Clinical Reasoning Graphs: Structured Evaluation of LLM Diagnostic Reasoning Reveals Competence Without Consistency
Pith reviewed 2026-06-30 05:54 UTC · model grok-4.3
The pith
LLMs reach diagnostic accuracy on clinical cases but show equivalent reasoning graph similarity within and between case clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
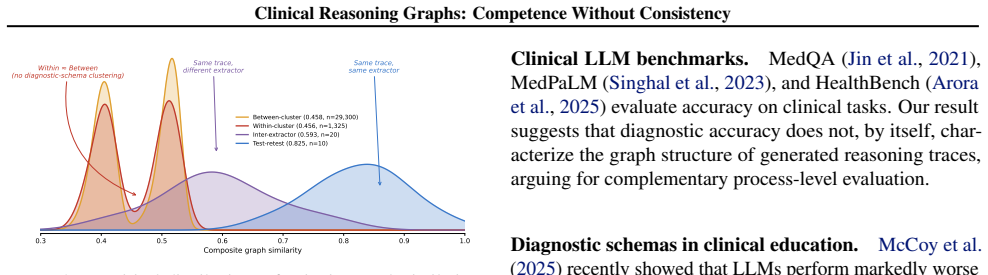
Across 15 model-condition comparisons, within-cluster and between-cluster composite similarity are nearly equal, and no comparison survives multiple-testing correction; graph similarity is also nearly identical for pairs of models that are both correct (0.488) and both incorrect (0.484). Structured reflection prompting increases explicit discriminating-feature analysis within traces (+33%) but does not increase cross-case consistency.
What carries the argument
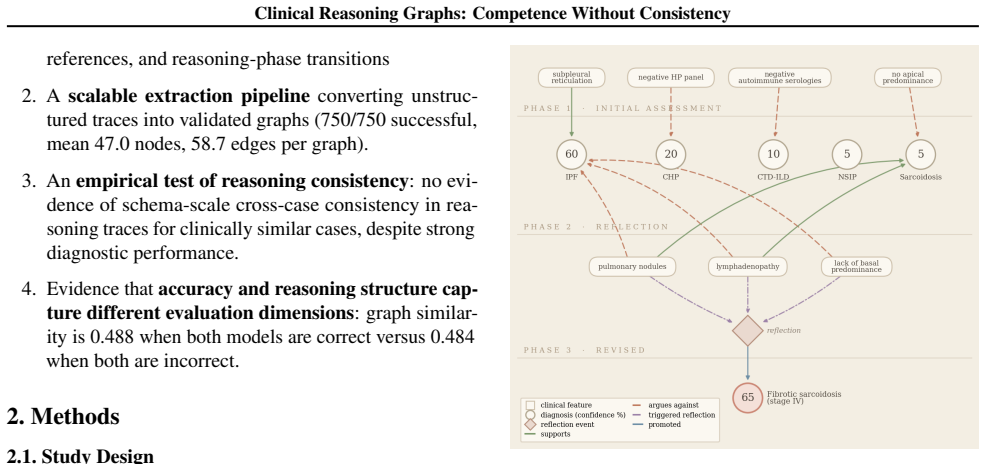
Clinical reasoning graphs, structured representations with 5 node types and 7 edge types extracted from free-text LLM diagnostic traces via a domain ontology, whose composite similarity serves as the measure of stable reasoning patterns.
If this is right
- Diagnostic accuracy alone cannot distinguish stable clinically-grounded reasoning from pattern matching.
- Graph structure captures a dimension of reasoning independent of whether the final diagnosis is correct.
- Structured reflection prompting boosts explicit feature analysis but leaves cross-case consistency unchanged.
- Process-level evaluation with graph similarity should complement final-answer accuracy in LLM clinical assessment.
Where Pith is reading between the lines
- Benchmarks that score only final diagnoses may overestimate reliability when models are deployed on new cases.
- The same graph extraction approach could be adapted to test reasoning consistency in non-medical domains such as legal analysis or scientific hypothesis generation.
- Low consistency may contribute to brittle performance when case distributions shift even if average accuracy remains high.
Load-bearing premise
The composite graph similarity from the 5-node 7-edge ontology extraction pipeline validly operationalizes stable structured reasoning patterns or diagnostic schemas.
What would settle it
A replication on the same 50 NEJM cases that finds statistically significant higher within-cluster than between-cluster composite similarity after multiple-testing correction would falsify the central result.
Figures
read the original abstract
Modern large language models (LLMs) reach 60-70% diagnostic accuracy on complex clinical case benchmarks, but accuracy alone cannot distinguish stable clinically-grounded reasoning from pattern matching. We introduce clinical reasoning graphs, structured graph representations extracted from free-text LLM diagnostic traces using a domain-grounded ontology with 5 node types and 7 edge types. We apply this pipeline to 750 traces from five LLMs across 50 New England Journal of Medicine Clinicopathological Conference cases and three prompt conditions, and test whether diagnostic traces show stable structured reasoning patterns, or diagnostic schemas, for clinically similar cases. We operationalize this as higher graph similarity among clinically similar cases than among clinically dissimilar ones. Across 15 model-condition comparisons, within-cluster and between-cluster composite similarity are nearly equal, and no comparison survives multiple-testing correction; a component-level analysis finds any residual content signal far below schema scale. Graph similarity is also nearly identical for pairs of models that are both correct (0.488) and both incorrect (0.484), suggesting that graph structure captures a dimension not reflected in diagnostic accuracy. Structured reflection prompting increases explicit discriminating-feature analysis within traces (+33%) but does not increase cross-case consistency. These results show diagnostic competence without schema-scale reasoning consistency, and indicate that final-answer accuracy should be complemented by process-level evaluation. We release the ontology, extraction pipeline, validation protocol, and the extracted reasoning graphs and similarity artifacts as resources for structured evaluation of LLM clinical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces clinical reasoning graphs extracted from free-text LLM diagnostic traces via a fixed domain ontology (5 node types, 7 edge types). It applies the pipeline to 750 traces from five LLMs on 50 NEJM CPC cases under three prompt conditions and tests for stable diagnostic schemas by comparing composite graph similarity within clinically similar case clusters versus between dissimilar ones. Across 15 model-condition comparisons, within- and between-cluster similarities are statistically indistinguishable (none survive multiple-testing correction); component-level signals are weak, and similarity is nearly identical for correct-correct (0.488) versus incorrect-incorrect (0.484) pairs. Structured reflection prompting boosts explicit feature analysis (+33%) but not cross-case consistency. The central claim is diagnostic competence without schema-scale reasoning consistency, advocating process-level evaluation beyond accuracy. The ontology, pipeline, and artifacts are released.
Significance. If the null result on schema consistency is robust, the work supplies a concrete, reproducible method for structured process evaluation of LLM clinical reasoning and demonstrates that accuracy metrics alone are insufficient. The large scale (750 traces, multiple models/conditions, correction for multiple tests) and public release of the extraction pipeline and graphs are concrete strengths that enable follow-on work. The finding that graph structure is orthogonal to correctness also suggests a useful separation of concerns for future benchmarks.
major comments (2)
- [Methods (ontology extraction and similarity computation)] The central claim (competence without schema-scale consistency) rests on the composite similarity metric detecting schemas if present. The Methods section on the ontology extraction pipeline defines a fixed 5-node/7-edge representation; however, no positive-control experiment or sensitivity analysis is reported showing that this granularity distinguishes known distinct reasoning structures (e.g., alternative causal chains or feature-weighting patterns) on the same cases. Without such evidence, the observed null (within ≈ between) could arise from representational collapse rather than absence of schemas, directly weakening the interpretation of the 15 comparisons and the correct/incorrect pair result (0.488 vs 0.484).
- [Results (component-level analysis)] Results section on component-level analysis: the claim that residual content signal is “far below schema scale” inherits the same 5/7 ontology; if the representation lacks sensitivity, this analysis cannot rule out that finer-grained or alternative graph encodings would reveal consistency. A direct test (e.g., comparison against a higher-resolution extraction or human-annotated schemas) is needed to support the load-bearing conclusion.
minor comments (2)
- [Methods] Clarify in the Methods how the 50 cases were clustered into “clinically similar” groups and whether cluster definitions were pre-registered or derived post-hoc from the same traces.
- [Results] The abstract states “no comparison survives multiple-testing correction”; report the exact correction method and the raw p-values in a supplementary table for transparency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on validating the sensitivity of our ontology. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: The central claim (competence without schema-scale consistency) rests on the composite similarity metric detecting schemas if present. The Methods section on the ontology extraction pipeline defines a fixed 5-node/7-edge representation; however, no positive-control experiment or sensitivity analysis is reported showing that this granularity distinguishes known distinct reasoning structures (e.g., alternative causal chains or feature-weighting patterns) on the same cases. Without such evidence, the observed null (within ≈ between) could arise from representational collapse rather than absence of schemas, directly weakening the interpretation of the 15 comparisons and the correct/incorrect pair result (0.488 vs 0.484).
Authors: We agree that an explicit positive-control or sensitivity analysis would strengthen claims about the ontology's ability to detect schemas if present. The 5/7 ontology is derived from standard clinical reasoning models, and our results show detectable sensitivity (e.g., +33% explicit feature nodes under structured reflection). To address the concern directly, the revised manuscript will add a sensitivity analysis comparing the current ontology against a coarsened version (merged node types) and report effects on within- vs. between-cluster similarities. revision: yes
-
Referee: Results section on component-level analysis: the claim that residual content signal is “far below schema scale” inherits the same 5/7 ontology; if the representation lacks sensitivity, this analysis cannot rule out that finer-grained or alternative graph encodings would reveal consistency. A direct test (e.g., comparison against a higher-resolution extraction or human-annotated schemas) is needed to support the load-bearing conclusion.
Authors: We acknowledge that the component-level claims depend on the chosen representation and that finer-grained encodings or human-annotated schemas could reveal additional consistency. The component results do show condition-specific signals (e.g., prompting effects on features), indicating the graphs are not fully collapsed. A full human-annotation comparison would require new expert effort on the 50 cases and is outside current scope. In revision we will expand the limitations section to discuss this explicitly and identify it as future work. revision: partial
Circularity Check
No circularity: purely empirical comparison of extracted graph similarities
full rationale
The paper defines an extraction pipeline with a fixed 5-node/7-edge ontology, applies it to 750 LLM traces, computes composite graph similarities, and performs direct statistical comparisons (within- vs between-cluster, correct vs incorrect pairs). No equations, fitted parameters, predictions, or derivations are present. The operationalization of 'diagnostic schemas' as higher within-cluster similarity is a testable hypothesis, not a self-definition. No self-citations are load-bearing for any result. The analysis is self-contained against external benchmarks (NEJM CPC cases) with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The domain-grounded ontology with 5 node types and 7 edge types adequately represents the clinically relevant elements in free-text LLM diagnostic traces.
invented entities (1)
-
clinical reasoning graphs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Teaching and Learning in Medicine , volume=
The script concordance test: A tool to assess the reflective clinician , author=. Teaching and Learning in Medicine , volume=
-
[2]
New England Journal of Medicine , volume=
Educational strategies to promote clinical diagnostic reasoning , author=. New England Journal of Medicine , volume=
-
[3]
The assessment of reasoning tool (
Dhaliwal, Gurpreet , journal=. The assessment of reasoning tool (
-
[4]
Eriksen, Alexander V and M. Use of. NEJM AI , volume=
-
[5]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=
-
[6]
What disease does this patient have?
Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter , journal=. What disease does this patient have?
-
[9]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Academic Medicine , volume=
A cognitive perspective on medical expertise: Theory and implications , author=. Academic Medicine , volume=
-
[12]
NEJM AI , volume=
Assessment of large language models in clinical reasoning: A novel benchmarking study , author=. NEJM AI , volume=
-
[13]
2026 , note =
Patel, Nisarg , title =. 2026 , note =
2026
-
[14]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Arora, R. K., Wei, J., Hicks, R. S., Bowman, P., Qui \ n onero-Candela, J., Tsimpourlas, F., Sharman, M., Shah, M., Vallone, A., Beutel, A., Heidecke, J., and Singhal, K. HealthBench : Evaluating large language models towards improved human health. arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Measuring and curing reasoning rigidity: from decorative chain-of-thought to genuine faithfulness
Basu, A. and Chakraborty, P. The illusion of reasoning: Step-level evaluation reveals decorative chain-of-thought in frontier language models. arXiv preprint arXiv:2603.22816, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Bowen, J. L. Educational strategies to promote clinical diagnostic reasoning. New England Journal of Medicine, 355 0 (21): 0 2217--2225, 2006
2006
-
[17]
The script concordance test: A tool to assess the reflective clinician
Charlin, B., Roy, L., Brailovsky, C., Goulet, F., and van der Vleuten, C. The script concordance test: A tool to assess the reflective clinician. Teaching and Learning in Medicine, 12 0 (4): 0 189--195, 2000
2000
-
[18]
The assessment of reasoning tool ( ART ): Structuring the conversation between teachers and learners
Dhaliwal, G. The assessment of reasoning tool ( ART ): Structuring the conversation between teachers and learners. Diagnosis, 4 0 (4): 0 197--203, 2017
2017
-
[19]
V., M ller, S., and Ryg, J
Eriksen, A. V., M ller, S., and Ryg, J. Use of GPT-4 to diagnose complex clinical cases. NEJM AI, 1 0 (1), 2023
2023
-
[20]
What disease does this patient have? A large-scale open domain question answering dataset from medical exams
Jin, D., Pan, E., Oufattole, N., Weng, W.-H., Fang, H., and Szolovits, P. What disease does this patient have? A large-scale open domain question answering dataset from medical exams. Applied Sciences, 11 0 (14): 0 6421, 2021
2021
-
[21]
Measuring Faithfulness in Chain-of-Thought Reasoning
Lanham, T., Chen, A., Radhakrishnan, A., Steiner, B., Denison, C., Hernandez, D., Li, D., Durmus, E., Hubinger, E., Kernion, J., et al. Measuring faithfulness in chain-of-thought reasoning. arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
G., Swamy, R., Sagar, N., Wang, M., Bacchi, S., Fong, J
McCoy, L. G., Swamy, R., Sagar, N., Wang, M., Bacchi, S., Fong, J. M. N., Tan, N. C., Tan, K., Buckley, T. A., Brodeur, P., Celi, L. A., Manrai, A. K., Humbert, A., and Rodman, A. Assessment of large language models in clinical reasoning: A novel benchmarking study. NEJM AI, 2 0 (10), 2025
2025
-
[23]
Patel, N. Problem representation, metacognition, and the limits of diagnostic self-critique In frontier language models , 2026. https://doi.org/10.17605/OSF.IO/B8NHR
-
[24]
S., Wei, J., Chung, H
Singhal, K., Azizi, S., Tu, T., Mahdavi, S. S., Wei, J., Chung, H. W., Scales, N., Tanwani, A., Cole-Lewis, H., Pfohl, S., et al. Large language models encode clinical knowledge. Nature, 620 0 (7972): 0 172--180, 2023
2023
-
[25]
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting
Turpin, M., Michael, J., Perez, E., and Bowman, S. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. Advances in Neural Information Processing Systems, 36, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.