Reproducibility Study of "AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models"
Pith reviewed 2026-06-26 05:03 UTC · model grok-4.3
The pith
Reproducing AlphaEdit shows its null-space projection gives only bounded protection against forgetting and does not generalize to newer model architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
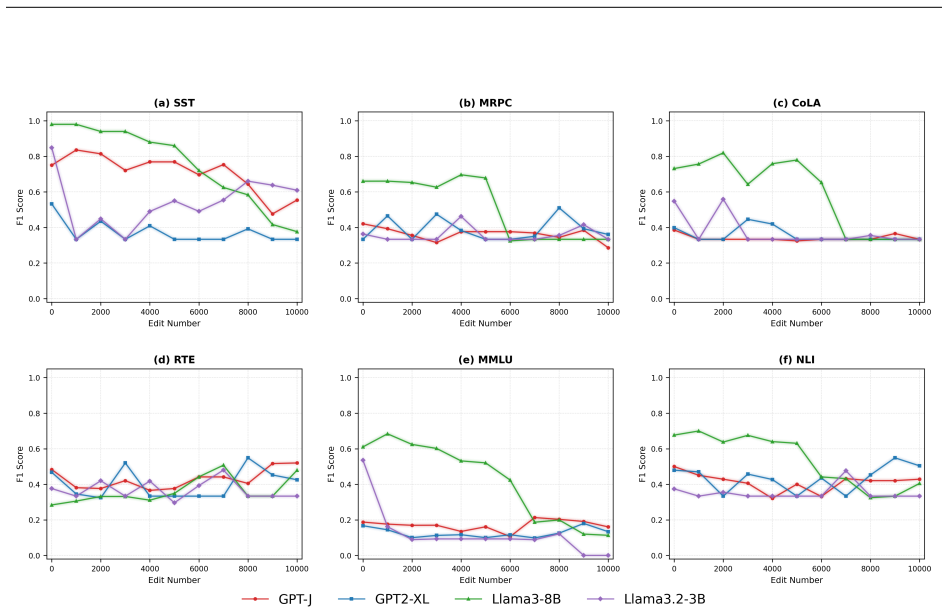
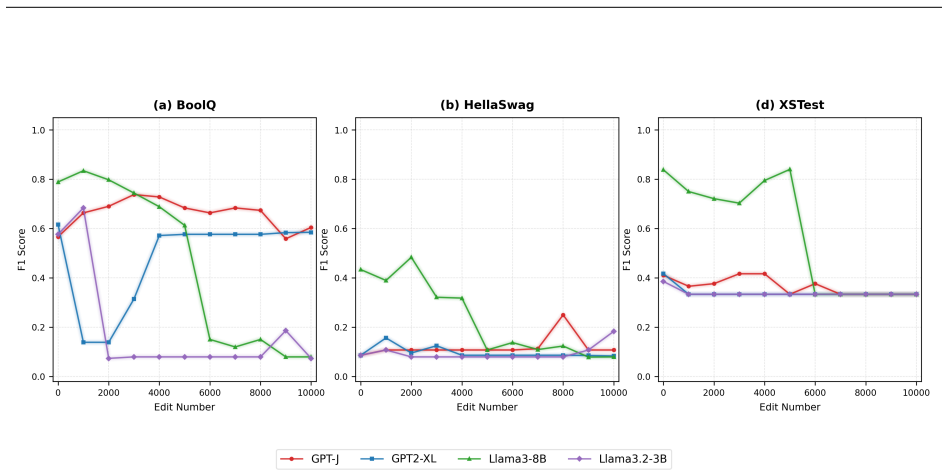
The paper establishes that AlphaEdit reproduces its metrics on the original models, though with a noted discrepancy in fluency and consistency scores. When extended to newer model families the performance advantage does not generalize uniformly, which the authors trace to architectural assumptions in the locate-then-edit paradigm that those models violate. Stress-testing with substantially longer sequential edit horizons shows that the null-space projection's safeguard against catastrophic forgetting holds at the originally reported scale but breaks down at much higher edit counts, proving the protection is bounded. Evaluation on BoolQ, HellaSwag, and XSTest further reveals that large-scale
What carries the argument
The null-space constrained projection that restricts edits to directions orthogonal to previously preserved knowledge in locate-then-edit knowledge editing.
If this is right
- AlphaEdit performs as reported within its original scope on LLaMA3, GPT2-XL, and GPT-J.
- Its advantage does not generalize uniformly to newer model families because locate-then-edit assumptions are violated.
- The null-space projection's protection against catastrophic forgetting is bounded and degrades at high edit counts.
- Large-scale sequential editing degrades general downstream task competence and safety-relevant refusal behavior.
Where Pith is reading between the lines
- Practical deployment would need limits on total edit volume and compatibility checks for each model family.
- The locate-then-edit approach itself may require updates to remain reliable on current and future architectures.
- Testing on still longer edit sequences or additional model families could map the exact boundary of the projection's effectiveness.
- The observed degradation on safety benchmarks suggests sequential editing can unintentionally alter model alignment properties.
Load-bearing premise
The locate-then-edit paradigm's assumptions about model internals and the scaling behavior of the null-space projection continue to hold when the method is applied to newer architectures and substantially longer edit sequences.
What would settle it
A direct measurement showing whether performance on the original models remains stable or begins to degrade once the sequential edit count exceeds the original paper's range by a factor of five or more.
Figures
read the original abstract
Fang et al. (2025) introduced a null-space constrained projection, named AlphaEdit, for locate-then-edit knowledge editing methods, theoretically guaranteeing that edits do not disrupt previously preserved knowledge, and reports substantial gains over existing editing methods on LLaMA3, GPT2-XL, and GPT-J. In this work, we present a reproducibility study of AlphaEdit, reproducing its reported results under the original experimental setup and extending the evaluation along three axes: new model architectures, additional downstream benchmarks, and substantially longer sequential editing horizons. We successfully reproduce AlphaEdit's reported metrics across the original models, though we identify a discrepancy in the reported fluency and consistency metric. Extending AlphaEdit to newer model families, we find that its advantage does not generalize uniformly, which we trace to architectural assumptions in the locate-then-edit paradigm that are violated by these newer models. We further stress-test AlphaEdit's central sequential-editing claim by extending the number of edits well beyond those evaluated in the original paper, and find that performance, which is stable at the originally reported scale, degrades as edits reach a much higher count, indicating that the null-space projection's protection against catastrophic forgetting is bounded rather than unconditional. Finally, we extend evaluation of edited models on three extra benchmarks, namely, BoolQ, HellaSwag, and XSTest, and we find that large-scale sequential editing degrades both general downstream task competence and safety-relevant refusal behavior. Our results confirm that AlphaEdit performs as reported within its original scope, while showing that its core theoretical guarantees are sensitive to model architecture and editing scale in ways that have practical implications for its deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This reproducibility study of AlphaEdit (Fang et al., 2025) reproduces the original metrics on LLaMA3, GPT2-XL, and GPT-J under the stated setup, notes a discrepancy in fluency/consistency scores, extends evaluation to newer model families (finding non-uniform generalization due to violated locate-then-edit assumptions), stress-tests sequential editing at scales far beyond the original (finding degradation that indicates the null-space projection's protection against catastrophic forgetting is bounded rather than unconditional), and adds results on BoolQ, HellaSwag, and XSTest (showing degradation in downstream competence and safety refusal behavior). The central claim is that AlphaEdit performs as reported within its original scope but its guarantees are sensitive to architecture and editing scale.
Significance. If the results hold, the work is significant for confirming reproduction of AlphaEdit within the original experimental scope while providing concrete extension results that demonstrate practical limits on its theoretical guarantees. It supplies reproducible extension data and additional benchmark evaluations, which are valuable for the knowledge-editing literature. The finding that performance remains stable at the originally reported scale but degrades at much higher edit counts directly informs deployment considerations.
major comments (2)
- [Extension to substantially longer sequential editing horizons] In the section on stress-testing AlphaEdit's sequential-editing claim (abstract and corresponding extension results): the attribution of performance degradation at high edit counts to the null-space projection's protection being 'bounded rather than unconditional' is not isolated from other pipeline components. The manuscript does not report post-projection checks such as update norms, dot products with preserved knowledge directions, or effective rank of the null-space basis in the high-edit regime; degradation could instead arise from locate-step failures, accumulated rank deficiency, or numerical instability even if the projection step remains orthogonal.
- [Extension to new model architectures] In the extension to newer model families: the claim that AlphaEdit's advantage 'does not generalize uniformly' because 'architectural assumptions in the locate-then-edit paradigm are violated' is stated without specifying which assumptions (e.g., layer-wise edit location or single-layer update assumptions) are violated or providing targeted ablation evidence linking the violation to the observed performance gap.
minor comments (2)
- The discrepancy in reported fluency and consistency metrics is noted but not diagnosed or resolved; clarifying whether this stems from implementation differences, metric computation, or data splits would strengthen the reproduction claim.
- The additional benchmark results on BoolQ, HellaSwag, and XSTest would benefit from explicit comparison tables against the unedited baseline and original editing scale to make the degradation claim more quantitative.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our reproducibility study. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Extension to substantially longer sequential editing horizons] In the section on stress-testing AlphaEdit's sequential-editing claim (abstract and corresponding extension results): the attribution of performance degradation at high edit counts to the null-space projection's protection being 'bounded rather than unconditional' is not isolated from other pipeline components. The manuscript does not report post-projection checks such as update norms, dot products with preserved knowledge directions, or effective rank of the null-space basis in the high-edit regime; degradation could instead arise from locate-step failures, accumulated rank deficiency, or numerical instability even if the projection step remains orthogonal.
Authors: We agree that the attribution would be more robust with explicit isolation of the projection step's contribution. Our observation of stability at the original edit scales followed by degradation at substantially higher counts is consistent with bounded protection, but we acknowledge that locate-step failures or numerical issues could contribute. In the revised manuscript, we will add post-projection diagnostics including update norms, dot products with preserved knowledge directions, and effective rank of the null-space basis across the high-edit regime to better isolate the source of degradation. revision: yes
-
Referee: [Extension to new model architectures] In the extension to newer model families: the claim that AlphaEdit's advantage 'does not generalize uniformly' because 'architectural assumptions in the locate-then-edit paradigm are violated' is stated without specifying which assumptions (e.g., layer-wise edit location or single-layer update assumptions) are violated or providing targeted ablation evidence linking the violation to the observed performance gap.
Authors: We agree that greater specificity would improve the claim. The locate-then-edit paradigm relies on assumptions such as reliable layer-wise localization of edits and sufficiency of single-layer updates without cross-layer interference. Newer architectures can violate these through differences in depth, attention mechanisms, or residual connections. We will revise the relevant section to explicitly name these assumptions and include targeted ablation results (e.g., layer-specific edit success rates) to link violations to the observed performance differences. revision: yes
Circularity Check
Empirical reproducibility study contains no derivation chain
full rationale
This is a reproducibility and extension study that reproduces AlphaEdit metrics on original models, tests newer architectures, extends edit sequences, and reports downstream benchmark results. No equations, first-principles derivations, or predictions are presented that could reduce to fitted inputs or self-referential definitions. All claims rest on direct experimental observation rather than any mathematical reduction or self-citation load-bearing step. The paper therefore has no circularity in its reported chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2404.14219. AI@Meta. Llama 3.2 model card,
-
[2]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova
URLhttps://github.com/meta-llama/llama3. Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Jill Burstein, Christy Doran, and Thamar Solorio (eds.),Proceedings of the 2019 Conference of the North American Chapter of the Associat...
2019
-
[3]
B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions
Association for Computational Linguistics. doi: 10.18653/v1/N19-1300. URLhttps://aclanthology.org/N19-1300/. Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. In Joaquin Quiñonero-Candela, Ido Dagan, Bernardo Magnini, and Florence d’Alché Buc (eds.),Machine Learning Challenges. Evaluating Predictive Uncer...
-
[4]
URLhttps: //arxiv.org/abs/2410.02355. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aure...
-
[5]
Jia-Chen Gu, Hao-Xiang Xu, Jun-Yu Ma, Pan Lu, Zhen-Hua Ling, Kai-Wei Chang, and Nanyun Peng
URLhttps://arxiv.org/abs/2407.21783. Jia-Chen Gu, Hao-Xiang Xu, Jun-Yu Ma, Pan Lu, Zhen-Hua Ling, Kai-Wei Chang, and Nanyun Peng. Model editing harms general abilities of large language models: Regularization to the rescue,
-
[6]
Akshat Gupta, Anurag Rao, and Gopala Anumanchipalli
URL https://arxiv.org/abs/2401.04700. Akshat Gupta, Anurag Rao, and Gopala Anumanchipalli. Model editing at scale leads to gradual and catastrophic forgetting,
-
[7]
DanHendrycks, CollinBurns, StevenBasart, AndyZou, MantasMazeika, DawnSong, andJacobSteinhardt
URLhttps://arxiv.org/abs/2401.07453. DanHendrycks, CollinBurns, StevenBasart, AndyZou, MantasMazeika, DawnSong, andJacobSteinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR),
-
[8]
Zero-shot relation extraction via reading com- prehension
Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. Zero-shot relation extraction via reading com- prehension. In Roger Levy and Lucia Specia (eds.),Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pp. 333–342, Vancouver, Canada, August
2017
-
[9]
com/deepmind-media/Model-Cards/ Gemini-3-Flash-Model-Card.pdf
Association for Computational Linguistics. doi: 10.18653/v1/K17-1034. URLhttps://aclanthology.org/K17-1034/. Jun-Yu Ma, Hong Wang, Hao-Xiang Xu, Zhen-Hua Ling, and Jia-Chen Gu. Perturbation-restrained sequen- tial model editing,
-
[10]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov
URLhttps://arxiv.org/abs/2405.16821. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY, USA,
-
[11]
15 Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al
URLhttps://arxiv.org/abs/2412.15115. 15 Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9,
-
[12]
XSTest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. XSTest: A test suite for identifying exaggerated safety behaviours in large language models. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.),Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: ...
2024
-
[13]
doi: 10.18653/ v1/2024.naacl-long.301
Association for Computational Linguistics. doi: 10.18653/ v1/2024.naacl-long.301. URLhttps://aclanthology.org/2024.naacl-long.301/. Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. InProceedings of the 2013 Confere...
2024
-
[14]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R
URLhttps://arxiv.org/abs/2408.00118. Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Tal Linzen, Grzegorz Chrupała, and Afra Alishahi (eds.),Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural...
Pith/arXiv arXiv 2018
-
[15]
GLUE : A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
Associa- tion for Computational Linguistics. doi: 10.18653/v1/W18-5446. URLhttps://aclanthology.org/ W18-5446/. 16 Ben Wang and Aran Komatsuzaki. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax, May
-
[16]
URLhttps://aclanthology.org/Q19-1040/
doi: 10.1162/tacl_a_00290. URLhttps://aclanthology.org/Q19-1040/. Adina Williams, Nikita Nangia, and Samuel R. Bowman. A broad-coverage challenge corpus for sentence understanding through inference. In Marilyn Walker, Heng Ji, and Amanda Stent (eds.),Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Ling...
-
[17]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference
Association for Computational Linguistics. doi: 10.18653/v1/N18-1101. URLhttps://aclanthology. org/N18-1101/. Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Anna Korhonen, David Traum, and Lluís Màrquez (eds.),Proceedings of the 57th Annual Meeting of the Association for Com...
work page internal anchor Pith review doi:10.18653/v1/n18-1101
-
[18]
Association for Computational Linguistics. doi: 10.18653/v1/P19-1472. URLhttps: //aclanthology.org/P19-1472/. A Appendix A.1 GLUE Benchmark The exact F1 scores of all the models evaluated on the GLUE benchmarks are given in Table
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.