Bandits for Efficient Experimentation: Adapting to Control Group, Preferences, and Context Drifts
Pith reviewed 2026-06-27 17:17 UTC · model grok-4.3
The pith
Dri-MED achieves Õ(κ/Δ̃ d² log T) regret and Õ(d) constraint violations by reducing drifting contextual bandits to a linear bandit with heteroskedastic noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
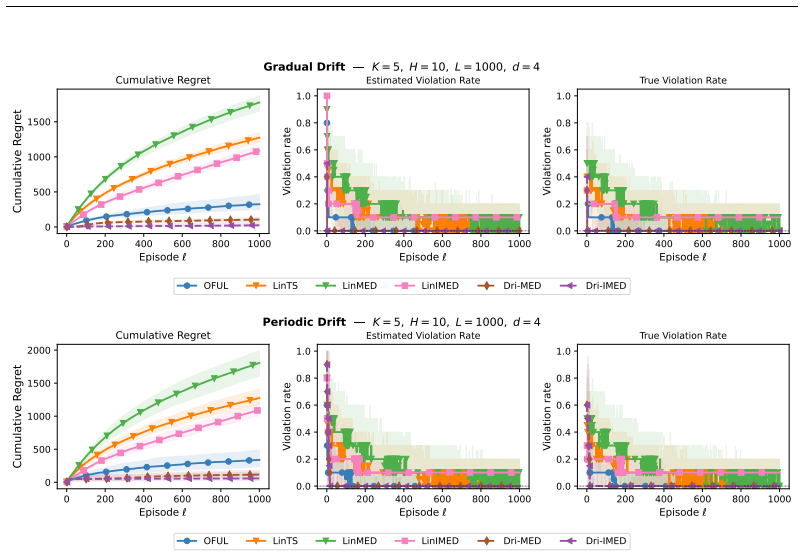
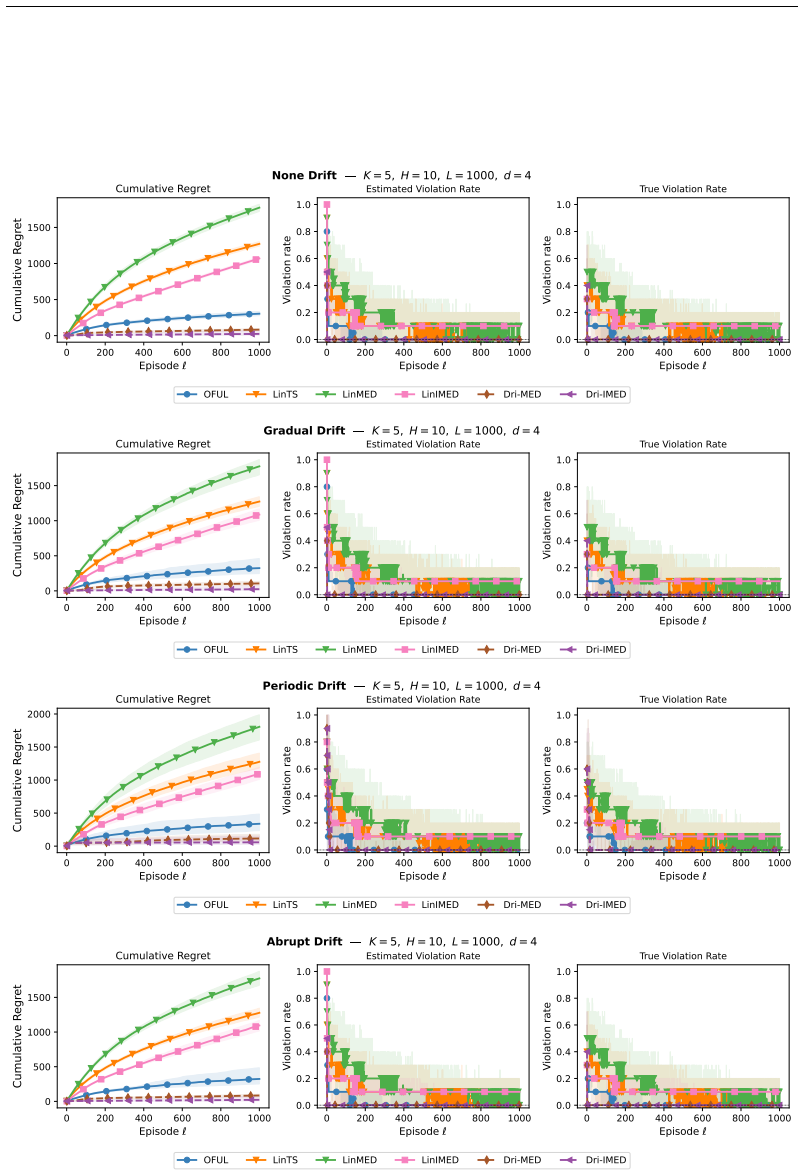
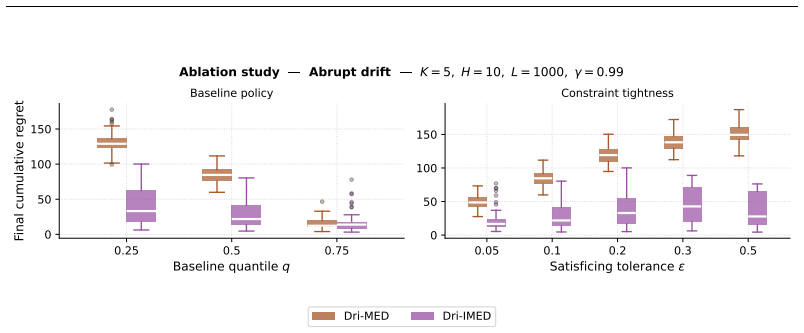
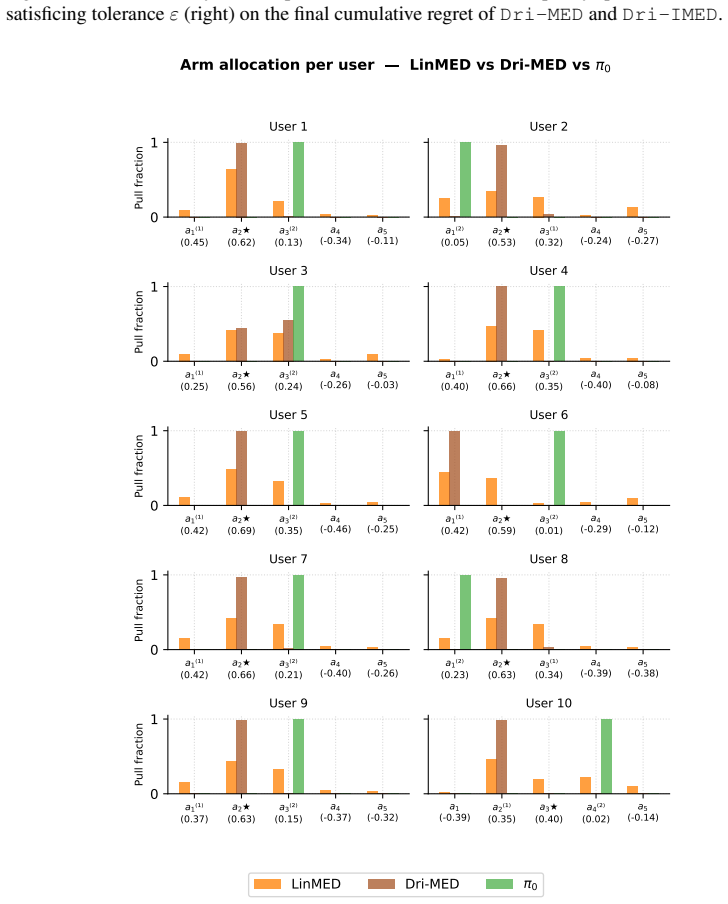
Under practitioner-friendly assumptions the setting reduces to a linear bandit with stationary mean but heteroskedastic and non-stationary noise. Dri-MED, obtained by adapting the linear MED strategy to this noise model, attains instance-dependent regret scaling as Õ(κ/Δ̃ d² log T) where Δ̃ is the constraint-aware sub-optimality gap relative to π₀, together with Õ(d) expected constraint violations. Numerical experiments indicate that Dri-MED significantly outperforms conservative baselines that ignore drift and preference structure.
What carries the argument
Dri-MED, the adaptation of the linear MED strategy that uses heteroskedastic regression to control the variance-aware multiplicative term κ while enforcing the baseline constraint at each step.
If this is right
- Regret scales with the constraint-aware gap Δ̃ rather than an unconstrained gap.
- Expected constraint violations remain Õ(d) independently of the time horizon T.
- Both preference personalization and context drift are handled inside the same regret bound.
- The variance factor κ is controlled explicitly through heteroskedastic regression rather than worst-case bounds.
Where Pith is reading between the lines
- The reduction technique could be applied to other constrained bandit settings that exhibit non-stationary noise.
- Practitioners running A/B tests could adopt the same baseline-enforcement mechanism to keep control-group integrity while adapting to user groups.
- If the heteroskedastic regression step is replaced by a simpler estimator the regret bound would lose the κ term but might increase the leading constant.
- The Õ(d) violation bound suggests the algorithm could be useful in safety-critical experimentation where even moderate cumulative violations are unacceptable.
Load-bearing premise
The drifting contextual problem with preferences can be reduced to a linear bandit with stationary mean but heteroskedastic and non-stationary noise under the practitioner-friendly assumptions used before algorithm design.
What would settle it
An experiment in which context drift is present, the heteroskedastic regression step is disabled, and the observed regret exceeds the claimed Õ(κ/Δ̃ d² log T) scaling while constraint violations exceed Õ(d).
Figures
read the original abstract
We consider a variant of the linear contextual stochastic multi-armed bandits, where the learner must provide recommendations to a group of users, each having its personalized preference vector, and in the presence of context distributions that are drifting over time. Under practitioner-friendly assumptions, we reduce this setting to linear bandit with stationary mean but heteroskedastic and non-stationary noise. We further study the case when the learner must ensure the mean reward of each decision must exceed that of a baseline strategy $\boldsymbol{\pi}_0$ at each decision step. We introduce Dri-MED, an algorithm inspired from the linear version of the MED strategy, and carefully adapted to handle the non-stationary heteroskedastic noise. We show that the instance-dependent regret scales as $\tilde{\mathcal O}\left(\frac{\kappa}{\tilde{\Delta}}d^2(\log(T)\right)$, where $\tilde{\Delta}$ is the constraint-aware sub-optimality gap subject to policy $\pi_0$, with variance-aware multiplicative term $\kappa$ that we carefully handle using heteroskedastic regression. We further show Dri-MED enjoys $\tilde{\mathcal{O}}(d)$ expected constraint violations. Our numerical results suggest that Dri-MED significantly outperforms conservative baselines that ignores the drift and preference structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript considers linear contextual stochastic multi-armed bandits where recommendations are made to users with personalized preference vectors under drifting context distributions. Under practitioner-friendly assumptions, the setting is reduced to a linear bandit with stationary mean but heteroskedastic and non-stationary noise. The paper introduces Dri-MED, an adaptation of the linear MED strategy that handles this noise and enforces that the mean reward of each decision exceeds that of a baseline policy π₀. It claims an instance-dependent regret of Õ(κ / Δ̃ d² log(T)), where Δ̃ is the constraint-aware sub-optimality gap, together with Õ(d) expected constraint violations, and reports that numerical experiments show outperformance over conservative baselines.
Significance. If the reduction preserves the gap Δ̃ without bias and the heteroskedastic analysis is rigorous, the result would supply a practical, instance-dependent method for constrained experimentation that adapts to drifts and preferences while controlling violations relative to a control group. The explicit handling of κ via heteroskedastic regression and the Õ(d) violation bound are potentially useful strengths for applications such as personalized A/B testing.
major comments (2)
- [Reduction step (preceding Dri-MED design)] The reduction from drifting contexts and personalized preferences to a linear bandit with stationary mean (but heteroskedastic non-stationary noise) is the load-bearing modeling step that enables transfer of both the regret scaling and the violation bound. The manuscript must state the practitioner-friendly assumptions explicitly and prove that they leave the effective constraint-aware gap Δ̃ unchanged; otherwise the claimed Õ(κ / Δ̃ d² log(T)) bound does not hold.
- [Dri-MED analysis and regret proof] The adaptation of MED to heteroskedastic regression and the derivation of the variance-aware term κ in the regret analysis lack sufficient detail. Without a proof sketch or key steps showing how non-stationary noise is controlled while preserving the Õ(d) violation bound, it is impossible to verify that the instance-dependent claim follows from first principles rather than post-hoc fitting.
minor comments (2)
- [Abstract] The abstract states numerical results but provides no description of the experimental setup, number of runs, or specific metrics used to compare against baselines that ignore drift and preference structure.
- [Notation and preliminaries] Notation for ilde{\mathcal{O}} and ilde{\Delta} should be introduced with explicit definitions in the main text before the regret statement is given.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where the reduction and analysis require greater explicitness and detail. We will revise the manuscript to address both major comments by adding the requested statements, proofs, and sketches.
read point-by-point responses
-
Referee: [Reduction step (preceding Dri-MED design)] The reduction from drifting contexts and personalized preferences to a linear bandit with stationary mean (but heteroskedastic non-stationary noise) is the load-bearing modeling step that enables transfer of both the regret scaling and the violation bound. The manuscript must state the practitioner-friendly assumptions explicitly and prove that they leave the effective constraint-aware gap Δ̃ unchanged; otherwise the claimed Õ(κ / Δ̃ d² log(T)) bound does not hold.
Authors: We agree that the assumptions and the invariance of Δ̃ must be made fully explicit. In the revision we will add a dedicated paragraph in Section 2 listing the practitioner-friendly assumptions (bounded drift, norm bounds on preference vectors, and mild conditions on context distributions) and insert a new lemma immediately after the reduction that proves the effective constraint-aware gap Δ̃ is identical to the original gap (no bias is introduced) because the mapping preserves both the mean reward differences and the baseline constraint exactly under those assumptions. revision: yes
-
Referee: [Dri-MED analysis and regret proof] The adaptation of MED to heteroskedastic regression and the derivation of the variance-aware term κ in the regret analysis lack sufficient detail. Without a proof sketch or key steps showing how non-stationary noise is controlled while preserving the Õ(d) violation bound, it is impossible to verify that the instance-dependent claim follows from first principles rather than post-hoc fitting.
Authors: We will expand the analysis. The revised appendix will contain a proof sketch with the following steps: (i) concentration of the heteroskedastic least-squares estimator under non-stationary noise via a time-varying variance bound, (ii) incorporation of the resulting κ factor into the MED dual and the resulting instance-dependent regret bound, and (iii) a separate argument showing that the constraint-violation analysis depends only on the dual variable update and is unaffected by the noise heteroskedasticity, yielding the Õ(d) bound. These steps will be written out explicitly rather than left implicit. revision: yes
Circularity Check
No significant circularity; modeling reduction and regret derivation are self-contained under stated assumptions
full rationale
The paper explicitly frames the reduction of the drifting-context, personalized-preference setting to a linear bandit with stationary mean and heteroskedastic non-stationary noise as a modeling step under 'practitioner-friendly assumptions' prior to algorithm design. The instance-dependent regret bound Õ(κ/Δ̃ d² log T) and Õ(d) constraint violations are then claimed for this reduced model, with Δ̃ defined as the standard constraint-aware sub-optimality gap relative to baseline π₀. No equations or text indicate that any 'prediction' reduces to a fitted parameter by construction, that a self-citation supplies a uniqueness theorem, or that an ansatz is smuggled via prior work. The derivation chain therefore stands on the validity of the modeling assumptions rather than on any internal definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Practitioner-friendly assumptions allow reduction of the drifting personalized-preference setting to a linear bandit with stationary mean but heteroskedastic and non-stationary noise.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2411.00229 , year=
Minimum empirical divergence for sub-gaussian linear bandits , author=. arXiv preprint arXiv:2411.00229 , year=
-
[2]
Diggle, Peter J. and Chetwynd, Amanda G. , isbn =. 5 Experimental design: agricultural field experiments and clinical trials , booktitle =. 2011 , month =. doi:10.1093/acprof:oso/9780199543182.003.0005 , eprint =
work page doi:10.1093/acprof:oso/9780199543182.003.0005 2011
-
[3]
Essay on , author=
On the Application of Probability Theory to Agricultural Experiments. Essay on , author=. Statistical Science , volume=. 1923 , note=
1923
-
[4]
arXiv preprint arXiv:2405.15200 , year=
Indexed minimum empirical divergence-based algorithms for linear bandits , author=. arXiv preprint arXiv:2405.15200 , year=
-
[5]
The Journal of Machine Learning Research , volume=
Non-asymptotic analysis of a new bandit algorithm for semi-bounded rewards , author=. The Journal of Machine Learning Research , volume=. 2015 , publisher=
2015
-
[6]
arXiv preprint arXiv:2303.06058 , year=
A general recipe for the analysis of randomized multi-armed bandit algorithms , author=. arXiv preprint arXiv:2303.06058 , year=
-
[7]
Advances in Neural Information Processing Systems , volume=
Fast asymptotically optimal algorithms for non-parametric stochastic bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Advances in Neural Information Processing Systems , volume=
Kullback-leibler maillard sampling for multi-armed bandits with bounded rewards , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
arXiv preprint arXiv:2502.14379 , year=
Achieving adaptivity and optimality for multi-armed bandits using Exponential-Kullback Leibler Maillard Sampling , author=. arXiv preprint arXiv:2502.14379 , year=
-
[10]
Machine Learning , volume=
An asymptotically optimal policy for finite support models in the multiarmed bandit problem , author=. Machine Learning , volume=. 2011 , publisher=
2011
-
[11]
Advances in Neural Information Processing Systems , volume=
Weighted linear bandits for non-stationary environments , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
arXiv preprint arXiv:2003.10113 , year=
Algorithms for non-stationary generalized linear bandits , author=. arXiv preprint arXiv:2003.10113 , year=
-
[13]
arXiv preprint arXiv:2103.05750 , year=
Regret bounds for generalized linear bandits under parameter drift , author=. arXiv preprint arXiv:2103.05750 , year=
-
[14]
arXiv preprint arXiv:2503.12020 , year=
Variance-Dependent Regret Lower Bounds for Contextual Bandits , author=. arXiv preprint arXiv:2503.12020 , year=
-
[15]
Conference On Learning Theory , pages=
Information directed sampling and bandits with heteroscedastic noise , author=. Conference On Learning Theory , pages=. 2018 , organization=
2018
-
[16]
Artificial Intelligence and Statistics , pages=
Linear thompson sampling revisited , author=. Artificial Intelligence and Statistics , pages=. 2017 , organization=
2017
-
[17]
Journal of Machine Learning Research , volume=
Streaming kernel regression with provably adaptive mean, variance, and regularization , author=. Journal of Machine Learning Research , volume=
-
[18]
International Conference on Machine Learning , pages=
Target tracking for contextual bandits: Application to demand side management , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[19]
A Jointly Efficient and Optimal Algorithm for Heteroskedastic Generalized Linear Bandits with Adversarial Corruptions , author=. arXiv preprint arXiv:2602.10971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
The Thirteenth International Conference on Learning Representations , year=
Satisficing Regret Minimization in Bandits , author=. The Thirteenth International Conference on Learning Representations , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Linear stochastic bandits under safety constraints , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
International conference on artificial intelligence and statistics , pages=
Stochastic bandits with linear constraints , author=. International conference on artificial intelligence and statistics , pages=. 2021 , organization=
2021
-
[23]
Seventeenth European Workshop on Reinforcement Learning , year=
Learning to explore with Lagrangians for bandits under unknown constraints , author=. Seventeenth European Workshop on Reinforcement Learning , year=
-
[24]
Advances in neural information processing systems , volume=
Contextual gaussian process bandit optimization , author=. Advances in neural information processing systems , volume=
-
[25]
Artificial Intelligence and Statistics , pages=
The end of optimism? an asymptotic analysis of finite-armed linear bandits , author=. Artificial Intelligence and Statistics , pages=. 2017 , organization=
2017
-
[26]
International Conference on Machine Learning , pages=
On kernelized multi-armed bandits , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[27]
International conference on machine learning , pages=
Spectral bandits for smooth graph functions , author=. International conference on machine learning , pages=. 2014 , organization=
2014
-
[28]
2017 , school=
Exploration-exploitation with Thompson sampling in linear systems , author=. 2017 , school=
2017
-
[29]
International Conference on Machine Learning , pages=
Almost optimal anytime algorithm for batched multi-armed bandits , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[30]
The Annals of Statistics , pages=
Batched bandit problems , author=. The Annals of Statistics , pages=. 2016 , publisher=
2016
-
[31]
Advances in Neural Information Processing Systems , volume=
Batched multi-armed bandits problem , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
2018 IEEE International Conference on Big Data (Big Data) , pages=
A batched multi-armed bandit approach to news headline testing , author=. 2018 IEEE International Conference on Big Data (Big Data) , pages=. 2018 , organization=
2018
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Regret bounds for batched bandits , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[34]
Advances in Neural Information Processing Systems , volume=
Batched thompson sampling , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
IEEE Transactions on Information Theory , volume=
Asymptotic performance of Thompson sampling for batched multi-armed bandits , author=. IEEE Transactions on Information Theory , volume=. 2023 , publisher=
2023
-
[36]
Advances in Neural Information Processing Systems , volume=
Optimal batched best arm identification , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Advances in neural information processing systems , volume=
Inference for batched bandits , author=. Advances in neural information processing systems , volume=
-
[38]
Advances in Neural Information Processing Systems , volume=
An asymptotically optimal batched algorithm for the dueling bandit problem , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
International conference on machine learning , pages=
Thompson sampling for contextual bandits with linear payoffs , author=. International conference on machine learning , pages=. 2013 , organization=
2013
-
[40]
2023 , publisher=
Experimenting on the Farm: Introduction to Experimental Design , author=. 2023 , publisher=
2023
-
[41]
1984 , publisher=
Statistical procedures for agricultural research , author=. 1984 , publisher=
1984
-
[42]
Advances in neural information processing systems , number=
Batched Thompson Sampling, Advances in Neural Information Processing Systems , author=. Advances in neural information processing systems , number=
-
[43]
Field Crops Research , volume=
A new adaptive identification strategy of best crop management with farmers , author=. Field Crops Research , volume=. 2024 , publisher=
2024
-
[44]
Foundations and Trends in Optimization , volume=
Introduction to online convex optimization , author=. Foundations and Trends in Optimization , volume=. 2016 , publisher=
2016
-
[45]
Advances in neural information processing systems , volume=
Improved algorithms for linear stochastic bandits , author=. Advances in neural information processing systems , volume=
-
[46]
arXiv preprint arXiv:2402.07341 , year=
Noise-adaptive confidence sets for linear bandits and application to bayesian optimization , author=. arXiv preprint arXiv:2402.07341 , year=
-
[47]
International Conference on Machine Learning , pages=
Contextual bandits with large action spaces: Made practical , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[48]
Advances in Neural Information Processing Systems , volume=
An asymptotically optimal primal-dual incremental algorithm for contextual linear bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Breakthroughs in statistics: Methodology and distribution , pages=
The arrangement of field experiments , author=. Breakthroughs in statistics: Methodology and distribution , pages=. 1926 , publisher=
1926
-
[50]
Li et al
A new Rothamsted long-term field experiment for the twenty-first century: principles and practice: X. Li et al. , author=. Agronomy for Sustainable Development , volume=. 2023 , publisher=
2023
-
[51]
Journal of the Ministry of Agriculture , volume=
The arrangement of field experiments , author=. Journal of the Ministry of Agriculture , volume=. 1926 , publisher=
1926
-
[52]
1995 , publisher=
A text book of agricultural statistics , author=. 1995 , publisher=
1995
-
[53]
American Economic Review , volume=
A theory of experimenters: Robustness, randomization, and balance , author=. American Economic Review , volume=. 2020 , publisher=
2020
-
[54]
Encyclopedia of machine learning and data mining , pages=
Online controlled experiments and A/B tests , author=. Encyclopedia of machine learning and data mining , pages=. 2015 , publisher=
2015
-
[55]
Nature , volume=
Machine-learning-assisted materials discovery using failed experiments , author=. Nature , volume=. 2016 , publisher=
2016
-
[56]
The Lancet , volume=
Randomisation and baseline comparisons in clinical trials , author=. The Lancet , volume=. 1990 , publisher=
1990
-
[57]
2018 , publisher=
Design of experiments for agriculture and the natural sciences , author=. 2018 , publisher=
2018
-
[58]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[59]
Bandit Algorithms , DOI=
Lattimore, Tor and Szepesvári, Csaba , year=. Bandit Algorithms , DOI=
-
[60]
Computational and structural biotechnology journal , volume=
Machine learning applications in drug development , author=. Computational and structural biotechnology journal , volume=. 2020 , publisher=
2020
-
[61]
The Lancet , volume=
Safety and immunogenicity of seven COVID-19 vaccines as a third dose (booster) following two doses of ChAdOx1 nCov-19 or BNT162b2 in the UK (COV-BOOST): a blinded, multicentre, randomised, controlled, phase 2 trial , author=. The Lancet , volume=. 2021 , publisher=
2021
-
[62]
Applied mathematics and computation , volume=
Effective implementation of the -constraint method in multi-objective mathematical programming problems , author=. Applied mathematics and computation , volume=. 2009 , publisher=
2009
-
[63]
arXiv preprint arXiv:2509.05460 , year=
Calibrated Recommendations with Contextual Bandits , author=. arXiv preprint arXiv:2509.05460 , year=
-
[64]
One Good Source is All You Need: Near-Optimal Regret for Bandits under Heterogeneous Noise
One Good Source is All You Need: Near-Optimal Regret for Bandits under Heterogeneous Noise , author=. arXiv preprint arXiv:2602.14474 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Statistics in Medicine , volume=
Heterogeneity in phase I clinical trials: prior elicitation and computation using the continual reassessment method , author=. Statistics in Medicine , volume=. 2001 , publisher=
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.