OWMDrive: Causality-Aware End-to-End Autonomous Driving via 4D Occupancy World Model
Pith reviewed 2026-06-30 05:56 UTC · model grok-4.3
The pith
OWMDrive forecasts multi-step 3D occupancy to condition a diffusion planner on future scene states and capture causal traffic dependencies for trajectory generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OWMDrive is a generative end-to-end driving framework built upon an Occupancy World Model for multi-step 3D occupancy forecasting, which serves as a conditional prior to guide diffusion-based planning. Conditioned on both current observations and predicted future states, the planner iteratively refines trajectory candidates to generate a reinforced driving trajectory. By explicitly modeling scene evolution over future horizons, OWMDrive captures key spatiotemporal causal dependencies, which leads to more foresighted and robust trajectory generation.
What carries the argument
The Occupancy World Model that produces multi-step 3D occupancy forecasts used as a conditional prior for the diffusion planner.
If this is right
- Trajectory candidates are refined using both present observations and predicted future occupancy states rather than current observations alone.
- Planning reliability increases especially under partial observability because the model anticipates how occlusions and interactions will unfold.
- The diffusion planner produces less conservative and more stable outputs once it conditions on the forecasted causal dynamics.
- End-to-end systems that previously relied on static representations can now incorporate explicit temporal rollouts without reverting to modular pipelines.
Where Pith is reading between the lines
- The same forecasting-plus-conditioning pattern could be tested on longer prediction horizons to check whether early detection of distant hazards becomes feasible.
- If the world model generalizes across sensor modalities, the approach might transfer to camera-only or radar-only stacks without retraining the planner.
- The method suggests that explicit causal modeling of occupancy evolution could reduce the sample complexity of learning safe policies in simulation before real-world deployment.
Load-bearing premise
The multi-step 3D occupancy forecasts must be accurate enough and carry enough causal information to improve the diffusion planner beyond what is achieved by planners that receive only the current scene.
What would settle it
An ablation experiment that runs the identical diffusion planner once with the occupancy forecasts and once without them, then measures collision rate, progress, and comfort metrics on the same set of occluded or high-uncertainty test scenes.
Figures

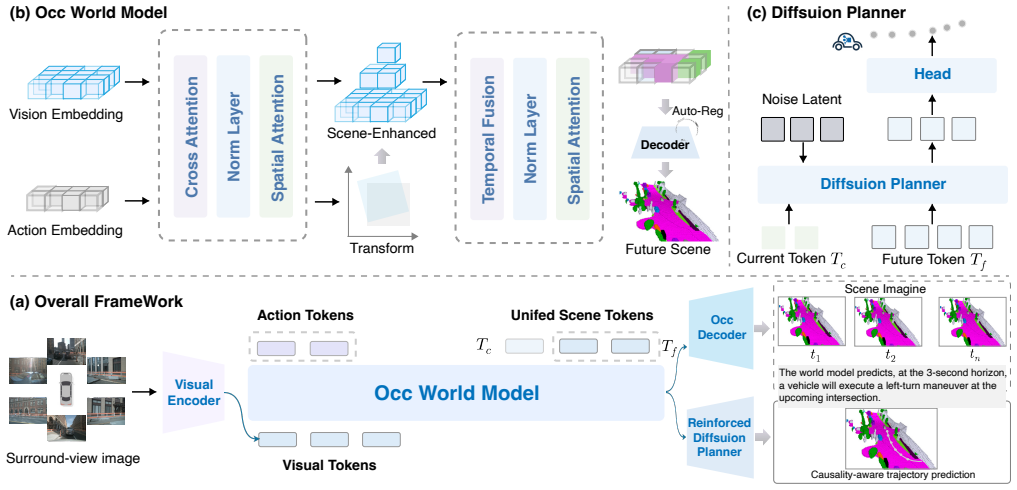
read the original abstract
Autonomous driving systems are steadily moving toward end-to-end paradigms to mitigate the limited adaptability of rule-based pipelines in complex traffic environments. However, most existing learning-based methods still make decisions from static representations of the current scene, without explicit future rollouts or modeling of the temporal causal dynamics in traffic interactions. This limitation often results in unstable or overly conservative planning under high-uncertainty conditions, such as occlusions and unexpected events. To overcome these challenges, we introduce OWMDrive, a generative end-to-end driving framework built upon an Occupancy World Model for multi-step 3D occupancy forecasting, which serves as a conditional prior to guide diffusion-based planning. Conditioned on both current observations and predicted future states, the planner iteratively refines trajectory candidates to generate a reinforced driving trajectory. By explicitly modeling scene evolution over future horizons, OWMDrive captures key spatiotemporal causal dependencies, which leads to more foresighted and robust trajectory generation. Extensive experiments demonstrate that OWMDrive significantly improves planning reliability and safety, especially in challenging and partially observable driving scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OWMDrive, a generative end-to-end autonomous driving framework built on an Occupancy World Model that performs multi-step 3D occupancy forecasting. This forecast serves as a conditional prior for a diffusion-based planner that iteratively refines trajectory candidates using both current observations and predicted future states. The central claim is that explicit modeling of scene evolution over future horizons captures spatiotemporal causal dependencies, yielding more foresighted and robust trajectories, with extensive experiments purportedly confirming gains in reliability and safety, especially under occlusion and partial observability.
Significance. If the empirical claims were substantiated, the work would address a recognized limitation in current end-to-end planners that rely on static scene encodings by adding explicit future rollout and causal structure; this could improve robustness in uncertain traffic scenarios. The approach of conditioning a diffusion planner on a learned 4D occupancy prior is a plausible direction, but the manuscript provides no data with which to evaluate whether the claimed benefits materialize.
major comments (2)
- [Abstract] Abstract: the manuscript asserts that 'extensive experiments demonstrate that OWMDrive significantly improves planning reliability and safety' yet supplies no quantitative results, ablation tables, error bars, dataset descriptions, or baseline comparisons. The central performance claim therefore receives no empirical support from the provided text.
- [Abstract] Abstract: the claim that multi-step 3D occupancy forecasts are 'sufficiently accurate and causally informative' to improve the diffusion planner rests on an unverified assumption; no per-horizon forecast metrics (e.g., IoU or error accumulation), no ablation isolating the world-model prior, and no evidence that the diffusion process actually conditions on or benefits from those forecasts are presented.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. Both major points correctly identify that the abstract makes strong empirical claims without any supporting quantitative evidence, metrics, tables, or ablations appearing in the provided manuscript text. We will revise the abstract to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript asserts that 'extensive experiments demonstrate that OWMDrive significantly improves planning reliability and safety' yet supplies no quantitative results, ablation tables, error bars, dataset descriptions, or baseline comparisons. The central performance claim therefore receives no empirical support from the provided text.
Authors: We agree with this observation. The abstract as written asserts performance gains without including or referencing any numerical results, tables, or experimental details from the text. In the revised manuscript we will either (a) insert a concise summary of key metrics (e.g., collision-rate reduction and success-rate improvement on the evaluation set) or (b) moderate the language to state only that improvements are shown in the full experimental section. This change will be made. revision: yes
-
Referee: [Abstract] Abstract: the claim that multi-step 3D occupancy forecasts are 'sufficiently accurate and causally informative' to improve the diffusion planner rests on an unverified assumption; no per-horizon forecast metrics (e.g., IoU or error accumulation), no ablation isolating the world-model prior, and no evidence that the diffusion process actually conditions on or benefits from those forecasts are presented.
Authors: We agree that the abstract presents this as an assumption without any supporting forecast accuracy numbers, horizon-wise metrics, or ablation evidence in the supplied text. The revised abstract will either qualify the statement or add a short clause summarizing the relevant per-horizon IoU and ablation outcomes that appear later in the paper. This change will be made. revision: yes
- The manuscript text supplied to the referee consists solely of the abstract and contains none of the experimental results, tables, metrics, or ablations needed to substantiate the claims; therefore the empirical content itself cannot be defended from the given document.
Circularity Check
No equations or derivation chain present; circularity cannot be assessed
full rationale
The provided abstract and description contain no mathematical derivations, equations, or explicit prediction steps that could be inspected for self-definition, fitted-input renaming, or self-citation load-bearing. The central claim is an empirical assertion about improved planning from occupancy forecasts, supported by experiments rather than a closed-form derivation that reduces to its inputs by construction. Without visible math or load-bearing self-citations in the text, no circular steps are identifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
End- to-end autonomous driving through v2x cooperation,
H. Yu, W. Yang, J. Zhong, Z. Yang, S. Fan, P. Luo, and Z. Nie, “End- to-end autonomous driving through v2x cooperation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9598–9606
2025
-
[2]
Sparsedrive: End-to-end autonomous driving via sparse scene representation,
W. Sun, X. Lin, Y. Shi, C. Zhang, H. Wu, and S. Zheng, “Sparsedrive: End-to-end autonomous driving via sparse scene representation,” in 2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 8795–8801
2025
-
[3]
A rgb-d based real-time multiple object detection and ranging system for autonomous driving,
J. Yang, C. Wang, H. Wang, and Q. Li, “A rgb-d based real-time multiple object detection and ranging system for autonomous driving,” IEEE Sensors Journal, vol. 20, no. 20, pp. 11959–11966, 2020
2020
-
[4]
Pointpillars: Fast encoders for object detection from point clouds,
A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 12689–12697
2019
-
[5]
A rule-based behaviour planner for autonomous driving,
F. Bouchard, S. Sedwards, and K. Czarnecki, “A rule-based behaviour planner for autonomous driving,” inInternational joint conference on rules and reasoning. Springer, 2022, pp. 263–279
2022
-
[6]
Learning robust control policies for end-to- end autonomous driving from data-driven simulation,
A. Amini, I. Gilitschenski, J. Phillips, J. Moseyko, R. Banerjee, S. Karaman, and D. Rus, “Learning robust control policies for end-to- end autonomous driving from data-driven simulation,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1143–1150, 2020
2020
-
[7]
Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 11, pp. 12878–12895, 2023
2023
-
[8]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y. Zhang, Q. Zhang,et al., “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12037–12047
2025
-
[9]
Versatile behavior diffusion for generalized traffic agent simulation,
Z. Huang, Z. Zhang, A. Vaidya, Y. Chen, C. Lv, and J. F. Fisac, “Versatile behavior diffusion for generalized traffic agent simulation,” arXiv preprint arXiv:2404.02524, 2024
-
[10]
Bevworld: A multimodal world model for autonomous driving via unified bev latent space,
Y. Zhang, S. Gong, K. Xiong, X. Ye, X. Tan, F. Wang, J. Huang, H. Wu, and H. Wang, “Bevworld: A multimodal world model for autonomous driving via unified bev latent space,” 2024
2024
-
[11]
A. Popov, A. Degirmenci, D. Wehr, S. Hegde, R. Oldja, A. Kamenev, B. Douillard, D. Nistér, U. Muller, R. Bhargava,et al., “Mitigating covariate shift in imitation learning for autonomous vehicles using latent space generative world models,”arXiv preprint arXiv:2409.16663, 2024
-
[12]
Vista: A generalizable driving world model with high fidelity and versatile controllability,
S. Gao, J. Yang, L. Chen, K. Chitta, Y. Qiu, A. Geiger, J. Zhang, and H. Li, “Vista: A generalizable driving world model with high fidelity and versatile controllability,”Advances in Neural Information Processing Systems, vol. 37, pp. 91560–91596, 2024
2024
-
[13]
Dome: Taming diffusion model into high-fidelity controllable occupancy world model,
S. Gu, W. Yin, B. Jin, X. Guo, J. Wang, H. Li, Q. Zhang, and X. Long, “Dome: Taming diffusion model into high-fidelity controllable occupancy world model,”arXiv preprint arXiv:2410.10429, 2024
-
[14]
Occ-llm: Enhancing autonomous driving with occupancy-based large language models,
T. Xu, H. Lu, X. Yan, Y. Cai, B. Liu, and Y. Chen, “Occ-llm: Enhancing autonomous driving with occupancy-based large language models,” arXiv preprint arXiv:2502.06419, 2025
-
[15]
Occworld: Learning a 3d occupancy world model for autonomous driving,
W. Zheng, W. Chen, Y. Huang, B. Zhang, Y. Duan, and J. Lu, “Occworld: Learning a 3d occupancy world model for autonomous driving,” inEuropean conference on computer vision. Springer, 2024, pp. 55–72
2024
-
[16]
Occsora: 4d occupancy generation models as world simulators for autonomous driving
L. Wang, W. Zheng, Y. Ren, H. Jiang, Z. Cui, H. Yu, and J. Lu, “Occsora: 4d occupancy generation models as world simulators for autonomous driving,”arXiv preprint arXiv:2405.20337, 2024
-
[17]
J. Chen, H. Xu, Y. Wang, and L.-P. Chau, “Occprophet: Pushing effi- ciency frontier of camera-only 4d occupancy forecasting with observer- forecaster-refiner framework,”arXiv preprint arXiv:2502.15180, 2025
-
[18]
Driving in the occupancy world: Vision-centric 4d occupancy forecasting and planning via world models for autonomous driving,
Y. Yang, J. Mei, Y. Ma, S. Du, W. Chen, Y. Qian, Y. Feng, and Y. Liu, “Driving in the occupancy world: Vision-centric 4d occupancy forecasting and planning via world models for autonomous driving,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9327–9335
2025
-
[19]
i2-world: Intra-inter tokenization for efficient dynamic 4d scene forecasting,
Z. Liao, P. Wei, R. Zhang, S. Chen, H. Wang, and Z. Ren, “i2-world: Intra-inter tokenization for efficient dynamic 4d scene forecasting,” arXiv preprint arXiv:2507.09144, 2025
-
[20]
Genad: Generative end-to-end autonomous driving,
W. Zheng, R. Song, X. Guo, C. Zhang, and L. Chen, “Genad: Generative end-to-end autonomous driving,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 87–104
2024
-
[21]
Insightdrive: Insight scene representation for end-to-end autonomous driving,
R. Song, X. Guo, Y. Peng, Q. Wei, H. Wu, and L. Chen, “Insightdrive: Insight scene representation for end-to-end autonomous driving,”arXiv preprint arXiv:2503.13047, 2025
-
[22]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model,
Z. Xu, Y. Zhang, E. Xie, Z. Zhao, Y. Guo, K.-Y. K. Wong, Z. Li, and H. Zhao, “Drivegpt4: Interpretable end-to-end autonomous driving via large language model,”IEEE Robotics and Automation Letters, 2024
2024
-
[23]
Generative planning with 3d-vision language pre-training for end-to-end autonomous driv- ing,
T. Li, H. Wang, X. Li, W. Liao, T. He, and P. Peng, “Generative planning with 3d-vision language pre-training for end-to-end autonomous driv- ing,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 5, 2025, pp. 4950–4958
2025
-
[24]
Diffad: A unified diffusion modeling approach for autonomous driving,
T. Wang, C. Zhang, X. Qu, K. Li, W. Liu, and C. Huang, “Diffad: A unified diffusion modeling approach for autonomous driving,”arXiv preprint arXiv:2503.12170, 2025
-
[25]
Autoregressive image generation using residual quantization,
D. Lee, C. Kim, S. Kim, M. Cho, and W.-S. Han, “Autoregressive image generation using residual quantization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11523–11532
2022
-
[26]
Visual autoregres- sive modeling: Scalable image generation via next-scale prediction,
K. Tian, Y. Jiang, Z. Yuan, B. Peng, and L. Wang, “Visual autoregres- sive modeling: Scalable image generation via next-scale prediction,” Advances in neural information processing systems, vol. 37, pp. 84839– 84865, 2024
2024
-
[27]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11621–11631
2020
-
[28]
Planning-oriented autonomous driving,
Y. Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang,et al., “Planning-oriented autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17853–17862
2023
-
[29]
Is ego status all you need for open-loop end-to-end autonomous driving?
Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. Alvarez, “Is ego status all you need for open-loop end-to-end autonomous driving?” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14864–14873
2024
-
[30]
Vad: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8340–8350
2023
-
[31]
Para- drive: Parallelized architecture for real-time autonomous driving,
X. Weng, B. Ivanovic, Y. Wang, Y. Wang, and M. Pavone, “Para- drive: Parallelized architecture for real-time autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15449–15458
2024
-
[32]
Navsim: Data- driven non-reactive autonomous vehicle simulation and benchmarking,
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone,et al., “Navsim: Data- driven non-reactive autonomous vehicle simulation and benchmarking,” Advances in Neural Information Processing Systems, vol. 37, pp. 28706– 28719, 2024
2024
-
[33]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Z. Li, K. Li, S. Wang, S. Lan, Z. Yu, Y. Ji, Z. Li, Z. Zhu, J. Kautz, Z. Wu,et al., “Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation,”arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
S. Chen, B. Jiang, H. Gao, B. Liao, Q. Xu, Q. Zhang, C. Huang, W. Liu, and X. Wang, “Vadv2: End-to-end vectorized autonomous driving via probabilistic planning,”arXiv preprint arXiv:2402.13243, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Drama: An efficient end-to-end motion planner for autonomous driving with mamba
C. Yuan, Z. Zhang, J. Sun, S. Sun, Z. Huang, C. D. W. Lee, D. Li, Y. Han, A. Wong, K. P. Tee,et al., “Drama: An efficient end-to-end motion planner for autonomous driving with mamba,”arXiv preprint arXiv:2408.03601, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.