Zeta: Dual Whitening for Matrix Optimization via Coordinate-Adaptive Preconditioning
Pith reviewed 2026-06-27 05:00 UTC · model grok-4.3
The pith
A dual whitening pipeline applies coordinate whitening before spectral whitening to reduce orthogonalization error by improving input condition number.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
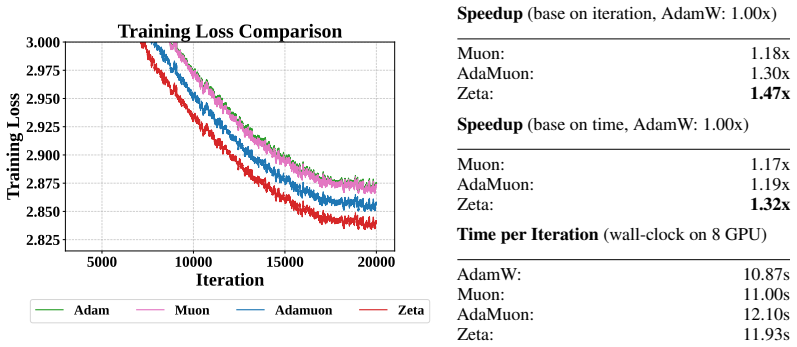
Zeta performs coordinate whitening followed by spectral whitening because the first step creates the isotropy the second step needs; the paper proves this ordered pipeline improves the condition number of the input matrix and thereby strictly reduces orthogonalization error compared with pure spectral methods.
What carries the argument
The strictly ordered dual whitening pipeline (coordinate whitening then spectral whitening) that establishes isotropy before orthogonalization.
If this is right
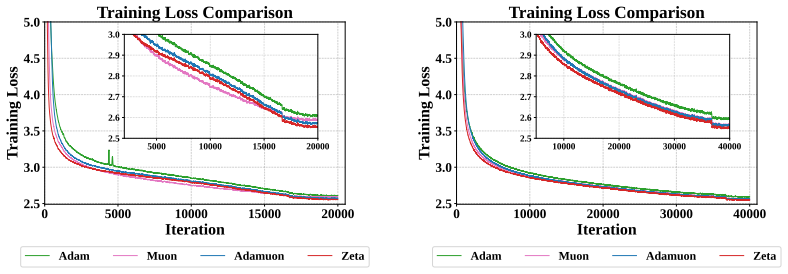
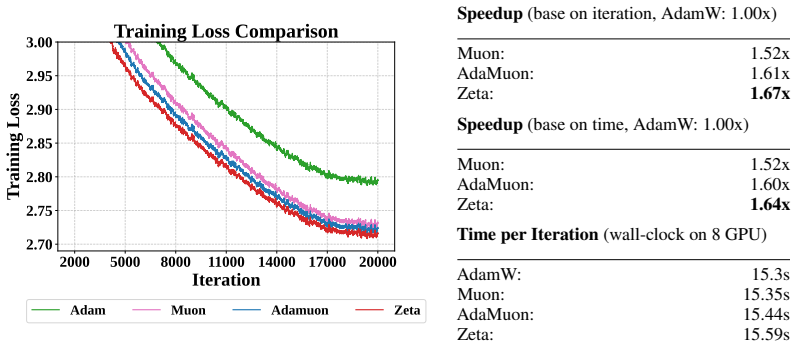
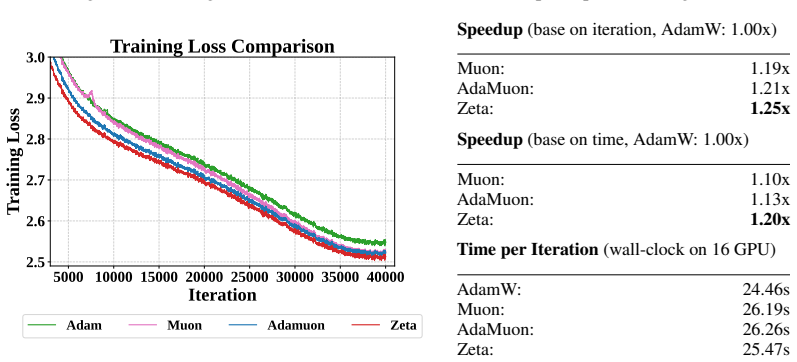
- The dual pipeline produces faster convergence than pure spectral baselines on language models from 0.6B to 8B parameters.
- Zeta matches or exceeds strong baselines on mixture-of-experts architectures and vision tasks.
- Resolving scale imbalance before orthogonalization is shown to be the source of the observed gains in convergence and generalization.
- The ordering of the two whitening steps follows from a mathematical dependency rather than from hyperparameter search.
Where Pith is reading between the lines
- Similar pre-conditioning steps could be inserted into other matrix-aware optimizers that rely on spectral operations.
- Integrating isotropy diagnostics into the optimizer loop might allow automatic detection of when coordinate whitening is needed.
- The approach may generalize to any setting where heterogeneous coordinate scales precede an orthogonalization or inversion step.
Load-bearing premise
Coordinate whitening is required to create the statistical isotropy that spectral whitening needs to operate reliably.
What would settle it
A controlled test on the same momentum matrices that reverses the whitening order or skips coordinate whitening and shows whether orthogonalization error reduction is lost or unchanged.
Figures
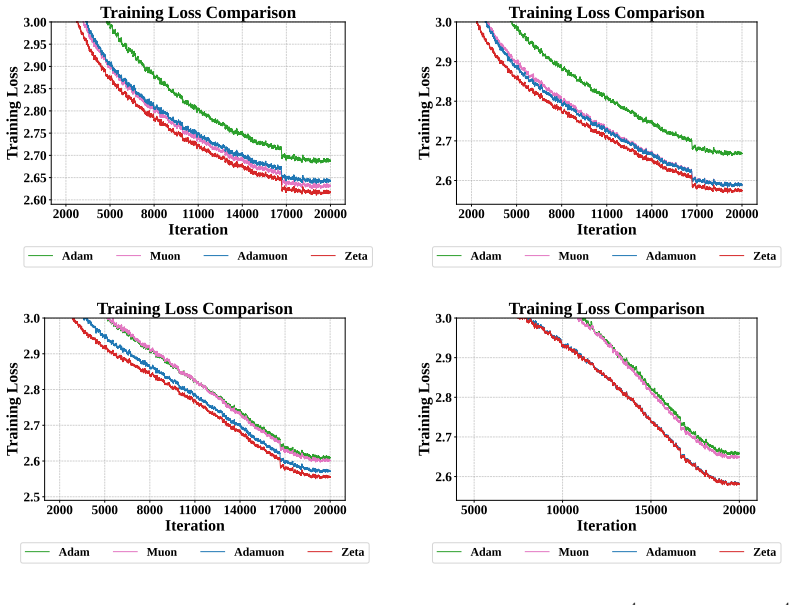
read the original abstract
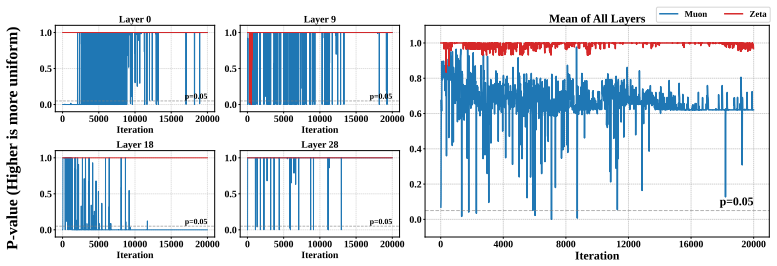
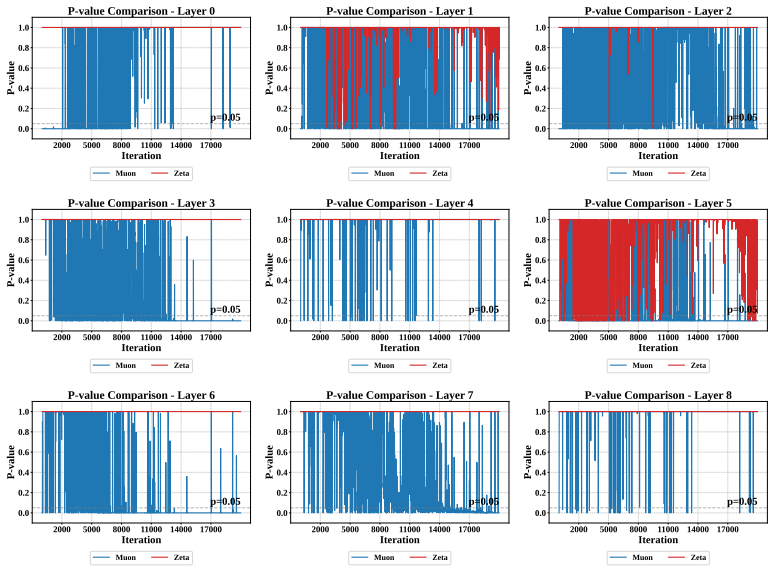
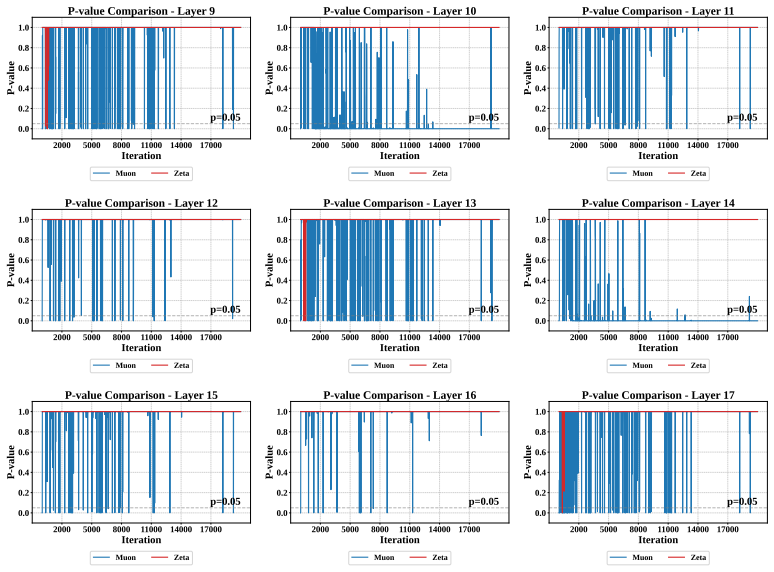
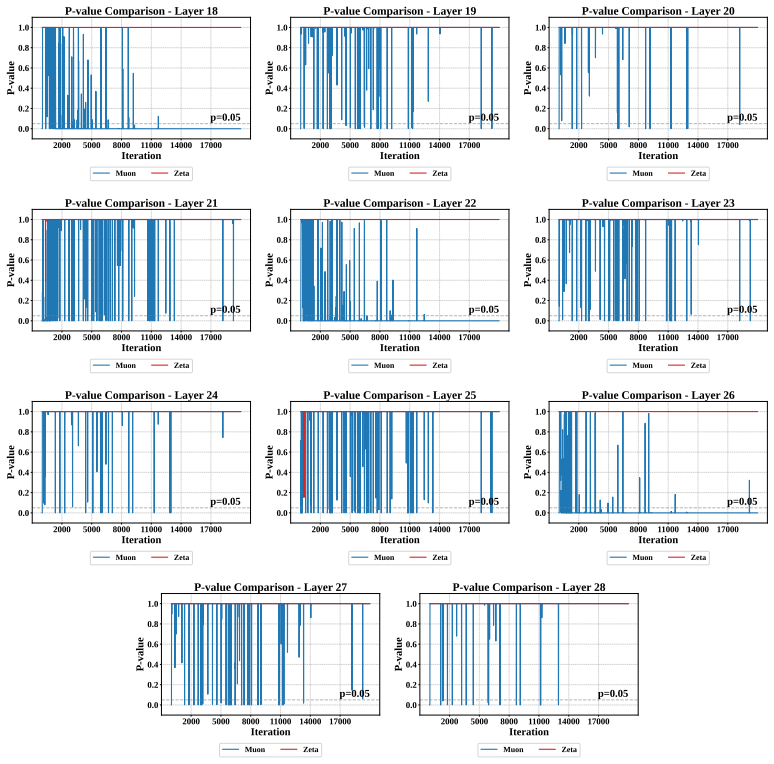
Large-scale neural network training increasingly relies on matrix-aware optimizers that exploit the structure of weight parameters beyond element-wise adaptation. However, existing matrix-aware methods such as Muon have an underappreciated vulnerability: their core operation, Newton-Schulz iteration, depends critically on input conditioning, yet the raw momentum matrices exhibit severe coordinate-wise scale heterogeneity. In this paper, we first verify this scale heterogeneity through a chi-square uniformity test, showing that intra-matrix scale imbalance is prevalent across Transformer layers and that coordinate whitening effectively corrects it. Motivated by this finding, we propose Zeta, a dual whitening optimizer that applies coordinate whitening and spectral whitening in a strictly ordered pipeline. The ordering is not a tunable choice but follows from a mathematical dependency: coordinate whitening establishes the statistical isotropy that spectral whitening requires to function reliably. We further prove that this dual pipeline strictly reduces orthogonalization error relative to pure spectral methods by improving the condition number of the input. Empirically, Zeta matches or surpasses strong baselines across language modeling (0.6B to 8B parameters), mixture-of-experts architectures, and vision tasks, demonstrating that resolving scale imbalance before orthogonalization leads to faster convergence and better generalization. Code is available at https://github.com/AIGCodeOS/aigcode_zeta_optimizer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that momentum matrices in matrix-aware optimizers like Muon exhibit prevalent coordinate-wise scale heterogeneity (verified via chi-square uniformity test across Transformer layers), which coordinate whitening corrects to establish statistical isotropy; it then proposes Zeta as a strictly ordered dual pipeline (coordinate whitening followed by spectral whitening via Newton-Schulz iteration) whose ordering is mathematically necessary rather than tunable, proves that this pipeline strictly reduces orthogonalization error relative to pure spectral methods by improving the input condition number, and reports that Zeta matches or exceeds strong baselines on language modeling (0.6B–8B params), MoE, and vision tasks with faster convergence and better generalization. Code is released.
Significance. If the necessity of the coordinate-then-spectral ordering and the error-reduction proof hold under the paper's stated conditions on momentum matrices, the work supplies a principled preconditioning step that could stabilize and accelerate existing spectral matrix optimizers; the empirical scope across model scales and architectures plus open code are positive factors for adoption and verification.
major comments (2)
- [Abstract / theoretical analysis] Abstract and theoretical analysis section: the central claim that 'coordinate whitening establishes the statistical isotropy that spectral whitening requires to function reliably' (making the ordering a mathematical necessity) is asserted without an explicit derivation or set of sufficient/necessary conditions on the input matrices showing why spectral methods cannot achieve reliable performance without the preceding coordinate step; this directly underpins both the proof of strict error reduction and the rejection of alternative orderings or preconditioners.
- [theoretical analysis] Proof of error reduction (theoretical analysis section): the statement that the dual pipeline 'strictly reduces orthogonalization error relative to pure spectral methods by improving the condition number of the input' requires the full theorem statement, including any assumptions on matrix distributions or norms, to confirm the reduction is strict rather than conditional on unstated properties of the momentum matrices.
minor comments (2)
- [Experiments] Experiments section: provide the precise definition of the chi-square uniformity test statistic and the exact layers/models on which it was run, to allow independent replication of the scale-heterogeneity finding.
- [Method] Notation throughout: clarify whether 'coordinate whitening' refers to a specific per-row or per-column normalization and how it interacts with the subsequent Newton-Schulz iteration in the presence of momentum buffers.
Simulated Author's Rebuttal
We thank the referee for the careful reading and specific suggestions regarding the theoretical claims. We will revise the manuscript to supply the requested explicit derivation and complete theorem statement.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract and theoretical analysis section: the central claim that 'coordinate whitening establishes the statistical isotropy that spectral whitening requires to function reliably' (making the ordering a mathematical necessity) is asserted without an explicit derivation or set of sufficient/necessary conditions on the input matrices showing why spectral methods cannot achieve reliable performance without the preceding coordinate step; this directly underpins both the proof of strict error reduction and the rejection of alternative orderings or preconditioners.
Authors: We agree that the necessity claim requires an explicit derivation. In the revised version we will insert a new subsection deriving the sufficient and necessary conditions on the second-moment structure of momentum matrices under which spectral whitening alone fails to produce reliable isotropy, using the same chi-square uniformity test framework already present in the paper. This derivation will directly justify the fixed ordering. revision: yes
-
Referee: [theoretical analysis] Proof of error reduction (theoretical analysis section): the statement that the dual pipeline 'strictly reduces orthogonalization error relative to pure spectral methods by improving the condition number of the input' requires the full theorem statement, including any assumptions on matrix distributions or norms, to confirm the reduction is strict rather than conditional on unstated properties of the momentum matrices.
Authors: We accept that the current proof sketch omits the complete formal statement. The revised manuscript will state the full theorem, including the assumptions that momentum matrices possess finite fourth moments and that coordinate whitening produces a matrix whose singular values lie in a bounded interval around unity. Under these conditions the subsequent Newton-Schulz iteration is shown to achieve strictly lower orthogonalization error; the complete proof will be supplied. revision: yes
Circularity Check
No circularity; central claims rest on claimed internal proof and independent empirical test
full rationale
The paper's derivation begins with an empirical chi-square uniformity test on real momentum matrices from Transformer layers to establish scale heterogeneity, then motivates the coordinate-then-spectral ordering from a stated mathematical dependency on isotropy, and asserts a proof that the dual pipeline reduces orthogonalization error via condition-number improvement. No equations, fitted parameters, or self-citations are quoted that reduce the ordering necessity or error-reduction result back to the inputs by construction. The verification test and proof are presented as independent content external to any renaming or self-referential fit, making the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coordinate whitening establishes the statistical isotropy that spectral whitening requires to function reliably.
Reference graph
Works this paper leans on
-
[1]
Optimization methods for large-scale machine learning.SIAM review, 60(2):223–311, 2018
Léon Bottou, Frank E Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning.SIAM review, 60(2):223–311, 2018
2018
-
[2]
MIT press Cambridge, 2016
Ian Goodfellow, Yoshua Bengio, Aaron Courville, and Yoshua Bengio.Deep learning, volume 1. MIT press Cambridge, 2016
2016
-
[3]
Adaptive subgradient methods for online learning and stochastic optimization.Journal of machine learning research, 12(7), 2011
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization.Journal of machine learning research, 12(7), 2011
2011
-
[4]
Adafactor: Adaptive learning rates with sublinear memory cost
Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. InInternational conference on machine learning, pages 4596–4604. PMLR, 2018
2018
-
[5]
On the variance of the adaptive learning rate and beyond.arXiv preprint arXiv:1908.03265, 2019
Liyuan Liu, Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Jiawei Han. On the variance of the adaptive learning rate and beyond.arXiv preprint arXiv:1908.03265, 2019
-
[6]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Understanding the difficulty of training deep feedfor- ward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedfor- ward neural networks. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010
2010
-
[8]
Why are adaptive methods good for attention models?Advances in Neural Information Processing Systems, 33:15383–15393, 2020
Jingzhao Zhang, Sai Praneeth Karimireddy, Andreas Veit, Seungyeon Kim, Sashank Reddi, Sanjiv Kumar, and Suvrit Sra. Why are adaptive methods good for attention models?Advances in Neural Information Processing Systems, 33:15383–15393, 2020
2020
-
[9]
Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan. github. io/posts/muon, 6(3):4, 2024
2024
-
[10]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Some iterative methods for improving orthonormality.SIAM Journal on Numerical Analysis, 7(3):386–389, 1970
Zdislav Kovarik. Some iterative methods for improving orthonormality.SIAM Journal on Numerical Analysis, 7(3):386–389, 1970
1970
-
[12]
An iterative algorithm for computing the best estimate of an orthogonal matrix.SIAM Journal on Numerical Analysis, 8(2):358–364, 1971
Åke Björck and Clazett Bowie. An iterative algorithm for computing the best estimate of an orthogonal matrix.SIAM Journal on Numerical Analysis, 8(2):358–364, 1971
1971
-
[13]
SIAM, 2008
Nicholas J Higham.Functions of matrices: theory and computation. SIAM, 2008
2008
-
[14]
Mousse: Rectifying the geometry of muon with curvature-aware preconditioning
Yechen Zhang, Shuhao Xing, Junhao Huang, Kai Lv, Yunhua Zhou, Xipeng Qiu, Qipeng Guo, and Kai Chen. Mousse: Rectifying the geometry of muon with curvature-aware preconditioning. arXiv preprint arXiv:2603.09697, 2026
-
[15]
Insights on muon from simple quadratics.arXiv preprint arXiv:2602.11948, 2026
Antoine Gonon, Andreea-Alexandra Mu¸ sat, and Nicolas Boumal. Insights on muon from simple quadratics.arXiv preprint arXiv:2602.11948, 2026
-
[16]
Backward stability of iterations for computing the polar decomposition.SIAM Journal on Matrix Analysis and Applications, 33(2):460–479, 2012
Yuji Nakatsukasa and Nicholas J Higham. Backward stability of iterations for computing the polar decomposition.SIAM Journal on Matrix Analysis and Applications, 33(2):460–479, 2012. 10
2012
-
[17]
Wei He, Kai Han, Hang Zhou, Hanting Chen, Zhicheng Liu, Xinghao Chen, and Yunhe Wang. Root: Robust orthogonalized optimizer for neural network training.arXiv preprint arXiv:2511.20626, 2025
-
[18]
Peng Cheng, Jiucheng Zang, Qingnan Li, Liheng Ma, Yufei Cui, Yingxue Zhang, Boxing Chen, Ming Jian, and Wen Tong. Trasmuon: Trust-region adaptive scaling for orthogonalized momentum optimizers.arXiv preprint arXiv:2602.13498, 2026
-
[19]
Karl Pearson. X. on the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling.The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 50(302):157–175, 1900
1900
-
[20]
Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005, 2025
Chongjie Si, Debing Zhang, and Wei Shen. Adamuon: Adaptive muon optimizer.arXiv preprint arXiv:2507.11005, 2025
-
[21]
Large-scale machine learning with stochastic gradient descent
Léon Bottou. Large-scale machine learning with stochastic gradient descent. InProceedings of COMPSTAT’2010: 19th International Conference on Computational StatisticsParis France, August 22-27, 2010 Keynote, Invited and Contributed Papers, pages 177–186. Springer, 2010
2010
-
[22]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Symbolic discovery of optimization algorithms.Advances in neural information processing systems, 36:49205–49233, 2023
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, et al. Symbolic discovery of optimization algorithms.Advances in neural information processing systems, 36:49205–49233, 2023
2023
-
[24]
Hong Liu, Zhiyuan Li, David Hall, Percy Liang, and Tengyu Ma. Sophia: A scalable stochastic second-order optimizer for language model pre-training.arXiv preprint arXiv:2305.14342, 2023
-
[25]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. InInternational Conference on Machine Learning, pages 1842–1850. PMLR, 2018
2018
-
[26]
SOAP: Improving and Stabilizing Shampoo using Adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Old Optimizer, New Norm: An Anthology
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Datacomp-lm: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37:14200–14282, 2024
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, et al. Datacomp-lm: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37:14200–14282, 2024
2024
-
[32]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019. 11
2019
-
[33]
Cmmlu: Measuring massive multitask language understanding in chinese
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. Cmmlu: Measuring massive multitask language understanding in chinese. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11260–11285, 2024
2024
-
[34]
Mo Li, Songyang Zhang, Yunxin Liu, and Kai Chen. Needlebench: Can llms do retrieval and reasoning in 1 million context window.arXiv preprint arXiv:2407.11963, 2024
-
[35]
Piqa: Reasoning about phys- ical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about phys- ical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
2020
-
[36]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models.Advances in neural information processing systems, 36:62991–63010, 2023
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Yao Fu, et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models.Advances in neural information processing systems, 36:62991–63010, 2023
2023
-
[38]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017
2017
-
[39]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2381–2391, 2018
2018
-
[40]
Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
2021
-
[41]
Chid: A large-scale chinese idiom dataset for cloze test
Chujie Zheng, Minlie Huang, and Aixin Sun. Chid: A large-scale chinese idiom dataset for cloze test. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 778–787, 2019
2019
-
[42]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[43]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[44]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 12 APPENDIX Contents A Theoretical Analysis 14 A.1 Proof of Th...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[45]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.