Intuition-Guided Latent Reasoning for LLM-Based Recommendation
Pith reviewed 2026-06-29 03:42 UTC · model grok-4.3
The pith
IntuRec anchors latent reasoning in LLM recommenders by injecting an intuition embedding derived from top-K candidate sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
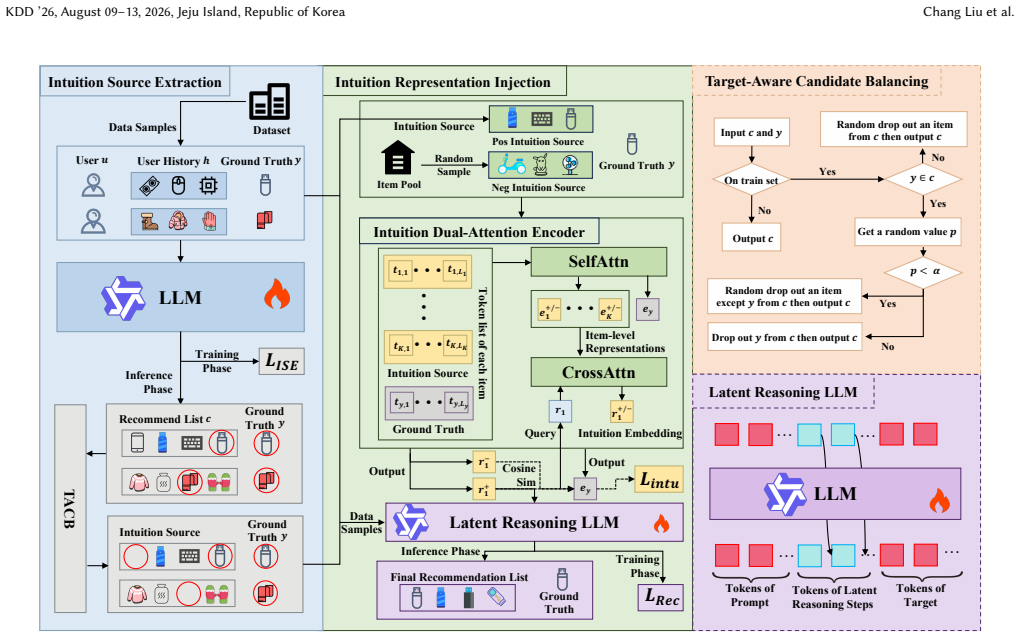
IntuRec is a two-stage framework. The extraction stage has the LLM-based recommender produce a top-K candidate set from user histories as the source of recommendation intuition. The injection stage applies self- and cross-attention to turn the candidate set into a preference-aligned intuition embedding that initializes the latent reasoning start point and guides subsequent steps in the continuous hidden space, yielding more accurate reasoning trajectories toward target items.
What carries the argument
The recommendation intuition embedding, obtained by transforming the top-K candidate set through self- and cross-attention, which initializes the latent reasoning start point and steers the trajectory in hidden space.
If this is right
- Latent reasoning follows more accurate trajectories through preference space.
- The two-stage process yields consistent outperformance over state-of-the-art baselines on multiple real-world datasets.
- Recommendation intuition functions as a semantically grounded prior that improves exploration efficiency.
Where Pith is reading between the lines
- The same candidate-to-embedding injection could be tested in non-recommendation LLM reasoning tasks that also suffer from poor starting alignments.
- Dynamic updating of the intuition embedding mid-reasoning might further tighten trajectories beyond the current fixed initialization.
- If the attention-based injection proves robust, it could reduce reliance on extensive prompt engineering or additional fine-tuning stages in LLM recommenders.
Load-bearing premise
The top-K candidate set produced by the base LLM from user histories supplies a preference-aligned intuition that can be turned into an embedding to initialize and guide reasoning without adding misalignment.
What would settle it
Running the same latent reasoning process with the intuition injection stage removed or replaced by a random start point and observing no drop or an increase in recommendation accuracy on the same datasets would falsify the benefit of the grounded starting point.
Figures

read the original abstract
Large Language Models (LLMs) have demonstrated impressive reasoning capabilities in complex problem-solving tasks, motivating their use for preference reasoning in recommender systems. Latent reasoning, which operates in continuous hidden spaces rather than discrete tokens, has recently emerged as a promising paradigm for LLM-based recommendation. However, existing methods often start from unconstrained reasoning points, where hidden representations are misaligned with target item embeddings, leading to suboptimal reasoning trajectories. Inspired by cognitive neuroscience, which suggests that human multi-step reasoning is guided by intuition as a latent prior, we propose \emph{IntuRec}, a two-stage framework that anchors latent reasoning with \emph{recommendation intuition}. In the extraction stage, the LLM-based recommender generates a top-$K$ candidate set based on users' histories as the source of intuition. In the injection stage, the candidate set is transformed into a preference-aligned intuition embedding using self- and cross-attention mechanisms, which initializes the reasoning start point and guides subsequent latent reasoning. By providing a semantically grounded starting point, IntuRec efficiently explores the preference space along more accurate reasoning trajectories. Extensive experiments on multiple real-world datasets demonstrate that IntuRec consistently outperforms state-of-the-art baselines. We release our code at https://github.com/Ten-Mao/IntuRec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing LLM-based latent reasoning methods for recommendation suffer from misalignment due to unconstrained starting points in hidden space. It proposes IntuRec, a two-stage method: an extraction stage generates a top-K candidate set from user histories via a base LLM recommender as 'recommendation intuition,' followed by an injection stage that uses self- and cross-attention to produce a preference-aligned embedding. This embedding initializes the latent reasoning start point and guides trajectories, yielding more accurate preference exploration and outperforming SOTA baselines on real-world datasets.
Significance. If the central empirical claims hold after verification, the work could meaningfully advance LLM-based recommender systems by addressing a plausible source of suboptimal trajectories in latent reasoning. The neuroscience-inspired framing and code release are positive for reproducibility and follow-up work.
major comments (2)
- [Abstract / Method description] The load-bearing assumption that the top-K candidate set (generated by the base LLM from user histories) can be transformed via self- and cross-attention into an embedding that reliably initializes and guides latent reasoning without introducing misalignment is stated in the abstract but lacks any equations, loss terms, or alignment verification in the provided description. This directly underpins the claimed advantage over unconstrained points.
- [Experiments] No ablation studies, error analysis, or quantitative checks (e.g., cosine similarity between intuition embedding and target item embeddings, or trajectory quality metrics) are referenced to test whether the injection stage preserves semantic alignment, making it impossible to assess if the reported gains stem from the proposed mechanism or other factors.
minor comments (1)
- [Abstract] The abstract mentions 'extensive experiments on multiple real-world datasets' but provides no dataset names, metrics, or baseline details; these should be summarized with key numbers for context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarifying the methodological details and strengthening the experimental validation. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract / Method description] The load-bearing assumption that the top-K candidate set (generated by the base LLM from user histories) can be transformed via self- and cross-attention into an embedding that reliably initializes and guides latent reasoning without introducing misalignment is stated in the abstract but lacks any equations, loss terms, or alignment verification in the provided description. This directly underpins the claimed advantage over unconstrained points.
Authors: The abstract is intentionally high-level due to length constraints. The full manuscript provides the detailed equations for the self- and cross-attention mechanisms in the injection stage (Section 3.2), along with the overall training objective and loss terms (Section 3.3). To directly address the concern, we will add explicit alignment verification (e.g., cosine similarity metrics) and a brief reference to these equations in the revised abstract where space allows, or strengthen the pointer to the method section. revision: yes
-
Referee: [Experiments] No ablation studies, error analysis, or quantitative checks (e.g., cosine similarity between intuition embedding and target item embeddings, or trajectory quality metrics) are referenced to test whether the injection stage preserves semantic alignment, making it impossible to assess if the reported gains stem from the proposed mechanism or other factors.
Authors: We acknowledge that the current experiments section focuses on overall performance comparisons without the specific ablations and alignment checks mentioned. In the revision, we will add ablation studies isolating the injection stage, error analysis, cosine similarity measurements between the intuition embedding and target item embeddings, and trajectory quality metrics to verify semantic alignment and confirm that performance gains arise from the proposed mechanism. revision: yes
Circularity Check
No circularity; method is a proposed architecture validated externally
full rationale
The provided text (abstract and description) contains no equations, fitted parameters renamed as predictions, or self-citation chains. The two-stage extraction/injection process is defined independently; claimed gains rest on experimental comparison to baselines rather than reducing to input definitions or prior self-work by construction. This matches the default case of a self-contained proposal against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- K
axioms (1)
- domain assumption Human multi-step reasoning is guided by intuition as a latent prior
invented entities (1)
-
recommendation intuition embedding
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Zhuoxi Bai, Ning Wu, Fengyu Cai, Xinyi Zhu, and Yun Xiong. 2024. Aligning large language model with direct multi-preference optimization for recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 76–86
2024
-
[3]
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yanchen Luo, Chong Chen, Fuli Feng, and Qi Tian. 2025. A bi-step grounding paradigm for large language models in recommendation systems.ACM Transactions on Recommender Systems3, 4 (2025), 1–27
2025
-
[4]
Keqin Bao, Jizhi Zhang, Yang Zhang, Xinyue Huo, Chong Chen, and Fuli Feng
-
[5]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Decoding Matters: Addressing Amplification Bias and Homogeneity Issue in Recommendations for Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Miami, Florida, USA, 10540–10552
2024
-
[6]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. InProceedings of the 17th ACM conference on recommender systems. 1007–1014
2023
-
[7]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wang Wenjie, Fuli Feng, and Xiangnan He. 2023. Large Language Models for Recommendation: Progresses and Future Directions. InProceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region (Beijing, China)(SIGIR-AP ’23). Association for Computi...
2023
- [8]
- [9]
-
[10]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [11]
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
- [13]
- [14]
-
[15]
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. 2020. Shortcut learn- ing in deep neural networks.Nature Machine Intelligence2, 11 (2020), 665–673
2020
-
[16]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM conference on recommender systems. 299–315
2022
-
[17]
Vinod Goel. 2009. Cognitive neuroscience of thinking.Handbook of neuroscience for the behavioral sciences1 (2009), 417–430
2009
-
[18]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. 2025. Seed1.5-vl technical report. arXiv preprint arXiv:2505.07062(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al . 2025. DeepSeek-R1 in- centivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
-
[20]
Zihao Guo, Jian Wang, Ruxin Zhou, Youhua Liu, Jiawei Guo, Jun Zhao, Xiaox- iao Xu, Yongqi Liu, and Kaiqiao Zhan. 2026. S2GR: Stepwise Semantic-Guided Reasoning in Latent Space for Generative Recommendation.arXiv preprint arXiv:2601.18664(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. 2024. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Yingzhi He, Xiaohao Liu, An Zhang, Yunshan Ma, and Tat-Seng Chua. 2025. LLM2Rec: Large Language Models Are Powerful Embedding Models for Sequen- tial Recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2(Toronto ON, Canada)(KDD ’25). Association for Computing Machinery, New York, NY, USA, 896–907
2025
-
[23]
Balázs Hidasi and Alexandros Karatzoglou. 2018. Recurrent Neural Networks with Top-k Gains for Session-based Recommendations. InProceedings of the 27th ACM International Conference on Information and Knowledge Management (Torino, Italy)(CIKM ’18). Association for Computing Machinery, New York, NY, USA, 843–852
2018
-
[24]
Ninja K Horr, Christoph Braun, and Kirsten G Volz. 2014. Feeling before knowing why: The role of the orbitofrontal cortex in intuitive judgments—an MEG study. Cognitive, Affective, & Behavioral Neuroscience14, 4 (2014), 1271–1285
2014
-
[25]
Wenyue Hua, Shuyuan Xu, Yingqiang Ge, and Yongfeng Zhang. 2023. How to index item ids for recommendation foundation models. InProceedings of the KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Chang Liu et al. Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region. 195–204
2023
-
[26]
Kushal Jain, Moritz Miller, Niket Tandon, and Kumar Shridhar. 2025. First- Step Advantage: Importance of Starting Right in Multi-Step Math Reasoning. In Findings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics, Vienna, Austria, 766–778
2025
-
[27]
Daniel Kahneman. 2011. Thinking, fast and slow.Farrar, Straus and Giroux (2011)
2011
-
[28]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, IEEE Computer Society, 197–206
2018
-
[29]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakr- ishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al
-
[30]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Peter Kok, Gijs Joost Brouwer, Marcel AJ van Gerven, and Floris P de Lange
-
[32]
Prior expectations bias sensory representations in visual cortex.Journal of Neuroscience33, 41 (2013), 16275–16284
2013
-
[33]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. 2024. LLaRA: Large Language-Recommendation Assistant. In Proceedings of the 47th International ACM SIGIR Conference on Research and Devel- opment in Information Retrieval(Washington DC, USA)(SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 1785–1795
2024
-
[34]
Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Hao Zhang, Yong Liu, Chuhan Wu, Xiangyang Li, Chenxu Zhu, Huifeng Guo, Yong Yu, Ruiming Tang, and Weinan Zhang. 2025. How Can Recommender Systems Benefit from Large Language Models: A Survey.ACM Trans. Inf. Syst.43, 2, Article 28 (Jan. 2025), 47 pages
2025
-
[35]
Zijie Lin, Yang Zhang, Xiaoyan Zhao, Fengbin Zhu, Fuli Feng, and Tat-Seng Chua. 2026. Igd: Token decisiveness modeling via information gain in llms for personalized recommendation.Advances in Neural Information Processing Systems 38 (2026), 78113–78136
2026
-
[36]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [37]
- [38]
-
[39]
Zhanyu Liu, Shiyao Wang, Xingmei Wang, Rongzhou Zhang, Jiaxin Deng, Honghui Bao, Jinghao Zhang, Wuchao Li, Pengfei Zheng, Xiangyu Wu, et al
- [40]
-
[41]
Earl K Miller and Jonathan D Cohen. 2001. An integrative theory of prefrontal cortex function.Annual review of neuroscience24, 1 (2001), 167–202
2001
-
[42]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, ...
2019
-
[43]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[45]
InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence(Montreal, Quebec, Canada)(UAI ’09)
BPR: Bayesian personalized ranking from implicit feedback. InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence(Montreal, Quebec, Canada)(UAI ’09). AUAI Press, Arlington, Virginia, USA, 452–461
-
[46]
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. 2025. Codi: Compressing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 677–693
2025
-
[47]
Leheng Sheng, An Zhang, Yi Zhang, Yuxin Chen, Xiang Wang, and Tat-Seng Chua
-
[48]
InInternational Conference on Learning Representations, Vol
Language Representations Can be What Recommenders Need: Findings and Potentials. InInternational Conference on Learning Representations, Vol. 2025. 91632–91658
2025
- [49]
-
[50]
Jiakai Tang, Sunhao Dai, Teng Shi, Jun Xu, Xu Chen, Wen Chen, Jian Wu, and Yuning Jiang. 2026. Think before recommend: Unleashing the latent reasoning power for sequential recommendation.IEEE Transactions on Knowledge and Data Engineering(2026)
2026
-
[51]
Jiaxi Tang and Ke Wang. 2018. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding. InProceedings of the Eleventh ACM International Conference on Web Search and Data Mining(Marina Del Rey, CA, USA)(WSDM ’18). Association for Computing Machinery, New York, NY, USA, 565–573
2018
-
[52]
Chi, and Xinyang Yi
Alicia Tsai, Adam Kraft, Long Jin, Chenwei Cai, Anahita Hosseini, Taibai Xu, Zemin Zhang, Lichan Hong, Ed H. Chi, and Xinyang Yi. 2024. Leveraging LLM Reasoning Enhances Personalized Recommender Systems. InFindings of the As- sociation for Computational Linguistics: ACL 2024. Association for Computational Linguistics, Bangkok, Thailand, 13176–13188
2024
- [53]
-
[54]
Tongzhou Wang and Phillip Isola. 2020. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InProceedings of the 37th International Conference on Machine Learning (ICML’20). JMLR.org, Article 921, 11 pages
2020
- [55]
-
[56]
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al . 2024. A survey on large language models for recommendation.World Wide Web27, 5 (2024), 60
2024
- [57]
-
[58]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [59]
-
[60]
Runyang You, Yongqi Li, Xinyu Lin, Xin Zhang, Wenjie Wang, Wenjie Li, and Liqiang Nie. 2025. R 2ec: Towards Large Recommender Models with Reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[61]
Weiqi Yue, Yuyu Yin, Xin Zhang, Binbin Shi, Tingting Liang, and Jian Wan. 2025. CoT4Rec: Revealing User Preferences Through Chain of Thought for Recom- mender Systems.Proceedings of the AAAI Conference on Artificial Intelligence39, 12 (Apr. 2025), 13142–13151
2025
-
[62]
Junjie Zhang, Ruobing Xie, Yupeng Hou, Xin Zhao, Leyu Lin, and Ji-Rong Wen
-
[63]
Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach.ACM Trans. Inf. Syst.43, 5, Article 114 (July 2025), 37 pages
2025
- [64]
- [65]
-
[66]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). 1435–1448
2024
- [67]
- [68]
-
[69]
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, et al. 2025. Onerec-v2 technical report.arXiv preprint arXiv:2508.20900(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Rui-Jie Zhu, Tianhao Peng, Tianhao Cheng, Xingwei Qu, Jinfa Huang, Dawei Zhu, Hao Wang, Kaiwen Xue, Xuanliang Zhang, Yong Shan, et al. 2025. A survey on latent reasoning.arXiv preprint arXiv:2507.06203(2025). Intuition-Guided Latent Reasoning for LLM-Based Recommendation KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea A More Dataset Validation...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.