Panoramic Scene Analysis: A Survey from Distortion-Aware Engineering to Sphere-Native Foundation Modeling
Pith reviewed 2026-06-29 04:33 UTC · model grok-4.3
The pith
No panoramic scene analysis method achieves both strict spherical equivariance and full reuse of perspective-pretrained foundation-model weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
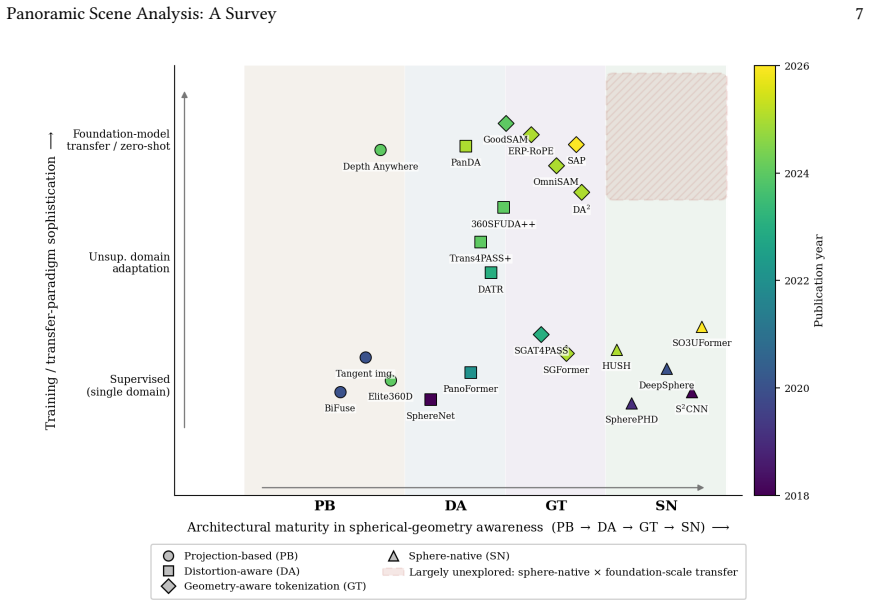
The literature evolves along a trajectory of increasing geometric commitment from projection adaptation through distortion engineering to sphere-native modeling, yet none of the surveyed methods simultaneously delivers strict spherical equivariance and full reuse of perspective-pretrained foundation-model weights; this tension is structural. Five systematic gaps exist in evaluation protocols: absence of spherical-area-weighted metrics, seam-consistency testing, polar-robustness stratification, cross-projection generalization checks, and open-world protocol standardization. A six-point research roadmap is proposed to reach general-purpose panoramic intelligence.
What carries the argument
The two orthogonal dimensions of architectural design (operator interaction with spherical geometry) and training paradigm (knowledge transfer across domains) that together expose the unresolved equivariance-versus-weight-reuse tension.
If this is right
- Architectures must be redesigned so spherical geometry is native rather than corrected after the fact.
- Training paradigms need mechanisms that preserve pretrained weights while enforcing exact equivariance under spherical transformations.
- Evaluation protocols must add area-weighted metrics, seam-consistency tests, polar stratification, cross-projection checks, and standardized open-world benchmarks.
- Multi-task, open-world, and video panoramic systems will remain limited until the equivariance-weight tension is resolved.
- Geometry-aware tokenization offers one concrete route toward unified panoramic foundation models.
Where Pith is reading between the lines
- A hybrid approach that freezes most pretrained weights and adds lightweight spherical-equivariant layers could serve as an immediate engineering bridge.
- The same tension likely appears in other omnidirectional sensing domains such as 360 video compression or robotic navigation on curved surfaces.
- If the gap is truly structural, native spherical pretraining from scratch on large panoramic corpora may ultimately outperform any adaptation strategy.
- Standard vision benchmarks could be extended with synthetic spherical distortions to quantify how much equivariance is lost when reusing flat-image weights.
Load-bearing premise
The surveyed methods comprehensively represent the current state of the art, so the identified tension between equivariance and weight reuse is genuinely unresolved rather than merely overlooked.
What would settle it
Publication or discovery of any single method that simultaneously achieves strict spherical equivariance and full reuse of perspective-pretrained foundation-model weights on the covered tasks would falsify the structural-gap claim.
Figures
read the original abstract
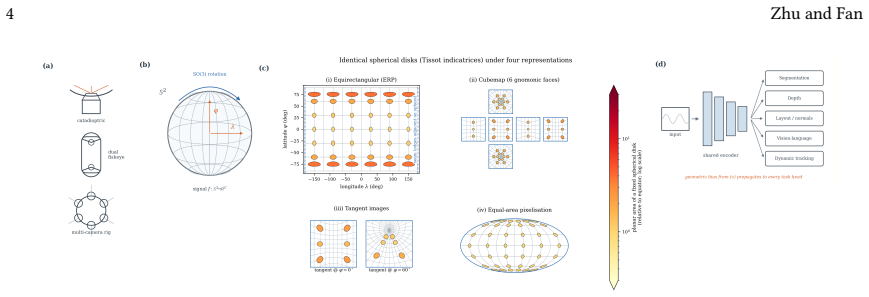
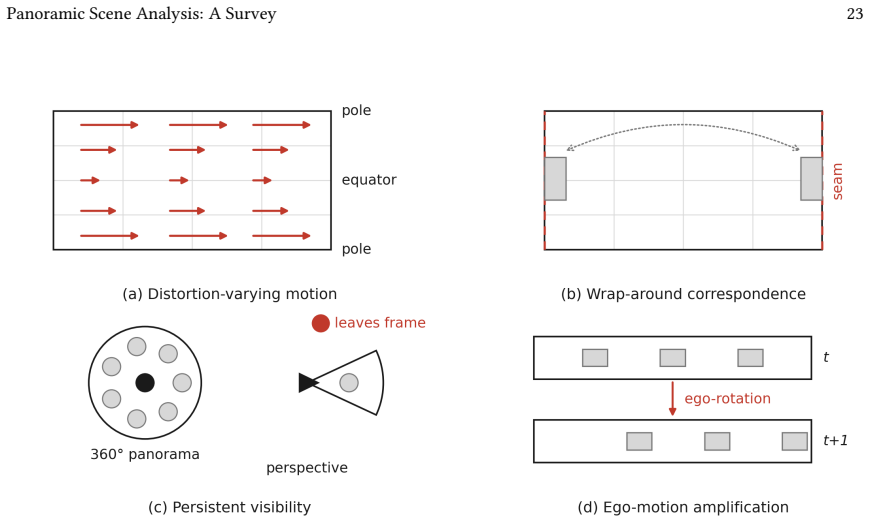
Panoramic images capture the complete visual sphere in a single frame, providing spatial context unattainable by conventional cameras. Yet this completeness comes at a geometric cost: the 2-sphere cannot be faithfully mapped to the plane, and every planar representation introduces distortions that violate the assumptions underlying standard vision architectures. This survey traces the evolution of panoramic scene analysis along a methodological trajectory, from projection-based adaptation, through distortion-aware engineering, to sphere-native modeling and geometry-aware tokenization for foundation models, and argues that this evolution reflects a progressive deepening of geometric commitment rather than a simple accumulation of techniques. We organize the literature along two orthogonal dimensions: architectural design (how operators interact with spherical geometry) and training paradigm (how knowledge is transferred across domains). Covering dense prediction (semantic segmentation, depth estimation, and room layout estimation), unified multi-task understanding, open-world perception, vision-language reasoning, and dynamic video analysis, we identify a central unresolved tension: among the methods surveyed, none simultaneously delivers strict spherical equivariance and full reuse of perspective-pretrained foundation-model weights, and we argue that this is a structural rather than incidental gap. We further expose five systematic gaps in current evaluation protocols, namely the absence of spherical-area-weighted metrics, seam-consistency testing, polar-robustness stratification, cross-projection generalization, and open-world protocol standardization, and propose a six-point research roadmap toward general-purpose panoramic intelligence. The corresponding repository is publicly available at: https://github.com/zhuqinfeng1999/Awesome-Panoramic-Scene-Analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey traces the development of panoramic scene analysis from projection-based adaptations and distortion-aware engineering to sphere-native modeling and geometry-aware tokenization. It organizes the literature along two axes—architectural design (operator interaction with spherical geometry) and training paradigm (knowledge transfer)—covering tasks from dense prediction and multi-task understanding to vision-language reasoning and video analysis. The central claim is that no surveyed method simultaneously achieves strict spherical equivariance and full reuse of perspective-pretrained foundation-model weights, which the authors argue is a structural gap; the paper also identifies five evaluation-protocol gaps and outlines a six-point research roadmap, with an accompanying public repository.
Significance. If the survey coverage is representative, the work would usefully synthesize progress in panoramic vision and isolate a concrete tension between geometric fidelity and transfer learning that future foundation-model efforts must resolve. The explicit identification of evaluation gaps (spherical-area-weighted metrics, seam consistency, polar robustness, cross-projection generalization, open-world protocols) and the public repository provide concrete value for the community even if the structural-gap claim requires further substantiation.
major comments (2)
- [Abstract and §1] Abstract and §1 (Introduction): The claim that 'none simultaneously delivers strict spherical equivariance and full reuse of perspective-pretrained foundation-model weights' and that the tension is 'structural rather than incidental' is the paper's primary contribution. This assertion rests on the surveyed set being exhaustive, yet the manuscript provides no documented search protocol, keyword list, database sources, date cutoffs, or explicit inclusion/exclusion rules, preventing verification that omitted recent adapter-based or hybrid equivariant fine-tuning approaches do not already satisfy both criteria.
- [§4 and §5] §4 (Training Paradigm) and §5 (Evaluation Gaps): The five listed evaluation gaps are presented as systematic, but the section does not quantify how many of the surveyed papers fail each criterion or provide a table mapping methods to the gaps; without this, it is unclear whether the gaps are uniformly unaddressed or whether a subset of methods already partially satisfies them, weakening the roadmap's motivation.
minor comments (2)
- The two-dimensional taxonomy (architectural design × training paradigm) is conceptually clean, but the manuscript would benefit from an explicit table or figure that places every cited method into the taxonomy cells to improve traceability.
- Several section headings use similar phrasing (e.g., 'sphere-native' appears in multiple contexts); consistent terminology or a glossary would reduce ambiguity for readers new to the subfield.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help improve the rigor of our survey. We provide point-by-point responses to the major comments below, indicating planned revisions to address the concerns about documentation and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1 (Introduction): The claim that 'none simultaneously delivers strict spherical equivariance and full reuse of perspective-pretrained foundation-model weights' and that the tension is 'structural rather than incidental' is the paper's primary contribution. This assertion rests on the surveyed set being exhaustive, yet the manuscript provides no documented search protocol, keyword list, database sources, date cutoffs, or explicit inclusion/exclusion rules, preventing verification that omitted recent adapter-based or hybrid equivariant fine-tuning approaches do not already satisfy both criteria.
Authors: We agree that a documented search protocol is essential for verifying the exhaustiveness of the surveyed literature and thus the strength of our central claim. In the revised version, we will insert a new subsection (e.g., §2.1 Literature Search Methodology) that explicitly details the databases queried (Google Scholar, arXiv, IEEE Xplore), the keyword combinations employed, the time period covered, and the inclusion/exclusion criteria applied. This addition will enable independent verification and address potential concerns about omitted methods such as recent adapter-based approaches. revision: yes
-
Referee: [§4 and §5] §4 (Training Paradigm) and §5 (Evaluation Gaps): The five listed evaluation gaps are presented as systematic, but the section does not quantify how many of the surveyed papers fail each criterion or provide a table mapping methods to the gaps; without this, it is unclear whether the gaps are uniformly unaddressed or whether a subset of methods already partially satisfies them, weakening the roadmap's motivation.
Authors: We concur that quantifying the prevalence of each gap and providing a mapping would strengthen the motivation for the proposed roadmap. Accordingly, we will augment §5 with a comprehensive table that lists all surveyed methods and indicates their compliance with each of the five evaluation criteria. We will also include summary statistics (e.g., percentage of methods addressing each gap) to demonstrate that the gaps are indeed widespread. This revision will clarify the systematic nature of the identified issues. revision: yes
Circularity Check
No circularity: survey paper with no derivations or self-referential fits
full rationale
This is a literature survey paper with no equations, fitted parameters, predictions, or derivation chains. The central claim—that no surveyed method achieves both strict spherical equivariance and full weight reuse—rests on external reviewed publications rather than any reduction to the paper's own inputs or self-citations. No self-definitional, fitted-input, or uniqueness-imported patterns apply. The paper is self-contained as a review whose exhaustiveness can be externally checked against the cited works.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The surveyed literature is representative of the field and sufficient to establish that no method achieves both strict spherical equivariance and full weight reuse.
Reference graph
Works this paper leans on
-
[1]
Hao Ai, Zidong Cao, Yan-Pei Cao, Ying Shan, and Lin Wang. 2023. Hrdfuse: Monocular 360deg depth estimation by collaboratively learning holistic-with-regional depth distributions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13273–13282
2023
- [2]
-
[3]
Hao Ai and Lin Wang. 2024. Elite360d: Towards efficient 360 depth estimation via semantic-and distance-aware bi-projection fusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9926–9935
2024
- [4]
-
[5]
Georgios Albanis, Nikolaos Zioulis, Petros Drakoulis, Vasileios Gkitsas, Vladimiros Sterzentsenko, Federico Alvarez, Dimitrios Zarpalas, and Petros Daras. 2021. Pano3d: A holistic benchmark and a solid baseline for 360deg depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3727–3737
2021
-
[6]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. 2018. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition. 3674–3683
2018
-
[7]
Iro Armeni, Sasha Sax, Amir R Zamir, and Silvio Savarese. 2017. Joint 2d-3d-semantic data for indoor scene understanding.arXiv preprint arXiv:1702.01105(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Jiayang Bai, Haoyu Qin, Shuichang Lai, Jie Guo, and Yanwen Guo. 2024. GLPanoDepth: Global-to-local panoramic depth estimation.IEEE Transactions on Image Processing33 (2024), 2936–2949
2024
-
[9]
Yaniv Benny and Lior Wolf. 2025. Sphereuformer: A u-shaped transformer for spherical 360 perception. InProceedings of the Computer Vision and Pattern Recognition Conference. 940–950
2025
-
[10]
Meiqi Cao, Rui Yan, Xiangbo Shu, Guangzhao Dai, Yazhou Yao, and Guo-Sen Xie. 2024. Adafpp: Adapt-focused bi-propagating prototype learning for panoramic activity recognition. InProceedings of the 32nd ACM International Conference on Multimedia. 691–700
2024
-
[11]
Yihong Cao, Jiaming Zhang, Hao Shi, Kunyu Peng, Yuhongxuan Zhang, Hui Zhang, Rainer Stiefelhagen, and Kailun Yang. 2024. Occlusion-aware seamless segmentation. InEuropean Conference on Computer Vision. Springer, 129–147
2024
-
[12]
Zidong Cao, Jinjing Zhu, Weiming Zhang, Hao Ai, Haotian Bai, Hengshuang Zhao, and Lin Wang. 2025. Panda: Towards panoramic depth anything with unlabeled panoramas and mobius spatial augmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 982–992
2025
-
[13]
Mahdi Chamseddine, Didier Stricker, and Jason Rambach. 2026. PanoSAMic: Panoramic Image Segmentation from SAM Feature Encoding and Dual View Fusion.arXiv preprint arXiv:2601.07447(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang
-
[15]
Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14455–14465
2024
-
[17]
Hsien-Tzu Cheng, Chun-Hung Chao, Jin-Dong Dong, Hao-Kai Wen, Tyng-Luh Liu, and Min Sun. 2018. Cube padding for weakly-supervised saliency prediction in 360 videos. InProceedings of the IEEE conference on computer vision and pattern recognition. 1420–1429
2018
-
[18]
Shih-Han Chou, Wei-Lun Chao, Wei-Sheng Lai, Min Sun, and Ming-Hsuan Yang. 2020. Visual question answering on 360deg images. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 1607–1616. Manuscript submitted to ACM 32 Zhu and Fan
2020
-
[19]
Taco Cohen, Maurice Weiler, Berkay Kicanaoglu, and Max Welling. 2019. Gauge equivariant convolutional networks and the icosahedral CNN. In International conference on Machine learning. PMLR, 1321–1330
2019
-
[20]
Taco S Cohen, Mario Geiger, Jonas Köhler, and Max Welling. 2018. Spherical cnns.arXiv preprint arXiv:1801.10130(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Benjamin Coors, Alexandru Paul Condurache, and Andreas Geiger. 2018. Spherenet: Learning spherical representations for detection and classification in omnidirectional images. InProceedings of the European conference on computer vision (ECCV). 518–533
2018
-
[22]
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. 2016. The cityscapes dataset for semantic urban scene understanding. InProceedings of the IEEE conference on computer vision and pattern recognition. 3213–3223
2016
-
[23]
Thiago LT Da Silveira, Paulo GL Pinto, Jeffri Murrugarra-Llerena, and Cláudio R Jung. 2022. 3d scene geometry estimation from 360 imagery: A survey.Comput. Surveys55, 4 (2022), 1–39
2022
- [24]
- [25]
- [26]
-
[27]
Marc Eder, Mykhailo Shvets, John Lim, and Jan-Michael Frahm. 2020. Tangent images for mitigating spherical distortion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12426–12434
2020
-
[28]
Carlos Esteves, Christine Allen-Blanchette, Ameesh Makadia, and Kostas Daniilidis. 2018. Learning so (3) equivariant representations with spherical cnns. InProceedings of the european conference on computer vision (ECCV). 52–68
2018
-
[29]
Carlos Esteves, Ameesh Makadia, and Kostas Daniilidis. 2020. Spin-weighted spherical cnns. InAdvances in Neural Information Processing Systems, Vol. 33. 8614–8625
2020
- [30]
-
[31]
Weijia Fan, Ruiping Liu, Jiale Wei, Yufan Chen, Junwei Zheng, Zichao Zeng, Jiaming Zhang, Qiufu Li, Linlin Shen, and Rainer Stiefelhagen. 2026. More than the Sum: Panorama-Language Models for Adverse Omni-Scenes.arXiv preprint arXiv:2603.09573(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Shaohua Gao, Kailun Yang, Hao Shi, Kaiwei Wang, and Jian Bai. 2022. Review on panoramic imaging and its applications in scene understanding. IEEE Transactions on Instrumentation and Measurement71 (2022), 1–34
2022
-
[33]
Jan Gerken, Oscar Carlsson, Hampus Linander, Fredrik Ohlsson, Christoffer Petersson, and Daniel Persson. 2022. Equivariance versus augmentation for spherical images. InInternational Conference on Machine Learning. PMLR, 7404–7421
2022
-
[34]
Christopher Geyer and Kostas Daniilidis. 2000. A unifying theory for central panoramic systems and practical implications. InEuropean conference on computer vision. Springer, 445–461
2000
-
[35]
Krzysztof M Gorski, Eric Hivon, Anthony J Banday, Benjamin D Wandelt, Frode K Hansen, Mstvos Reinecke, and Matthia Bartelmann. 2005. HEALPix: A framework for high-resolution discretization and fast analysis of data distributed on the sphere.The Astrophysical Journal622, 2 (2005), 759–771
2005
-
[36]
Yuliang Guo, Sparsh Garg, S Mahdi H Miangoleh, Xinyu Huang, and Liu Ren. 2025. Depth any camera: Zero-shot metric depth estimation from any camera. InProceedings of the Computer Vision and Pattern Recognition Conference. 26996–27006
2025
-
[37]
Ruize Han, Haomin Yan, Jiacheng Li, Songmiao Wang, Wei Feng, and Song Wang. 2022. Panoramic human activity recognition. InEuropean Conference on Computer Vision. Springer, 244–261
2022
-
[38]
Byeongho Heo, Song Park, Dongyoon Han, and Sangdoo Yun. 2024. Rotary position embedding for vision transformer. InEuropean Conference on Computer Vision. Springer, 289–305
2024
- [39]
-
[40]
Huajian Huang, Yinzhe Xu, Yingshu Chen, and Sai-Kit Yeung. 2023. 360vot: A new benchmark dataset for omnidirectional visual object tracking. InProceedings of the IEEE/CVF International Conference on Computer Vision. 20566–20576
2023
- [41]
-
[42]
Sandeep Inuganti, Hideaki Kanayama, Kanta Shimizu, Mahdi Chamseddine, Soichiro Yokota, Didier Stricker, and Jason Rambach. 2026. JOPP-3D: Joint Open Vocabulary Semantic Segmentation on Point Clouds and Panoramas.arXiv preprint arXiv:2603.06168(2026)
work page internal anchor Pith review arXiv 2026
- [43]
-
[44]
Alexander Jaus, Kailun Yang, and Rainer Stiefelhagen. 2023. Panoramic panoptic segmentation: Insights into surrounding parsing for mobile agents via unsupervised contrastive learning.IEEE Transactions on Intelligent Transportation Systems24, 4 (2023), 4438–4453
2023
-
[45]
Hualie Jiang, Zhe Sheng, Siyu Zhu, Zilong Dong, and Rui Huang. 2021. Unifuse: Unidirectional fusion for 360 panorama depth estimation.IEEE Robotics and Automation Letters6, 2 (2021), 1519–1526
2021
- [46]
-
[47]
Jing Jiang, Sicheng Zhao, Jiankun Zhu, Wenbo Tang, Zhaopan Xu, Jidong Yang, Guoping Liu, Tengfei Xing, Pengfei Xu, and Hongxun Yao. 2025. Multi-source domain adaptation for panoramic semantic segmentation.Information Fusion117 (2025), 102909
2025
- [48]
-
[49]
Zhigang Jiang, Zhongzheng Xiang, Jinhua Xu, and Ming Zhao. 2022. Lgt-net: Indoor panoramic room layout estimation with geometry-aware transformer network. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1654–1663
2022
- [50]
-
[51]
Juho Kannala and Sami S Brandt. 2006. A generic camera model and calibration method for conventional, wide-angle, and fish-eye lenses.IEEE transactions on pattern analysis and machine intelligence28, 8 (2006), 1335–1340
2006
-
[52]
Bogdan Khomutenko, Gaëtan Garcia, and Philippe Martinet. 2015. An enhanced unified camera model.IEEE Robotics and Automation Letters1, 1 (2015), 137–144
2015
-
[53]
Risi Kondor and Shubhendu Trivedi. 2018. On the generalization of equivariance and convolution in neural networks to the action of compact groups. InInternational conference on machine learning. PMLR, 2747–2755
2018
-
[54]
Duy Tho Le, Chenhui Gou, Stavya Datta, Hengcan Shi, Ian Reid, Jianfei Cai, and Hamid Rezatofighi. 2024. Jrdb-panotrack: An open-world panoptic segmentation and tracking robotic dataset in crowded human environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22325–22334
2024
-
[55]
Jongsung Lee, Harin Park, Byeong-Uk Lee, and Kyungdon Joo. 2025. Hush: Holistic panoramic 3d scene understanding using spherical harmonics. InProceedings of the Computer Vision and Pattern Recognition Conference. 16599–16608
2025
-
[56]
Yeonkun Lee, Jaeseok Jeong, Jongseob Yun, Wonjune Cho, and Kuk-Jin Yoon. 2019. Spherephd: Applying cnns on a spherical polyhedron representation of 360deg images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9181–9189
2019
- [57]
-
[58]
Xiang Li, Haoyuan Cao, Shijie Zhao, Junlin Li, Li Zhang, and Bhiksha Raj. 2023. Panoramic video salient object detection with ambisonic audio guidance. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 1424–1432
2023
- [59]
-
[60]
Yuyan Li, Yuliang Guo, Zhixin Yan, Xinyu Huang, Ye Duan, and Liu Ren. 2022. Omnifusion: 360 monocular depth estimation via geometry-aware fusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2801–2810
2022
- [61]
- [62]
- [63]
- [64]
-
[65]
Jingguo Liu, Han Yu, Shigang Li, and Jianfeng Li. 2025. 360-degree full-view image segmentation by spherical convolution compatible with large-scale planar pre-trained models. In2025 IEEE International Conference on Multimedia and Expo Workshops (ICMEW). IEEE, 1–6
2025
-
[66]
Kai Luo, Hao Shi, Kunyu Peng, Fei Teng, Sheng Wu, Kaiwei Wang, and Kailun Yang. 2025. OmniTrack++: Omnidirectional Multi-Object Tracking by Learning Large-FoV Trajectory Feedback.arXiv preprint arXiv:2511.00510(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Kai Luo, Hao Shi, Sheng Wu, Fei Teng, Mengfei Duan, Chang Huang, Yuhang Wang, Kaiwei Wang, and Kailun Yang. 2025. Omnidirectional multi-object tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21959–21969
2025
-
[68]
Chaoxiang Ma, Jiaming Zhang, Kailun Yang, Alina Roitberg, and Rainer Stiefelhagen. 2021. Densepass: Dense panoramic semantic segmentation via unsupervised domain adaptation with attention-augmented context exchange. In2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE, 2766–2772
2021
-
[69]
Koki Maeda, Shuhei Kurita, Taiki Miyanishi, and Naoaki Okazaki. 2023. Query-based image captioning from multi-context 360cdegree images. In Findings of the Association for Computational Linguistics: EMNLP 2023. 6940–6954
2023
-
[70]
Roberto Martin-Martin, Mihir Patel, Hamid Rezatofighi, Abhijeet Shenoi, JunYoung Gwak, Eric Frankel, Amir Sadeghian, and Silvio Savarese. 2021. Jrdb: A dataset and benchmark of egocentric robot visual perception of humans in built environments.IEEE transactions on pattern analysis and machine intelligence45, 6 (2021), 6748–6765
2021
- [71]
-
[72]
OpenAI. 2024. GPT-4o System Card. https://cdn.openai.com/gpt-4o-system-card.pdf
2024
-
[73]
Hao Peng, Yun Zhang, and Fang-Lue Zhang. 2025. Robust and enhanced 360 ◦ visual tracking based on dynamic gnomonic projection.Journal of the Royal Society of New Zealand55, 6 (2025), 2169–2197. Manuscript submitted to ACM 34 Zhu and Fan
2025
-
[74]
Nathanaël Perraudin, Michaël Defferrard, Tomasz Kacprzak, and Raphael Sgier. 2019. Deepsphere: Efficient spherical convolutional neural network with healpix sampling for cosmological applications.Astronomy and Computing27 (2019), 130–146
2019
-
[75]
Luigi Piccinelli, Christos Sakaridis, Mattia Segu, Yung-Hsu Yang, Siyuan Li, Wim Abbeloos, and Luc Van Gool. 2025. Unik3d: Universal camera monocular 3d estimation. InProceedings of the Computer Vision and Pattern Recognition Conference. 1028–1039
2025
-
[76]
Giovanni Pintore, Marco Agus, and Enrico Gobbetti. 2020. AtlantaNet: inferring the 3D indoor layout from a single 360 ◦ image beyond the Manhattan world assumption. InEuropean conference on computer vision. Springer, 432–448
2020
-
[77]
Manuel Rey-Area, Mingze Yuan, and Christian Richardt. 2022. 360MonoDepth: High-Resolution 360deg Monocular Depth Estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3762–3772
2022
-
[78]
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al . 2019. Habitat: A platform for embodied ai research. InProceedings of the IEEE/CVF international conference on computer vision. 9339–9347
2019
-
[79]
Zhijie Shen, Chunyu Lin, Kang Liao, Lang Nie, Zishuo Zheng, and Yao Zhao. 2022. PanoFormer: panorama transformer for indoor 360◦ depth estimation. InEuropean Conference on Computer Vision. Springer, 195–211
2022
-
[80]
Zhijie Shen, Zishuo Zheng, Chunyu Lin, Lang Nie, Kang Liao, Shuai Zheng, and Yao Zhao. 2023. Disentangling orthogonal planes for indoor panoramic room layout estimation with cross-scale distortion awareness. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 17337–17345
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.