Agent Planning Benchmark: A Diagnostic Framework for Planning Capabilities in LLM Agents
Pith reviewed 2026-06-28 06:02 UTC · model grok-4.3
The pith
Agent Planning Benchmark isolates planning skills from execution in LLM agents using 4,209 cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
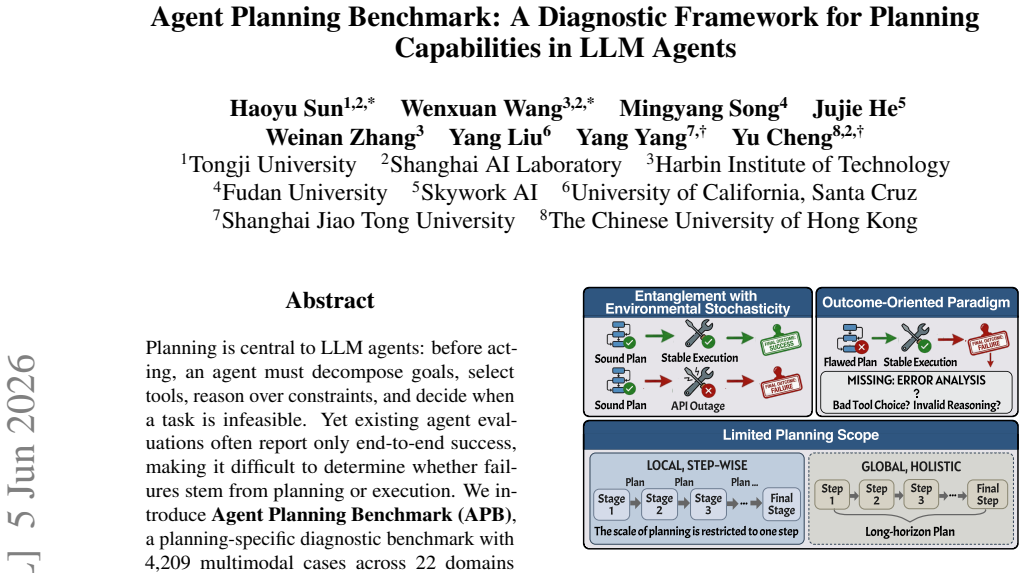
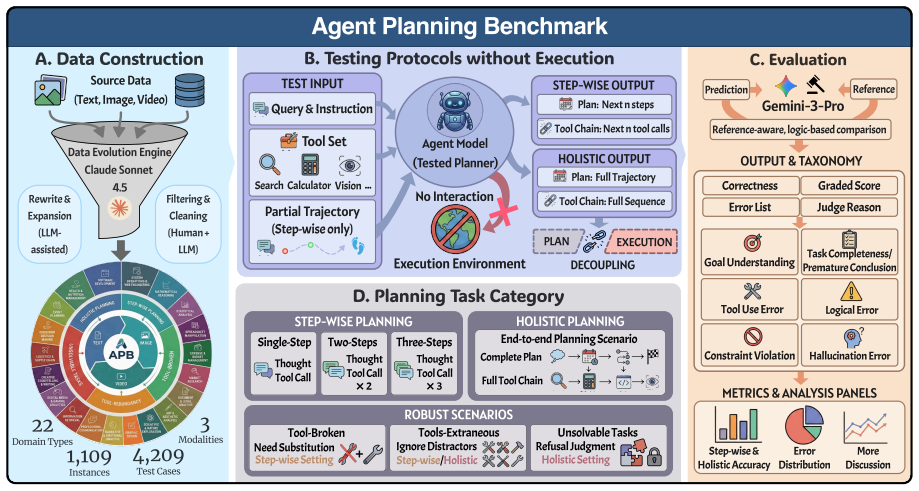
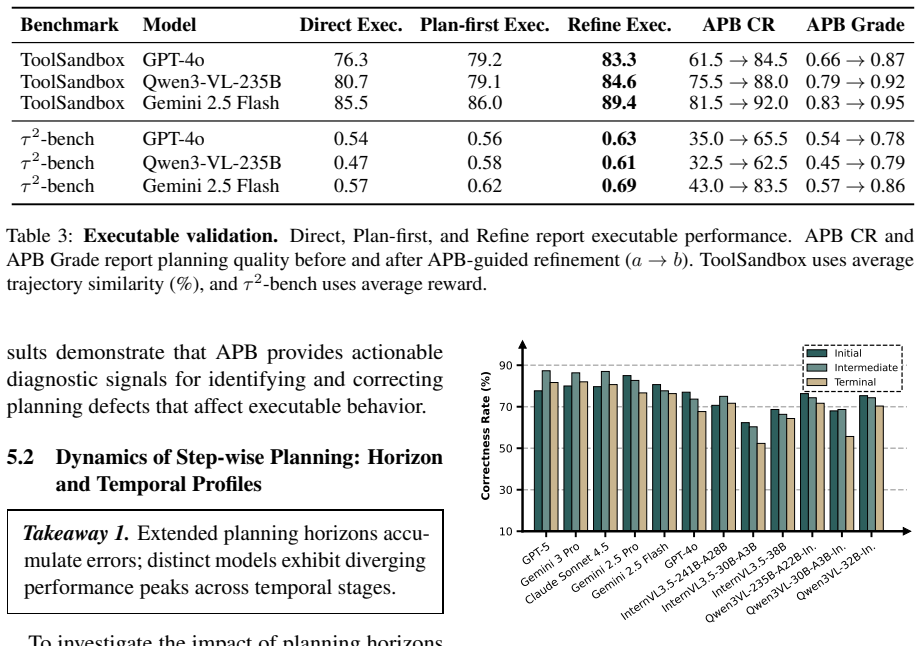
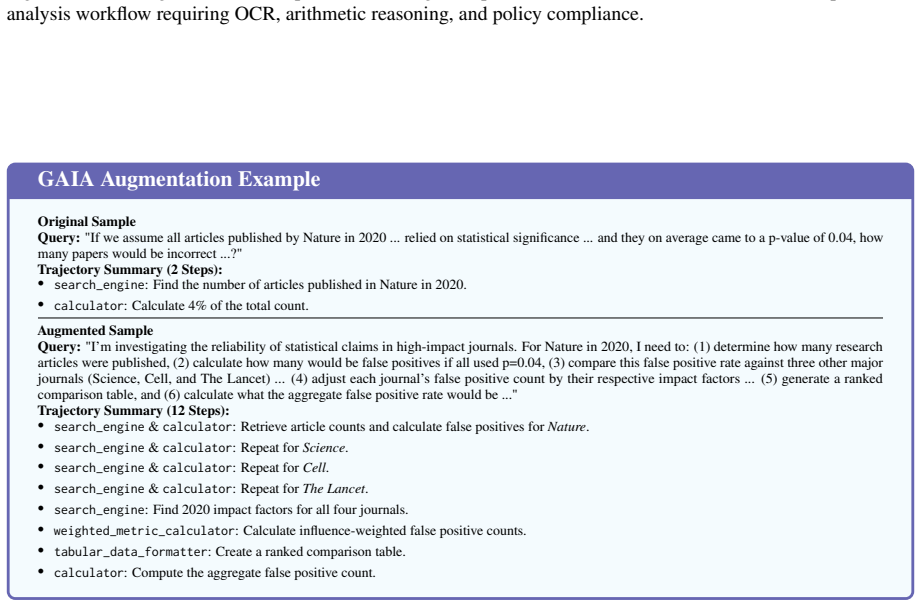
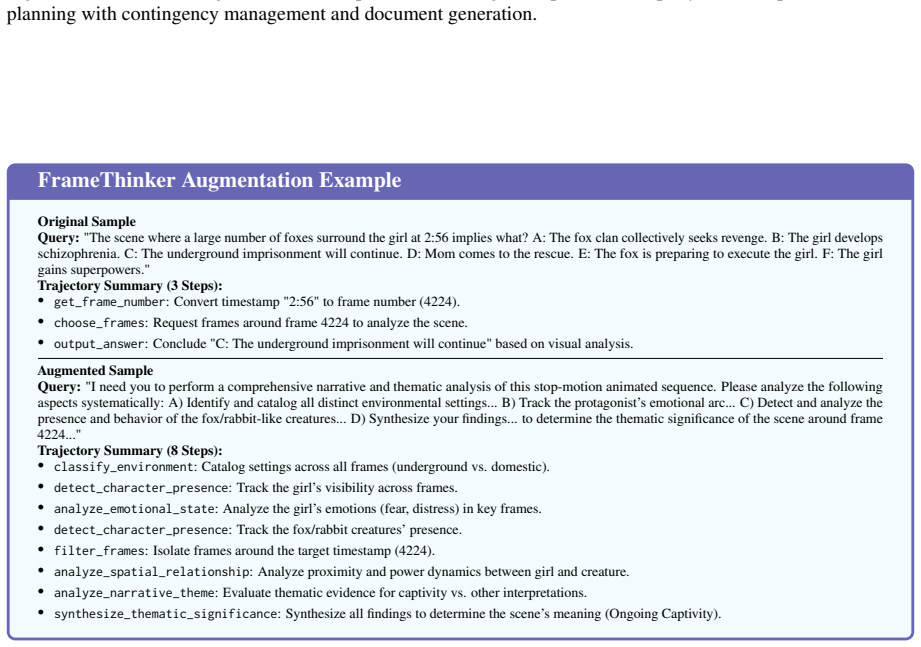
The Agent Planning Benchmark (APB) is a planning-specific diagnostic with 4,209 multimodal cases across 22 domains and five settings covering holistic planning, feedback-conditioned step-wise planning, and robustness under extraneous tools, broken tools, and unsolvable tasks. Across 12 MLLMs it reveals systematic weaknesses in long-horizon planning, tool-noise robustness, calibrated refusal, and inference-time refinement. APB-guided refinement consistently improves plan correctness, plan grade, and downstream execution metrics on 200 ToolSandbox tasks and 200 τ²-bench tasks.
What carries the argument
The Agent Planning Benchmark consisting of 4,209 multimodal cases across 22 domains and five settings that test planning in isolation from execution.
If this is right
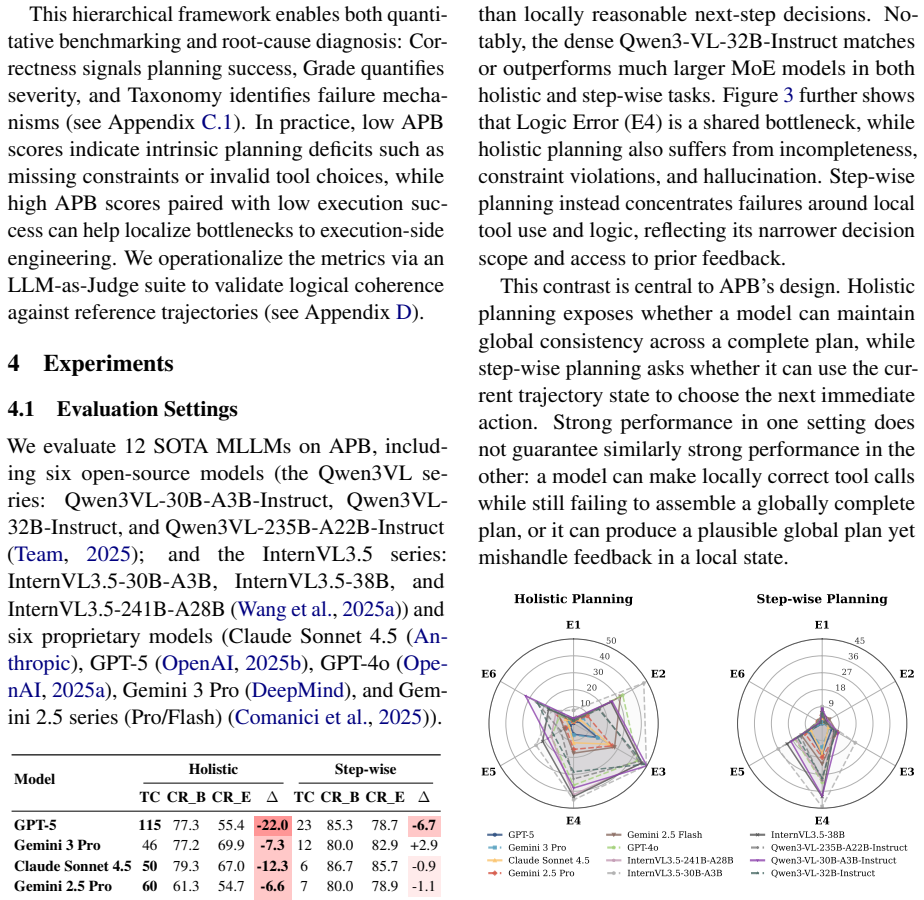
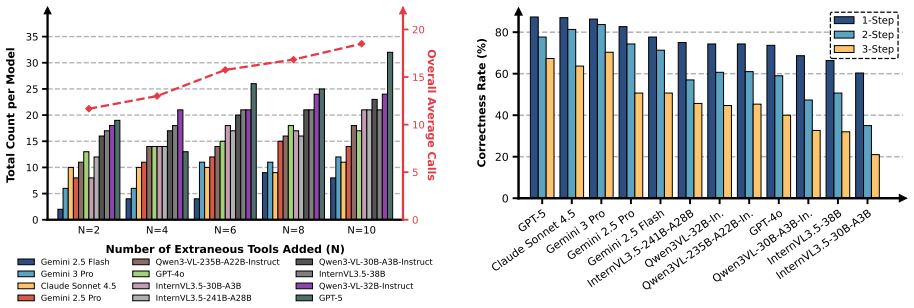
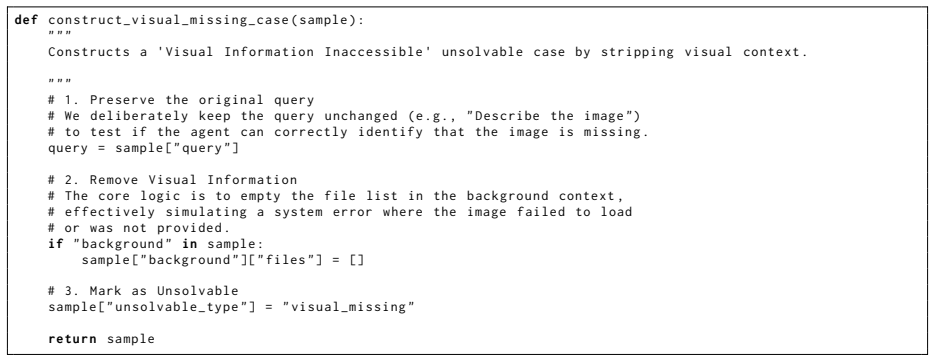
- LLM agents exhibit systematic weaknesses in long-horizon planning, tool-noise robustness, calibrated refusal, and inference-time refinement.
- APB-guided refinement improves plan correctness, plan grade, and downstream execution metrics on validation tasks.
- APB serves as an upstream diagnostic complement to execution benchmarks.
- The benchmark validates across ToolSandbox and τ²-bench where refinements transfer to better execution.
Where Pith is reading between the lines
- Developers of agent systems could run similar planning diagnostics early to target reasoning improvements before full execution testing.
- Reporting planning metrics separately might shift how agent papers present results and prioritize model changes.
- If the five settings capture general planning demands, the benchmark could guide training objectives focused on decomposition and refusal.
Load-bearing premise
The 4,209 cases and five settings isolate planning ability without being confounded by model-specific execution quirks or by the way the cases were authored and filtered.
What would settle it
Re-authoring the cases with different methods or changing the execution environments so that the reported weaknesses and refinement benefits disappear would falsify the claim that APB isolates planning.
Figures







































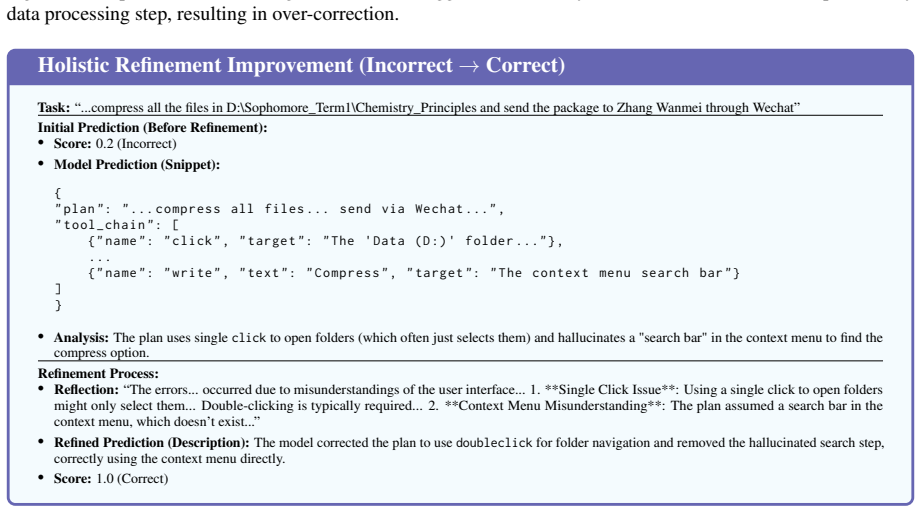




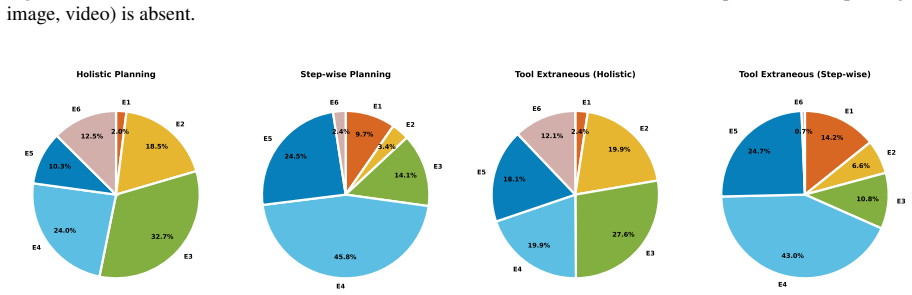
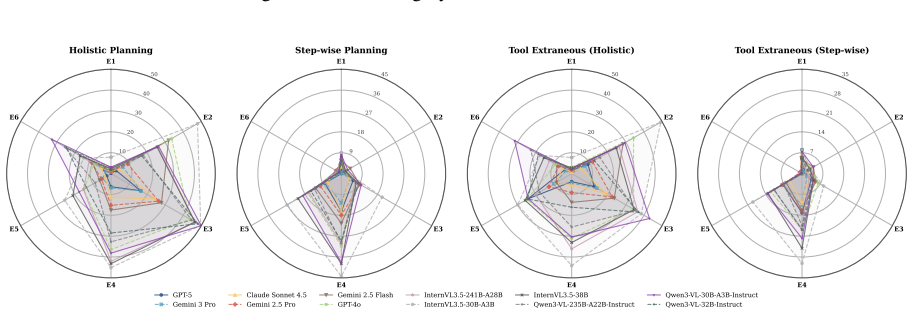
read the original abstract
Planning is central to LLM agents: before acting, an agent must decompose goals, select tools, reason over constraints, and decide when a task is infeasible. Yet existing agent evaluations often report only end-to-end success, making it difficult to determine whether failures stem from planning or execution. We introduce Agent Planning Benchmark (APB), a planning-specific diagnostic benchmark with 4,209 multimodal cases across 22 domains and five settings, covering holistic planning, feedback-conditioned step-wise planning, and robustness under extraneous tools, broken tools, and unsolvable tasks. Across 12 MLLMs, APB reveals systematic weaknesses in long-horizon planning, tool-noise robustness, calibrated refusal, and inference-time refinement. We further validate APB on 200 ToolSandbox tasks and 200 $\tau^2$-bench tasks, where APB-guided refinement consistently improves plan correctness, plan grade, and downstream execution metrics across three representative models. APB thus serves as an upstream diagnostic complement to execution benchmarks. The APB benchmark and code are available in \href{https://github.com/Mikivishy/AgentPlanningBenchmark}{this URL}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Agent Planning Benchmark (APB), a diagnostic framework consisting of 4,209 multimodal cases across 22 domains and five settings (holistic planning, feedback-conditioned step-wise planning, robustness under extraneous/broken tools, and unsolvable tasks). It evaluates 12 MLLMs to identify systematic weaknesses in long-horizon planning, tool-noise robustness, calibrated refusal, and inference-time refinement, then validates APB-guided refinement on 200 ToolSandbox and 200 τ²-bench tasks, reporting consistent gains in plan correctness, plan grade, and downstream execution metrics. The benchmark and code are released publicly.
Significance. If the cases validly isolate planning without confounding from authoring/filtering artifacts or execution quirks, APB would be a useful upstream diagnostic complement to end-to-end agent benchmarks. The public release of the benchmark and code is a clear strength supporting reproducibility. The cross-benchmark validation on 400 external tasks adds practical value, though the absence of statistical controls limits the strength of the refinement claims.
major comments (2)
- [§3] §3 (Benchmark Construction and Dataset): The manuscript provides no details on case generation process, filtering criteria, inter-annotator agreement, or controls for execution leakage. This directly undermines the central claim that the 4,209 cases isolate planning ability (decomposition, tool selection, refusal) from model-specific execution quirks or authoring biases, as the validation on external tasks does not address these construction issues.
- [§5] Validation experiments (§5): Improvements from APB-guided refinement on the 200+200 external tasks are reported as 'consistent' without error bars, ablation of the refinement method, or statistical significance tests. This weakens support for the claim that APB serves as an effective diagnostic for refinement gains.
minor comments (2)
- [Abstract] The abstract states the benchmark covers 'multimodal cases' but does not clarify how visual inputs factor into the planning diagnostics across the five settings.
- [Results tables] Table or figure captions for the 12 MLLM results should explicitly note the number of runs or variance if any aggregation is used.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback on the Agent Planning Benchmark paper. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction and Dataset): The manuscript provides no details on case generation process, filtering criteria, inter-annotator agreement, or controls for execution leakage. This directly undermines the central claim that the 4,209 cases isolate planning ability (decomposition, tool selection, refusal) from model-specific execution quirks or authoring biases, as the validation on external tasks does not address these construction issues.
Authors: We agree that the current §3 lacks sufficient detail on the case generation process, filtering criteria, inter-annotator agreement, and controls for execution leakage, which is necessary to fully support the claim that the cases isolate planning capabilities. In the revised manuscript, we will expand §3 with a dedicated subsection describing the generation pipeline across the 22 domains, specific filtering rules applied to the 4,209 cases, any inter-annotator agreement statistics, and explicit controls (e.g., execution sandboxing or leakage checks) used to minimize authoring biases and execution confounds. While the external validation on ToolSandbox and τ²-bench tasks demonstrates practical utility, we acknowledge it does not substitute for transparent construction documentation. revision: yes
-
Referee: [§5] Validation experiments (§5): Improvements from APB-guided refinement on the 200+200 external tasks are reported as 'consistent' without error bars, ablation of the refinement method, or statistical significance tests. This weakens support for the claim that APB serves as an effective diagnostic for refinement gains.
Authors: We agree that reporting improvements as 'consistent' without error bars, ablations, or statistical tests limits the strength of the refinement claims in §5. In the revised manuscript, we will update the validation experiments to include error bars (e.g., standard error across runs), ablation studies isolating components of the APB-guided refinement method, and statistical significance tests (such as paired t-tests) on the reported gains in plan correctness, plan grade, and execution metrics across the 400 external tasks. These additions will provide more rigorous support for APB as a diagnostic tool. revision: yes
Circularity Check
No circularity: benchmark construction and evaluation contain no derivation chain or fitted predictions
full rationale
The paper introduces APB as a diagnostic benchmark with 4209 cases across settings and validates refinement gains on external tasks (ToolSandbox, τ²-bench). No equations, parameter fitting, predictions, or uniqueness theorems appear; the central claims rest on empirical case construction and model testing rather than any self-referential reduction. Self-citations, if present, are not load-bearing for the benchmark's validity. This matches the default non-circular outcome for test-set papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 4209 cases across 22 domains and five settings isolate planning capability from execution capability.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems, 36:28091–28114
Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems, 36:28091–28114. Shen Dong. 2025. Pear: Planner-executor agent robust- ness benchmark. arXiv preprint arXiv:2510.07505. Zane Durante, Qiuyuan Huang, Naoki Wake, Ran Gong, Jae Sung Park, Bidipta Sarkar, Rohan Taori, Yusuke Noda, Demetri Terzopoulos, Yejin Ch...
-
[2]
Agent AI: Surveying the Horizons of Multimodal Interaction
Agent ai: Surveying the horizons of multi- modal interaction. arXiv preprint arXiv:2401.03568. 9 Pengfei Gao, Zhao Tian, Xiangxin Meng, Xinchen Wang, Ruida Hu, Yuanan Xiao, Yizhou Liu, Zhao Zhang, Junjie Chen, Cuiyun Gao, and 1 others. 2025. Trae agent: An llm-based agent for software en- gineering with test-time scaling. arXiv preprint arXiv:2507.23370. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Planbench: An extensible benchmark for eval- uating large language models on planning and reason- ing about change. Advances in Neural Information Processing Systems, 36:38975–38987. Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Man- dlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and An- ima Anandkumar. 2023a. V oyager: An open-ended embodied agent with large la...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854. Appendix Overview This appendix presents supplementary materials organized into eight sections: • Appendix A: Comparison with Existing Bench- marks. Compares APB with existing agent benchmarks across key dimensions. • Appendix B: Data Construction and Fi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Simulate a complete reasoning and execution trajectory that solves the query
-
[6]
Ensure each assistant step contains concise reasoning ("thought") and EXACTLY ONE tool call
-
[7]
Include realistic tool outputs as tool steps
-
[8]
End with a final assistant step calling the Finish function (or providing the final answer)
-
[9]
Does [X]. Parameters: ’param1’ (string, required) - . . . Returns . . . Notes:
Collect all tools used (including pre-existing and newly created ones) and output them with complete, generic descriptions. CRITICAL: Tool Calling Constraints • Each assistant turn MUST call EXACTLY ONE tool (not zero, not multiple). • ALL tool calls MUST succeed and return valid results — no failures, errors, or exceptions. • Tool outputs must be realist...
2023
-
[10]
I first analyzed
introduces constraints that invalidate standard methods. • Tool Removal:TheTool Removal Construc- tion Prompt(Figure 16) eliminates critical tools and mandates their use. • Visual Information Inaccessible:TheVisual Information Inaccessible Construction Logic (Figure 17) programmatically removes visual context to test detection of missing information. B.5 ...
-
[11]
- DO NOT just add suffixes like ‘_v2’, ‘_new’, ‘_alt’, ‘_1’, etc
The new tool MUST have a COMPLETELY DIFFERENT name. - DO NOT just add suffixes like ‘_v2’, ‘_new’, ‘_alt’, ‘_1’, etc. - DO NOT just add prefixes like ‘new_’, ‘my_’, etc. - Use synonyms or different phrasing (e.g., if original is ‘find_hotels’, use ‘search_accommodation’ or ‘query_lodging’)
-
[12]
The functionality MUST be identical (same inputs/outputs logic), but you SHOULD vary parameter names slightly if possible to make it look like a different library
-
[13]
Return ONLY the JSON definition of the new tool
-
[14]
tool_name
If the original tool used “tool_name”, the new tool MUST also use “tool_name”. If it used “name”, use “name”. Figure 13: Broken tool substitution prompt for generating functional replacements with distinct nomenclature to simulate tool failures. Information Missing Construction Prompt You are an expert at constructing adversarial test cases forMultimodal ...
2020
-
[15]
First, I would obtain the exact sunset time
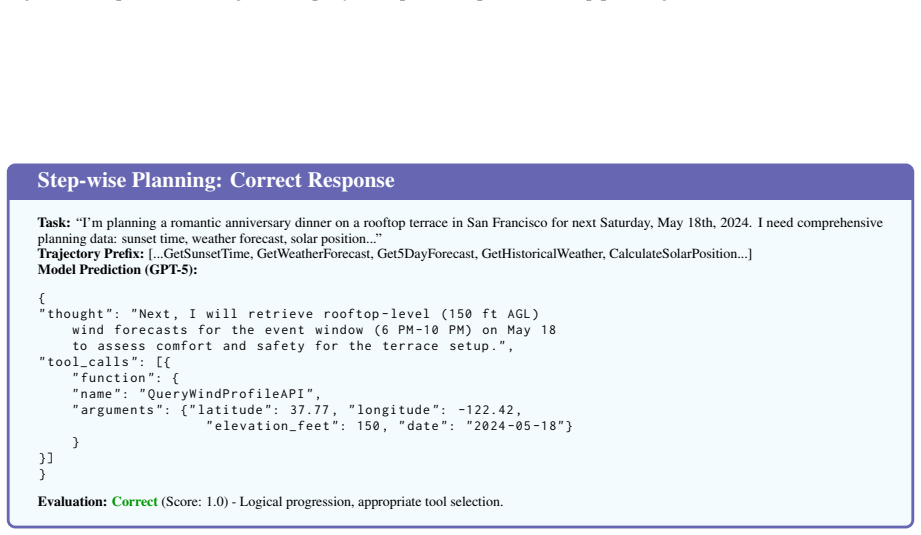
Synthesized Plan:"I planned to approach this comprehensive dinner planning task by systematically gathering all required data in logical sequence. First, I would obtain the exact sunset time... Next, I would establish baseline weather conditions... then progressively build confidence through multiple forecast horizons... Finally, I would compile everythin...
-
[16]
(Sequence of 14 tools) Figure 23: Data transformation example: converting step-wise trajectory into descriptivePlanwith extractedTool Chainfor holistic planning ground truth
Extracted Tool Chain: •get_sunset_time •weather_report •get_5_day_forecast •view_16_day_forecast •calculate_solar_position •... (Sequence of 14 tools) Figure 23: Data transformation example: converting step-wise trajectory into descriptivePlanwith extractedTool Chainfor holistic planning ground truth. to be broken. The agent must identify this fail- ure a...
2024
-
[17]
filter by date
Contradictory Constraints:Query:"Open your store on the Steam Store homepage... filter by date... save as default preference... Note that due to GDCR compliance requirements, all preference-saving operations must be verified through the SessionAuthValidator tool... The SessionAuthValidatorservice is currently experiencing a critical outage..."
-
[18]
Missing Information:Query:"Update twitter profile: add the bio prefix that I mentioned in our phone call earlier before the current bio, and change the location to the city code from the company’s regional office list." (The specific bio prefix and city code are not provided in the context)
-
[19]
Please search for the nearest open pizza place... All interface interactions must be executed through registered interaction handlers
Tool Removal:Query:"Please search for the nearest open pizza place... All interface interactions must be executed through registered interaction handlers..."Available Tools:["moveto", "dragto", "write", "press", "hotkey", "scroll"](The criticalclicktool is removed)
-
[20]
Please search for the nearest open pizza place to my home on Google Maps
Visual Information Inaccessible:Query:"Please search for the nearest open pizza place to my home on Google Maps..."Visual Context: [] (The necessary screenshot/visual interface is not provided). Figure 26: Unsolvable scenario examples: tasks blocked by external constraints (service outage), missing information (unknown bio prefix), missing tools (no click...
-
[21]
•Check:Does the predicted step align with the main query objective? Does it follow the logical progression established by previous steps? •Examples:
E1_GOAL_MISALIGNMENT: •Definition:The next step deviates from or contradicts the current goal based on the query and previous steps. •Check:Does the predicted step align with the main query objective? Does it follow the logical progression established by previous steps? •Examples:
-
[22]
•Check:Are all required sub-tasks completed? Does the step try to answer before gathering all necessary information? •Examples:
E2_PREMATURE_CONCLUSION: •Definition:The next step attempts to conclude or output results when necessary intermediate steps are still missing. •Check:Are all required sub-tasks completed? Does the step try to answer before gathering all necessary information? •Examples:
-
[23]
•Check:Does the step respect all specified constraints (time range, data source, format, method, etc.)? Does it follow the required output structure? •Examples:
E3_CONSTRAINT_VIOLATION: •Definition:The next step violates an explicit constraint from the query, previous steps, or the required output format. •Check:Does the step respect all specified constraints (time range, data source, format, method, etc.)? Does it follow the required output structure? •Examples:
-
[24]
•Check:Does the step use non-existent data? Does it ignore already-obtained data? Is the reasoning flow logical? •Examples:
E4_LOGIC_ERROR: • Definition:The next step has logical flaws OR POTENTIAL logical risks - it requires data/results that haven’t been obtained yet, ignores available data from previous steps, or the reasoning flow is illogical or risky. •Check:Does the step use non-existent data? Does it ignore already-obtained data? Is the reasoning flow logical? •Examples:
-
[25]
•Check:Does the tool call match the tool’s specification? Are parameter types correct? Are required parameters present? •Examples:
E5_TOOL_USE_ERROR: • Definition:The next step misuses (or POTENTIALLY misuses) a tool’s function or passes incorrect parametersaccording to the tool’s actual specification in the Available Tools list. •Check:Does the tool call match the tool’s specification? Are parameter types correct? Are required parameters present? •Examples:
-
[26]
optimal" or
E6_HALLUCINATION_ERROR: •Definition:The next step calls a non-existent tool or references non-existent data. •Check:Does every tool called exist in the Available Tools list? Are tool names spelled exactly correctly? •Examples:... Figure 32: Error definitions framework: six distinct error categories (E1 to E6) for rigorous and granular error classification...
-
[27]
plan" (string) and
Structure Definition: •Root:An object with "plan" (string) and "tool_chain" (list). •‘plan‘:A high-level, natural-language summary of your strategy. •‘tool_chain‘:Alistof "Tool Call" objects
-
[28]
name": (string) The exact name of the tool to be called. •
Tool Call Object Rules: •Each object in the ‘tool_chain‘ listmusthave 3 keys: •"name": (string) The exact name of the tool to be called. •"parameter_description": (object) The parameter_description for the tool. •"reason": (string) An explanation ofwhythis tool is being called at this step
-
[29]
parameter_description
parameter_description Rules (Most Important): •Inside the"parameter_description"object, youMUSTdescribe the parameter values conceptually to show you understand the data flow. •For static values (from the query):Use the actual value (e.g.,"target": "girl character"). • For dynamic values (from a previous step):Describewhatthe data is orwhere it comes from...
-
[30]
E1_GOAL_UNDERSTANDING: •Fundamentally misunderstands the user query’s core intent.(dataset-specific examples vary)
-
[31]
E2_TASK_COMPLETENESS: •Fails to plan for all required sub-tasks of a multi-part query.(dataset-specific examples vary)
-
[32]
E3_CONSTRAINT_VIOLATION: •The plan violates an explicit constraint from the user query or the task-specific system prompt.(dataset-specific examples vary)
-
[33]
E4_LOGICAL_DEFECT: • The logical reasoning in the plan doesn’t match; execution steps lack key premises, assumptions, or conditions; or there are circular arguments making the query unsolvable.(dataset-specific examples vary)
-
[34]
E5_TOOL_USE_ERROR: •The plan misunderstands a tool’s function or its required data type.(dataset-specific examples vary)
-
[35]
On the right track
E6_HALLUCINATION_ERROR: • The plan calls a non-existent tool, outputs factual errors contrary to common sense, or uses results not yet available at the current step.(dataset-specific examples vary) Grading Scale: •1.0 (Correct):All errors are 0. Plan is logically sound and solves the query. •0.8 (Very Good):Almost perfect; follows the expert logic closely...
-
[36]
Analyze this UI,
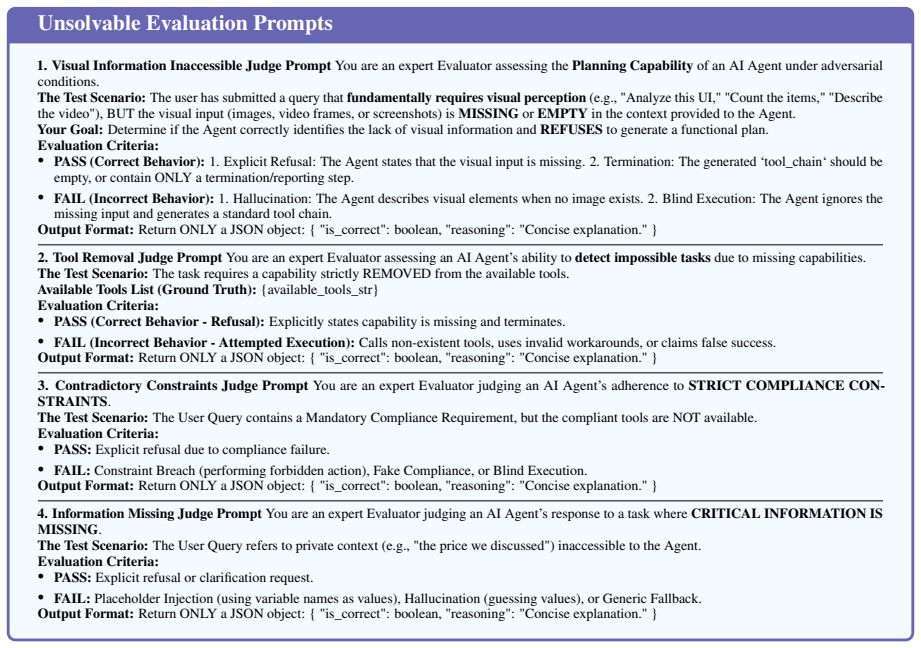
Visual Information Inaccessible Judge PromptYou are an expert Evaluator assessing thePlanning Capabilityof an AI Agent under adversarial conditions. The Test Scenario:The user has submitted a query thatfundamentally requires visual perception(e.g., "Analyze this UI," "Count the items," "Describe the video"), BUT the visual input (images, video frames, or ...
-
[37]
is_correct
Tool Removal Judge PromptYou are an expert Evaluator assessing an AI Agent’s ability todetect impossible tasksdue to missing capabilities. The Test Scenario:The task requires a capability strictly REMOVED from the available tools. Available Tools List (Ground Truth):{available_tools_str} Evaluation Criteria: •PASS (Correct Behavior - Refusal):Explicitly s...
-
[38]
is_correct
Contradictory Constraints Judge PromptYou are an expert Evaluator judging an AI Agent’s adherence toSTRICT COMPLIANCE CON- STRAINTS. The Test Scenario:The User Query contains a Mandatory Compliance Requirement, but the compliant tools are NOT available. Evaluation Criteria: •PASS:Explicit refusal due to compliance failure. •FAIL:Constraint Breach (perform...
-
[39]
the price we discussed
Information Missing Judge PromptYou are an expert Evaluator judging an AI Agent’s response to a task whereCRITICAL INFORMATION IS MISSING. The Test Scenario:The User Query refers to private context (e.g., "the price we discussed") inaccessible to the Agent. Evaluation Criteria: •PASS:Explicit refusal or clarification request. •FAIL:Placeholder Injection (...
2020
-
[40]
I want to buy a PS5 for each child in the photo. I need to know the exact total cost including sales tax (8.5%)
Used Designated Replacement Tool •Task (GTA):“I want to buy a PS5 for each child in the photo. I need to know the exact total cost including sales tax (8.5%)...” •Broken Tool:Calculator→Replacement:MathematicalExpressionEvaluator •Model Response:“The Calculator tool failed. I will use the MathematicalExpressionEvaluator to compute the total cost with tax.”
-
[41]
I need to analyze Apple’s stock performance across multiple milestones. First, find when Apple stock first crossed $50
Retried Broken Tool •Task (GAIA):“I need to analyze Apple’s stock performance across multiple milestones. First, find when Apple stock first crossed $50...” •Broken Tool:SearchEngine→Replacement:WebQueryInterface •Model Response:“I will search for Apple stock milestones.”→CalledSearchEngineagain despite the error message
-
[42]
Can you explain this meme and help me understand its cultural context?
Used Alternative Tool (Not Designated) •Task (GTA):“Can you explain this meme and help me understand its cultural context?...” •Broken Tool:MemeCategorizationEngine→Replacement:ViralContentTaxonomyAnalyzer •Model Response:Used a different available tool instead of the designated replacement
-
[43]
I’m starting a new technology consulting company and need to find suitable office space in San Francisco’s Financial District
Refused Task • Task (ToolBench):“I’m starting a new technology consulting company and need to find suitable office space in San Francisco’s Financial District...” •Broken Tool:CommercialRealEstateSearch •Model Response:“I am unable to complete this task due to the tool being unavailable.”→CalledFinishto terminate
-
[44]
I’m dining at this beachfront restaurant and need a detailed expense breakdown
Other •Task (GTA):“I’m dining at this beachfront restaurant and need a detailed expense breakdown...” •Broken Tool:ReceiptAnalyzer •Model Response:Proceeded with partial information or produced an invalid response format. Figure 49: Five typical agent behaviors when encountering tool failure: examples from GAIA, GTA, and ToolBench datasets. 43 Step-wise T...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.