ReasonCLIP-58M: Visually Grounded Commonsense Reasoning Supervision for CLIP
Pith reviewed 2026-06-26 05:00 UTC · model grok-4.3
The pith
Structured reasoning supervision during pretraining allows CLIP-style models to handle visually grounded commonsense and compositional reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
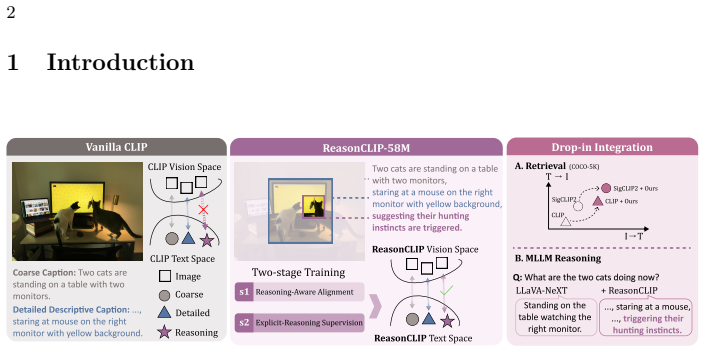
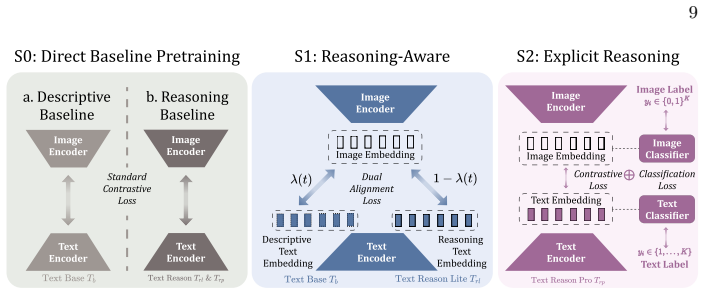
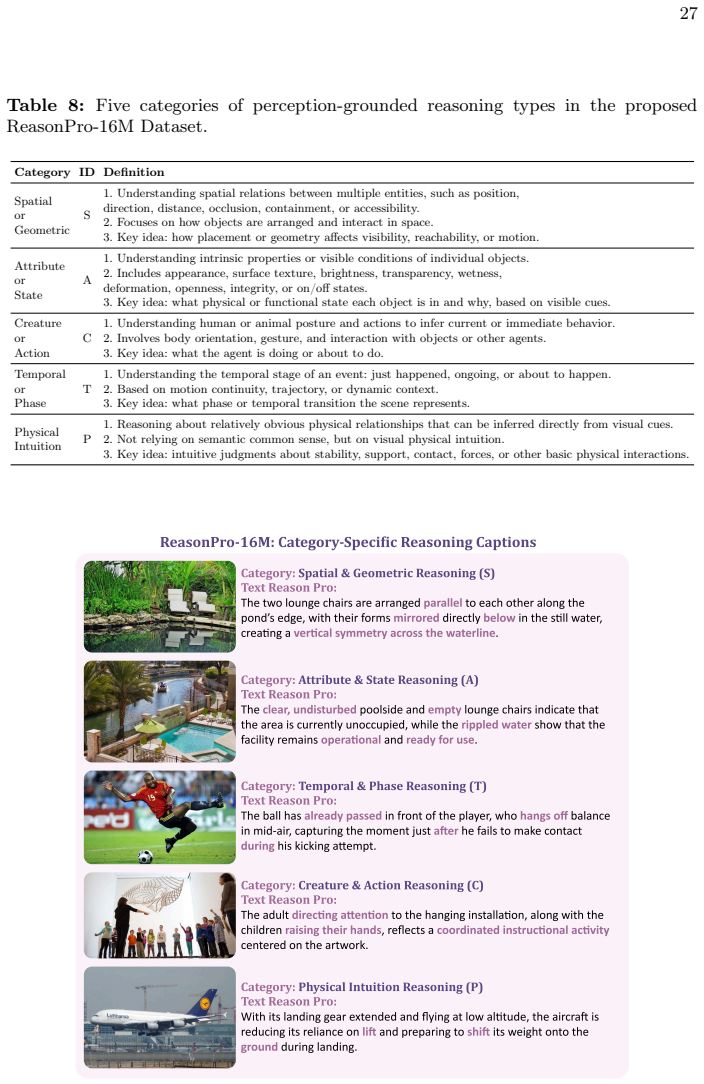
By constructing ReasonLite-42M and ReasonPro-16M datasets and applying a two-stage continual pretraining framework that progressively integrates reasoning signals while preserving descriptive alignment, followed by category-structured reasoning supervision, ReasonCLIP-58M models achieve enhanced visually grounded commonsense and compositional reasoning capabilities compared to standard CLIP, as shown through diagnostic evaluation on RCLIP-Bench and downstream gains in models like LLaVA-NeXT.
What carries the argument
The two-stage continual pretraining strategy that integrates reasoning supervision progressively while maintaining descriptive alignment, supported by the ReasonLite-42M and ReasonPro-16M datasets.
If this is right
- ReasonCLIP models show gains in visually grounded commonsense and compositional reasoning.
- Zero-shot image-text retrieval performance is also improved.
- Using ReasonCLIP as a drop-in visual encoder in multimodal LLMs like LLaVA-NeXT yields consistent performance gains at no extra inference cost.
- CLIP-style visual encoders can support reasoning tasks without requiring architectural modifications.
Where Pith is reading between the lines
- If the approach works, it implies that curating high-quality reasoning data could be a more efficient path to better multimodal reasoning than solely scaling model size.
- The method could be extended to other vision-language models beyond the CLIP family.
- Improved visual representations might lead to better performance in tasks like visual question answering or robotic perception that require commonsense.
- Further scaling the reasoning datasets beyond 58M might produce additional gains in expressive capacity.
Load-bearing premise
The reasoning captions generated for the new datasets are accurate and visually verifiable without introducing significant noise or biases from the construction process.
What would settle it
Observing no improvement or even a decline in performance on the RCLIP-Bench reasoning tasks after training on the new datasets compared to a baseline CLIP model would falsify the central claim.
Figures








read the original abstract
CLIP and its variants are widely adopted visual backbones in multimodal systems, but their pretraining remains dominated by descriptive image-text alignment. As downstream applications increasingly demand visually grounded commonsense inference and compositional reasoning, it remains unclear whether CLIP-style encoders can support such reasoning without architectural changes. To address this, we present ReasonCLIP-58M, a continual pretraining framework that integrates large-scale reasoning supervision into CLIP-style models through our two-stage strategy, which progressively integrates reasoning signals while preserving descriptive alignment, followed by category-structured reasoning supervision. To support this framework, we construct two complementary datasets and a benchmark: ReasonLite-42M, with open-form, visually verifiable reasoning captions; ReasonPro-16M, with category-specific reasoning supervision; and RCLIP-Bench for diagnostic evaluation of visually grounded reasoning. We train a family of ReasonCLIP that improves visually grounded commonsense and compositional reasoning while also enhancing zero-shot retrieval performance. As a drop-in visual encoder for multimodal large language models such as LLaVA-NeXT, ReasonCLIP delivers consistent gains without additional inference cost, demonstrating that structured reasoning supervision enhances the expressive capacity of CLIP-style visual representations. All datasets, models, and training code are available at https://github.com/RISys-Lab/ReasonCLIP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that CLIP-style visual encoders can acquire enhanced visually grounded commonsense and compositional reasoning capabilities through a two-stage continual pretraining framework (ReasonCLIP-58M) that incorporates large-scale structured reasoning supervision. This is supported by newly constructed datasets ReasonLite-42M (open-form visually verifiable reasoning captions) and ReasonPro-16M (category-specific reasoning supervision), plus the diagnostic benchmark RCLIP-Bench. The resulting models improve reasoning performance and zero-shot retrieval, and yield consistent gains as drop-in encoders in MLLMs such as LLaVA-NeXT, all without added inference cost. Datasets, models, and code are released.
Significance. If the central claims hold after verification, the work would demonstrate that descriptive alignment in CLIP can be augmented with reasoning supervision to increase expressive capacity for downstream multimodal reasoning tasks. The open release of 58M-scale datasets, models, and training code is a clear strength that enables reproducibility and further research.
major comments (2)
- [Dataset construction (ReasonLite-42M / ReasonPro-16M)] The central claim that structured reasoning supervision (via ReasonLite-42M and ReasonPro-16M) injects new reasoning capacity rests on the assumption that the LLM-generated captions are accurate, non-noisy, and visually entailed by the images. No large-scale human or automated verification of caption accuracy, visual grounding, or absence of hallucinations is reported, raising the possibility that observed gains on RCLIP-Bench and LLaVA integration arise from data volume or training schedule rather than genuine reasoning signals.
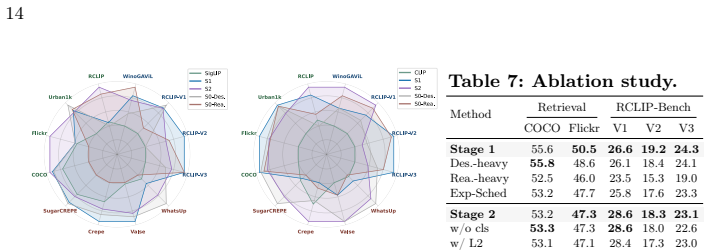
- [Experimental evaluation and results] The manuscript provides no experimental details, baselines, ablation studies, or statistical tests to substantiate the claimed improvements in reasoning and retrieval. Without these, it is impossible to assess whether the two-stage strategy or category-structured supervision is responsible for the reported gains.
minor comments (1)
- [Abstract] The abstract refers to a 'two-stage strategy' and 'category-structured reasoning supervision' without defining the stages or the structuring process; these details are needed for reproducibility even at the high level.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive feedback, which has helped us identify areas for improvement in the manuscript. We address each major comment below and commit to substantial revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Dataset construction (ReasonLite-42M / ReasonPro-16M)] The central claim that structured reasoning supervision (via ReasonLite-42M and ReasonPro-16M) injects new reasoning capacity rests on the assumption that the LLM-generated captions are accurate, non-noisy, and visually entailed by the images. No large-scale human or automated verification of caption accuracy, visual grounding, or absence of hallucinations is reported, raising the possibility that observed gains on RCLIP-Bench and LLaVA integration arise from data volume or training schedule rather than genuine reasoning signals.
Authors: We thank the referee for this important observation. The manuscript does not report large-scale verification of the LLM-generated captions, which is a limitation given the dataset scale. Our generation process incorporates image-conditioned LLMs and filtering steps intended to ensure visual grounding, but we agree this needs explicit documentation. In the revised version, we will add a dedicated subsection on dataset quality control, including automated metrics for caption-image alignment and a human study on a sampled subset (e.g., 1,000 examples) to quantify accuracy and hallucination rates. We will also include an ablation study comparing models trained on the full dataset versus a verified subset to demonstrate the contribution of the reasoning supervision beyond data volume. revision: yes
-
Referee: [Experimental evaluation and results] The manuscript provides no experimental details, baselines, ablation studies, or statistical tests to substantiate the claimed improvements in reasoning and retrieval. Without these, it is impossible to assess whether the two-stage strategy or category-structured supervision is responsible for the reported gains.
Authors: We agree that the initial manuscript lacks sufficient experimental details. The reported improvements are based on our internal evaluations, but these were not fully documented. In the revision, we will substantially expand the experimental section to include: (i) detailed baselines such as standard CLIP, SigLIP, and other reasoning-enhanced models; (ii) comprehensive ablations on the two-stage continual pretraining and the category-specific supervision in ReasonPro-16M; (iii) statistical significance testing (e.g., bootstrap confidence intervals or t-tests) for all key results on RCLIP-Bench and zero-shot retrieval; and (iv) full hyperparameter and training schedule details. This will allow readers to evaluate the contribution of each component. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central contribution consists of explicitly constructed datasets (ReasonLite-42M, ReasonPro-16M) via an LLM-based pipeline, a two-stage continual pretraining procedure, and empirical evaluation on RCLIP-Bench plus downstream tasks. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs; the reported gains are measured outcomes on held-out benchmarks rather than self-referential definitions or renamed fits. Self-citations, if present, are not load-bearing for the core claim, and the derivation remains externally falsifiable through the released code and data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems35, 23716– 23736 (2022)
Alayrac,J.B.,Donahue,J.,Luc,P.,Miech,A.,Barr,I.,Hasson,Y.,Lenc,K.,Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022)
2022
-
[2]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Alhamoud, K., Alshammari, S., Tian, Y., Li, G., Torr, P.H., Kim, Y., Ghassemi, M.: Vision-language models do not understand negation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29612–29622 (2025)
2025
-
[3]
arXiv preprint arXiv:2511.21631 (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
Pith/arXiv arXiv 2025
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[5]
Advances in neural information processing systems 32(2019)
Barbu, A., Mayo, D., Alverio, J., Luo, W., Wang, C., Gutfreund, D., Tenenbaum, J., Katz, B.: Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. Advances in neural information processing systems 32(2019)
2019
-
[6]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Basu, S., Hu, S.X., Sanjabi, M., Massiceti, D., Feizi, S.: Distilling knowledge from text-to-image generative models improves visio-linguistic reasoning in clip. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 6105–6113 (2024)
2024
-
[7]
Advances in Neural Information Processing Systems35, 26549–26564 (2022) 16
Bitton, Y., Bitton Guetta, N., Yosef, R., Elovici, Y., Bansal, M., Stanovsky, G., Schwartz, R.: Winogavil: Gamified association benchmark to challenge vision- and-language models. Advances in Neural Information Processing Systems35, 26549–26564 (2022) 16
2022
-
[8]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
Bolya, D., Huang, P.Y., Sun, P., Cho, J.H., Madotto, A., Wei, C., Ma, T., Zhi, J., Rajasegaran, J., Rasheed, H.A., et al.: Perception encoder: The best visual embeddings are not at the output of the network. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[9]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Changpinyo, S., Sharma, P., Ding, N., Soricut, R.: Conceptual 12m: Pushing web- scale image-text pre-training to recognize long-tail visual concepts. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3558–3568 (2021)
2021
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Chen, J., Yu, Q., Shen, X., Yuille, A., Chen, L.C.: Vitamin: Design scalable vision models in the vision-language era. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[11]
In: Eu- ropean Conference on Computer Vision
Chen, L., Li, J., Dong, X., Zhang, P., He, C., Wang, J., Zhao, F., Lin, D.: Sharegpt4v: Improving large multi-modal models with better captions. In: Eu- ropean Conference on Computer Vision. pp. 370–387. Springer (2024)
2024
-
[12]
Chen,L.,Li,J.,Dong,X.,Zhang,P.,Zang,Y.,Chen,Z.,Duan,H.,Wang,J.,Qiao, Y., Lin, D., et al.: Are we on the right way for evaluating large vision-language models? Advances in Neural Information Processing Systems37, 27056–27087 (2024)
2024
-
[13]
In: Findings of the Association for Computational Linguistics: ACL 2023
Chen, Z., Liu, G., Zhang, B.W., Yang, Q., Wu, L.: Altclip: Altering the language encoder in clip for extended language capabilities. In: Findings of the Association for Computational Linguistics: ACL 2023. pp. 8666–8682 (2023)
2023
-
[14]
5281/zenodo.15403103,https://doi.org/10.5281/zenodo.15403103
Cherti, M., Beaumont, R.: Clip benchmark (Nov 2022).https://doi.org/10. 5281/zenodo.15403103,https://doi.org/10.5281/zenodo.15403103
-
[15]
arXiv preprint arXiv:2507.22062 (2025)
Chuang, Y.S., Li, Y., Wang, D., Yeh, C.F., Lyu, K., Raghavendra, R., Glass, J., Huang, L., Weston, J., Zettlemoyer, L., et al.: Meta clip 2: A worldwide scaling recipe. arXiv preprint arXiv:2507.22062 (2025)
arXiv 2025
-
[16]
Cui, W., Bi, K., Guo, J., Cheng, X.: More: Multi-modal retrieval augmented gen- erativecommonsensereasoning.In:FindingsoftheAssociationforComputational Linguistics: ACL 2024. pp. 1178–1192 (2024)
2024
-
[17]
In: International Conference on Learning Representations (ICLR) (2024)
Dao, T.: FlashAttention-2: Faster attention with better parallelism and work partitioning. In: International Conference on Learning Representations (ICLR) (2024)
2024
-
[18]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[19]
Advances in Neural Information Processing Systems37, 17972–18018 (2024)
Dumpala, S.H., Jaiswal, A., Shama Sastry, C., Milios, E., Oore, S., Sajjad, H.: Sugarcrepe++ dataset: Vision-language model sensitivity to semantic and lexical alterations. Advances in Neural Information Processing Systems37, 17972–18018 (2024)
2024
-
[20]
arXiv preprint arXiv:2401.08541 (2024)
El-Nouby, A., Klein, M., Zhai, S., Bautista, M.A., Toshev, A., Shankar, V., Susskind, J.M., Joulin, A.: Scalable pre-training of large autoregressive image models. arXiv preprint arXiv:2401.08541 (2024)
arXiv 2024
-
[21]
International journal of computer vision111(1), 98–136 (2015)
Everingham, M., Eslami, S.A., Van Gool, L., Williams, C.K., Winn, J., Zisser- man, A.: The pascal visual object classes challenge: A retrospective. International journal of computer vision111(1), 98–136 (2015)
2015
-
[22]
arXiv preprint arXiv:2309.17425 (2023)
Fang, A., Jose, A.M., Jain, A., Schmidt, L., Toshev, A., Shankar, V.: Data filtering networks. arXiv preprint arXiv:2309.17425 (2023)
arXiv 2023
-
[23]
Image and Vision Computing p
Fang, Y., Sun, Q., Wang, X., Huang, T., Wang, X., Cao, Y.: Eva-02: A visual representation for neon genesis. Image and Vision Computing p. 105171 (2024) 17
2024
-
[24]
In: 2004 conference on computer vision and pattern recognition workshop
Fei-Fei, L., Fergus, R., Perona, P.: Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object cate- gories. In: 2004 conference on computer vision and pattern recognition workshop. pp. 178–178. IEEE (2004)
2004
-
[25]
arXiv preprint arXiv:2306.13394 (2023)
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al.: Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023)
Pith/arXiv arXiv 2023
-
[26]
Advances in Neural Information Processing Systems36, 27092–27112 (2023)
Gadre, S.Y., Ilharco, G., Fang, A., Hayase, J., Smyrnis, G., Nguyen, T., Marten, R., Wortsman, M., Ghosh, D., Zhang, J., et al.: Datacomp: In search of the next generation of multimodal datasets. Advances in Neural Information Processing Systems36, 27092–27112 (2023)
2023
-
[27]
Advances in Neural Information Process- ing Systems35, 6704–6719 (2022)
Goel, S., Bansal, H., Bhatia, S., Rossi, R., Vinay, V., Grover, A.: Cyclip: Cyclic contrastive language-image pretraining. Advances in Neural Information Process- ing Systems35, 6704–6719 (2022)
2022
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J., Song, D.: Natural adversarial examples. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15262–15271 (2021)
2021
-
[29]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Herzig,R.,Mendelson,A.,Karlinsky,L.,Arbelle,A.,Feris,R.,Darrell,T.,Glober- son, A.: Incorporating structured representations into pretrained vision & lan- guage models using scene graphs. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 14077–14098 (2023)
2023
-
[30]
Advances in neural information processing systems36, 31096–31116 (2023)
Hsieh, C.Y., Zhang, J., Ma, Z., Kembhavi, A., Krishna, R.: Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality. Advances in neural information processing systems36, 31096–31116 (2023)
2023
-
[31]
arXiv preprint arXiv:2501.13826 (2025)
Hu,K.,Wu,P.,Pu,F.,Xiao,W.,Zhang,Y.,Yue,X.,Li,B.,Liu,Z.:Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos. arXiv preprint arXiv:2501.13826 (2025)
Pith/arXiv arXiv 2025
-
[32]
arXiv preprint arXiv:2411.04997 (2024)
Huang, W., Wu, A., Yang, Y., Luo, X., Yang, Y., Hu, L., Dai, Q., Wang, C., Dai, X., Chen, D., et al.: Llm2clip: Powerful language model unlocks richer visual representation. arXiv preprint arXiv:2411.04997 (2024)
arXiv 2024
-
[33]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 6700–6709 (2019)
2019
-
[34]
Ilharco, G., Wortsman, M., Wightman, R., Gordon, C., Carlini, N., Taori, R., Dave, A., Shankar, V., Namkoong, H., Miller, J., Hajishirzi, H., Farhadi, A., Schmidt, L.: Openclip (Jul 2021).https://doi.org/10.5281/zenodo.5143773, https://doi.org/10.5281/zenodo.5143773, if you use this software, please cite it as below
-
[35]
In: NeurIPS (2023),https: //navidataset.github.io/
Jampani, V., Maninis, K.K., Engelhardt, A., Truong, K., Karpur, A., Sargent, K., Popov, S., Araujo, A., Martin-Brualla, R., Patel, K., Vlasic, D., Ferrari, V., Makadia, A., Liu, C., Li, Y., Zhou, H.: NAVI: Category-agnostic image collections with high-quality 3d shape and pose annotations. In: NeurIPS (2023),https: //navidataset.github.io/
2023
-
[36]
In: International conference on machine learning
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International conference on machine learning. pp. 4904–4916. PMLR (2021)
2021
-
[37]
In: Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., 18 Maharaj, T., Wagstaff, K., Zhu, J
Jiang, D., Zhang, R., Guo, Z., Li, Y., Qi, Y., Chen, X., Wang, L., Jin, J., Guo, C., Yan, S., Zhang, B., Fu, C., Gao, P., Li, H.: MME-CoT: Benchmarking chain- of-thought in large multimodal models for reasoning quality, robustness, and ef- ficiency. In: Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., 18 Maharaj, T., Wagstaff, K., Zhu, J...
2025
-
[38]
arXiv preprint arXiv:2407.12580 (2024)
Jiang, T., Song, M., Zhang, Z., Huang, H., Deng, W., Sun, F., Zhang, Q., Wang, D., Zhuang, F.: E5-v: Universal embeddings with multimodal large language mod- els. arXiv preprint arXiv:2407.12580 (2024)
Pith/arXiv arXiv 2024
-
[39]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Johnson, J., Hariharan, B., Van Der Maaten, L., Fei-Fei, L., Lawrence Zitnick, C., Girshick, R.: Clevr: A diagnostic dataset for compositional language and el- ementary visual reasoning. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2901–2910 (2017)
2017
-
[40]
arXiv preprint arXiv:2602.23351 (2026)
Kamath, A., Hessel, J., Chandu, K., Hwang, J.D., Chang, K.W., Krishna, R.: Scale can’t overcome pragmatics: The impact of reporting bias on vision-language reasoning. arXiv preprint arXiv:2602.23351 (2026)
arXiv 2026
-
[41]
In: EMNLP (2023)
Kamath, A., Hessel, J., Chang, K.W.: What’s “up” with vision-language models? investigating their struggle with spatial reasoning. In: EMNLP (2023)
2023
-
[42]
In: European conference on computer vision
Kembhavi, A., Salvato, M., Kolve, E., Seo, M., Hajishirzi, H., Farhadi, A.: A diagram is worth a dozen images. In: European conference on computer vision. pp. 235–251. Springer (2016)
2016
-
[43]
arXiv preprint arXiv:2405.20204 (2024)
Koukounas, A., Mastrapas, G., Günther, M., Wang, B., Martens, S., Mohr, I., Sturua, S., Akram, M.K., Martínez, J.F., Ognawala, S., et al.: Jina clip: Your clip model is also your text retriever. arXiv preprint arXiv:2405.20204 (2024)
arXiv 2024
-
[44]
Koukounas, A., Mastrapas, G., Wang, B., Akram, M.K., Eslami, S., Günther, M., Mohr, I., Sturua, S., Martens, S., Wang, N., Xiao, H.: jina-clip-v2: Multilingual multimodal embeddings for text and images (2024),https://arxiv.org/abs/ 2412.08802
arXiv 2024
-
[45]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
2009
-
[46]
arXiv preprint arXiv:2510.16540 (2025)
Kwon, J., Min, K., Sohn, J.y.: Enhancing compositional reasoning in clip via re- construction and alignment of text descriptions. arXiv preprint arXiv:2510.16540 (2025)
arXiv 2025
-
[47]
In: Proceedings of the ACM SIGOPS 29th Sympo- sium on Operating Systems Principles (2023)
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C.H., Gonzalez, J.E., Zhang, H., Stoica, I.: Efficient memory management for large language model serving with pagedattention. In: Proceedings of the ACM SIGOPS 29th Sympo- sium on Operating Systems Principles (2023)
2023
-
[48]
Laurençon, H., Saulnier, L., Tronchon, L., Bekman, S., Singh, A., Lozhkov, A., Wang, T., Karamcheti, S., Rush, A.M., Kiela, D., Cord, M., Sanh, V.: Obelics: An open web-scale filtered dataset of interleaved image-text documents (2023)
2023
-
[49]
arXiv preprint arXiv:2408.03326 (2024)
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
Pith/arXiv arXiv 2024
-
[50]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
2023
-
[51]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Li, L.H., Zhang, P., Zhang, H., Yang, J., Li, C., Zhong, Y., Wang, L., Yuan, L., Zhang, L., Hwang, J.N., et al.: Grounded language-image pre-training. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 10965–10975 (2022)
2022
-
[52]
In: Proceedings 19 of the IEEE/CVF conference on computer vision and pattern recognition
Li, M., Xu, R., Wang, S., Zhou, L., Lin, X., Zhu, C., Zeng, M., Ji, H., Chang, S.F.: Clip-event: Connecting text and images with event structures. In: Proceedings 19 of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16420–16429 (2022)
2022
-
[53]
Li, X., Tu, H., Hui, M., Wang, Z., Zhao, B., Xiao, J., Ren, S., Mei, J., Liu, Q., Zheng, H., et al.: What if we recaption billions of web images with llama-3? arXiv preprint arXiv:2406.08478 (2024)
arXiv 2024
-
[54]
arXiv preprint arXiv:2110.05208 (2021)
Li, Y., Liang, F., Zhao, L., Cui, Y., Ouyang, W., Shao, J., Yu, F., Yan, J.: Super- vision exists everywhere: A data efficient contrastive language-image pre-training paradigm. arXiv preprint arXiv:2110.05208 (2021)
arXiv 2021
-
[55]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Y., Fan, H., Hu, R., Feichtenhofer, C., He, K.: Scaling language-image pre- training via masking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 23390–23400 (2023)
2023
-
[56]
In: European confer- ence on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European confer- ence on computer vision. pp. 740–755. Springer (2014)
2014
-
[57]
io/blog/2024-01-30-llava-next/
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (January 2024),https://llava-vl.github. io/blog/2024-01-30-llava-next/
2024
-
[58]
arXiv preprint arXiv:2411.16828 (2024)
Liu, Y., Li, X., Wang, Z., Zhao, B., Xie, C.: Clips: An enhanced clip framework for learning with synthetic captions. arXiv preprint arXiv:2411.16828 (2024)
arXiv 2024
-
[59]
Ma, Z., Hong, J., Gul, M.O., Gandhi, M., Gao, I., Krishna, R.: Crepe: Can vision-language foundation models reason compositionally? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10910–10921 (2023)
2023
-
[60]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A.L., Murphy, K.: Gen- eration and comprehension of unambiguous object descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 11–20 (2016)
2016
-
[61]
In: Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Marino, K., Rastegari, M., Farhadi, A., Mottaghi, R.: Ok-vqa: A visual question answering benchmark requiring external knowledge. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
2019
-
[62]
In: Findings of the association for computational linguistics: ACL 2022
Masry, A., Do, X.L., Tan, J.Q., Joty, S., Hoque, E.: Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In: Findings of the association for computational linguistics: ACL 2022. pp. 2263–2279 (2022)
2022
-
[63]
In: European Conference on Computer Vision
McKinzie, B., Gan, Z., Fauconnier, J.P., Dodge, S., Zhang, B., Dufter, P., Shah, D., Du, X., Peng, F., Belyi, A., et al.: Mm1: methods, analysis and insights from multimodal llm pre-training. In: European Conference on Computer Vision. pp. 304–323. Springer (2024)
2024
-
[64]
arXiv preprint arXiv:2410.05210 (2024)
Oh, Y., Cho, J.W., Kim, D.J., Kweon, I.S., Kim, J.: Preserving multi-modal capabilities of pre-trained vlms for improving vision-linguistic compositionality. arXiv preprint arXiv:2410.05210 (2024)
arXiv 2024
-
[65]
In: European Conference on Computer Vision
Onoe, Y., Rane, S., Berger, Z., Bitton, Y., Cho, J., Garg, R., Ku, A., Parekh, Z., Pont-Tuset,J.,Tanzer,G.,etal.:Docci:Descriptionsofconnectedandcontrasting images. In: European Conference on Computer Vision. pp. 291–309. Springer (2024)
2024
-
[66]
arXiv preprint arXiv:2304.07193 (2023)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez,P.,Haziza,D.,Massa,F.,El-Nouby,A.,etal.:Dinov2:Learningrobust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
Pith/arXiv arXiv 2023
-
[67]
In: Proceedings of the 60th Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers)
Parcalabescu, L., Cafagna, M., Muradjan, L., Frank, A., Calixto, I., Gatt, A.: Valse: A task-independent benchmark for vision and language models centered 20 on linguistic phenomena. In: Proceedings of the 60th Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers). pp. 8253–8280 (2022)
2022
-
[68]
Patel, M., Kusumba, N.S.A., Cheng, S., Kim, C., Gokhale, T., Baral, C., et al.: Tripletclip: Improving compositional reasoning of clip via synthetic vision- languagenegatives.Advancesinneuralinformationprocessingsystems37,32731– 32760 (2024)
2024
-
[69]
In: International conference on machine learning
Radford,A.,Kim,J.W.,Hallacy,C.,Ramesh,A.,Goh,G.,Agarwal,S.,Sastry,G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[70]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Rao, Y., Zhao, W., Chen, G., Tang, Y., Zhu, Z., Huang, G., Zhou, J., Lu, J.: Denseclip: Language-guided dense prediction with context-aware prompting. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 18082–18091 (2022)
2022
-
[71]
Recht, B., Roelofs, R., Schmidt, L., Shankar, V.: Do imagenet classifiers generalize to imagenet? In: International conference on machine learning. pp. 5389–5400. PMLR (2019)
2019
-
[72]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision
Sahin, U., Li, H., Khan, Q., Cremers, D., Tresp, V.: Enhancing multimodal com- positional reasoning of visual language models with generative negative mining. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision. pp. 5563–5573 (2024)
2024
-
[73]
International Journal on Digital Libraries23(3), 289–301 (2022)
Saikh, T., Ghosal, T., Mittal, A., Ekbal, A., Bhattacharyya, P.: Scienceqa: A novel resource for question answering on scholarly articles. International Journal on Digital Libraries23(3), 289–301 (2022)
2022
-
[74]
arXiv preprint arXiv:2111.02114 (2021)
Schuhmann, C., Vencu, R., Beaumont, R., Kaczmarczyk, R., Mullis, C., Katta, A., Coombes, T., Jitsev, J., Komatsuzaki, A.: Laion-400m: Open dataset of clip- filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114 (2021)
Pith/arXiv arXiv 2021
-
[75]
In: European conference on computer vision
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from rgbd images. In: European conference on computer vision. pp. 746–
-
[76]
arXiv preprint arXiv:2601.03267 (2025)
Singh, A.,Fry, A., Perelman, A., Tart,A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
Pith/arXiv arXiv 2025
-
[77]
arXiv preprint arXiv:2103.01913 (2021)
Srinivasan, K., Raman, K., Chen, J., Bendersky, M., Najork, M.: Wit: Wikipedia- based image text dataset for multimodal multilingual machine learning. arXiv preprint arXiv:2103.01913 (2021)
arXiv 2021
-
[78]
In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Subramanian, S., Merrill, W., Darrell, T., Gardner, M., Singh, S., Rohrbach, A.: Reclip: A strong zero-shot baseline for referring expression comprehension. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 5198–5215 (2022)
2022
-
[79]
arXiv preprint arXiv:2303.15389 (2023)
Sun, Q., Fang, Y., Wu, L., Wang, X., Cao, Y.: Eva-clip: Improved training tech- niques for clip at scale. arXiv preprint arXiv:2303.15389 (2023)
Pith/arXiv arXiv 2023
-
[80]
arXiv preprint arXiv:2402.04252 (2024)
Sun, Q., Wang, J., Yu, Q., Cui, Y., Zhang, F., Zhang, X., Wang, X.: Eva-clip-18b: Scaling clip to 18 billion parameters. arXiv preprint arXiv:2402.04252 (2024)
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.