UA-ChatDev: Uncertainty-Aware Multi-Agent Collaboration for Reliable Software Development
Pith reviewed 2026-07-03 13:59 UTC · model grok-4.3
The pith
Integrating uncertainty estimates from token probabilities into multi-agent software development reduces error spread and improves final code quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
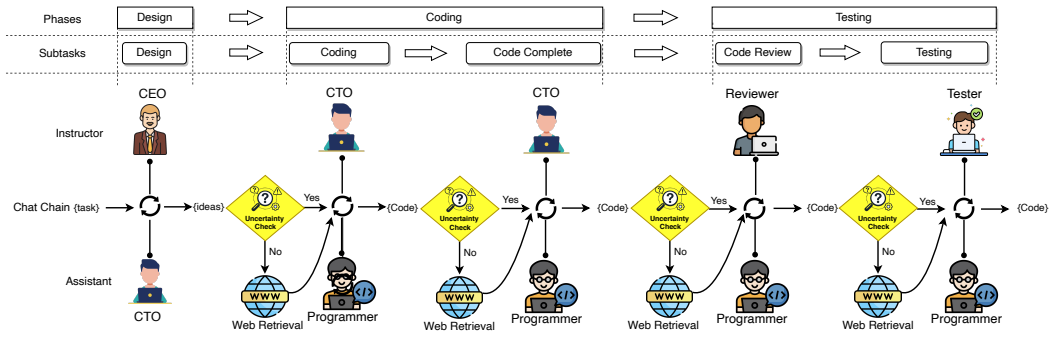
The central claim is that an uncertainty-aware multi-agent software development framework which assesses agent response confidence via token-level log probabilities and uses phase-aware thresholds to trigger retrieval-based verification when uncertainty is high consistently produces higher quality software than standard multi-agent or single-agent methods by reducing the propagation of incorrect decisions.
What carries the argument
Token-level log probability uncertainty estimator paired with phase-aware threshold calibration that selectively activates retrieval-based verification on high-uncertainty steps.
If this is right
- Development phases produce more complete and executable code because doubtful steps receive extra checks.
- Consistency across the full project rises since early mistakes are less likely to reach final code.
- Overall quality improves as the system avoids compounding hallucinations from one agent to the next.
- Agent interactions become more reliable when uncertainty levels guide when verification occurs.
Where Pith is reading between the lines
- The same probability-based signal could be tested in other multi-step agent workflows such as automated planning or data analysis.
- Phase-specific thresholds imply that a single fixed cutoff may be insufficient, suggesting experiments with learned or adaptive thresholds.
- If token probabilities track correctness here, they might also flag when an agent should consult external knowledge sources in unrelated tasks.
Load-bearing premise
Token probabilities assigned during generation serve as a reliable indicator of whether an agent's output is actually correct.
What would settle it
An experiment in which high-uncertainty outputs turn out to be correct more often than low-uncertainty ones and the full framework shows no measurable gain in completeness or executability over a non-uncertainty baseline.
Figures
read the original abstract
Software development is a complex task that demands cooperation among agents with diverse roles. Large language models (LLMs) have enabled autonomous multi-agent software development frameworks that leverage role-based collaboration to automate requirements analysis, coding, testing, and refinement. However, existing approaches typically assume that intermediate agent outputs are equally reliable, leaving them vulnerable to hallucination propagation, where incorrect decisions generated in early development phases are transferred to downstream agents and negatively impact final software quality. To address this challenge, we propose UA-ChatDev, an uncertainty-aware multi-agent software development framework that integrates uncertainty quantification into agent interactions. It introduces a lightweight uncertainty estimation mechanism based on token-level log probabilities to assess the confidence of agent responses and employs phase-aware threshold calibration to selectively trigger retrieval-based verification when uncertainty exceeds acceptable levels. Extensive experiments on the SRDD benchmark demonstrate that UA-ChatDev consistently outperforms existing single-agent and multi-agent software development frameworks across completeness, executability, consistency, and overall quality metrics. Further ablation studies and communication analyses verify that uncertainty-aware interactions enhance code execution reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UA-ChatDev, an uncertainty-aware multi-agent framework for software development. It integrates token-level log-probability uncertainty estimation with phase-aware threshold calibration to selectively trigger retrieval-based verification, aiming to prevent hallucination propagation from early-phase errors. Experiments on the SRDD benchmark are claimed to show consistent gains over single- and multi-agent baselines on completeness, executability, consistency, and overall quality, with ablations and communication analyses supporting the value of uncertainty-aware interactions.
Significance. If the empirical gains are reproducible and the log-probability proxy is shown to be well-calibrated, the approach could meaningfully improve reliability in LLM-driven multi-agent coding pipelines by making verification decisions data-driven rather than uniform. The work directly targets a recognized failure mode (error propagation) in existing role-based frameworks and supplies an inexpensive uncertainty signal, which is a practical contribution if validated.
major comments (2)
- [Abstract] Abstract: the central claim of consistent outperformance on SRDD is stated without any numerical results, baseline names, effect sizes, or statistical tests. This absence makes the primary empirical contribution impossible to evaluate from the provided text.
- [Abstract] Abstract (uncertainty mechanism): the decision to invoke verification rests on the assumption that token-level log probabilities (with phase-aware calibration) reliably flag incorrect intermediate outputs more often than correct ones. No correlation analysis, calibration plots, or proxy-validation experiment against ground-truth correctness is described, which is load-bearing for attributing any measured gains to uncertainty awareness rather than to the verification step itself.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the validation of the uncertainty mechanism. We address each major comment below and will revise the manuscript accordingly to improve clarity and strengthen the empirical presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of consistent outperformance on SRDD is stated without any numerical results, baseline names, effect sizes, or statistical tests. This absence makes the primary empirical contribution impossible to evaluate from the provided text.
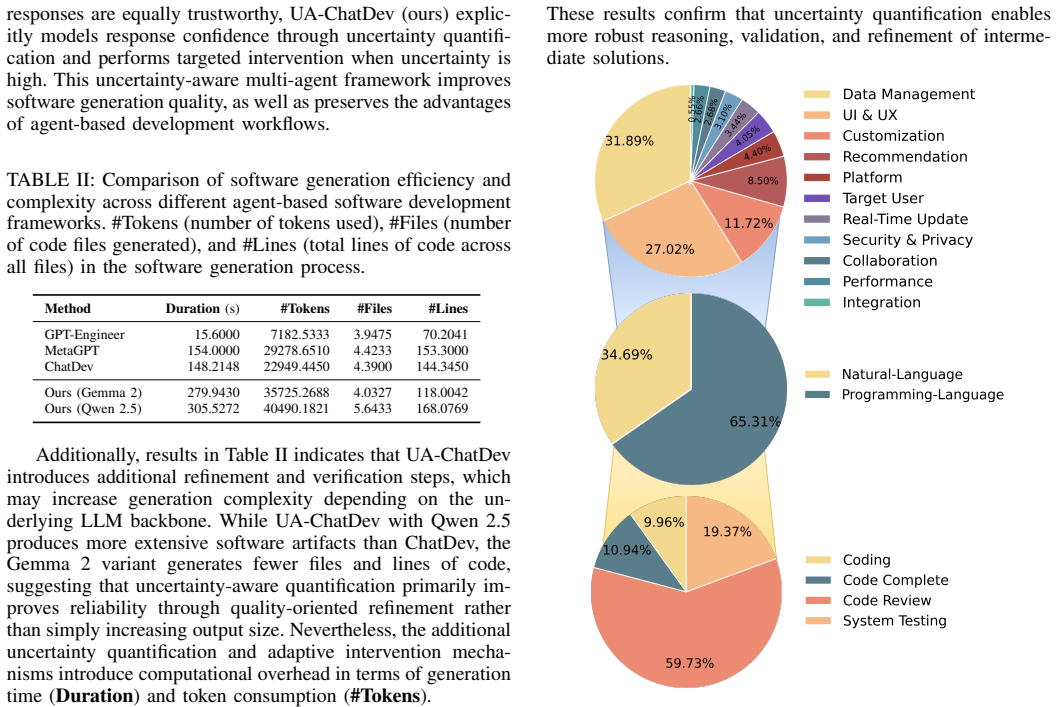
Authors: We agree that the abstract would be strengthened by including concrete quantitative results. In the revised version, we will incorporate specific metrics from the SRDD experiments, such as the overall quality score improvements (e.g., +X% over ChatDev and +Y% over MetaGPT), along with baseline names and effect sizes. The full paper already contains detailed tables with these values; we will ensure the abstract provides a concise summary of the key gains to allow immediate evaluation. revision: yes
-
Referee: [Abstract] Abstract (uncertainty mechanism): the decision to invoke verification rests on the assumption that token-level log probabilities (with phase-aware calibration) reliably flag incorrect intermediate outputs more often than correct ones. No correlation analysis, calibration plots, or proxy-validation experiment against ground-truth correctness is described, which is load-bearing for attributing any measured gains to uncertainty awareness rather than to the verification step itself.
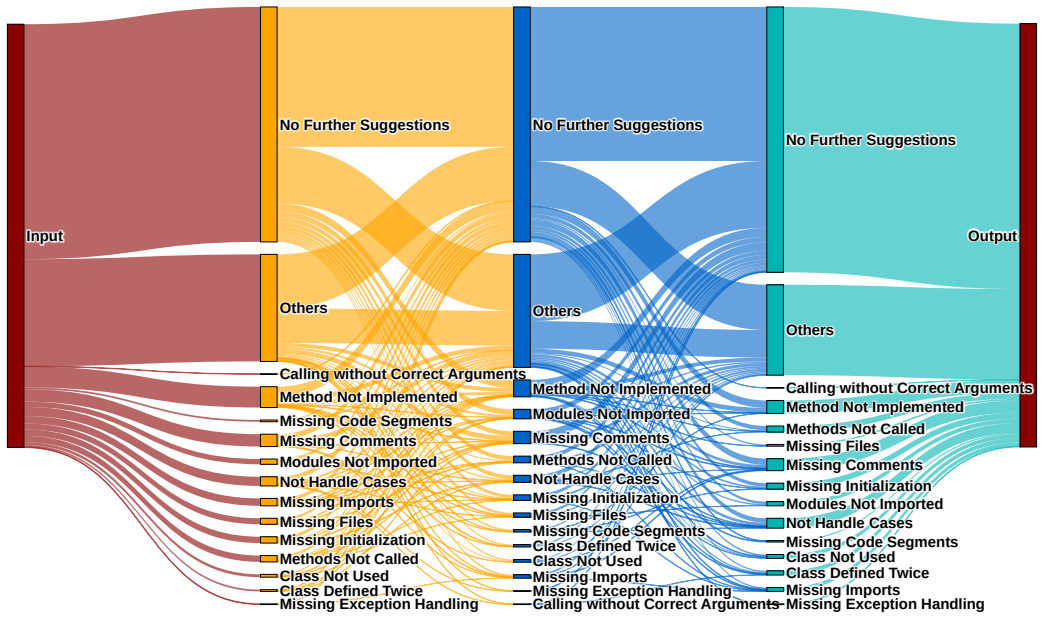
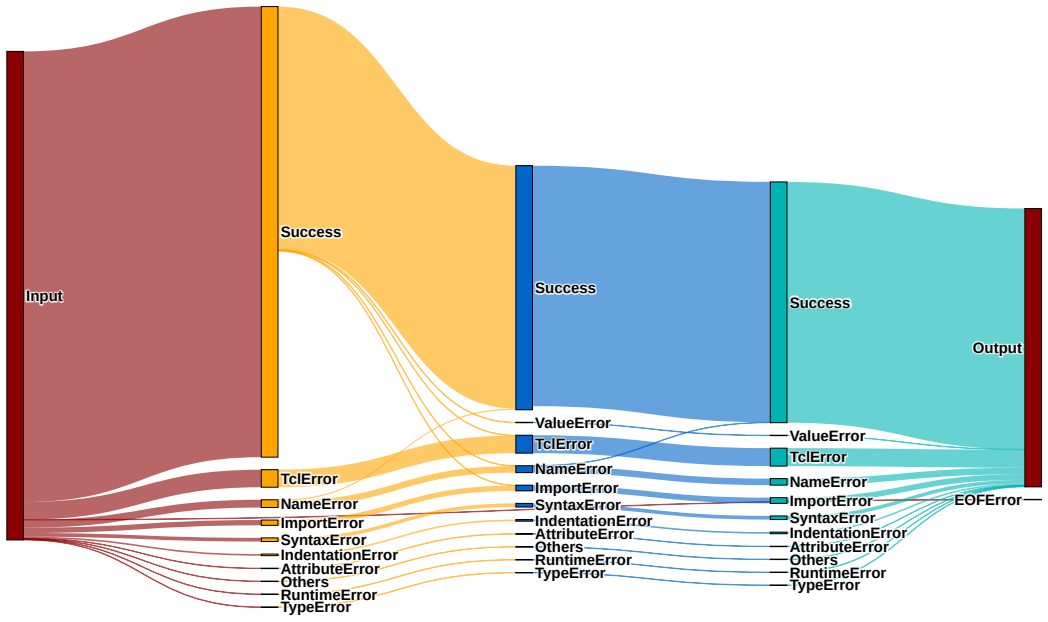
Authors: The manuscript includes ablation studies demonstrating that uncertainty-based verification triggering outperforms random or uniform triggering, supporting the value of the log-probability signal. However, we acknowledge that explicit correlation analysis, calibration plots, or direct proxy-validation of token-level uncertainty against ground-truth correctness of intermediate outputs is not currently presented. We will add this analysis in a new subsection of the revised manuscript, including correlation coefficients and calibration metrics, to more rigorously validate the uncertainty proxy and strengthen attribution of gains. revision: yes
Circularity Check
No circularity in claimed derivation chain
full rationale
The paper describes an empirical multi-agent framework and reports benchmark results on SRDD without presenting equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations. The uncertainty mechanism (token-level log probabilities with phase-aware thresholds) is introduced as a design choice whose effectiveness is evaluated experimentally rather than derived from prior results by the same authors. No step reduces the outperformance claim to a self-referential input by construction; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Software testing with large language models: Survey, landscape, and vision,
J. Wang, Y . Huang, C. Chen, Z. Liu, S. Wang, and Q. Wang, “Software testing with large language models: Survey, landscape, and vision,” IEEE Transactions on Software Engineering, vol. 50, no. 4, 2024, pp. 911–936
2024
-
[2]
Large language models for software engi- neering: A systematic literature review,
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang, “Large language models for software engi- neering: A systematic literature review,” ACM Transactions on Software Engineering and Methodology, vol. 33, no. 8, 2024, pp. 1–79
2024
-
[3]
Unseen horizons: Unveiling the real capability of LLM code generation beyond the familiar,
Y . Zhang, Y . Xie, S. Li, K. Liu, C. Wang, Z. Jia, X. Huang, J. Song, C. Luo, Z. Zheng, R. Xu, Y . Liu, S. Zheng, and X. Liao, “Unseen horizons: Unveiling the real capability of LLM code generation beyond the familiar,” in Proceedings of the IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE/ACM, 2025, pp. 604–615
2025
-
[4]
Software defect reduction top 10 list,
B. Boehm, V . R. Basili et al., “Software defect reduction top 10 list,” Foundations of empirical software engineering: the legacy of Victor R. Basili, vol. 426, no. 37, 2005, pp. 426–431
2005
-
[5]
Imperfect code generation: Uncovering weaknesses in automatic code generation by large language models,
X. Lian, S. Wang, J. Ma, X. Tan, F. Liu, L. Shi, C. Gao, and L. Zhang, “Imperfect code generation: Uncovering weaknesses in automatic code generation by large language models,” in Proceedings of the IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion). IEEE/ACM, 2024
2024
-
[6]
Towards understanding the characteristics of code gener- ation errors made by large language models,
Z. Wang, Z. Zhou, D. Song, Y . Huang, S. Chen, L. Ma, and T. Zhang, “Towards understanding the characteristics of code gener- ation errors made by large language models,” in Proceedings of the IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE/ACM, 2025, pp. 2587–2599
2025
-
[7]
Evaluating large language models in class-level code generation,
X. Du, M. Liu, K. Wang, H. Wang, J. Liu, Y . Chen, J. Feng, C. Sha, X. Peng, and Y . Lou, “Evaluating large language models in class-level code generation,” in Proceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE). IEEE/ACM, 2024, pp. 982–994
2024
-
[8]
Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead,
J. He, C. Treude, and D. Lo, “Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead,” ACM Transactions on Software Engineering and Methodology, vol. 34, no. 5, 2025, pp. 1–30
2025
-
[9]
Metagpt: Meta programming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, S. Yau, Z. Lin, L. Zhou et al., “Metagpt: Meta programming for a multi-agent collaborative framework,” in International Conference on Learning Representations, vol. 2024, 2024, pp. 23 247–23 275
2024
-
[10]
Chatdev: Communicative agents for software development,
C. Qian, W. Liu, H. Liu, N. Chen, Y . Dang, J. Li, C. Yang, W. Chen, Y . Su, X. Cong et al., “Chatdev: Communicative agents for software development,” in Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), 2024, pp. 15 174–15 186
2024
-
[11]
Locobench-agent: An interactive benchmark for llm agents in long-context software engineering,
J. Qiu, Z. Liu, Z. Liu, R. Murthy, J. Zhang, H. Chen, S. Wang, M. Zhu, L. Yang, J. Tan et al., “Locobench-agent: An interactive benchmark for llm agents in long-context software engineering,” arXiv preprint arXiv:2511.13998, 2025
-
[12]
Interactive evaluation of large language models for multi-requirement software engineering tasks,
D. Rontogiannis, M. Peyrard, N. Baldwin, M. Josifoski, R. West, and D. Gunopulos, “Interactive evaluation of large language models for multi-requirement software engineering tasks,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 39, 2026, pp. 32 843–32 850
2026
-
[13]
Towards uncertainty-aware language agent,
J. Han, W. Buntine, and E. Shareghi, “Towards uncertainty-aware language agent,” in Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 6662–6685
2024
-
[14]
Gemma 2: Improving Open Language Models at a Practical Size
G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ramé et al., “Gemma 2: Improving open language models at a practical size,” arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu et al., “Qwen2. 5-coder technical report,” arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Transformers: State- of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz et al., “Transformers: State- of-the-art natural language processing,” in Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, 2020, pp. 38–45
2020
-
[17]
GPT-Engineer: Specify what you want it to build, the AI asks for clarification, and then builds it,
A. Osika, “GPT-Engineer: Specify what you want it to build, the AI asks for clarification, and then builds it,” https://github.com/ gpt-engineer-org/gpt-engineer, 2023
2023
-
[18]
Metagpt: Meta programming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin et al., “Metagpt: Meta programming for a multi-agent collaborative framework,” in The twelfth international conference on learning representations, 2023
2023
-
[19]
Codebert: A pre-trained model for programming and natural languages,
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang et al., “Codebert: A pre-trained model for programming and natural languages,” in Findings of the Association for Computational Linguistics: EMNLP 2020, 2020, pp. 1536–1547
2020
-
[20]
Gamegpt: Multi- agent collaborative framework for game development,
D. Chen, H. Wang, Y . Huo, Y . Li, and H. Zhang, “Gamegpt: Multi- agent collaborative framework for game development,” arXiv preprint arXiv:2310.08067, 2023
-
[21]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y . Zhou, S. Savarese, and C. Xiong, “Codegen: An open large language model for code with multi-turn program synthesis,” arXiv preprint arXiv:2203.13474, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Code Llama: Open Foundation Models for Code
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remez et al., “Code llama: Open foundation models for code,” arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Codegemma: Open code models based on gemma,
C. Team, H. Zhao, J. Hui, J. Howland, N. Nguyen, S. Zuo, A. Hu, C. A. Choquette-Choo, J. Shen, J. Kelley et al., “Codegemma: Open code models based on gemma,” arXiv preprint arXiv:2406.11409, 2024
-
[24]
arXiv preprint (2020), https://arxiv.org/abs/2002.07650, arXiv:2002.07650
A. Malinin and M. Gales, “Uncertainty estimation in autoregressive structured prediction,” arXiv preprint arXiv:2002.07650, 2020
-
[25]
L. Kuhn, Y . Gal, and S. Farquhar, “Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,” arXiv preprint arXiv:2302.09664, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Y . Yang, H. Li, Y . Wang, and Y . Wang, “Improving the reliability of large language models by leveraging uncertainty-aware in-context learning,” arXiv preprint arXiv:2310.04782, 2023
-
[27]
Active retrieval augmented generation,
Z. Jiang, F. F. Xu, L. Gao, Z. Sun, Q. Liu, J. Dwivedi-Yu, Y . Yang, J. Callan, and G. Neubig, “Active retrieval augmented generation,” in Proceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 7969–7992
2023
-
[28]
Gorilla: Large language model connected with massive apis,
S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez, “Gorilla: Large language model connected with massive apis,” Advances in Neural Information Processing Systems, vol. 37, 2024, pp. 126 544–126 565
2024
-
[29]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman et al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.