The Role of Input Dimensionality in the Emergence and Targeted Control of Adversarial Examples
Pith reviewed 2026-06-26 01:07 UTC · model grok-4.3
The pith
High input dimensionality is a fundamental factor underlying the emergence and targeted control of adversarial examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
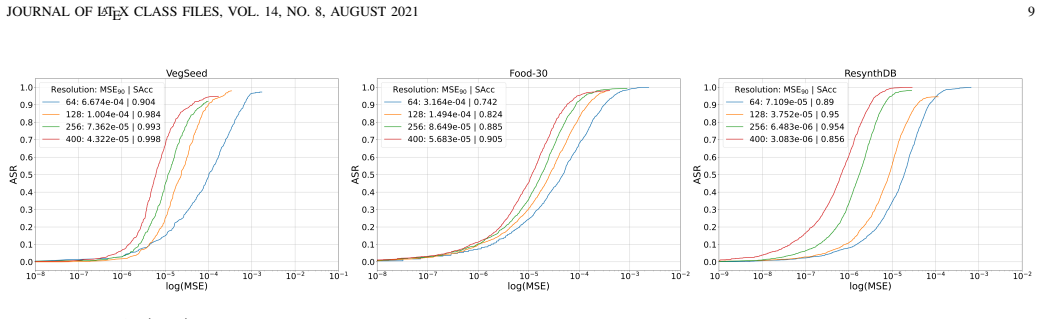
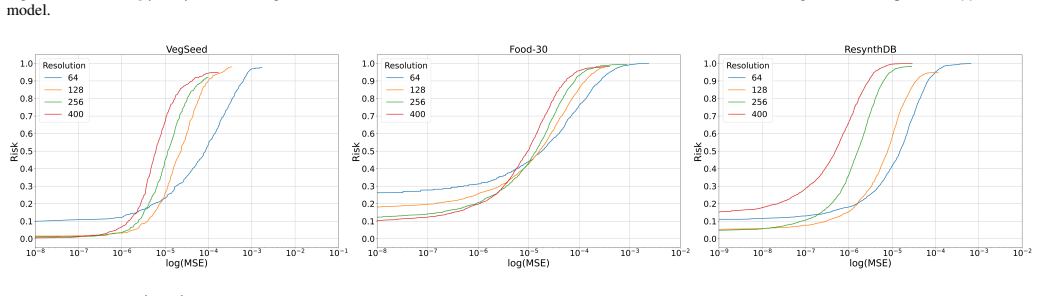
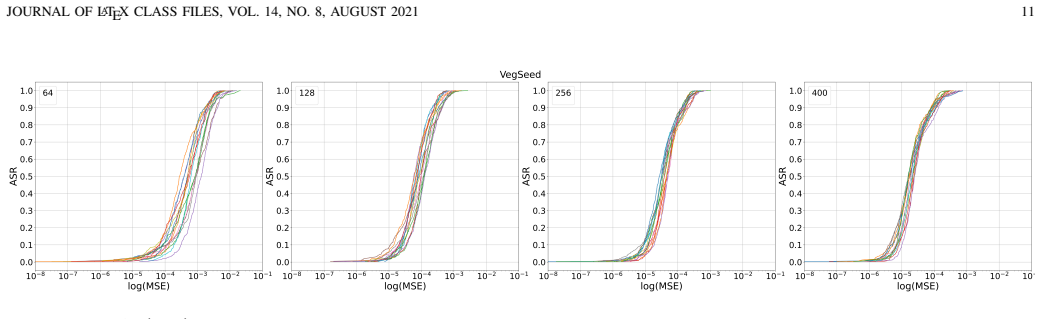
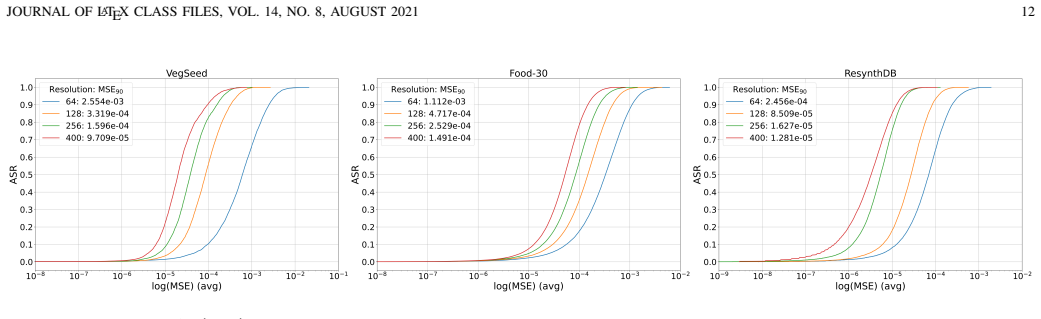
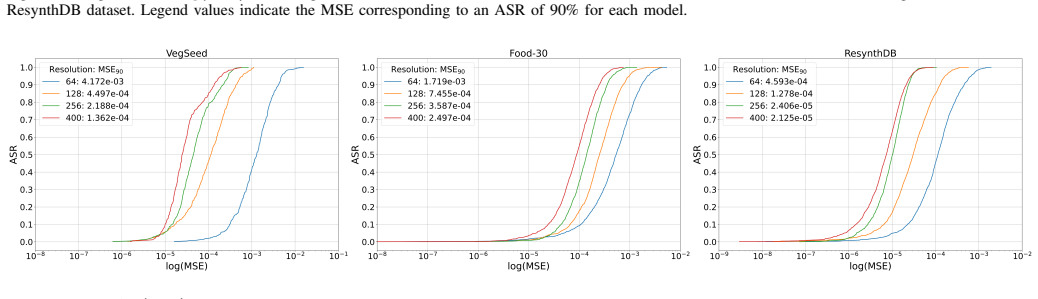
The paper establishes high input dimensionality as a fundamental factor underlying the emergence and targeted control of adversarial examples. Theoretical arguments indicate that high-dimensional geometry implies only limited additional distortion when enforcing a specific target label compared with untargeted attacks. Extensive experiments across datasets spanning wide ranges of input dimensionality and across diverse architectures corroborate that adversarial examples are easier to construct at higher dimensionality and that the targeted-untargeted gap narrows as dimensionality increases.
What carries the argument
Input dimensionality, defined as the number of coordinates in the input vector, which governs how readily small perturbations can cross decision boundaries under high-dimensional geometry.
If this is right
- Adversarial examples become easier to construct as input dimensionality increases.
- The additional distortion needed to reach a chosen target label rather than any wrong label remains small and decreases with rising dimensionality.
- High-dimensional geometry accounts for why targeted attacks require only limited extra cost compared with untargeted ones.
- The observed effects hold across multiple neural architectures and hierarchical image datasets.
Where Pith is reading between the lines
- Dimensionality-reduction preprocessing might reduce vulnerability if the geometric mechanism dominates.
- Similar dimensionality effects could appear in non-image domains such as audio or sensor data.
- Architectural defenses may need to be evaluated separately at different input dimensionalities to isolate geometry from model-specific factors.
Load-bearing premise
The hierarchical image datasets vary input dimensionality without other differences in class structure, label noise, or dataset properties that could independently change attack success rates.
What would settle it
A dataset or architecture in which adversarial examples do not become easier to generate and the targeted-untargeted distortion gap does not shrink as input dimensionality increases would contradict the central claim.
Figures

read the original abstract
Several theoretical works have tried to explain the adversarial vulnerability of deep neural networks through properties of high-dimensional geometry. However, the assumptions underlying these works are rarely examined empirically, and systematic evidence remains limited. In this work, we present a systematic study of the role of input dimensionality in both the emergence and the targeted control of adversarial examples. We first analyse the scope and limitations of existing theoretical frameworks based on concentration of measure, showing that real image classes exhibit strong empirical localization, beyond what such theories typically assume. We then conduct an extensive empirical evaluation across hierarchical image datasets spanning a wide range of input dimensionalities and diverse neural architectures. Our results consistently show that adversarial examples become easier to construct as dimensionality increases. We also investigate how input dimensionality affects the additional difficulty of crafting targeted adversarial examples. In particular, we provide theoretical arguments showing that high-dimensional geometry implies that enforcing a specific target label entails only a limited additional distortion compared to untargeted attacks. We corroborate this insight through extensive experiments, demonstrating that the gap between targeted and untargeted perturbations remains small and further narrows as input dimensionality increases. While, taken together, our findings establish high input dimensionality as a fundamental factor underlying the emergence and targeted control of adversarial examples, whether this phenomenon primarily arises from the interplay between high-dimensional geometry and data distributions or from the architectural properties of deep neural networks remains an open question.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that high input dimensionality is a fundamental factor underlying both the emergence of adversarial examples and the relative ease of targeted attacks. It first shows that real image classes exhibit stronger localization than assumed by concentration-of-measure theories, then reports consistent empirical trends across hierarchical image datasets and architectures: adversarial examples become easier to construct and the targeted-untargeted distortion gap narrows as dimensionality increases. Theoretical arguments are offered for why high-dimensional geometry implies only limited extra cost for targeting. The authors leave open whether the driver is geometry plus data distribution or network architecture.
Significance. If the attribution to dimensionality survives controls for confounding dataset properties, the work would supply useful empirical grounding for geometric accounts of adversarial vulnerability and indicate that high-dimensional inputs inherently facilitate both untargeted and targeted attacks. The cross-architecture consistency is a positive feature. The explicit open question on geometry versus architecture, however, limits how definitive the 'fundamental factor' conclusion can be.
major comments (2)
- [Abstract, paragraph on empirical evaluation] Abstract, paragraph on empirical evaluation: the hierarchical image datasets are used to vary input dimensionality, yet no evidence is provided that class count, label noise, or intra-class variability are held fixed across the hierarchy; any correlation between these factors and dimensionality would make the reported trends non-causal for the claimed fundamental role of dimensionality.
- [theoretical argument] Abstract and theoretical argument section: the claim that high-dimensional geometry implies only limited additional distortion for targeted attacks is presented as supporting the central thesis, but it is not shown how this geometric implication survives the paper's own finding of strong empirical localization beyond typical concentration-of-measure assumptions.
minor comments (1)
- [Abstract] The abstract's phrasing that the findings 'establish high input dimensionality as a fundamental factor' sits in tension with the immediately following open question; a minor rewording would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important considerations for strengthening the causal claims and ensuring consistency between empirical and theoretical components. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract, paragraph on empirical evaluation] Abstract, paragraph on empirical evaluation: the hierarchical image datasets are used to vary input dimensionality, yet no evidence is provided that class count, label noise, or intra-class variability are held fixed across the hierarchy; any correlation between these factors and dimensionality would make the reported trends non-causal for the claimed fundamental role of dimensionality.
Authors: We agree that explicit controls or measurements of these factors would strengthen the attribution to dimensionality. The hierarchical datasets were constructed to vary input dimensionality while preserving core data characteristics from the same source distributions. In the revised version we will add a dedicated analysis quantifying class count, label noise, and intra-class variability across hierarchy levels, along with a discussion of any observed correlations and their potential influence on the trends. revision: yes
-
Referee: [theoretical argument] Abstract and theoretical argument section: the claim that high-dimensional geometry implies only limited additional distortion for targeted attacks is presented as supporting the central thesis, but it is not shown how this geometric implication survives the paper's own finding of strong empirical localization beyond typical concentration-of-measure assumptions.
Authors: The localization result is presented to delineate the limitations of standard concentration-of-measure arguments that assume diffuse class support. The targeted-attack cost analysis instead rests on separate high-dimensional geometric properties (e.g., the measure of directions orthogonal to the decision boundary and the relative volume of target-class regions). These properties are compatible with localized classes. We will revise the theoretical section to make this distinction explicit and show that the limited-extra-cost claim does not depend on the concentration assumptions that our empirical analysis shows are violated. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims rest on direct empirical measurements of adversarial-example success rates across hierarchical image datasets of varying dimensionality, plus separate theoretical arguments drawn from high-dimensional geometry (concentration of measure). No equations, fitted parameters, or self-citations are presented that reduce the reported trends or targeted/untargeted gaps to quantities defined or fitted from the same experimental data. The derivation chain is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Concentration of measure phenomena govern the geometry of high-dimensional image manifolds in the manner assumed by existing theoretical frameworks.
Reference graph
Works this paper leans on
-
[1]
Intriguing properties of neural networks,
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,”arXiv preprint arXiv:1312.6199, 2013
Pith/arXiv arXiv 2013
-
[2]
The concentration of measure phenomenon,
M. Ledoux, “The concentration of measure phenomenon,”American Mathematical Soc., vol. Number 89, 2001
2001
-
[3]
Analysis of classifiers’ robustness to adversarial perturbations,
A. Fawzi, O. Fawzi, and P. Frossard, “Analysis of classifiers’ robustness to adversarial perturbations,”Machine learning, vol. 107, no. 3, pp. 481– 508, 2018
2018
-
[4]
Are adversarial examples inevitable?
A. Shafahi, W. R. Huang, C. Studer, S. Feizi, and T. Goldstein, “Are adversarial examples inevitable?” inInternational Conference on Learning Representations (ICLR), vol. 11, 2019, pp. 8324–8340
2019
-
[5]
The curse of concentration in robust learning: Evasion and poisoning attacks from concentration of measure,
S. Mahloujifar, D. I. Diochnos, and M. Mahmoody, “The curse of concentration in robust learning: Evasion and poisoning attacks from concentration of measure,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 4536–4543
2019
-
[6]
J. Gilmer, L. Metz, F. Faghri, S. S. Schoenholz, M. Raghu, M. Wat- tenberg, and I. Goodfellow, “Adversarial spheres,”arXiv preprint arXiv:1801.02774, 2018
Pith/arXiv arXiv 2018
-
[7]
Adversarial examples are a natural consequence of test error in noise,
J. Gilmer, N. Ford, N. Carlini, and E. Cubuk, “Adversarial examples are a natural consequence of test error in noise,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 2280–2289
2019
-
[8]
Generalized no free lunch theorem for adversarial robustness,
E. Dohmatob, “Generalized no free lunch theorem for adversarial robustness,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 1646–1654
2019
-
[9]
Adversarial robustness guarantees for random deep neural networks,
G. De Palma, B. Kiani, and S. Lloyd, “Adversarial robustness guarantees for random deep neural networks,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 2522–2534
2021
-
[10]
Adversarial examples might be avoid- able: The role of data concentration in adversarial robustness,
A. Pal, J. Sulam, and R. Vidal, “Adversarial examples might be avoid- able: The role of data concentration in adversarial robustness,”Advances in Neural Information Processing Systems, vol. 36, pp. 46 989–47 015, 2023
2023
-
[11]
Adversarial vulnerability for any classifier,
A. Fawzi, H. Fawzi, and O. Fawzi, “Adversarial vulnerability for any classifier,” inAdvances in neural information processing systems, 31 (Neurips 2018), 2018
2018
-
[12]
Adversarial risk and robustness: General definitions and implications for the uniform distri- bution,
D. Diochnos, S. Mahloujifar, and M. Mahmoody, “Adversarial risk and robustness: General definitions and implications for the uniform distri- bution,”Advances in Neural Information Processing Systems, vol. 31, 2018
2018
-
[13]
Empirically measuring concentration: Fundamental limits on intrinsic robustness,
S. Mahloujifar, X. Zhang, M. Mahmoody, and D. Evans, “Empirically measuring concentration: Fundamental limits on intrinsic robustness,” Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[14]
Improved estimation of concentra- tion underell p-norm distance metrics using half spaces,
J. Prescott, X. Zhang, and D. Evans, “Improved estimation of concentra- tion underell p-norm distance metrics using half spaces,”arXiv preprint arXiv:2103.12913, 2021
arXiv 2021
-
[15]
Incorporating label uncertainty in un- derstanding adversarial robustness
X. Zhang and D. D. Evans, “Incorporating label uncertainty in un- derstanding adversarial robustness.” inInternational Conference on Learning Representations (ICLR), vol. 2022, 2022
2022
-
[16]
Towards evaluating the robustness of neural networks,
N. Carlini and D. Wagner, “Towards evaluating the robustness of neural networks,” inProceedings of the IEEE Symposium on Security and Privacy, 2017, pp. 39–57
2017
-
[17]
Reliable evaluation of adversarial robustness with an ensemble of diverse attacks,
F. Croce and M. Hein, “Reliable evaluation of adversarial robustness with an ensemble of diverse attacks,” inInternational Conference on Machine Learning (ICML), 2020
2020
-
[18]
Targeted mismatch adversarial attack: Query with a flower to retrieve the tower,
G. Tolias, F. Radenovi ´c, and O. Chum, “Targeted mismatch adversarial attack: Query with a flower to retrieve the tower,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 5037–5046
2019
-
[19]
Boosting adversarial attacks with momentum,
Y . Dong, F. Liao, T. Pang, H. Su, J. Zhu, X. Hu, and J. Li, “Boosting adversarial attacks with momentum,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2018, pp. 9185–9193
2018
-
[20]
Threat of adversarial attacks on deep learning in computer vision: A survey,
N. Akhtar and A. Mian, “Threat of adversarial attacks on deep learning in computer vision: A survey,”Ieee Access, vol. 6, pp. 14 410–14 430, 2018
2018
-
[21]
Veg- SeedsBD: A comprehensive image dataset of vegetable seeds,
M. H. Ferdaus, S. R. A. Ohona, R. H. Prito, and M. Ahmed, “Veg- SeedsBD: A comprehensive image dataset of vegetable seeds,” 2025. [Online]. Available: https://data.mendeley.com/datasets/dtpzbwwpm7/1
2025
-
[22]
Food-101 – mining dis- criminative components with random forests,
L. Bossard, M. Guillaumin, and L. Van Gool, “Food-101 – mining dis- criminative components with random forests,” inEuropean Conference on Computer Vision, 2014
2014
-
[23]
Training- free source attribution of ai-generated images via resynthesis,
P. Bongini, V . Molinari, A. Costanzo, B. Tondi, and M. Barni, “Training- free source attribution of ai-generated images via resynthesis,” in2025 IEEE International Workshop on Information Forensics and Security (WIFS), 2025
2025
-
[24]
Searching for mobilenetv3,
A. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y . Zhu, R. Pang, V . Vasudevanet al., “Searching for mobilenetv3,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1314–1324
2019
-
[25]
Efficientnet: Rethinking model scaling for con- volutional neural networks,
M. Tan and Q. Le, “Efficientnet: Rethinking model scaling for con- volutional neural networks,” inInternational conference on machine learning. PMLR, 2019, pp. 6105–6114
2019
-
[26]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[27]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[28]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248–255
2009
-
[29]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,”arXiv preprint arXiv:1706.06083, 2017
Pith/arXiv arXiv 2017
-
[30]
W. Zuo, K. Zhang, and L. Zhang,Convolutional Neural Networks for Image Denoising and Restoration. Cham: Springer International Publishing, 2018, pp. 93–123. [Online]. Available: https://doi.org/10. 1007/978-3-319-96029-6 4
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.