Rethinking Groups in Critic-Free RLVR
Pith reviewed 2026-06-27 03:18 UTC · model grok-4.3
The pith
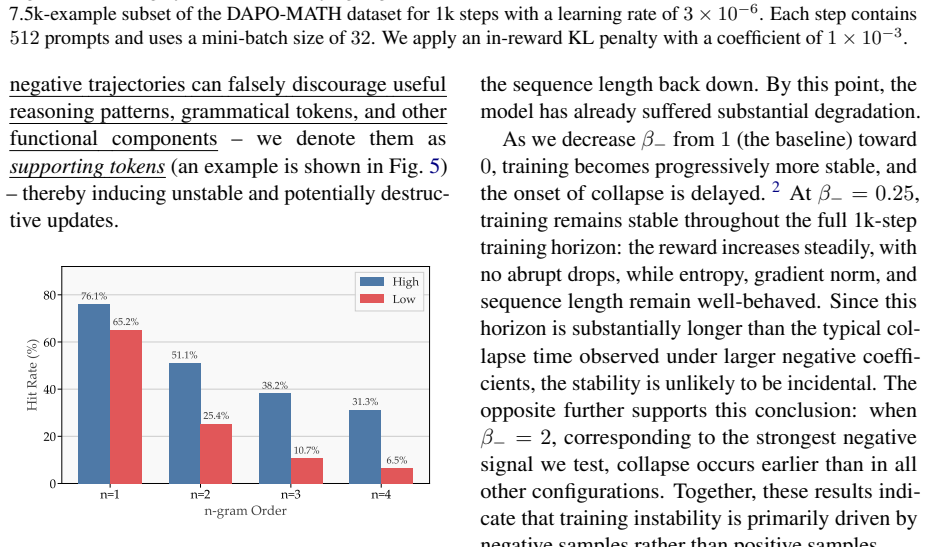
Negative token filtering enables stable single-rollout training in critic-free RL by stopping false penalties on negative samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
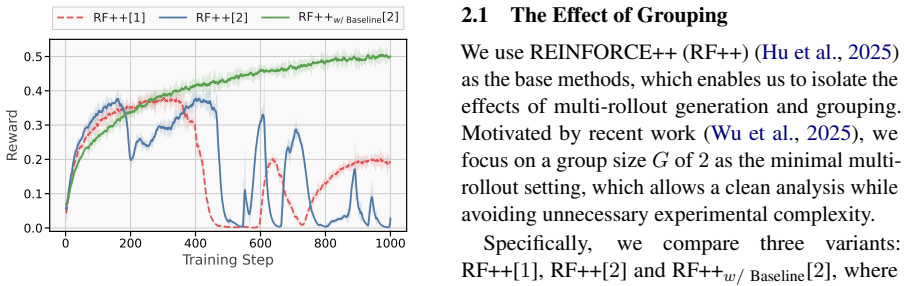
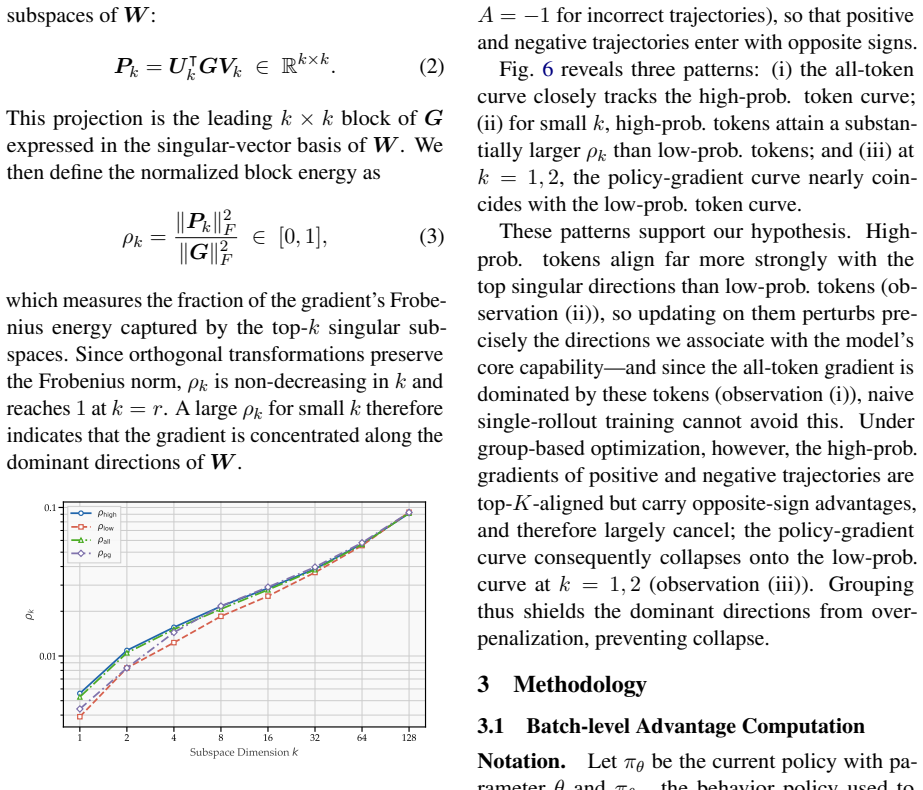
The authors demonstrate that the primary role of the group is to prevent false penalties on negative samples during advantage calculation; negative token filtering replicates this protection without groups, yielding stable single-rollout training that matches group-based performance on reasoning tasks and exceeds it on agentic tasks.
What carries the argument
Negative token filtering, which removes or masks negative tokens before advantage computation to avoid spurious penalties in single-rollout batch-level estimators.
If this is right
- Training requires only one rollout per prompt instead of a synchronized group, cutting generation cost and removing synchronization barriers.
- The method extends to batch-level advantage estimators without redesigning the core RL loop.
- Agentic tasks show stronger final performance than group-based baselines while reasoning tasks remain comparable.
- Structured or variable-length rollouts become easier to handle because no fixed group size is required.
Where Pith is reading between the lines
- The approach could cut total rollout compute roughly in half for the same number of training examples.
- It may reduce the risk of mode collapse that sometimes appears when groups force repeated sampling of the same prompt.
- Similar filtering logic might apply to other critic-free estimators that currently rely on multiple samples for variance reduction.
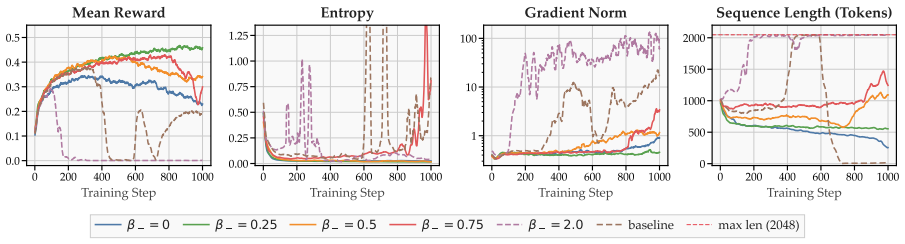
Load-bearing premise
That the main purpose of grouping rollouts is to block false penalties on negative samples and that filtering them produces equivalent advantage signals without the group.
What would settle it
A controlled run on the same tasks showing that single-rollout training without negative token filtering produces markedly higher variance or lower final performance than the filtered version or the original group baseline.
Figures



read the original abstract
Reinforcement learning (RL) has become a central paradigm for post-training large language models. Existing critic-free RL methods typically generate a group of rollouts for the same question to estimate value baselines for advantage computation. However, this design suffers from data inefficiency, group synchronization barriers, and inflexibility with structured rollouts. In this work, we revisit the role of the ``group'' and show that its underlying function is not merely to estimate baselines but to prevent false penalties on negative samples. Building on this insight, we propose negative token filtering, a simple and effective strategy that enables stable single-rollout training. We apply it to two batch-level advantage methods, achieving comparable performance on reasoning tasks and stronger performance on agentic tasks relative to group-based RL techniques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reexamines the role of rollout groups in critic-free RLVR for LLMs. It claims that groups primarily serve to prevent false penalties on negative samples rather than solely estimating value baselines. Building on this, the authors propose negative token filtering as a strategy for stable single-rollout training, apply it to two batch-level advantage methods, and report performance comparable to group-based RL on reasoning tasks and stronger on agentic tasks.
Significance. If the reinterpretation of the group and the negative token filtering method hold, the work could enable more data-efficient and flexible critic-free RL training by removing group synchronization requirements. The reported empirical outcomes on reasoning and agentic tasks indicate potential practical advantages over existing group-based baselines.
Simulated Author's Rebuttal
We thank the referee for the concise summary of our manuscript and the recommendation for minor revision. The report accurately reflects the central claim that groups in critic-free RLVR primarily prevent false penalties on negative samples, motivating our negative token filtering approach for single-rollout training. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper reinterprets the group's role via observational insight (preventing false penalties on negative samples) rather than any mathematical derivation, fitted parameter, or self-citation chain. The abstract and stated argument present this as a conceptual reframing that directly motivates negative token filtering, with no equations, uniqueness theorems, or prior self-work invoked to force the result. The central claim remains independent of its inputs and does not reduce by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[2]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[3]
2025 , howpublished =
AMC 2023 , author =. 2025 , howpublished =
2023
-
[4]
2026 , howpublished =
AIME 2025 , author =. 2026 , howpublished =
2025
-
[5]
2024 , eprint=
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems , author=. 2024 , eprint=
2024
-
[6]
2022 , eprint=
Solving Quantitative Reasoning Problems with Language Models , author=. 2022 , eprint=
2022
-
[7]
2024 , eprint=
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs , author=. 2024 , eprint=
2024
-
[8]
2021 , eprint=
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , author=. 2021 , eprint=
2021
-
[9]
2023 , eprint=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. 2023 , eprint=
2023
-
[10]
2023 , eprint=
Let's Verify Step by Step , author=. 2023 , eprint=
2023
-
[11]
FlashRL: 8Bit Rollouts, Full Power RL , url =
Liu, Liyuan and Yao, Feng and Zhang, Dinghuai and Dong, Chengyu and Shang, Jingbo and Gao, Jianfeng , journal =. FlashRL: 8Bit Rollouts, Full Power RL , url =
-
[12]
2025 , eprint=
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author=. 2025 , eprint=
2025
-
[13]
2023 , eprint=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2023 , eprint=
2023
-
[14]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[15]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[16]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
arXiv preprint arXiv:2602.22817 , year=
Hierarchy-of-groups policy optimization for long-horizon agentic tasks , author=. arXiv preprint arXiv:2602.22817 , year=
-
[18]
arXiv preprint arXiv:2510.00977 , year=
It takes two: Your grpo is secretly dpo , author=. arXiv preprint arXiv:2510.00977 , year=
-
[19]
Advances in Neural Information Processing Systems , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. Advances in Neural Information Processing Systems , year=
-
[20]
Advances in Neural Information Processing Systems , year=
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. Advances in Neural Information Processing Systems , year=
-
[21]
arXiv preprint arXiv:2501.03262 , year=
Reinforce++: Stabilizing critic-free policy optimization with global advantage normalization , author=. arXiv preprint arXiv:2501.03262 , year=
-
[22]
Single-stream policy optimization , author=. Int. Conf. Learn. Represent. , year=
-
[23]
arXiv preprint arXiv:2404.05868 , year=
Negative preference optimization: From catastrophic collapse to effective unlearning , author=. arXiv preprint arXiv:2404.05868 , year=
-
[24]
arXiv preprint arXiv:2605.08666 , year=
The Cancellation Hypothesis in Critic-Free RL: From Outcome Rewards to Token Credits , author=. arXiv preprint arXiv:2605.08666 , year=
-
[25]
arXiv preprint arXiv:2509.21154 , year=
Grpo is secretly a process reward model , author=. arXiv preprint arXiv:2509.21154 , year=
-
[26]
arXiv preprint arXiv:2310.10505 , year=
Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models , author=. arXiv preprint arXiv:2310.10505 , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
The surprising effectiveness of negative reinforcement in llm reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[29]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Contrastive decoding: Open-ended text generation as optimization , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[30]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[31]
Advances in Neural Information Processing Systems , volume=
Disco: Reinforcing large reasoning models with discriminative constrained optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in Neural Information Processing Systems , volume=
Group-in-group policy optimization for llm agent training , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.