SGR-Bench: Benchmarking Search Agents on State-Gated Retrieval
Pith reviewed 2026-05-22 05:38 UTC · model grok-4.3
The pith
Search agents reach relevant sites but set the wrong filters and scopes on specialized data websites
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
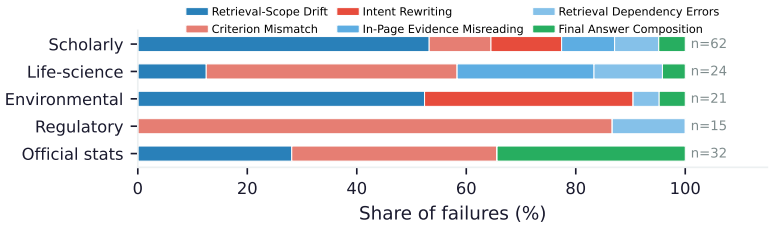
SGR-Bench shows that current agentic LLM systems reach only 66.18 percent item-level F1 on tasks that require discovering a website and then correctly configuring its site-specific retrieval state; manual analysis of 156 failed trajectories finds that retrieval-scope drift accounts for 37.2 percent and criterion mismatch for 27.6 percent of errors, while final answer composition accounts for just 10.3 percent.
What carries the argument
State-gated retrieval (SGR): the requirement to establish site-specific retrieval states through filters, views, hierarchies or scopes before structured evidence can be retrieved from specialized data websites.
If this is right
- Explicit constraint guidance in task prompts can be directly compared against implicit goal-oriented prompts for its effect on successful state establishment.
- Row-level F1 scores being substantially lower than item-level scores indicate that even partial state success often fails to produce complete structured outputs.
- The dominant error categories of scope drift and criterion mismatch point to the need for agents that can monitor and correct their current retrieval state during navigation.
- Performance on SGR-Bench exposes limitations in current tool-using LLMs that standard open-web search benchmarks do not capture.
Where Pith is reading between the lines
- Future agents could incorporate an explicit state-tracking module that logs active filters and scopes separately from general planning steps.
- The benchmark tasks could serve as training data for fine-tuning models to recognize and correct retrieval-state mismatches on the fly.
- Similar state-establishment problems are likely to appear in non-web settings such as database query interfaces or multi-parameter API calls that require sequential configuration.
Load-bearing premise
The 100 expert-curated tasks and the item-level plus row-level F1 metrics are representative of the core difficulties of state-gated retrieval on real specialized websites.
What would settle it
A new agent system that achieves above 85 percent row-level F1 across the full SGR-Bench suite or on a fresh set of equivalent tasks drawn from the same website families would indicate that state configuration is not the primary remaining bottleneck.
Figures






read the original abstract
Recent advances in large language models and tool-using agents have expanded the range of benchmarked web tasks. Yet an important class of specialized retrieval tasks remains undercharacterized. On many specialized data-retrieval websites, answer-bearing evidence becomes accessible only after establishing the correct site-specific retrieval state through filters, views, hierarchies, or scopes. We term this capability state-gated retrieval (SGR). We introduce SGR-Bench, a benchmark for this setting containing 100 expert-curated tasks spanning six source families and 12 public data ecosystems. Each task requires discovering the appropriate website and configuring its site-specific retrieval state to produce a structured answer. SGR-Bench pairs constraint-guided and goal-oriented formulations of the same underlying problems, enabling controlled comparisons between explicit and implicit guidance for state-gated retrieval. We evaluate eight CLI-based agentic LLM systems and three commercial search-agent products. On SGR-Bench, the strongest system reaches only 66.18% item-level F1, while row-level F1 remains much lower. A manual audit of 156 analyzable failed CLI trajectories shows why: agents often reach a relevant web source, but establish the wrong site-specific retrieval state. Retrieval-scope drift (37.2%) and criterion mismatch (27.6%) dominate, whereas final answer composition accounts for only 10.3%. The dataset and single-case evaluation instructions are available at https://huggingface.co/datasets/PKUAIWeb/SGR-BENCH.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SGR-Bench, a benchmark for state-gated retrieval (SGR) on specialized websites where evidence is accessible only after configuring site-specific states via filters, views, hierarchies or scopes. It contains 100 expert-curated tasks across six source families and 12 ecosystems, with paired constraint-guided and goal-oriented formulations. Eight CLI-based LLM agents and three commercial products are evaluated; the strongest reaches 66.18% item-level F1 while row-level F1 is substantially lower. A manual audit of 156 failed trajectories attributes most errors to retrieval-scope drift (37.2%) and criterion mismatch (27.6%), with answer composition at only 10.3%. The dataset is released publicly.
Significance. If the tasks and metrics validly isolate state configuration, the work identifies a concrete, previously under-characterized limitation in web agents and supplies reproducible evidence plus failure-mode statistics that can guide targeted improvements. Public dataset release is a clear strength for the field.
major comments (2)
- [Task Curation and Evaluation Setup] The central empirical claim—that current agents struggle with state-gated retrieval rather than benchmark-specific artifacts—depends on the 100 tasks adequately sampling state mechanisms across the six families and 12 ecosystems and on the F1 metrics isolating state-setting success. The manuscript provides no coverage statistics, selection criteria, or validation that answers are inaccessible under incorrect states (see abstract and §3).
- [Results] Table or figure reporting per-ecosystem or per-state-type performance is absent; without it, the aggregate 66.18% item-level F1 cannot be assessed for whether failures concentrate on particular state types or are uniformly distributed.
minor comments (2)
- [Evaluation Metrics] Clarify the exact definition of 'item-level F1' versus 'row-level F1' with a short example in the metrics subsection; the distinction is central to interpreting the gap between the two scores.
- [Failure Analysis] The audit sample of 156 trajectories should state the total number of failures and the selection procedure to allow readers to judge representativeness.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify how to strengthen the presentation of SGR-Bench. We respond to each major comment below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [Task Curation and Evaluation Setup] The central empirical claim—that current agents struggle with state-gated retrieval rather than benchmark-specific artifacts—depends on the 100 tasks adequately sampling state mechanisms across the six families and 12 ecosystems and on the F1 metrics isolating state-setting success. The manuscript provides no coverage statistics, selection criteria, or validation that answers are inaccessible under incorrect states (see abstract and §3).
Authors: We agree that explicit documentation of curation details would improve transparency and help readers assess sampling adequacy. In the revised manuscript we will expand §3 with (i) a table or paragraph reporting the distribution of the 100 tasks across the six source families and 12 ecosystems and (ii) a concise description of the expert curation protocol and selection criteria. We will also add a short validation statement confirming that, for each task, the expert curators verified that the target evidence is inaccessible under incorrect state configurations; this directly supports the claim that the reported F1 scores isolate state-setting success rather than benchmark artifacts. revision: yes
-
Referee: [Results] Table or figure reporting per-ecosystem or per-state-type performance is absent; without it, the aggregate 66.18% item-level F1 cannot be assessed for whether failures concentrate on particular state types or are uniformly distributed.
Authors: We acknowledge that aggregate metrics alone limit interpretability. We will add a new table (or supplementary figure) in the results section that reports item-level F1 broken down by ecosystem and by state mechanism type (filters, views, hierarchies, scopes). This disaggregation will allow readers to determine whether the observed performance is uniform or driven by particular state types. revision: yes
Circularity Check
Empirical benchmark paper with no derivations or fitted predictions
full rationale
This is a benchmark introduction and evaluation paper. It defines state-gated retrieval, curates 100 tasks across source families, evaluates agent systems on item/row-level F1, and audits failure modes. No equations, no parameter fitting, no predictions derived from inputs, and no self-citation chains that support the central claims. Performance numbers are measured outcomes on held-out tasks rather than being defined in terms of the evaluation itself, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-curated tasks across six source families adequately represent state-gated retrieval in public data ecosystems.
invented entities (1)
-
state-gated retrieval (SGR)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We term this capability state-gated retrieval (SGR). We introduce SGR-Bench, a benchmark for this setting containing 100 expert-curated tasks...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Retrieval-scope drift (37.2%) and criterion mismatch (27.6%) dominate
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic. Claude Code Overview. https://code.claude.com/docs/en/overview, 2026. Accessed: 2026-05-06
work page 2026
-
[2]
Anthropic. System Card: Claude Opus 4.7. https://www.anthropic.com/ claude-opus-4-7-system-card, apr 2026. Accessed: 2026-05-06
work page 2026
-
[3]
Léo Boisvert, Megh Thakkar, Maxime Gasse, Massimo Caccia, Thibault Le Sellier de Chezelles, Quentin Cappart, Nicolas Chapados, Alexandre Lacoste, and Alexandre Drouin. Workarena++: Towards compositional planning and reasoning-based common knowledge work tasks.Advances in Neural Information Processing Systems, 37:5996–6051, 2024
work page 2024
-
[4]
Seed2.0 Model Card: Towards Intelligence Frontier for Real- World Complexity
ByteDance Seed. Seed2.0 Model Card: Towards Intelligence Frontier for Real- World Complexity. https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0%20Model%20Card.pdf, feb 2026. Accessed: 2026-05-06
work page 2026
-
[5]
Thibault Le Sellier de Chezelles, Maxime Gasse, Alexandre Drouin, Massimo Caccia, Léo Boisvert, Megh Thakkar, Tom Marty, Rim Assouel, Sahar Omidi Shayegan, Lawrence Keunho Jang, Xing Han Lù, Ori Yoran, Dehan Kong, Frank F. Xu, Siva Reddy, Quentin Cappart, Graham Neubig, Ruslan Salakhutdinov, Nicolas Chapados, and Alexandre Lacoste. The browsergym ecosyste...
work page 2024
-
[6]
DeepSeek V4 Technical Documentation
DeepSeek-AI. DeepSeek V4 Technical Documentation. https://fe-static.deepseek.com/ chat/transparency/deepseek-V4-model-card-EN.pdf, apr 2026. Accessed: 2026-05-06
work page 2026
-
[7]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
work page 2023
-
[8]
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. Workarena: How capable are web agents at solving common knowledge work tasks? 2024
work page 2024
-
[9]
Deepresearch bench: A comprehensive benchmark for deep research agents, 2025
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench: A comprehensive benchmark for deep research agents, 2025
work page 2025
-
[10]
REAL: Benchmarking autonomous agents on deterministic simulations of real websites
Divyansh Garg, Shaun VanWeelden, Diego Caples, Andis Draguns, Nikil Ravi, Pranav Putta, Naman Garg, Tomas Abraham, Michael Lara, Federico Lopez, James Liu, Atharva Gundawar, Prannay Hebbar, Youngchul Joo, Jindong Gu, Charles London, Christian Schroeder de Witt, and Sumeet Motwani. REAL: Benchmarking autonomous agents on deterministic simulations of real w...
work page 2025
-
[11]
Glm-5: from vibe coding to agentic engineering, 2026
GLM-5-Team, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, Chenzheng Zhu, Congfeng Yin, Cunx- iang Wang, Gengzheng Pan, Hao Zeng, Haoke Zhang, Haoran Wang, Huilong Chen, Jiajie Zhang, Jian Jiao, Jiaqi Guo, Jingsen Wang, Jingzhao Du, Jinzhu Wu, Kedong Wang, Lei Li, Lin Fan, Lucen Zhon...
work page 2026
-
[12]
Expanding AI Overviews and Introducing AI Mode
Google. Expanding AI Overviews and Introducing AI Mode. https://blog.google/ products-and-platforms/products/search/ai-mode-search/ , mar 2025. Accessed: 2026-05-06
work page 2025
-
[13]
Google. Gemini Deep Research. https://gemini.google/overview/deep-research/?hl= en-US, 2026. Accessed: 2026-05-06
work page 2026
-
[14]
Model Evaluation – Approach, Methodology & Results: Gemini 3.1 Pro
Google DeepMind. Model Evaluation – Approach, Methodology & Results: Gemini 3.1 Pro. https://storage.googleapis.com/deepmind-media/gemini/gemini_3-1_pro_ model_evaluation.pdf, feb 2026. Accessed: 2026-05-06
work page 2026
-
[15]
Nikita Gupta, Riju Chatterjee, Lukas Haas, Connie Tao, Andrew Wang, Chang Liu, Hidekazu Oiwa, E. Gribovskaya, Jan Ackermann, John Blitzer, S. Goldshtein, and Dipanjan Das. Deepsearchqa: Bridging the comprehensiveness gap for deep research agents.arXiv preprint arXiv:2601.20975, 2026
-
[16]
Webvoyager: Building an end-to-end web agent with large multimodal models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6864–6890, Bangkok, Thailand, 2024. Association for Computa...
work page 2024
-
[17]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017
work page 2017
-
[18]
A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
Maurice G Kendall. A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
work page 1938
-
[19]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 881–905, 2024
work page 2024
- [20]
-
[21]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
work page 2019
-
[22]
Tian Lan, Bin Zhu, Qianghuai Jia, Junyang Ren, Haijun Li, Longyue Wang, Zhao Xu, Weihua Luo, and Kaifu Zhang. Deepwidesearch: Benchmarking depth and width in agentic information seeking.arXiv preprint arXiv:2510.20168, 2025
-
[23]
Deepresearch bench ii: Diagnosing deep research agents via rubrics from expert report, 2026
Ruizhe Li, Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench ii: Diagnosing deep research agents via rubrics from expert report, 2026. 11
work page 2026
-
[24]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[25]
Webgpt: Browser-assisted question-answering with human feedback, 2022
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback, 2022
work page 2022
-
[26]
OpenAI. Deep Research System Card. https://cdn.openai.com/ deep-research-system-card.pdf, feb 2025. Accessed: 2026-05-06
work page 2025
-
[27]
OpenAI. CLI – Codex. https://developers.openai.com/codex/cli, 2026. Accessed: 2026-05-06
work page 2026
-
[28]
OpenRouter. OpenRouter Models. https://openrouter.ai/docs/guides/overview/ models, 2026. Accessed: 2026-05-06
work page 2026
-
[29]
Kilt: a benchmark for knowledge intensive language tasks
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vassilis Plachouras, Tim Rocktäschel, and Sebastian Riedel. Kilt: a benchmark for knowledge intensive language tasks. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: H...
work page 2021
-
[30]
Weblinx: Real-world website navigation with multi-turn dialogue
Siva Reddy, Xing Lu, and Zden ˇek Kasner. Weblinx: Real-world website navigation with multi-turn dialogue. InInstitute of Formal and Applied Linguistics (ÚFAL), 2024
work page 2024
-
[31]
Toolformer: Language models can teach themselves to use tools, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023
work page 2023
-
[32]
World of bits: An open-domain platform for web-based agents
Tianlin Shi, Andrej Karpathy, Linxi Fan, Jonathan Hernandez, and Percy Liang. World of bits: An open-domain platform for web-based agents. InInternational Conference on Machine Learning, pages 3135–3144. PMLR, 2017
work page 2017
-
[33]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page 2026
-
[34]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y . Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kefan Chen, Liang Chen, Ruijue Chen, Xinhao Chen, Yanru Chen, Yanxu Chen, Yicun Chen, Yimin Chen, Yingjiang Chen, Yuankun Chen, Yujie Chen, Yutian Chen, Zhirong Chen, Ziwei Che...
work page 2026
-
[35]
Safearena: Evaluating the safety of autonomous web agents
Ada Defne Tur, Nicholas Meade, Xing Han Lù, Alejandra Zambrano, Arkil Patel, Esin DUR- MUS, Spandana Gella, Karolina Stanczak, and Siva Reddy. Safearena: Evaluating the safety of autonomous web agents. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[36]
Wei, Jason Wei, Chris Tar, Yun- Hsuan Sung, Denny Zhou, Quoc V
Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry W. Wei, Jason Wei, Chris Tar, Yun- Hsuan Sung, Denny Zhou, Quoc V . Le, and Thang Luong. Freshllms: Refreshing large language models with search engine augmentation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13697–13720, 2024
work page 2024
-
[37]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Widesearch: Benchmarking agentic broad info-seeking.arXiv preprint arXiv:2508.07999, 2025
Ryan Wong, Jiawei Wang, Junjie Zhao, Li Chen, Yan Gao, Long Zhang, Xuan Zhou, Zuo Wang, Kai Xiang, Ge Zhang, Wenhao Huang, Yang Wang, and Ke Wang. Widesearch: Benchmarking agentic broad info-seeking.arXiv preprint arXiv:2508.07999, 2025
-
[39]
Webwalker: Benchmarking llms in web 14 traversal
Jialong Wu, Wenbiao Yin, Yong Jiang, Zhenglin Wang, Zekun Xi, Runnan Fang, Linhai Zhang, Yulan He, Deyu Zhou, Pengjun Xie, and Fei Huang. Webwalker: Benchmarking llms in web 14 traversal. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10290–10305, 2025
work page 2025
-
[40]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page 2025
-
[41]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
work page 2022
-
[42]
React: Synergizing reasoning and acting in language models, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023
work page 2023
-
[43]
Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, and Jonathan Berant. Assistantbench: Can web agents solve realistic and time-consuming tasks? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8938–8968, 2024
work page 2024
-
[44]
Draco: a cross-domain benchmark for deep research accuracy, completeness, and objectivity, 2026
Joey Zhong, Hao Zhang, Clare Southern, Jeremy Yang, Thomas Wang, Kate Jung, Shu Zhang, Denis Yarats, Johnny Ho, and Jerry Ma. Draco: a cross-domain benchmark for deep research accuracy, completeness, and objectivity, 2026
work page 2026
-
[45]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, 2023. A Metric Definitions All metrics are computed after rev...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.