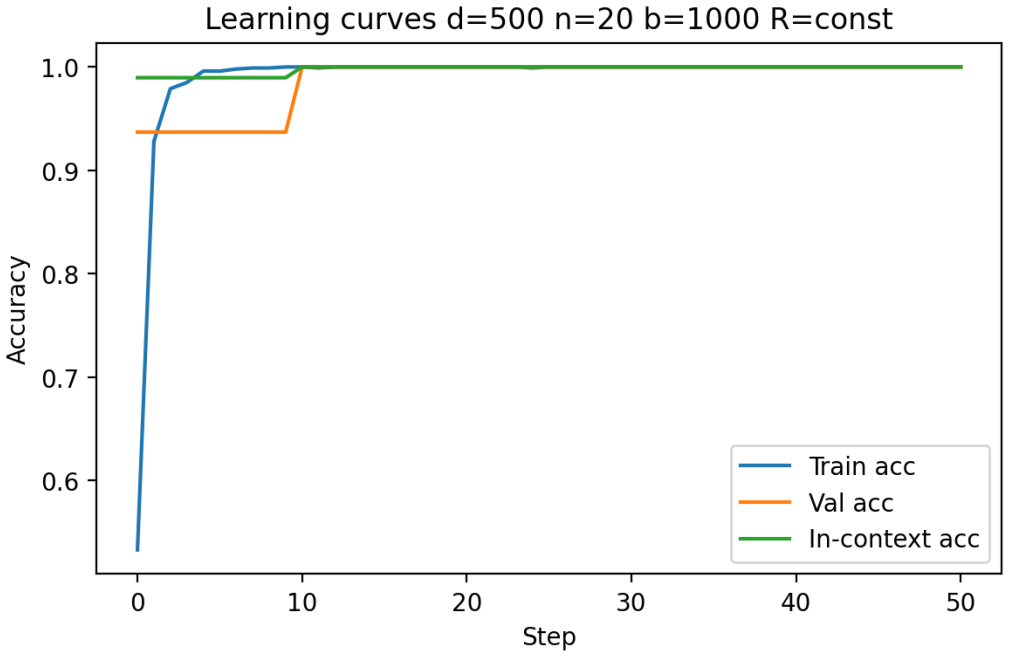
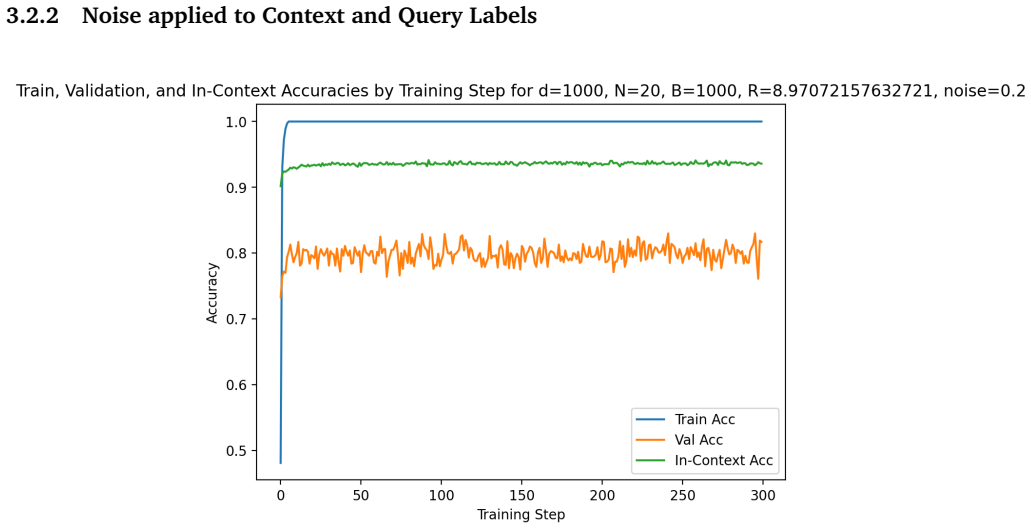
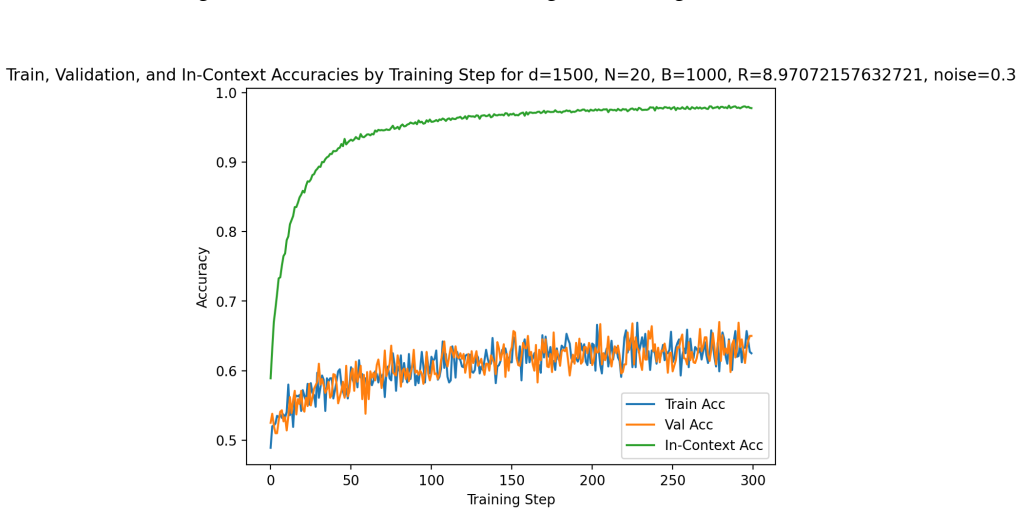
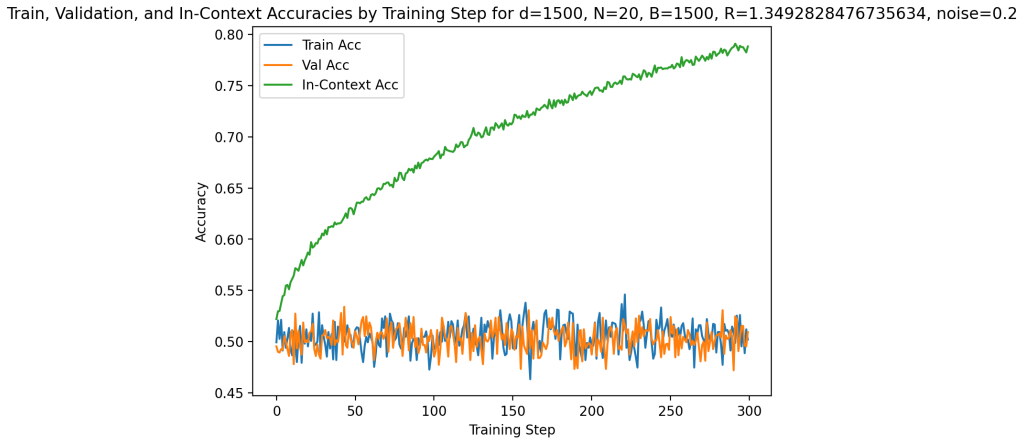
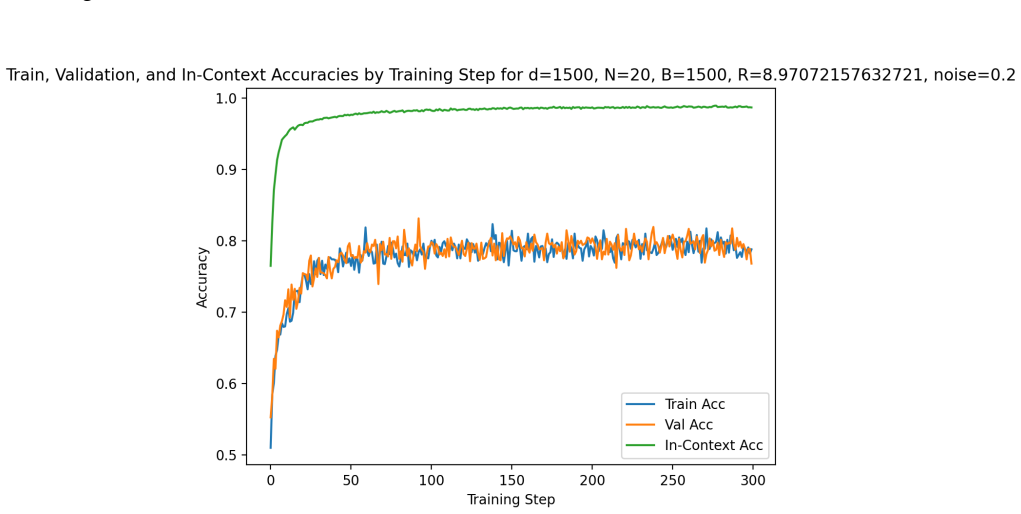
read the original abstract
Transformers have demonstrated a strong ability for in-context learning (ICL), enabling models to solve previously unseen tasks using only example input output pairs provided at inference time. While prior theoretical work has established conditions under which transformers can perform linear classification in-context, the empirical scaling behavior governing when this mechanism succeeds remains insufficiently characterized. In this paper, we conduct a systematic empirical study of in-context learning for Gaussian-mixture binary classification tasks. Building on the theoretical framework of Frei and Vardi (2024), we analyze how in-context test accuracy depends on three fundamental factors: the input dimension, the number of in-context examples, and the number of pre-training tasks. Using a controlled synthetic setup and a linear in-context classifier formulation, we isolate the geometric conditions under which models successfully infer task structure from context alone. We additionally investigate the emergence of benign overfitting, where models memorize noisy in-context labels while still achieving strong generalization performance on clean test data. Through extensive sweeps across dimensionality, sequence length, task diversity, and signal-to-noise regimes, we identify the parameter regions in which this phenomenon arises and characterize how it depends on data geometry and training exposure. Our results provide a comprehensive empirical map of scaling behavior in in-context classification, highlighting the critical role of dimensionality, signal strength, and contextual information in determining when in-context learning succeeds and when it fails.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic empirical study of in-context learning for Gaussian-mixture binary classification tasks in transformers. Building on prior theoretical work, it examines how in-context test accuracy scales with input dimension, number of in-context examples, and number of pre-training tasks. Using a controlled synthetic setup and a linear in-context classifier formulation, the authors isolate geometric conditions for successful task inference from context and characterize regimes of benign overfitting across sweeps of dimensionality, sequence length, task diversity, and signal-to-noise.
Significance. If the linear in-context classifier formulation accurately reflects transformer behavior, the work delivers a valuable empirical map of ICL scaling in classification, clarifying the roles of dimensionality, signal strength, and contextual information. The extensive parameter sweeps and focus on benign overfitting provide concrete guidance for when ICL succeeds or fails, which could inform both theory and model design.
major comments (1)
- [Abstract] Abstract and linear in-context classifier formulation: the central claims about transformer ICL scaling and benign-overfitting regions rest on using a linear proxy to isolate geometric conditions. Transformers implement nonlinear functions via attention and feed-forward layers, so the proxy may diverge from actual decision boundaries in high-dimensional or low-signal regimes. Direct validation (e.g., comparison of linear vs. transformer outputs on held-out contexts) is needed to confirm the reported maps characterize the models studied rather than only the surrogate.
minor comments (2)
- [Experimental Setup] The description of experimental details (data exclusion rules, exact training procedure, and number of runs) is insufficient to assess reproducibility; adding these would strengthen the manuscript.
- [Figures] Figures reporting accuracy vs. dimension or sequence length should include error bars or shaded regions indicating variability across random seeds.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address the major comment on the linear in-context classifier formulation below.
read point-by-point responses
-
Referee: [Abstract] Abstract and linear in-context classifier formulation: the central claims about transformer ICL scaling and benign-overfitting regions rest on using a linear proxy to isolate geometric conditions. Transformers implement nonlinear functions via attention and feed-forward layers, so the proxy may diverge from actual decision boundaries in high-dimensional or low-signal regimes. Direct validation (e.g., comparison of linear vs. transformer outputs on held-out contexts) is needed to confirm the reported maps characterize the models studied rather than only the surrogate.
Authors: We appreciate the referee's observation that transformers can implement nonlinear functions. The linear in-context classifier is not an arbitrary proxy but is directly motivated by the analysis in Frei and Vardi (2024), which establishes that, for the Gaussian-mixture tasks considered here, the attention mechanism in transformers realizes a linear classifier whose weights are inferred from the in-context examples. Our empirical study therefore maps scaling and benign-overfitting regimes inside the setting where this equivalence holds, allowing us to isolate geometric effects of dimension, context length, and task diversity. We agree that explicit validation would strengthen the link to full transformer behavior. In the revised manuscript we will add a dedicated subsection that compares the linear classifier outputs against the actual transformer predictions on held-out contexts, reporting agreement rates and selected decision-boundary visualizations across representative high-dimensional and low-signal regimes. revision: yes
Circularity Check
No significant circularity in this empirical study
full rationale
The paper is a systematic empirical investigation of transformer in-context learning on synthetic Gaussian-mixture tasks, relying on experimental sweeps over dimensionality, sequence length, task diversity, and signal-to-noise regimes rather than any mathematical derivation chain. It builds on the external theoretical framework of Frei and Vardi (2024) without self-citation load-bearing or imported uniqueness theorems from the present authors. The linear in-context classifier formulation is explicitly part of the controlled synthetic setup to isolate geometric conditions and does not reduce any reported prediction or scaling map to fitted inputs by construction; all central claims rest on observed empirical outcomes that remain falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Trained Transformer Classifiers Generalize and Exhibit Benign Overfitting In-Context
Frei, Spencer, and Gal Vardi.2024. “Trained Transformer Classifiers Generalize and Exhibit Benign Overfitting In-Context.”[Link]
work page 2024
-
[2]
What Can Trans- formers Learn In-Context? A Case Study of Simple Function Classes
Garg, Shivam, Dimitris Tsipras, Percy Liang, and Gregory Valiant.2023. “What Can Trans- formers Learn In-Context? A Case Study of Simple Function Classes.”[Link] 40
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.