ExTra: Exploratory Trajectory Optimization for Language Model Reinforcement Learning
Pith reviewed 2026-06-26 00:21 UTC · model grok-4.3
The pith
ExTra adds embedding novelty rewards and entropy prefix regeneration to GRPO, lifting math reasoning pass rates by five points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
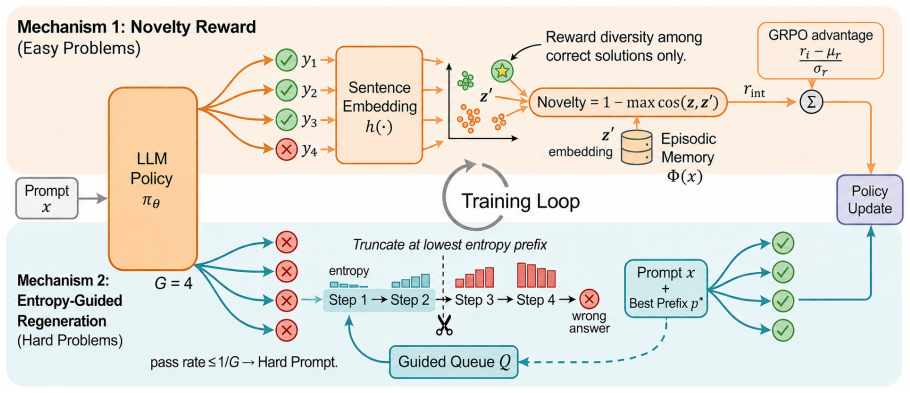
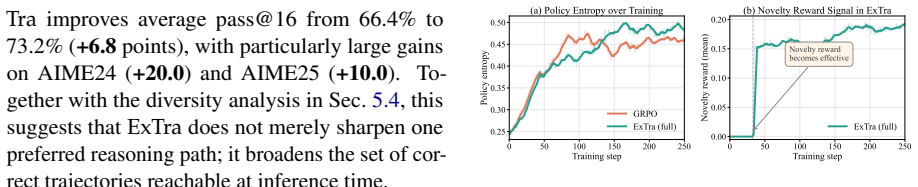
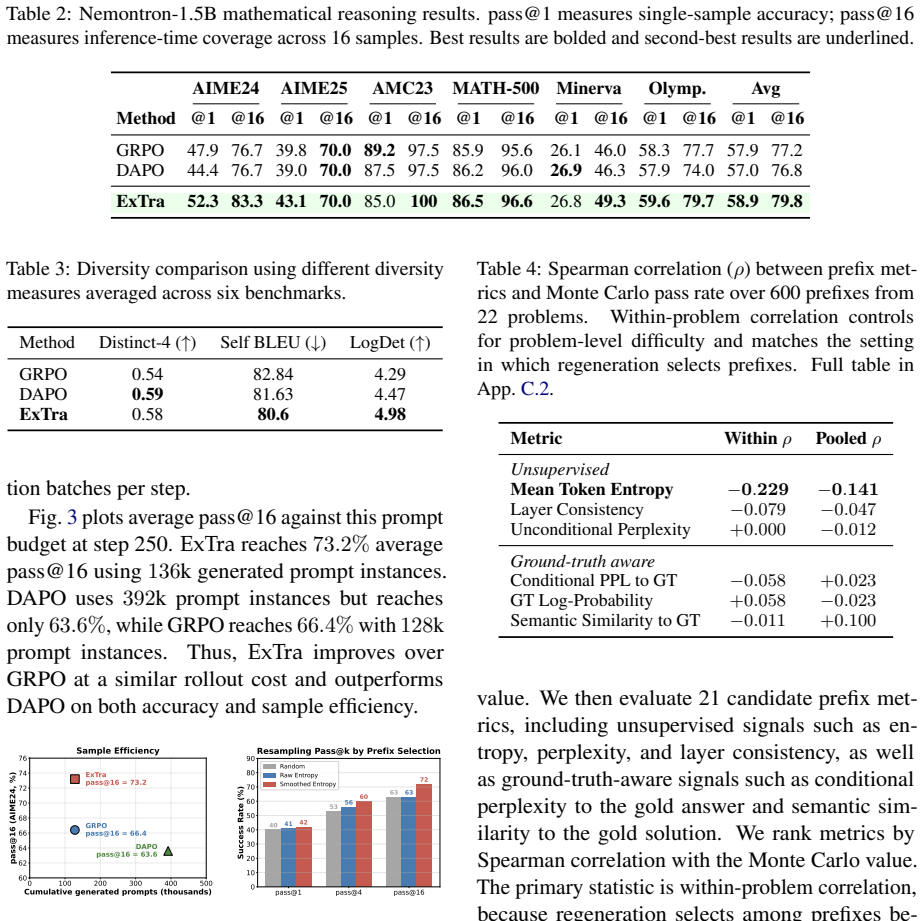
ExTra is a GRPO-compatible framework that extracts exploration signals from the model's own rollouts. It combines a novelty reward that adds embedding-based diversity bonuses after GRPO normalization to reward diverse correct solutions, and entropy-guided prefix regeneration that scores partial trajectories by entropy and continues exploration from promising intermediate steps. Across six mathematical reasoning benchmarks this produces roughly five-point gains on pass@1 and seven-point gains on pass@16 for Qwen3-1.7B.
What carries the argument
ExTra's novelty reward using embedding diversity after GRPO normalization and its entropy-guided prefix regeneration from high-entropy partial trajectories.
If this is right
- Single-sample accuracy on mathematical reasoning tasks increases.
- Inference-time coverage of distinct correct solutions increases.
- The framework remains compatible with existing GRPO training pipelines.
- Exploration bonuses are derived entirely from the model's rollouts without external data.
Where Pith is reading between the lines
- The same rollout-derived signals could be tested in reinforcement learning setups outside mathematical reasoning.
- If the signals prove stable, they might reduce the performance gap between smaller and larger models on verifiable-reward tasks.
- Measuring whether the novelty and entropy bonuses remain effective when the base model changes would test robustness.
Load-bearing premise
The embedding-based novelty signal and entropy scores from the model's own rollouts supply useful, non-spurious exploration bonuses that improve learning rather than merely increasing variance.
What would settle it
An ablation that removes both the novelty reward and the entropy-guided regeneration, then measures no change or a drop in pass@1 and pass@16 on the six benchmarks, would falsify the claim that these signals drive the observed gains.
Figures
read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) for language-model reasoning can fail at both extremes of task difficulty: easy prompts often produce all-correct, low-diversity rollout groups with little gradient signal, while hard prompts can produce all-incorrect groups with no positive reward. We introduce ExTra (Exploratory Trajectory Optimization), a GRPO-compatible framework that extracts exploration signals from the model's own rollouts. ExTra combines two mechanisms: (i) a novelty reward that adds embedding-based diversity bonuses after GRPO normalization, rewarding diverse correct solutions; and (ii) entropy-guided prefix regeneration, which scores partial trajectories using entropy signals and continues exploration from promising intermediate steps. Across six mathematical reasoning benchmarks, ExTra improves Qwen3-1.7B over GRPO by about +5 points on pass@1 and +7 points on pass@16, showing that trajectory-level exploration signals can improve both single-sample accuracy and inference-time coverage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ExTra, a GRPO-compatible framework for RLVR in language models that addresses low-diversity rollouts on easy prompts and zero-reward groups on hard prompts. It adds two mechanisms: (i) a novelty reward that applies embedding-based diversity bonuses after GRPO normalization to reward diverse correct solutions, and (ii) entropy-guided prefix regeneration that scores partial trajectories and restarts exploration from promising prefixes. On six mathematical reasoning benchmarks, ExTra improves Qwen3-1.7B over GRPO by roughly +5 points pass@1 and +7 points pass@16.
Significance. If the gains prove robust and causally attributable to the two signals, the work supplies a lightweight, rollout-internal method for improving both training signal and inference coverage in reasoning RL. The approach of extracting novelty and entropy signals directly from the policy's own trajectories is a practical strength that avoids external models or additional parameters.
major comments (3)
- [Experimental results / §4] Experimental section (results tables and §4): the central empirical claim of +5 pass@1 / +7 pass@16 gains is presented without reported run counts, standard deviations, number of random seeds, or statistical tests. This prevents verification that the improvements exceed baseline variance and is load-bearing for the attribution to ExTra.
- [§3.1] §3.1 (novelty reward definition): the embedding-based bonus is added after GRPO normalization and described as rewarding diverse correct solutions, yet no ablation or control (e.g., random bonus of matched magnitude, or lexical-only diversity) is reported. Without this, it is impossible to rule out that any variance-increasing additive term would produce comparable gains, undermining the claim that the embedding signal is the causal mechanism.
- [§3.2] §3.2 (entropy-guided prefix regeneration): the method scores partial trajectories with entropy and regenerates from promising prefixes, but the paper supplies no comparison isolating this component from the novelty reward alone, nor any analysis of how often regeneration is triggered or its effect on gradient variance.
minor comments (2)
- [§3] Notation for the combined reward (Eq. in §3) should explicitly state whether the novelty term is normalized per group or globally, and whether it is applied only to correct trajectories.
- [Results] The six benchmarks are listed in the abstract but the main text should include a table with per-benchmark pass@1 and pass@16 numbers plus GRPO baselines for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the empirical validation and providing necessary ablations. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental results / §4] Experimental section (results tables and §4): the central empirical claim of +5 pass@1 / +7 pass@16 gains is presented without reported run counts, standard deviations, number of random seeds, or statistical tests. This prevents verification that the improvements exceed baseline variance and is load-bearing for the attribution to ExTra.
Authors: We agree that the absence of run statistics limits verification of the gains. In the revised manuscript we will report results over multiple random seeds (with the exact count specified), include standard deviations, and add statistical significance tests to confirm the improvements exceed baseline variance. revision: yes
-
Referee: [§3.1] §3.1 (novelty reward definition): the embedding-based bonus is added after GRPO normalization and described as rewarding diverse correct solutions, yet no ablation or control (e.g., random bonus of matched magnitude, or lexical-only diversity) is reported. Without this, it is impossible to rule out that any variance-increasing additive term would produce comparable gains, undermining the claim that the embedding signal is the causal mechanism.
Authors: We acknowledge that controls are required to establish causality for the embedding signal. We will add ablations in the revision comparing the embedding novelty reward against a random bonus of matched magnitude and a lexical-only diversity baseline. revision: yes
-
Referee: [§3.2] §3.2 (entropy-guided prefix regeneration): the method scores partial trajectories with entropy and regenerates from promising prefixes, but the paper supplies no comparison isolating this component from the novelty reward alone, nor any analysis of how often regeneration is triggered or its effect on gradient variance.
Authors: We will add an ablation isolating the entropy-guided prefix regeneration from the novelty reward alone. We will also report regeneration trigger frequency and analyze its impact on gradient variance. revision: yes
Circularity Check
No circularity: empirical method with direct benchmark comparisons
full rationale
The paper describes ExTra as a GRPO-compatible framework using embedding-based novelty rewards and entropy-guided prefix regeneration extracted from rollouts. It reports empirical gains (+5 pass@1, +7 pass@16) on six math benchmarks versus GRPO baseline. No derivation chain, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatz smuggling is present. The central claims rest on experimental results rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
Texygen: A benchmarking platform for text generation models , author=. The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
-
[2]
arXiv preprint arXiv:2509.09675 , year=
Cde: Curiosity-driven exploration for efficient reinforcement learning in large language models , author=. arXiv preprint arXiv:2509.09675 , year=
-
[4]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[5]
Policy gradient methods for reinforcement learning with function approximation , author=. Proc. NeurIPS , volume=
-
[6]
Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning , author=. Proc. ICLR , year=
-
[7]
arXiv preprint arXiv:2407.21787 , year=
Large language monkeys: Scaling inference compute with repeated sampling , author=. arXiv preprint arXiv:2407.21787 , year=
-
[8]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[9]
arXiv preprint arXiv:2503.14476 , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=
Curiosity-driven Exploration by Self-Supervised Prediction , author=. Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=. 2017 , organization=
2017
-
[12]
International Conference on Learning Representations (ICLR) , year=
Exploration by Random Network Distillation , author=. International Conference on Learning Representations (ICLR) , year=
-
[13]
arXiv preprint arXiv:2305.20050 , year=
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Math-Shepherd: Verify and Reinforce
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Run and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang , journal=. Math-Shepherd: Verify and Reinforce
-
[16]
arXiv preprint arXiv:2501.12948 , year=
-
[17]
arXiv preprint arXiv:1707.06347 , year=
Proximal Policy Optimization Algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.