Concept Flow Models: Anchoring Concept-Based Reasoning with Hierarchical Bottlenecks
Pith reviewed 2026-06-26 21:14 UTC · model grok-4.3
The pith
Concept Flow Models replace flat bottlenecks with hierarchical decision trees to reduce information leakage in concept-based models while matching accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
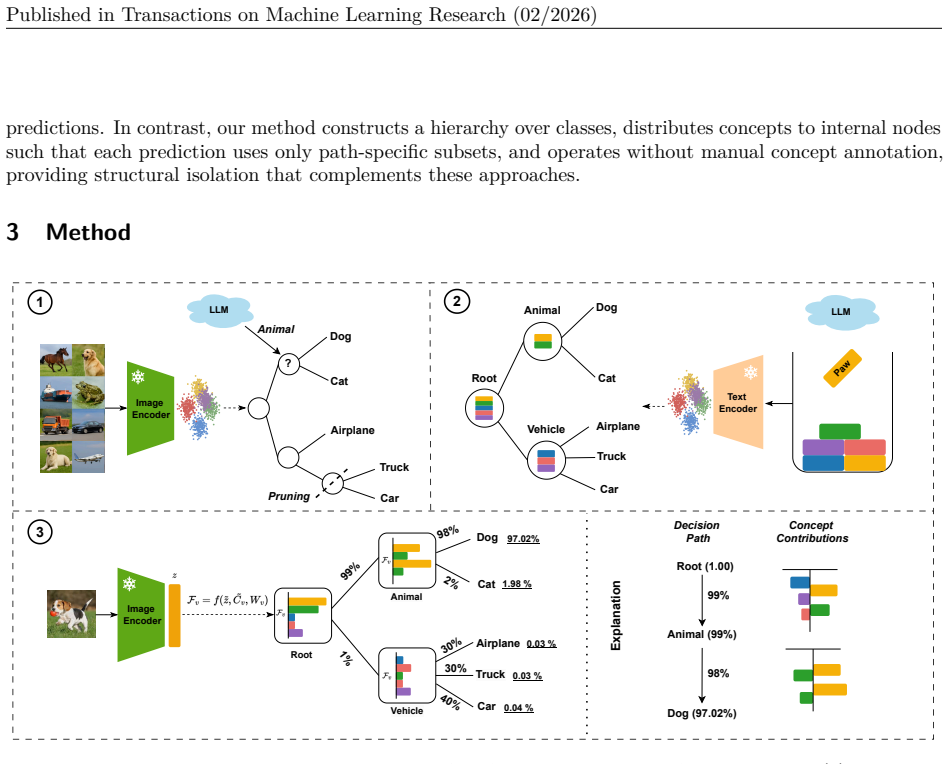
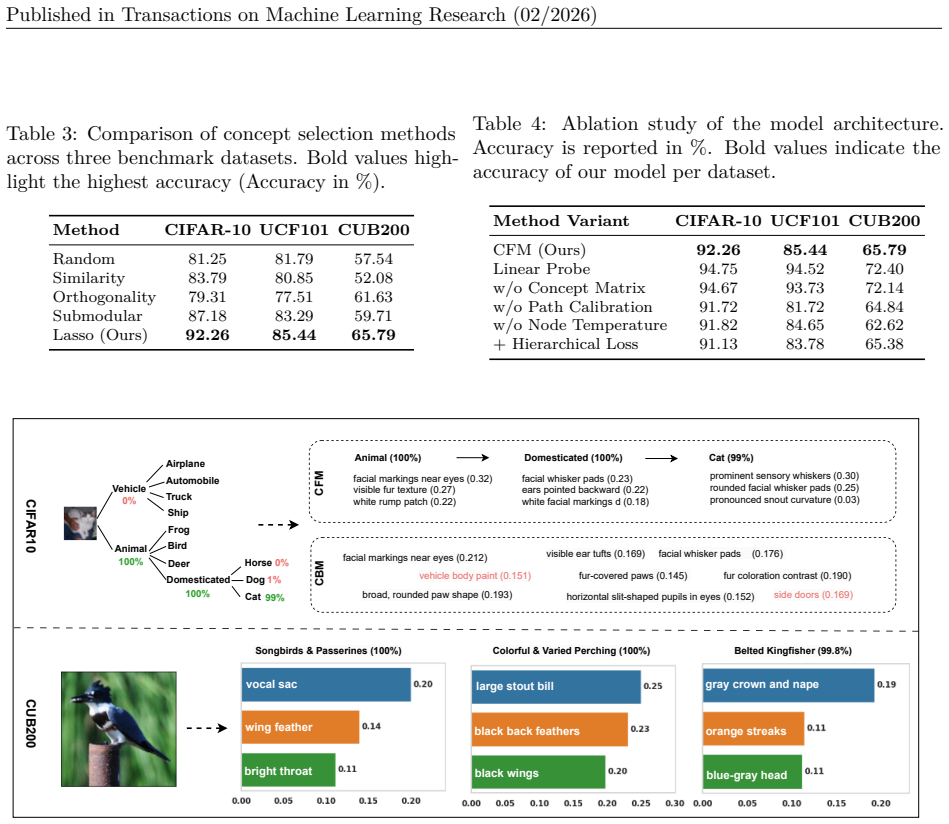
Concept Flow Models replace the flat bottleneck with a hierarchical, concept-driven decision tree constructed from visual embeddings; each internal node focuses on a localized subset of discriminative concepts, semantic concepts are distributed across levels, and differentiable concept weights are trained through probabilistic tree traversal, yielding predictive performance equal to flat CBMs while substantially reducing effective concept usage and information leakage.
What carries the argument
A hierarchical concept-driven decision tree that distributes semantic concepts across levels and performs probabilistic traversal to localize concept usage.
If this is right
- CFMs produce explicit stepwise decision flows that make model reasoning transparent and auditable.
- The hierarchical structure aligns naturally with datasets that have class taxonomies.
- Training remains end-to-end because concept weights are learned via differentiable probabilistic traversal.
- Information leakage is mitigated because each prediction path activates only a small subset of concepts.
Where Pith is reading between the lines
- The same hierarchy construction might be tested on non-vision tasks where embeddings already carry partial semantic structure.
- If the tree depth is chosen automatically from embedding geometry, the method could become parameter-light across domains.
- Auditable paths could support human-in-the-loop correction at specific tree nodes rather than the full model.
Load-bearing premise
A decision tree built from visual embeddings can assign concepts to levels so that effective usage drops without any loss in the ability to separate classes.
What would settle it
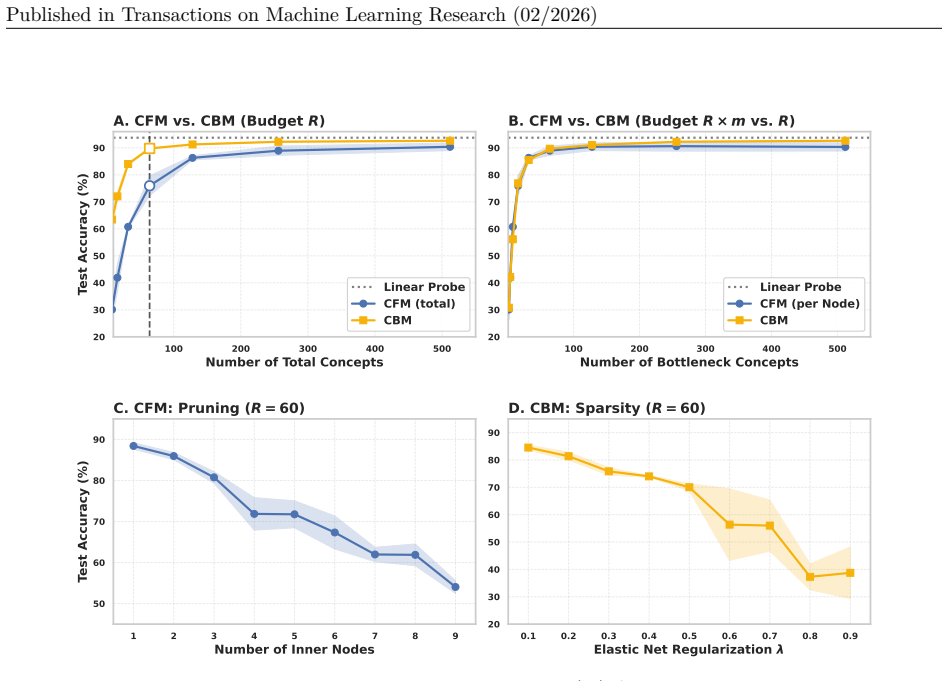
On the same benchmarks, measure effective concept usage and accuracy for CFMs versus flat CBMs; if CFMs show equal or higher leakage or lower accuracy, the central claim does not hold.
Figures

read the original abstract
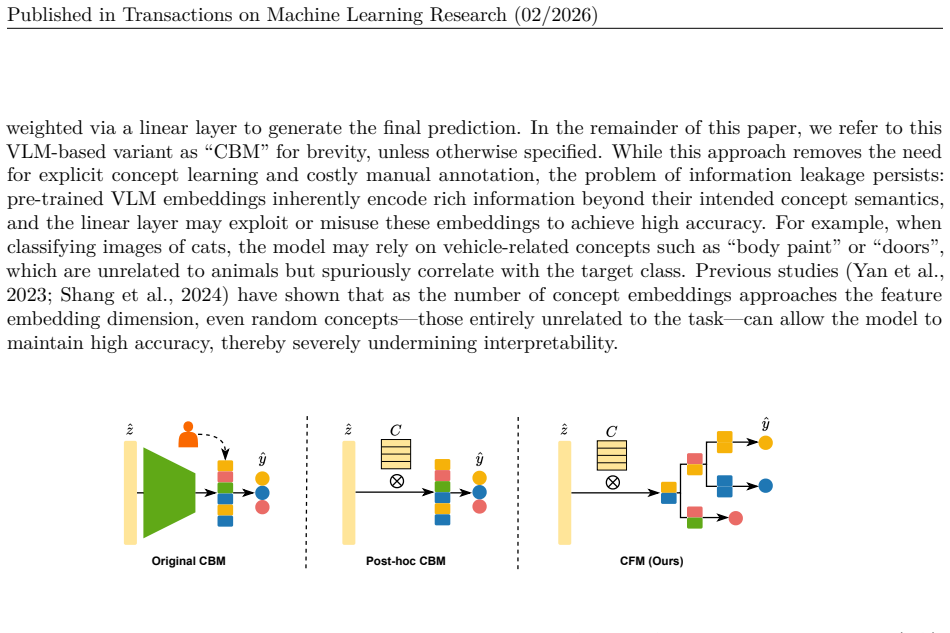
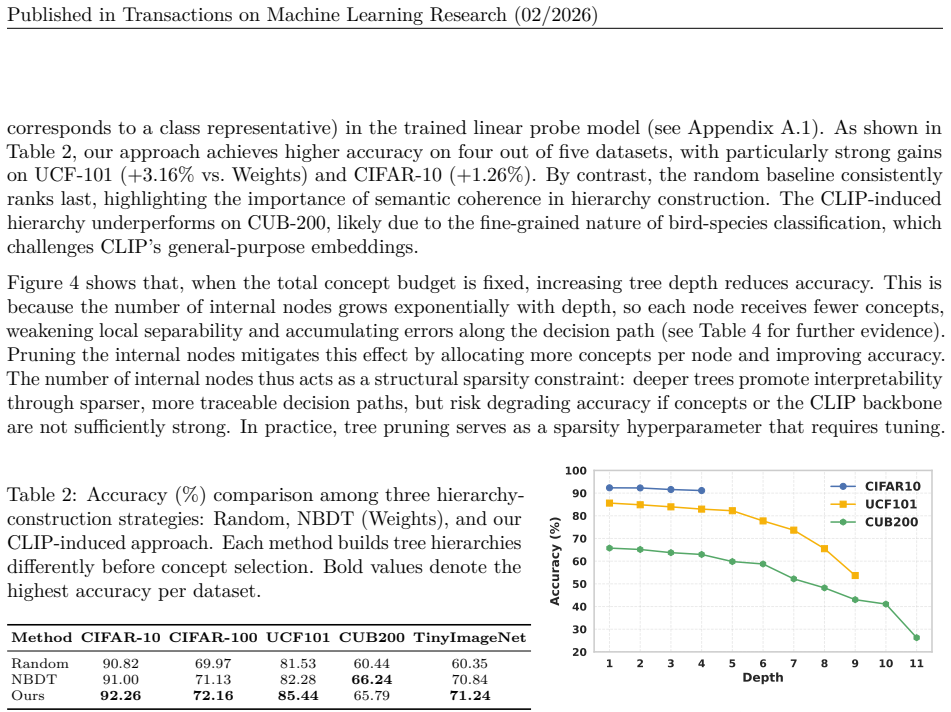
Concept Bottleneck Models (CBMs) enhance interpretability by projecting learned features into a human-understandable concept space. Recent approaches leverage vision-language models to generate concept embeddings, reducing the need for manual concept annotations. However, these models suffer from a critical limitation: as the number of concepts approaches the embedding dimension, information leakage increases, enabling the model to exploit spurious or semantically irrelevant correlations and undermining interpretability. In this work, we propose Concept Flow Models (CFMs), which replace the flat bottleneck with a hierarchical, concept-driven decision tree. Each internal node in the hierarchy focuses on a localized subset of discriminative concepts, progressively narrowing the prediction scope. Our framework constructs decision hierarchies from visual embeddings, distributes semantic concepts at each hierarchy level, and trains differentiable concept weights through probabilistic tree traversal. Extensive experiments on diverse benchmarks demonstrate that CFMs match the predictive performance of flat CBMs, while substantially mitigating information leakage by reducing effective concept usage. Furthermore, CFMs yield stepwise decision flows that enable transparent and auditable model reasoning with hierarchical class structures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Concept Flow Models (CFMs) to address information leakage in Concept Bottleneck Models (CBMs). It replaces the flat bottleneck with a hierarchical concept-driven decision tree constructed from visual embeddings; concepts are localized to nodes, and probabilistic traversal yields differentiable weights. The central claim is that CFMs match flat CBM predictive performance while reducing effective concept usage (thereby mitigating leakage) and yield interpretable stepwise decision flows with hierarchical class structure. Experiments on diverse benchmarks are cited in support.
Significance. If the empirical claims hold, the hierarchical bottleneck offers a concrete mechanism to cap active concepts per path and thereby limit leakage without accuracy loss, which directly targets a known weakness of flat CBMs. The added stepwise flows could improve auditability. The construction appears independent of prior fitted quantities and therefore avoids obvious circularity.
major comments (2)
- [Abstract] Abstract: the assertion that 'CFMs match the predictive performance of flat CBMs, while substantially mitigating information leakage by reducing effective concept usage' supplies no metrics, baselines, datasets, or description of how leakage was quantified. This is load-bearing for the central empirical claim and prevents verification of soundness.
- [Abstract] Abstract: no equations, algorithm, or pseudocode describe the construction of the decision hierarchy from visual embeddings, the per-node concept distribution, or the probabilistic traversal. Without these details the mechanism that is supposed to reduce effective concept usage cannot be evaluated.
minor comments (1)
- The abstract refers to 'diverse benchmarks' and 'extensive experiments' without naming the datasets or reporting any quantitative results; adding these would allow readers to assess scope.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We agree that the abstract requires strengthening to better support the central claims and will revise it in the next version. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'CFMs match the predictive performance of flat CBMs, while substantially mitigating information leakage by reducing effective concept usage' supplies no metrics, baselines, datasets, or description of how leakage was quantified. This is load-bearing for the central empirical claim and prevents verification of soundness.
Authors: We agree the abstract should supply concrete support for this claim. In the revision we will add specific quantitative results (e.g., accuracy on CUB-200 and AWA2, effective concept usage per path, and the leakage metric based on concept-path sparsity) together with the main baselines and datasets used. revision: yes
-
Referee: [Abstract] Abstract: no equations, algorithm, or pseudocode describe the construction of the decision hierarchy from visual embeddings, the per-node concept distribution, or the probabilistic traversal. Without these details the mechanism that is supposed to reduce effective concept usage cannot be evaluated.
Authors: Abstracts conventionally omit equations and pseudocode due to length limits; the full construction, per-node distributions, and differentiable traversal are detailed in Sections 3.1–3.2 with Algorithm 1. To address the concern we will insert a single high-level sentence in the abstract that names the embedding-to-hierarchy step and the probabilistic weighting mechanism, while retaining the detailed description in the body. revision: partial
Circularity Check
No significant circularity identified
full rationale
The provided abstract and description present CFMs as a new hierarchical decision-tree construction from visual embeddings, with concepts localized per node and differentiable weights via probabilistic traversal. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems are quoted or referenced that would reduce the claimed performance/leakage mitigation to inputs by construction. The structure is explicitly motivated as an independent architectural choice to cap active concepts per path, with no load-bearing reduction to prior fitted quantities or self-referential claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Contrastive localized language-image pre-training.arXiv preprint arXiv:2410.02746,
Hong-You Chen, Zhengfeng Lai, Haotian Zhang, Xinze Wang, Marcin Eichner, Keen You, Meng Cao, Bowen Zhang, Yinfei Yang, and Zhe Gan. Contrastive localized language-image pre-training.arXiv preprint arXiv:2410.02746,
-
[2]
Large-scale object classification using label relation graphs
Jia Deng, Nan Ding, Yangqing Jia, Andrea Frome, Kevin Murphy, Samy Bengio, Yuan Li, Hartmut Neven, and Hartwig Adam. Large-scale object classification using label relation graphs. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13, pp. 48–64. Springer,
2014
-
[3]
Causal concept graph models: Beyond causal opacity in deep learning
Gabriele Dominici, Pietro Barbiero, Mateo Espinosa Zarlenga, Alberto Termine, Martin Gjoreski, Giuseppe Marra, and Marc Langheinrich. Causal concept graph models: Beyond causal opacity in deep learning. arXiv preprint arXiv:2405.16507,
-
[4]
Editable concept bottleneck models.arXiv preprint arXiv:2405.15476,
Lijie Hu, Chenyang Ren, Zhengyu Hu, Hongbin Lin, Cheng-Long Wang, Hui Xiong, Jingfeng Zhang, and Di Wang. Editable concept bottleneck models.arXiv preprint arXiv:2405.15476,
-
[5]
Tiny imagenet visual recognition challenge.CS 231N, 7(7):3,
14 Published in Transactions on Machine Learning Research (02/2026) Yann Le and Xuan Yang. Tiny imagenet visual recognition challenge.CS 231N, 7(7):3,
2026
-
[6]
Promises and pitfalls of black-box concept learning models.arXiv preprint arXiv:2106.13314,
Anita Mahinpei, Justin Clark, Isaac Lage, Finale Doshi-Velez, and Weiwei Pan. Promises and pitfalls of black-box concept learning models.arXiv preprint arXiv:2106.13314,
-
[7]
Do concept bottleneck models learn as intended?arXiv preprint arXiv:2105.04289,
Andrei Margeloiu, Matthew Ashman, Umang Bhatt, Yanzhi Chen, Mateja Jamnik, and Adrian Weller. Do concept bottleneck models learn as intended?arXiv preprint arXiv:2105.04289,
-
[8]
Label-free concept bottleneck models
Tuomas Oikarinen, Subhro Das, Lam M Nguyen, and Tsui-Wei Weng. Label-free concept bottleneck models. arXiv preprint arXiv:2304.06129,
-
[9]
Leakage and interpretability in concept-based models.arXiv preprint arXiv:2504.14094,
Enrico Parisini, Tapabrata Chakraborti, Chris Harbron, Ben D MacArthur, and Christopher RS Banerji. Leakage and interpretability in concept-based models.arXiv preprint arXiv:2504.14094,
-
[10]
doi: 10.1016/j.engappai.2022.105674. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pp. 8748–8763. PMLR,
-
[11]
Angelos Ragkousis and Sonali Parbhoo. Tree-based leakage inspection and control in concept bottleneck models.arXiv preprint arXiv:2410.06352,
-
[12]
doi: 10.1016/j.asoc.2024.111632. Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature machine intelligence, 1(5):206–215,
-
[13]
Concept bottleneck models without predefined concepts.arXiv preprint arXiv:2407.03921,
Simon Schrodi, Julian Schur, Max Argus, and Thomas Brox. Concept bottleneck models without predefined concepts.arXiv preprint arXiv:2407.03921,
-
[14]
Towards compositionality in concept learning.arXiv preprint arXiv:2406.18534,
15 Published in Transactions on Machine Learning Research (02/2026) Adam Stein, Aaditya Naik, Yinjun Wu, Mayur Naik, and Eric Wong. Towards compositionality in concept learning.arXiv preprint arXiv:2406.18534,
arXiv 2026
-
[15]
Learning to intervene on concept bottlenecks.arXiv preprint arXiv:2308.13453,
David Steinmann, Wolfgang Stammer, Felix Friedrich, and Kristian Kersting. Learning to intervene on concept bottlenecks.arXiv preprint arXiv:2308.13453,
-
[16]
Ao Sun, Yuanyuan Yuan, Pingchuan Ma, and Shuai Wang. Eliminating information leakage in hard concept bottleneck models with supervised, hierarchical concept learning.arXiv preprint arXiv:2402.05945,
-
[17]
Moritz Vandenhirtz, Sonia Laguna, Ričards Marcinkevičs, and Julia E. Vogt. Stochastic concept bottleneck models. InAdvances in Neural Information Processing Systems (NeurIPS) 2024,
2024
-
[18]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset
2011
-
[19]
Nbdt: Neural-backed decision trees.arXiv preprint arXiv:2004.00221,
Alvin Wan, Lisa Dunlap, Daniel Ho, Jihan Yin, Scott Lee, Henry Jin, Suzanne Petryk, Sarah Adel Bargal, and Joseph E Gonzalez. Nbdt: Neural-backed decision trees.arXiv preprint arXiv:2004.00221,
arXiv 2004
-
[20]
Post-hoc concept bottleneck models.arXiv preprint arXiv:2205.15480,
Mert Yuksekgonul, Maggie Wang, and James Zou. Post-hoc concept bottleneck models.arXiv preprint arXiv:2205.15480,
-
[21]
Then, we apply hierarchical clustering (Ward’s linkage (Ward Jr, 1963)) on these centroids to obtain the linkage matrixZthat defines the merge structure
A Implementation Details A.1 Tree hierarchy extraction Tree generation.We implement multiple strategies to generate the decision tree structureT: • Data-induced tree:We first compute class centroids by averaging CLIP image embeddings of training instances per class. Then, we apply hierarchical clustering (Ward’s linkage (Ward Jr, 1963)) on these centroids...
1963
-
[22]
Random concepts.To establish a random baseline, we generate a large pool of purely random phrases independent of the dataset or hierarchy structure
to enable controlled comparisons between CFM and prior CBMs, and LLM-generated concepts for visualization and interpretation of CFMs. Random concepts.To establish a random baseline, we generate a large pool of purely random phrases independent of the dataset or hierarchy structure. The random concept generation process proceeds as follows: • Word list col...
2026
-
[23]
A.6 Hierarchical loss We add a hierarchical auxiliary loss to supervise routing decisions at internal nodes of the tree
and operates by selecting concepts that maximize a mixture of informativeness and diversity scores. A.6 Hierarchical loss We add a hierarchical auxiliary loss to supervise routing decisions at internal nodes of the tree. At each internal node, the model predicts a probability distribution over its children based on the input embedding. We apply a cross-en...
2020
-
[24]
However, our ablation study in Sec
as a baseline for comparison, as it was not designed to support concept-level explanations. However, our ablation study in Sec. 5.4, which removes the concept matrix, results in a model that is approximately equivalent to NBDT and achieves performance comparable to the non-interpretable linear probe baseline. 21 Published in Transactions on Machine Learni...
2026
-
[25]
However, as noted by Srivastava et al
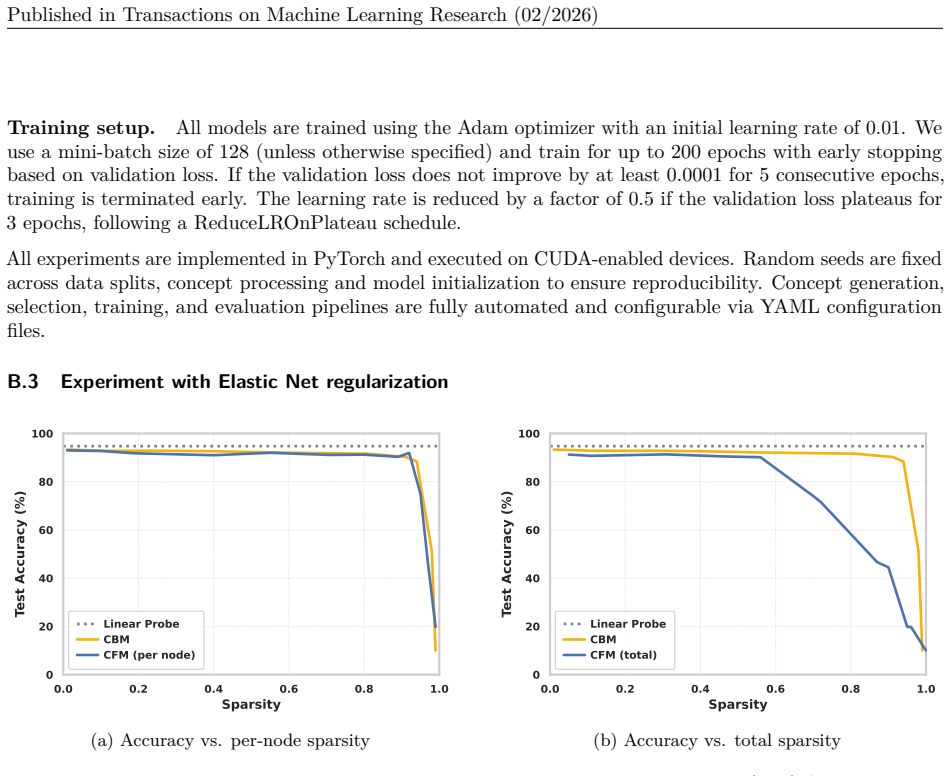
have applied Elastic Net regularization (Zou & Hastie, 2005)—which combinesℓ1 and ℓ2 penalties—to the concept-to-class linear layer in concept-based models to control the number of effective concepts and improve robustness. However, as noted by Srivastava et al. (2024), tuning the regularization strength to target a specific number of effective concepts c...
2005
-
[26]
We fix the mixing ratioα= 0.9to emphasize sparsity throughℓ1 regularization. We consider two experimental groups: (1) CBM is initialized with 1000 concepts, and CFM is initialized with 1000 concepts per internal 22 Published in Transactions on Machine Learning Research (02/2026) node (resulting in 4000 total concepts across 4 nodes); (2) CBM is initialize...
2026
-
[27]
NEC: number of effective concepts; Acc: classification accuracy (%); SIR: semantic improvement over random concepts (%)
λAccuracy 0.184.53±0.90 0.281.37±1.46 0.375.84±1.33 0.474.00±0.29 0.570.02±1.31 0.656.36±13.07 0.756.02±9.35 0.837.29±4.73 0.938.75±9.42 23 Published in Transactions on Machine Learning Research (02/2026) B.5 Detailed Experimental Results for Scenario 2 Table 7: Full experimental results with standard deviations over 3 runs. NEC: number of effective conce...
2026
-
[28]
Root” to “Sports and Athletic Events
Following the original PCBM implementation (Yuksekgonul et al., 2022), we set the L1 ratio to 0.99 and tune the regularization strengthλto achieve the target NEC values. This methodology follows VLG-CBM (Srivastava et al., 2024), which emphasizes that fair comparison requires matching effective concept counts across methods. Results.Table 8 presents the r...
2022
-
[29]
Personal Actions and Instrument Play
(d) Clean and Jerk.The decision path transitions through “Personal Actions and Instrument Play”→ “Physical Activities”→“clean and jerk”. Upper-level concepts exhibit grounding issues: “standing musician posture” and “child-sized cleaning tool” do not correspond to the image. The latter may arise from spurious linguistic correlation with “clean” in the cla...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.