xModel-KD: Cross-modal Knowledge Distillation for 3D Scene Perception using LiDAR
Pith reviewed 2026-06-29 08:20 UTC · model grok-4.3
The pith
Cross-modal fusion aligns 2D image cues with 3D LiDAR points to raise segmentation accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
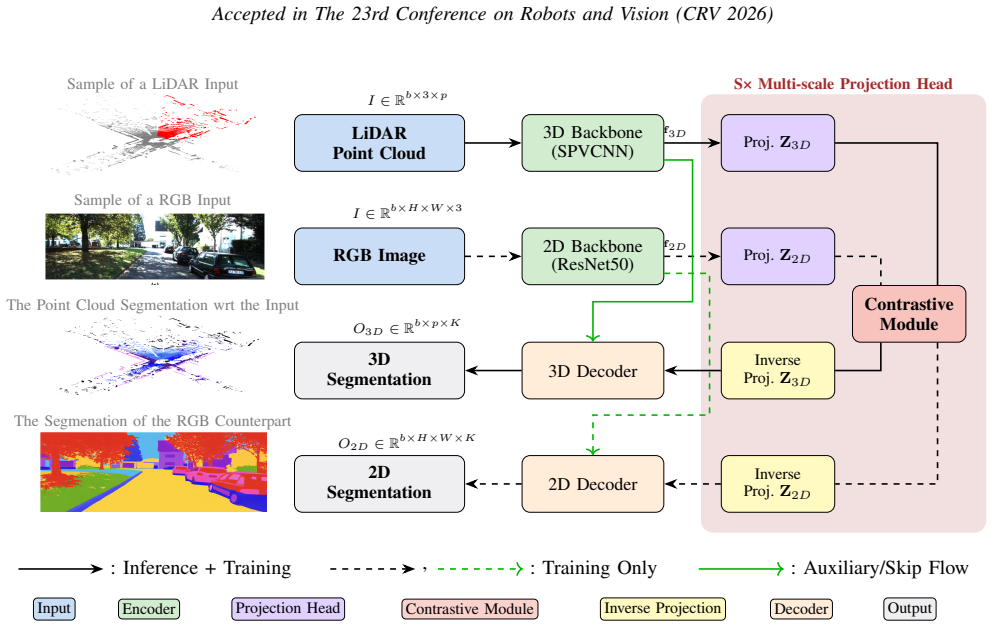
A cross-modal fusion encoder trained with a contrastive objective on 2D-3D correspondences across views transfers appearance cues from images to geometry-aware point features, producing unified representations that improve segmentation.
What carries the argument
Cross-modal fusion encoder with contrastive objective enforcing feature consistency between corresponding 2D and 3D representations across multiple views.
If this is right
- Unified per-point features become feasible for dense 3D prediction tasks.
- Pre-trained 2D backbones can be leveraged directly for 3D scene understanding.
- Annotation-efficient training becomes viable when paired 2D-3D data exist.
- Multi-view consistency reduces reliance on single-modality limitations.
Where Pith is reading between the lines
- The same alignment strategy could extend to 3D object detection or tracking if corresponding labels are available.
- Gains may depend on the degree of spatial registration between image and LiDAR inputs.
- Adding a third modality such as radar would test whether the contrastive fusion generalizes beyond image-point pairs.
Load-bearing premise
The contrastive alignment between 2D and 3D features transfers useful appearance information without introducing misalignment or domain noise that harms the point features.
What would settle it
An experiment on held-out datasets that shows the cross-modal component produces no mIoU gain or a net loss compared with the LiDAR-only baseline would falsify the claimed benefit.
Figures

read the original abstract
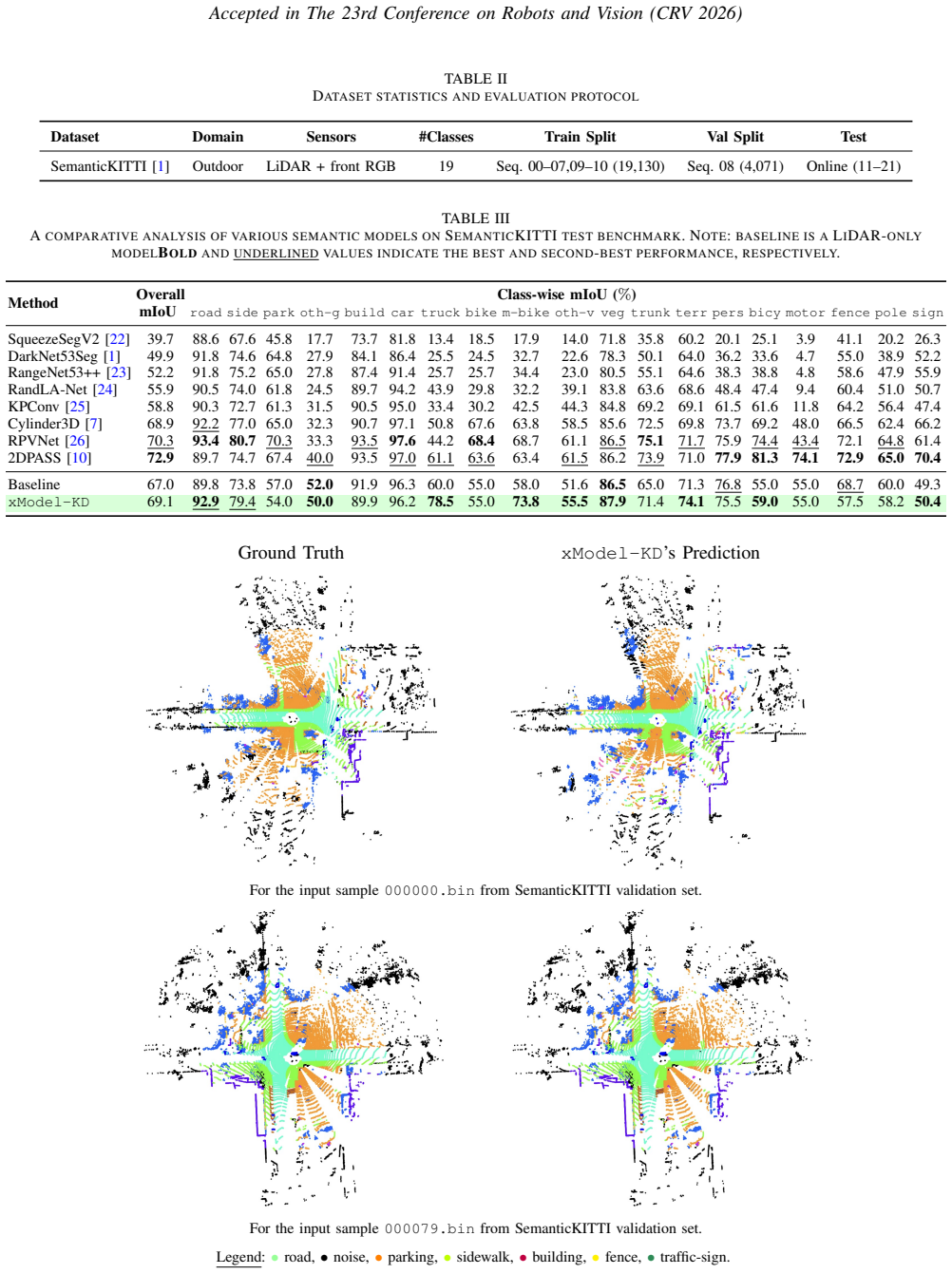
Point cloud segmentation is a fundamental task in 3D scene understanding. Its progress is constrained by the high cost and time required for dense 3D annotations, making labeled samples difficult to obtain. Beyond annotation scarcity, different sensing modalities face inherent limitations. 2D images provide rich texture and appearance cues, yet they lack explicit depth and geometric structure. In contrast, 3D point clouds capture accurate spatial geometry but are sparse and contain no texture information. As a result, relying on a single modality restricts the richness of learned representations and weakens generalization. Although recent multi-modal methods that combine 3D point clouds with 2D images have demonstrated strong performance in tasks such as classification and retrieval, they typically depend on large-scale labeled datasets and have not been fully exploited for data-efficient dense prediction. To address these limitations, we propose a novel cross-modal knowledge distillation framework, xModel-KD, for 3D point cloud segmentation. Our method exploits the complementary strengths of 2D texture and 3D geometry by learning unified per-point representations through cross-modal alignment. Specifically, we design a cross-modal fusion encoder trained with a contrastive objective that enforces feature consistency between corresponding 2D and 3D representations across multiple views. By integrating powerful pre-trained backbones with a targeted fusion strategy, the proposed framework effectively transfers appearance cues from images to geometry-aware point features. Experimental results show that cross-modal fusion achieves a 2% absolute improvement in mIoU over a LiDAR-only baseline, demonstrating the benefit of leveraging complementary multi-modal information for scalable and annotation-efficient 3D scene understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes xModel-KD, a cross-modal knowledge distillation framework for LiDAR-based 3D point cloud segmentation. It introduces a cross-modal fusion encoder trained with a contrastive objective to align per-point 3D features with corresponding 2D image features from multiple views, transferring appearance cues from pre-trained 2D backbones to geometry-aware point features. The central empirical claim is a 2% absolute mIoU improvement over a LiDAR-only baseline, positioned as enabling more scalable and annotation-efficient 3D scene understanding.
Significance. If the reported gain is reproducible on standard benchmarks with proper controls, the method would illustrate a practical route to leverage readily available 2D pre-trained models for improving 3D dense prediction without additional 3D labels. The contrastive multi-view alignment is a standard technique in multi-modal KD, so the contribution would lie primarily in its targeted application to point-cloud segmentation rather than in novel algorithmic machinery.
major comments (2)
- [Abstract] Abstract: the claim that 'cross-modal fusion achieves a 2% absolute improvement in mIoU over a LiDAR-only baseline' supplies neither the dataset name, the precise LiDAR-only baseline architecture, the number of runs, error bars, nor any ablation isolating the contrastive term. Without these elements the central experimental result cannot be evaluated and is therefore load-bearing for the paper's main claim.
- [Abstract] Abstract (and presumably §4): the description of the contrastive objective does not address how point-to-pixel correspondences are obtained across views or how misalignment between modalities is mitigated; if correspondences are noisy the transferred appearance cues could degrade rather than improve segmentation performance, directly affecting the weakest assumption underlying the 2% gain.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and methodological clarity. We will revise the manuscript to incorporate the requested details and explanations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'cross-modal fusion achieves a 2% absolute improvement in mIoU over a LiDAR-only baseline' supplies neither the dataset name, the precise LiDAR-only baseline architecture, the number of runs, error bars, nor any ablation isolating the contrastive term. Without these elements the central experimental result cannot be evaluated and is therefore load-bearing for the paper's main claim.
Authors: We agree that the abstract is insufficiently specific. In the revised version we will expand the abstract to name the dataset, identify the exact LiDAR-only baseline architecture, state that results are averaged over three independent runs with standard deviation, and reference the ablation study that isolates the contribution of the contrastive term. These additions will make the central empirical claim directly evaluable. revision: yes
-
Referee: [Abstract] Abstract (and presumably §4): the description of the contrastive objective does not address how point-to-pixel correspondences are obtained across views or how misalignment between modalities is mitigated; if correspondences are noisy the transferred appearance cues could degrade rather than improve segmentation performance, directly affecting the weakest assumption underlying the 2% gain.
Authors: We acknowledge the need for explicit description. The current abstract omits these implementation details due to length limits. In the revision we will add a concise statement in the abstract and expand §4 to explain that correspondences are obtained via camera-LiDAR extrinsic calibration matrices for projection across multiple views, with misalignment mitigated by a multi-view consistency filter and a spatially-aware contrastive loss that down-weights unreliable pairs. This will directly address the concern about potential degradation from noisy alignments. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes xModel-KD, a cross-modal knowledge distillation framework for LiDAR-based 3D segmentation that uses contrastive alignment between 2D and 3D features. Its central claim is an empirical 2% mIoU gain over a LiDAR-only baseline, presented as the outcome of training the described encoder and fusion strategy on standard benchmarks. No equations, uniqueness theorems, or parameter-fitting steps are shown that reduce the reported improvement to a self-definitional identity, a renamed input, or a self-citation chain; the result is framed as an experimental measurement rather than a derived quantity forced by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Semantickitti: A dataset for semantic scene understanding of lidar sequences,
J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “Semantickitti: A dataset for semantic scene understanding of lidar sequences,” inProceedings of the IEEE/CVF international conf. on computer vision, 2019, pp. 9297–9307
2019
-
[2]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Kr- ishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conf. on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[3]
Pointconv: Deep convolutional networks on 3d point clouds,
W. Wu, Z. Qi, and L. Fuxin, “Pointconv: Deep convolutional networks on 3d point clouds,” inProceedings of the IEEE/CVF conf. on computer vision and pattern recognition, 2019, pp. 9621–9630
2019
-
[4]
Efficient piecewise training of deep structured models for semantic segmentation,
G. Lin, C. Shen, A. Van Den Hengel, and I. Reid, “Efficient piecewise training of deep structured models for semantic segmentation,” inPro- ceedings of the IEEE conf. on computer vision and pattern recognition, 2016, pp. 3194–3203
2016
-
[5]
Ccnet: Criss-cross attention for semantic segmentation,
Z. Huang, X. Wang, L. Huang, C. Huang, Y . Wei, and W. Liu, “Ccnet: Criss-cross attention for semantic segmentation,” inProceedings of the IEEE/CVF international conf. on computer vision, 2019, pp. 603–612
2019
-
[6]
Search- ing efficient 3d architectures with sparse point-voxel convolution,
H. Tang, Z. Liu, S. Zhao, Y . Lin, J. Lin, H. Wang, and S. Han, “Search- ing efficient 3d architectures with sparse point-voxel convolution,” in European conf. on computer vision. Springer, 2020, pp. 685–702
2020
-
[7]
Cylindrical and asymmetrical 3d convolution networks for lidar segmentation,
X. Zhu, H. Zhou, T. Wang, F. Hong, Y . Ma, W. Li, H. Li, and D. Lin, “Cylindrical and asymmetrical 3d convolution networks for lidar segmentation,” inProceedings of the IEEE/CVF conf. on computer vision and pattern recognition, 2021, pp. 9939–9948
2021
-
[8]
Perception-aware multi-sensor fusion for 3d lidar semantic segmentation,
Z. Zhuang, R. Li, K. Jia, Q. Wang, Y . Li, and M. Tan, “Perception-aware multi-sensor fusion for 3d lidar semantic segmentation,” inProceedings of the IEEE/CVF international conf. on computer vision, 2021, pp. 16 280–16 290
2021
-
[9]
Mseg3d: Multi-modal 3d semantic segmentation for autonomous driving,
J. Li, H. Dai, H. Han, and Y . Ding, “Mseg3d: Multi-modal 3d semantic segmentation for autonomous driving,” inProceedings of the IEEE/CVF conf. on computer vision and pattern recognition, 2023, pp. 21 694– 21 704
2023
-
[10]
2dpass: 2d priors assisted semantic segmentation on lidar point clouds,
X. Yan, J. Gao, C. Zheng, C. Zheng, R. Zhang, S. Cui, and Z. Li, “2dpass: 2d priors assisted semantic segmentation on lidar point clouds,” inEuropean conf. on computer vision. Springer, 2022, pp. 677–695
2022
-
[11]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caineet al., “Scalability in perception for autonomous driving: Waymo open dataset,” inProceedings of the IEEE/CVF conf. on computer vision and pattern recognition, 2020, pp. 2446–2454
2020
-
[12]
Epnet: Enhancing point features with image semantics for 3d object detection,
T. Huang, Z. Liu, X. Chen, and X. Bai, “Epnet: Enhancing point features with image semantics for 3d object detection,” inEuropean conf. on computer vision. Springer, 2020, pp. 35–52
2020
-
[13]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”Transactions on Machine Learning Research Journal, pp. 1–31, 2024
2024
-
[14]
Point transformer v3: Simpler faster stronger,
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, and H. Zhao, “Point transformer v3: Simpler faster stronger,” inProceedings of the IEEE/CVF conf. on computer vision and pattern recognition, 2024, pp. 4840–4851
2024
-
[15]
Cylinder3d: An effective 3d framework for driving-scene lidar semantic segmentation,
H. Zhou, X. Zhu, X. Song, Y . Ma, Z. Wang, H. Li, and D. Lin, “Cylinder3d: An effective 3d framework for driving-scene lidar semantic segmentation,”arXiv preprint arXiv:2008.01550, 2020
-
[16]
Dino in the room: Leveraging 2d foundation models for 3d segmentation,
K. Abou Zeid, K. Yilmaz, D. de Geus, A. Hermans, D. B. Adrian, T. Linder, and B. Leibe, “Dino in the room: Leveraging 2d foundation models for 3d segmentation,” inThirteenth International conf. on 3D Vision, 2025
2025
-
[17]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” inProceedings of the IEEE conf. on computer vision and pattern recognition, 2017, pp. 652–660
2017
-
[18]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space,
C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[19]
Dynamic graph cnn for learning on point clouds,
Y . Wang, Y . Sun, Z. Liu, S. E. Sarma, M. M. Bronstein, and J. M. Solomon, “Dynamic graph cnn for learning on point clouds,”ACM Transactions on Graphics (tog), vol. 38, no. 5, pp. 1–12, 2019
2019
-
[20]
Deep projective 3d semantic segmentation,
F. J. Lawin, M. Danelljan, P. Tosteberg, G. Bhat, F. S. Khan, and M. Fels- berg, “Deep projective 3d semantic segmentation,” inInternational conf. on computer analysis of images and patterns. Springer, 2017, pp. 95– 107
2017
-
[21]
Uni-to-multi modal knowledge distillation for bidirectional lidar-camera semantic segmentation,
T. Sun, Z. Zhang, X. Tan, Y . Peng, Y . Qu, and Y . Xie, “Uni-to-multi modal knowledge distillation for bidirectional lidar-camera semantic segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 11 059–11 072, 2024
2024
-
[22]
Squeezesegv2: Improved model structure and unsupervised domain adaptation for road- object segmentation from a lidar point cloud,
B. Wu, X. Zhou, S. Zhao, X. Yue, and K. Keutzer, “Squeezesegv2: Improved model structure and unsupervised domain adaptation for road- object segmentation from a lidar point cloud,” ininternational conf. on robotics and automation (ICRA). IEEE, 2019, pp. 4376–4382
2019
-
[23]
Rangenet++: Fast and accurate lidar semantic segmentation,
A. Milioto, I. Vizzo, J. Behley, and C. Stachniss, “Rangenet++: Fast and accurate lidar semantic segmentation,” in2019 IEEE/RSJ international conf. on intelligent robots and systems (IROS). IEEE, 2019, pp. 4213– 4220
2019
-
[24]
Randla-net: Efficient semantic segmentation of large- scale point clouds,
Q. Hu, B. Yang, L. Xie, S. Rosa, Y . Guo, Z. Wang, N. Trigoni, and A. Markham, “Randla-net: Efficient semantic segmentation of large- scale point clouds,” inProceedings of the IEEE/CVF conf. on computer vision and pattern recognition, 2020, pp. 11 108–11 117
2020
-
[25]
Kpconv: Flexible and deformable convolution for point clouds,
H. Thomas, C. R. Qi, J.-E. Deschaud, B. Marcotegui, F. Goulette, and L. J. Guibas, “Kpconv: Flexible and deformable convolution for point clouds,” inProceedings of the IEEE/CVF international conf. on computer vision, 2019, pp. 6411–6420
2019
-
[26]
Rpvnet: A deep and efficient range-point-voxel fusion network for lidar point cloud segmentation,
J. Xu, R. Zhang, J. Dou, Y . Zhu, J. Sun, and S. Pu, “Rpvnet: A deep and efficient range-point-voxel fusion network for lidar point cloud segmentation,” inProceedings of the IEEE/CVF international conf. on computer vision, 2021, pp. 16 024–16 033
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.