Uncertainty-based Debiasing and Unlearning for Decontamination
Pith reviewed 2026-06-26 05:55 UTC · model grok-4.3
The pith
Uncertainty-Based Decontamination adjusts per-sample LLM outputs using only ensemble uncertainty from the contaminated model to recover distributions from an uncontaminated version.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UBD estimates a per-sample correction scalar from deep-ensemble uncertainty on the contaminated model alone, constructs a debiased target distribution that suppresses contamination-induced probability mass on correct answers, and applies this target either as post-hoc correction or as a soft training signal, producing per-sample output distributions substantially closer to those of an uncontaminated model than existing baselines on MMLU-Pro and MATH-MCQA.
What carries the argument
Uncertainty-Based Decontamination (UBD), which derives a per-sample correction scalar from ensemble uncertainty to build a debiased target distribution without requiring an uncontaminated model or contamination labels.
If this is right
- UBD produces per-sample output distributions closer to uncontaminated models than paraphrasing or choice-permutation methods.
- Performance on uncontaminated data remains unchanged after UBD application.
- The same uncertainty-derived correction works for both post-hoc debiasing and parameter-update unlearning.
- The approach requires no knowledge of which samples are contaminated and no separate clean model.
Where Pith is reading between the lines
- If ensemble uncertainty tracks memorization reliably, the method could be tested on other forms of data leakage such as training-data overlap outside benchmark sets.
- The per-sample distributional metric could be adopted as a standard complement to accuracy when reporting decontamination results.
- The correction scalar might be monitored over training to detect when contamination effects begin to appear in new model checkpoints.
Load-bearing premise
Ensemble uncertainty measured on the contaminated model alone can reliably estimate the amount of per-sample memorization caused by contamination.
What would settle it
Running UBD on a set of known contaminated samples and finding that the adjusted output distributions remain as far from the uncontaminated reference distributions as the original contaminated outputs would falsify the central claim.
Figures
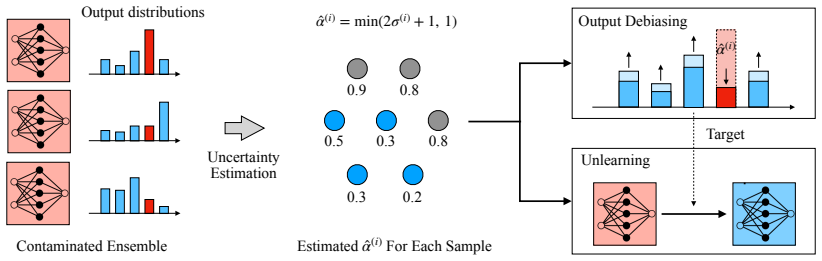
read the original abstract
Benchmark-based evaluation is the dominant paradigm for assessing large language model (LLM) capabilities, yet data contamination inflates reported performance and undermines fair comparison. Existing decontamination methods are evaluated solely through aggregate accuracy, which can obscure substantial differences in per-sample model behaviour, and many require access to an uncontaminated model. In this paper, we propose a sample-level evaluation framework for decontamination that complements accuracy-based assessment with distributional distance metrics, measuring how closely a decontaminated model recovers the output distribution of an uncontaminated model on each sample. Building on this framework, we introduce Uncertainty-Based Decontamination (UBD), a family of methods that leverage deep ensembles of the contaminated model to estimate per-sample memorization without requiring a uncontaminated model or knowledge of which samples are contaminated. UBD estimates a per-sample correction scalar from ensemble uncertainty, which is used to construct a debiased target distribution that suppresses the inflated probability mass on correct answers induced by contamination. This target is then used either as a post-hoc output correction (debiasing) or as a soft training signal for parameter update (unlearning). Experiments on MMLU-Pro and MATH-MCQA across multiple LLM backbones demonstrate that UBD produces per-sample output distributions substantially closer to those of an uncontaminated model than paraphrasing or choice-permutation baselines, while preserving model performance on uncontaminated data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that data contamination in LLM benchmarks can be addressed via Uncertainty-Based Decontamination (UBD), which uses deep ensembles on the contaminated model alone to estimate per-sample memorization via uncertainty, derives a correction scalar, and constructs a debiased target distribution. This target supports either post-hoc debiasing or unlearning. The work also introduces a sample-level evaluation framework that supplements aggregate accuracy with distributional distance metrics to an uncontaminated reference model. Experiments on MMLU-Pro and MATH-MCQA across multiple backbones report that UBD yields per-sample output distributions closer to the uncontaminated reference than paraphrasing or choice-permutation baselines while preserving performance on uncontaminated data.
Significance. If the core proxy assumption holds, the contribution would be notable for enabling decontamination and unlearning without access to an uncontaminated model or contamination labels, and for shifting evaluation from aggregate accuracy to per-sample distributional fidelity. The distributional metrics and the debiasing/unlearning duality are concrete strengths that could influence benchmarking practices.
major comments (2)
- [Abstract / Method] Abstract and method overview: the central claim that ensemble uncertainty on the contaminated model serves as a reliable proxy specifically for contamination-induced memorization (rather than task difficulty, model capacity, or stochasticity) is not accompanied by a derivation or by controls that isolate the contamination effect. This assumption is load-bearing for the correction scalar and the subsequent distributional-closeness results; without it the per-sample adjustment risks mis-correcting clean samples.
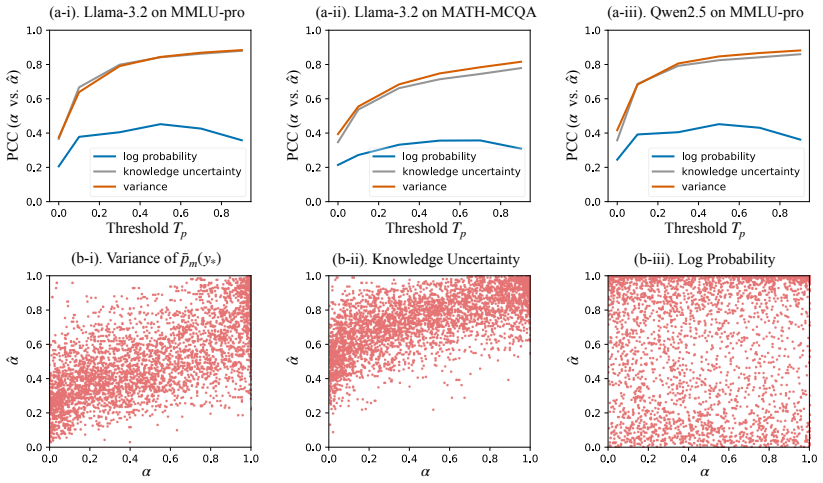
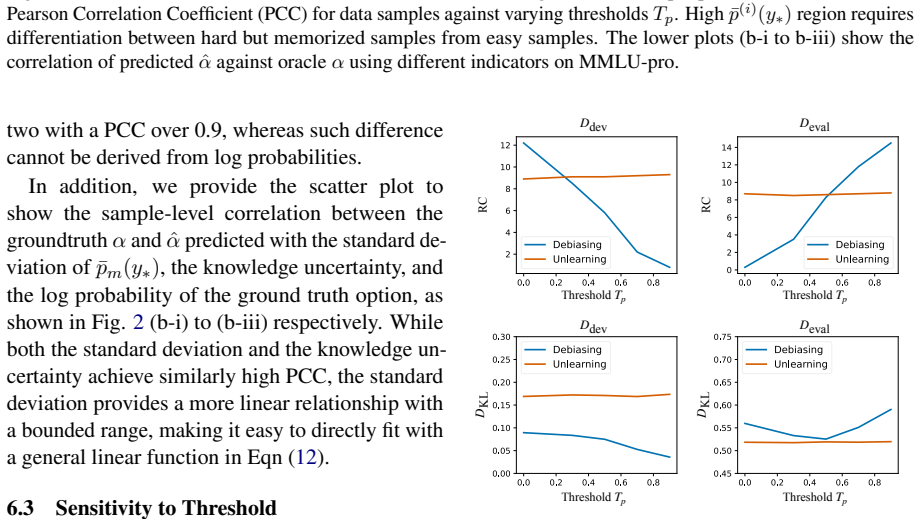
- [Experiments] Evaluation framework: the reported improvements in distributional distance are measured against an uncontaminated reference, yet the paper provides no ablation or diagnostic that verifies the uncertainty signal tracks contamination status rather than inherent item hardness on MMLU-Pro/MATH-MCQA. This directly affects the validity of the “substantially closer” claim.
minor comments (2)
- [Abstract] The abstract states experimental improvements but omits concrete details on ensemble size, uncertainty metric (e.g., entropy vs. variance), derivation of the correction scalar, and statistical significance testing; these should be supplied in the main text with pseudocode or equations.
- [Experiments] Baseline implementations (paraphrasing, choice-permutation) require explicit description of how they were applied to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications on our empirical grounding and motivation for the uncertainty proxy. We agree that additional discussion and diagnostics would strengthen the manuscript and will incorporate them where feasible.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method overview: the central claim that ensemble uncertainty on the contaminated model serves as a reliable proxy specifically for contamination-induced memorization (rather than task difficulty, model capacity, or stochasticity) is not accompanied by a derivation or by controls that isolate the contamination effect. This assumption is load-bearing for the correction scalar and the subsequent distributional-closeness results; without it the per-sample adjustment risks mis-correcting clean samples.
Authors: The proxy rests on the established connection between reduced ensemble variance and memorization effects in uncertainty estimation for neural networks. While no closed-form derivation isolating contamination from task difficulty is given, the method applies the correction only to low-uncertainty samples and our results show that performance on uncontaminated subsets remains unchanged, indicating limited mis-correction of clean items. We will expand the method section with further justification of the assumption and its scope. revision: partial
-
Referee: [Experiments] Evaluation framework: the reported improvements in distributional distance are measured against an uncontaminated reference, yet the paper provides no ablation or diagnostic that verifies the uncertainty signal tracks contamination status rather than inherent item hardness on MMLU-Pro/MATH-MCQA. This directly affects the validity of the “substantially closer” claim.
Authors: The distributional improvements are validated by the dual observation that UBD improves closeness to the reference while leaving accuracy on clean data intact. This provides indirect support that the signal is not driven solely by item hardness. We acknowledge the lack of a direct ablation (e.g., synthetic contamination or per-item hardness controls) and will add such diagnostics to the experiments section in revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes UBD by treating ensemble uncertainty on the contaminated model as an external proxy signal to derive a per-sample correction scalar for constructing a debiased target distribution. No equations, derivations, or self-citations are presented in the abstract or described framework that reduce the central claim to a self-definitional fit, fitted input renamed as prediction, or load-bearing self-citation chain. The evaluation framework compares to an external uncontaminated reference model using distributional metrics, keeping the method self-contained against independent benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Inference-time decontamination: Reusing leaked benchmarks for large language model evaluation , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[3]
Findings of the Association for Computational Linguistics: NAACL 2025 , year=
UNLEARN efficient removal of knowledge in large language models , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , year=
2025
-
[4]
arXiv preprint arXiv:2601.19334 , year=
When Benchmarks Leak: Inference-Time Decontamination for LLMs , author=. arXiv preprint arXiv:2601.19334 , year=
-
[5]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Machine unlearning of pre-trained large language models , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[6]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[7]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Antileakbench: Preventing data contamination by automatically constructing benchmarks with updated real-world knowledge , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[8]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Investigating data contamination in modern benchmarks for large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[9]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Data contamination can cross language barriers , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[10]
arXiv preprint arXiv:2310.16789 , year=
Detecting pretraining data from large language models , author=. arXiv preprint arXiv:2310.16789 , year=
-
[11]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Generalization or memorization: Data contamination and trustworthy evaluation for large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[12]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Does data contamination detection work (well) for llms? a survey and evaluation on detection assumptions , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[13]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[14]
ACM transactions on intelligent systems and technology , volume=
A survey on evaluation of large language models , author=. ACM transactions on intelligent systems and technology , volume=. 2024 , publisher=
2024
-
[15]
Publications Manual , year = "1983", publisher =
1983
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Reasoning or memorization? unreliable results of reinforcement learning due to data contamination , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[17]
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source LLMs , author=. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[18]
arXiv preprint arXiv:2404.18824 , year=
Benchmarking benchmark leakage in large language models , author=. arXiv preprint arXiv:2404.18824 , year=
-
[19]
arXiv preprint arXiv:2406.04244 , year=
Benchmark data contamination of large language models: A survey , author=. arXiv preprint arXiv:2406.04244 , year=
-
[20]
28th USENIX security symposium (USENIX security 19) , pages=
The secret sharer: Evaluating and testing unintended memorization in neural networks , author=. 28th USENIX security symposium (USENIX security 19) , pages=
-
[21]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Quantifying privacy risks of masked language models using membership inference attacks , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[22]
2017 IEEE symposium on security and privacy (SP) , pages=
Membership inference attacks against machine learning models , author=. 2017 IEEE symposium on security and privacy (SP) , pages=. 2017 , organization=
2017
-
[23]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[24]
arXiv preprint arXiv:2311.07919 , year=
Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models , author=. arXiv preprint arXiv:2311.07919 , year=
-
[25]
arXiv preprint arXiv:2111.05113 , year=
Membership inference attacks against self-supervised speech models , author=. arXiv preprint arXiv:2111.05113 , year=
-
[26]
On decoder-only architecture for speech-to-text and large language model integration , author=. Proc. ASRU , year =
-
[27]
arXiv preprint arXiv:2309.00916 , year=
Blsp: Bootstrapping language-speech pre-training via behavior alignment of continuation writing , author=. arXiv preprint arXiv:2309.00916 , year=
-
[28]
arXiv preprint arXiv:2310.13289 , year=
Salmonn: Towards generic hearing abilities for large language models , author=. arXiv preprint arXiv:2310.13289 , year=
-
[29]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[30]
Dan Gusfield , title =. 1997
1997
-
[31]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[32]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[33]
Proceedings of the 25th International Workshop on Mobile Computing Systems and Applications , pages=
Crowdotic: A Privacy-Preserving Hospital Waiting Room Crowd Density Estimation with Non-speech Audio , author=. Proceedings of the 25th International Workshop on Mobile Computing Systems and Applications , pages=
-
[34]
Proceedings on Privacy Enhancing Technologies , year=
Exploring the privacy concerns of bystanders in smart homes from the perspectives of both owners and bystanders , author=. Proceedings on Privacy Enhancing Technologies , year=
-
[35]
arXiv preprint arXiv:2508.08155 , year=
MSU-Bench: Towards Understanding the Conversational Multi-talker Scenarios , author=. arXiv preprint arXiv:2508.08155 , year=
-
[36]
2018 , publisher=
Legal Implications of Video Surveillance on Transit Systems , author=. 2018 , publisher=
2018
-
[37]
2014 , journal=
Audio monitoring in Smart Cities: an information privacy perspective , author=. 2014 , journal=
2014
-
[38]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Who Can Withstand Chat-Audio Attacks? An Evaluation Benchmark for Large Audio-Language Models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[39]
Nautsch, Andreas and Jasserand, Catherine and Kindt, Els and Todisco, Massimiliano and Trancoso, Isabel and Evans, Nicholas , journal=. The
-
[40]
Unlearning LLM-Based Speech Recognition Models , author=. Proc. Interspeech 2025 , pages=
2025
-
[41]
Chen, Guangke and Zhang, Yedi and Song, Fu , journal=
-
[42]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Unintended memorization in large asr models, and how to mitigate it , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[43]
Computer Speech & Language , volume=
Preserving privacy in speaker and speech characterisation , author=. Computer Speech & Language , volume=. 2019 , publisher=
2019
-
[44]
arXiv preprint arXiv:2104.00766 , year=
Configurable privacy-preserving automatic speech recognition , author=. arXiv preprint arXiv:2104.00766 , year=
-
[45]
arXiv preprint arXiv:2507.10016 , year=
The Man Behind the Sound: Demystifying Audio Private Attribute Profiling via Multimodal Large Language Model Agents , author=. arXiv preprint arXiv:2507.10016 , year=
-
[46]
arXiv preprint arXiv:2305.05227 , year=
Privacy in speech technology , author=. arXiv preprint arXiv:2305.05227 , year=
-
[47]
Defending Speech-enabled
Alexos, Antonios and Peri, Raghuveer and Jayanthi, Sai Muralidhar and Cekic, Metehan and Vishnubhotla, Srikanth and Han, Kyu J and Ronanki, Srikanth , booktitle=. Defending Speech-enabled
-
[48]
arXiv preprint arXiv:2506.00848 , year=
Speech Unlearning , author=. arXiv preprint arXiv:2506.00848 , year=
-
[49]
arXiv preprint arXiv:2505.15700 , year=
``Alexa, can you forget me?'' Machine Unlearning Benchmark in Spoken Language Understanding , author=. arXiv preprint arXiv:2505.15700 , year=
-
[50]
arXiv preprint arXiv:2310.17194 , year=
Privacy-preserving Representation Learning for Speech Understanding , author=. arXiv preprint arXiv:2310.17194 , year=
-
[51]
Audio-Based Jailbreak Attacks on Multi-Modal LLMs , author =
-
[52]
Building multimodal
Pascal Hartig , url =. Building multimodal
-
[53]
Proceedings of the ACM on Human-Computer Interaction , volume=
Privacy perceptions and designs of bystanders in smart homes , author=. Proceedings of the ACM on Human-Computer Interaction , volume=. 2019 , publisher=
2019
-
[54]
ACM Transactions on Computer-Human Interaction , year=
Bystander Privacy in Smart Homes: A Systematic Review of Concerns and Solutions , author=. ACM Transactions on Computer-Human Interaction , year=
-
[55]
Humanities and Social Sciences Communications , volume=
Bystanders’ collective responses set the norm against hate speech , author=. Humanities and Social Sciences Communications , volume=. 2024 , publisher=
2024
-
[56]
Hartmann, Valentin and Suri, Anshuman and Bindschaedler, Vincent and Evans, David and Tople, Shruti and West, Robert , journal=. So
-
[57]
Transactions of the Association for Computational Linguistics , volume=
How much do language models copy from their training data? evaluating linguistic novelty in text generation using raven , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[58]
30th USENIX security symposium (USENIX Security 21) , pages=
Extracting training data from large language models , author=. 30th USENIX security symposium (USENIX Security 21) , pages=
-
[59]
arXiv preprint arXiv:2412.08608 , year=
Advwave: Stealthy adversarial jailbreak attack against large audio-language models , author=. arXiv preprint arXiv:2412.08608 , year=
-
[60]
IEEE Transactions on Information Forensics and Security , year=
A benchmark for multi-speaker anonymization , author=. IEEE Transactions on Information Forensics and Security , year=
-
[61]
DeepMine Speech Processing Database: Text-Dependent and , author=. Proc. Odyssey 2018 The Speaker and Language Recognition , pages=
2018
-
[62]
Speaker Recognition Benchmark Using the
Garcia-Romero, Daniel and Snyder, David and Watanabe, Shinji and Sell, Gregory and McCree, Alan and Povey, Daniel and Khudanpur, Sanjeev , booktitle=. Speaker Recognition Benchmark Using the
-
[63]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
AudioSet-R: A Refined AudioSet with Multi-Stage LLM Label Reannotation , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[64]
Av-superb: A multi-task evaluation benchmark for audio-visual representation models , author=. Proc. ICASSP , year=
-
[65]
Godfrey, John J and Holliman, Edward C and McDaniel, Jane , booktitle =
-
[66]
arXiv preprint arXiv:2005.11262 , year=
Librimix: An open-source dataset for generalizable speech separation , author=. arXiv preprint arXiv:2005.11262 , year=
arXiv 2005
-
[67]
Kraaij, Wessel and Hain, Thomas and Lincoln, Mike and Post, Wilfried , booktitle=. The
-
[68]
Sakshi, S and Tyagi, Utkarsh and Kumar, Sonal and Seth, Ashish and Selvakumar, Ramaneswaran and Nieto, Oriol and Duraiswami, Ramani and Ghosh, Sreyan and Manocha, Dinesh , journal=
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[70]
Speech-Audio Compositional Attacks on Multimodal
Yang, Yudong and Zhang, Xuezhen and Han, Zhifeng and Wang, Siyin and Zhuang, Jimin and Jin, Zengrui and Shao, Jing and Sun, Guangzhi and Zhang, Chao , journal=. Speech-Audio Compositional Attacks on Multimodal
-
[71]
Dynamic-superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech , author=. Proc. ICASSP , year=
-
[72]
arXiv preprint arXiv:2410.21276 , year=
-
[73]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Audio-centric video understanding benchmark without text shortcut , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[74]
Gemini Live: A more helpful, natural and visual assistant , author =
-
[75]
McCowan and J
I. McCowan and J. Carletta and W. Kraaij and S. Ashby and S. Bourban and M. Flynn and M. Guillemot and T. Hain and J. Kadlec and V. Karaiskos and M. Kronenthal and G. Lathoud and M. Lincoln and A. Lisowska and W. Post and Dennis Reidsma and P. Wellner. The AMI meeting corpus. Proceedings of Measuring Behavior 2005, 5th International Conference on Methods ...
2005
-
[76]
Fang, Qingkai and Zhou, Yan and Guo, Shoutao and Zhang, Shaolei and Feng, Yang , title =. Proc. ACL , year =
-
[77]
2025 , journal =
Jin Xu and Zhifang Guo and Jinzheng He and Hangrui Hu and Ting He and Shuai Bai and Keqin Chen and Jialin Wang and Yang Fan and Kai Dang and Bin Zhang and Xiong Wang and Yunfei Chu and Junyang Lin , title =. 2025 , journal =
2025
-
[78]
Jin Xu and Zhifang Guo and Hangrui Hu and others , title =. arXiv:2509.17765 , year =
- [79]
-
[80]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , year=
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.