Speaking Numbers to LLMs: Multi-Wavelet Number Embeddings for Time Series Forecasting
Pith reviewed 2026-06-26 05:33 UTC · model grok-4.3
The pith
Multi-wavelet digit embeddings let LLMs forecast time series more accurately by overriding standard token representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
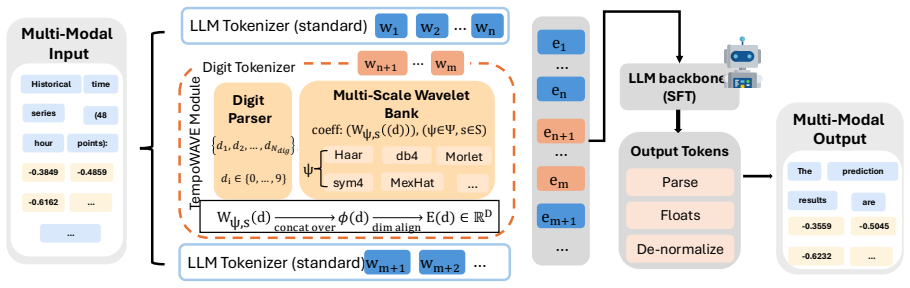
TempoWave is a plug-and-play temporal wavelet digit interface that converts each scalar observation into digit-wise embeddings constructed from multi-wavelet, multi-scale coefficients. By directly overriding standard token representations, it exposes both fine-grained local fluctuations and macro global structures in a form compatible with existing transformer pipelines, while preserving precise numerical formatting, distinct digit identity, and robustness to common normalization operations.
What carries the argument
The multi-wavelet multi-scale coefficient embeddings that override standard token representations for each scalar observation.
If this is right
- LLM-based forecasters reach higher accuracy on context-enriched benchmarks than with standard tokenization.
- Numerical ordering and robustness to normalization remain intact through the full pipeline.
- Both local fluctuations and global structures become directly accessible to the model without architecture changes.
- A new state-of-the-art is achieved for context-aware time series forecasting that uses LLMs.
Where Pith is reading between the lines
- The same embedding override could be tested on LLM tasks that require exact numerical computation, such as equation solving or simulation output analysis.
- Applying the method to longer sequences or different transformer variants would show whether the multi-resolution benefit scales.
- Combining the interface with lightweight fine-tuning on numerical data might further strengthen coupling between context and forecast precision.
Load-bearing premise
The multi-wavelet coefficients preserve precise numerical ordering and digit identity when overriding standard token representations inside the transformer pipeline.
What would settle it
If TempoWave produces no accuracy gain or lower accuracy than standard numeric tokenization when tested on the same five context-enriched forecasting benchmarks.
Figures
read the original abstract
Large language models (LLMs) are attractive for context-aware time series forecasting because they can integrate heterogeneous textual signals, yet their discrete, language-oriented tokenization and embedding interfaces are misaligned with continuous numerical values, often harming numerical ordering and forecasting reliability. We propose TempoWave, a plug-and-play temporal wavelet digit interface that maps each scalar observation into digit-wise embeddings constructed from multi-wavelet, multi-scale coefficients. By directly overriding standard token representations, TempoWave seamlessly exposes both fine-grained local fluctuations and macro global structures in a transformer-compatible form, ensuring that precise numerical formatting, distinct digit identity, and robustness to common normalization operations are maintained throughout the LLM pipeline. Experiments across five context-enriched forecasting benchmarks demonstrate that TempoWave consistently improves LLM-based forecasters over standard numeric tokenization and alternative embedding interfaces, achieving a new state-of-the-art. These results highlight the numeric interface as a key bottleneck and suggest that principled multi-resolution embeddings can better couple LLMs' contextual reasoning with precise forecasting. Our code is available at https://github.com/DC-research/TempoWAVE and our model can be accessed at https://huggingface.co/Melady/TempoWAVE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TempoWave, a plug-and-play temporal wavelet digit interface that maps each scalar observation into digit-wise embeddings from multi-wavelet, multi-scale coefficients. By overriding standard token representations, it aims to expose fine-grained and global structures while preserving numerical formatting, digit identity, and robustness to normalization. Experiments on five context-enriched forecasting benchmarks are claimed to show consistent improvements over standard numeric tokenization and alternative interfaces, achieving new state-of-the-art results for LLM-based forecasters.
Significance. If the empirical results hold with proper controls and statistical support, the work could meaningfully address the numeric interface bottleneck in LLM-based time series forecasting. The plug-and-play design and public code/model release are strengths that would facilitate adoption and verification. The multi-resolution wavelet approach offers a principled alternative to ad-hoc numeric tokenization, with potential broader relevance to other continuous-data LLM applications.
major comments (2)
- [Abstract] Abstract: The central claim of 'consistent improvements' and 'new state-of-the-art' is asserted without any quantitative results, baseline names, effect sizes, or statistical tests. This absence makes it impossible to evaluate whether the reported gains are load-bearing or merely incremental, directly undermining assessment of the paper's primary contribution.
- [Method] Method description (inferred from abstract): No equations, pseudocode, or explicit construction details are supplied for how multi-wavelet coefficients are computed, how they override token embeddings, or how invertibility is ensured to preserve numerical ordering and digit identity. Without these, the weakest assumption (compatibility without model changes while retaining precise numeric properties) cannot be checked.
minor comments (1)
- [Abstract] The abstract mentions 'five context-enriched forecasting benchmarks' but provides no names or references; adding these would improve clarity even if results are expanded elsewhere.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where the abstract and method presentation can be strengthened for clarity and evaluability. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'consistent improvements' and 'new state-of-the-art' is asserted without any quantitative results, baseline names, effect sizes, or statistical tests. This absence makes it impossible to evaluate whether the reported gains are load-bearing or merely incremental, directly undermining assessment of the paper's primary contribution.
Authors: We agree that the abstract should include quantitative support for the claims. In the revised version we will incorporate specific performance deltas, baseline names, effect sizes, and reference to statistical tests from the experimental section. revision: yes
-
Referee: [Method] Method description (inferred from abstract): No equations, pseudocode, or explicit construction details are supplied for how multi-wavelet coefficients are computed, how they override token embeddings, or how invertibility is ensured to preserve numerical ordering and digit identity. Without these, the weakest assumption (compatibility without model changes while retaining precise numeric properties) cannot be checked.
Authors: The referee is correct that the provided abstract contains no such details. The full manuscript will be revised to include explicit equations for multi-wavelet coefficient extraction, the embedding override procedure, pseudocode, and a clear account of how numerical ordering and digit identity are preserved (including invertibility considerations). revision: yes
Circularity Check
No significant circularity detected
full rationale
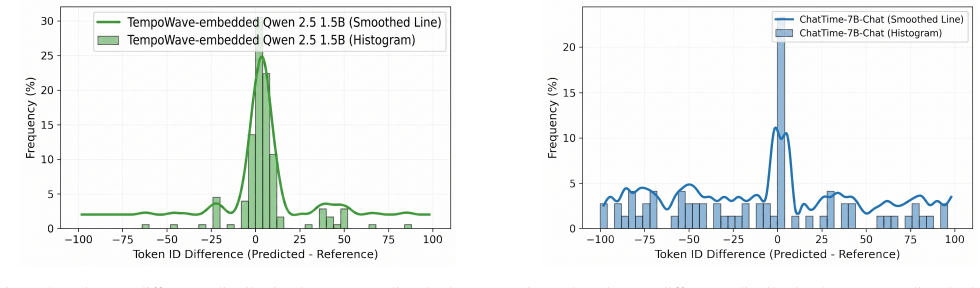
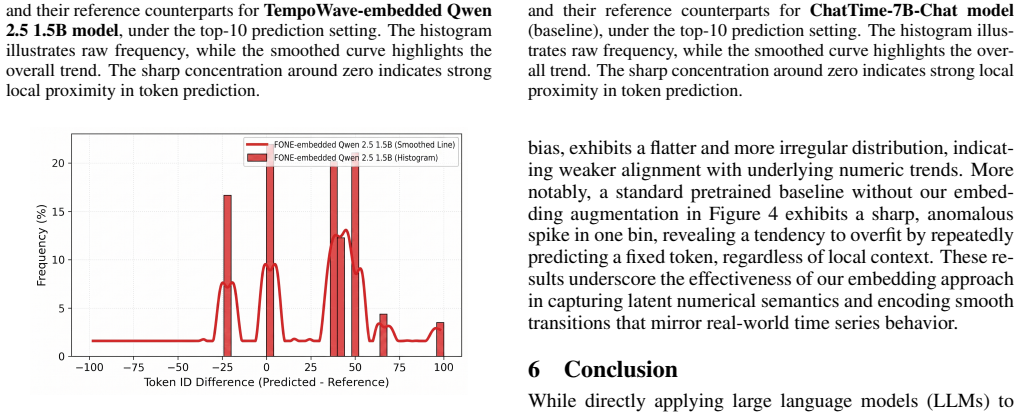
The paper proposes TempoWave, a new plug-and-play embedding method that maps time series scalars to multi-wavelet digit-wise representations for LLM-based forecasting. The central claims rest on the construction of these embeddings (via invertible wavelet transforms to preserve ordering and digit identity) and empirical results across five benchmarks showing improvements over baselines. No load-bearing equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or method description that would reduce the claimed gains to inputs by construction. The approach is presented as an independent interface compatible with existing transformers, with validation external to any internal fit.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815,
[Ansariet al., 2024 ] Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Se- bastian Pineda Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815,
Pith/arXiv arXiv 2024
-
[2]
Spectral temporal graph neural network for multivariate time-series forecast- ing.Advances in neural information processing systems, 33:17766–17778,
[Caoet al., 2020 ] Defu Cao, Yujing Wang, Juanyong Duan, Ce Zhang, Xia Zhu, Congrui Huang, Yunhai Tong, Bix- iong Xu, Jing Bai, Jie Tong, et al. Spectral temporal graph neural network for multivariate time-series forecast- ing.Advances in neural information processing systems, 33:17766–17778,
2020
-
[3]
Spectral temporal graph neural net- work for trajectory prediction
[Caoet al., 2021 ] Defu Cao, Jiachen Li, Hengbo Ma, and Masayoshi Tomizuka. Spectral temporal graph neural net- work for trajectory prediction. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 1839–1845,
2021
-
[4]
[Caoet al., 2024b ] Defu Cao, Wen Ye, Yizhou Zhang, and Yan Liu. Timedit: General-purpose diffusion transform- ers for time series foundation model.arXiv preprint arXiv:2409.02322,
-
[5]
[Caoet al., 2025 ] Defu Cao, Michael Gee, Jinbo Liu, Hengxuan Wang, Wei Yang, Rui Wang, and Yan Liu. Conversational time series foundation models: Towards explainable and effective forecasting.arXiv preprint arXiv:2512.16022,
arXiv 2025
-
[6]
PINFDit: Energy-based physics- informed diffusion transformers for general-purpose time series tasks
[Caoet al., 2026 ] Defu Cao, Wen Ye, Yizhou Zhang, Sam Griesemer, and Yan Liu. PINFDit: Energy-based physics- informed diffusion transformers for general-purpose time series tasks. InThe Fourteenth International Conference on Learning Representations,
2026
-
[7]
A decoder-only foundation model for time-series forecasting
[Daset al., 2024 ] Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InForty-first International Con- ference on Machine Learning,
2024
-
[8]
Fourier head: Helping large language models learn complex probability distri- butions
[Gillmanet al., 2025 ] Nate Gillman, Daksh Aggarwal, Michael Freeman, and Chen Sun. Fourier head: Helping large language models learn complex probability distri- butions. InThe Thirteenth International Conference on Learning Representations,
2025
-
[9]
Moment: A family of open time-series foundation models
[Goswamiet al., 2024 ] Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. Moment: A family of open time-series foundation models. InInternational Conference on Machine Learning, pages 16115–16152. PMLR,
2024
-
[10]
Large language models are zero- shot time series forecasters.Advances in Neural Informa- tion Processing Systems, 36,
[Gruveret al., 2024 ] Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G Wilson. Large language models are zero- shot time series forecasters.Advances in Neural Informa- tion Processing Systems, 36,
2024
-
[11]
Context-alignment: Ac- tivating and enhancing LLMs capabilities in time series
[Huet al., 2025 ] Yuxiao Hu, Qian Li, Dongxiao Zhang, Jinyue Yan, and Yuntian Chen. Context-alignment: Ac- tivating and enhancing LLMs capabilities in time series. InThe Thirteenth International Conference on Learning Representations,
2025
-
[12]
Gpt4mts: Prompt-based large language model for multimodal time-series forecasting
[Jiaet al., 2024 ] Furong Jia, Kevin Wang, Yixiang Zheng, Defu Cao, and Yan Liu. Gpt4mts: Prompt-based large language model for multimodal time-series forecasting. In The 14th Symposium on Educational Advances in Artifi- cial Intelligence (EAAI-24),
2024
-
[13]
Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen
[Jinet al., 2024 ] Ming Jin, Shiyu Wang, Lintao Ma, Zhix- uan Chu, James Y . Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen. Time-LLM: Time series forecasting by reprogram- ming large language models. InThe Twelfth International Conference on Learning Representations,
2024
-
[14]
someone hid it!
[Liet al., 2026 ] Jiate Li, Defu Cao, Li Li, Wei Yang, Yue- han Qin, Chenxiao Yu, Tiannuo Yang, Ryan A Rossi, Yan Liu, Xiyang Hu, et al. “someone hid it!”: Query-agnostic black-box attacks on LLM-based retrieval. InForty-third International Conference on Machine Learning,
2026
-
[15]
Non-stationary transformers: Exploring the stationarity in time series forecasting
[Liuet al., 2022 ] Yong Liu, Haixu Wu, Jianmin Wang, and Mingsheng Long. Non-stationary transformers: Exploring the stationarity in time series forecasting. InAdvances in Neural Information Processing Systems,
2022
-
[16]
catch22: Canonical time-series characteristics: Se- lected through highly comparative time-series analysis
[Lubbaet al., 2019 ] Carl H Lubba, Sarab S Sethi, Philip Knaute, Simon R Schultz, Ben D Fulcher, and Nick S Jones. catch22: Canonical time-series characteristics: Se- lected through highly comparative time-series analysis. Data mining and knowledge discovery, 33(6):1821–1852,
2019
-
[17]
Language models still struggle to zero-shot reason about time series
[Merrillet al., 2024 ] Mike A Merrill, Mingtian Tan, Vinayak Gupta, Thomas Hartvigsen, and Tim Althoff. Language models still struggle to zero-shot reason about time series. InEMNLP (Findings),
2024
-
[18]
Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam
[Nieet al., 2023 ] Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InInternational Conference on Learning Representations (ICLR ’23),
2023
-
[19]
Gpt-4 technical report,
[OpenAI, 2023] OpenAI. Gpt-4 technical report,
2023
-
[20]
[Oreshkinet al., 2019 ] Boris N Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-beats: Neural basis expansion analysis for interpretable time series fore- casting.arXiv preprint arXiv:1905.10437,
arXiv 2019
-
[21]
Totem: Tokenized time series embed- dings for general time series analysis.Transactions on Ma- chine Learning Research,
[Talukderet al., 2024 ] Sabera J Talukder, Yisong Yue, and Georgia Gkioxari. Totem: Tokenized time series embed- dings for general time series analysis.Transactions on Ma- chine Learning Research,
2024
-
[22]
From news to forecast: Inte- grating event analysis in llm-based time series forecasting with reflection
[Wanget al., 2024 ] Xinlei Wang, Maike Feng, Jing Qiu, Jin- jin Gu, and Junhua Zhao. From news to forecast: Inte- grating event analysis in llm-based time series forecasting with reflection. InNeural Information Processing Systems,
2024
-
[23]
Chattime: A unified multimodal time series foundation model bridging numerical and textual data
[Wanget al., 2025 ] Chengsen Wang, Qi Qi, Jingyu Wang, Haifeng Sun, Zirui Zhuang, Jinming Wu, Lei Zhang, and Jianxin Liao. Chattime: A unified multimodal time series foundation model bridging numerical and textual data. In Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 39, pages 12694–12702,
2025
-
[24]
[Wenget al., 2026 ] Muyan Weng, Defu Cao, Wei Yang, Yashaswi Sharma, and Yan Liu. Temporalbench: A benchmark for evaluating llm-based agents on contex- tual and event-informed time series tasks.arXiv preprint arXiv:2602.13272,
arXiv 2026
-
[25]
Unified training of universal time series forecasting trans- formers
[Wooet al., 2024 ] Gerald Woo, Chenghao Liu, Akshat Ku- mar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting trans- formers. InForty-first International Conference on Ma- chine Learning,
2024
-
[26]
Autoformer: Decomposition transform- ers with auto-correlation for long-term series forecasting
[Wuet al., 2021 ] Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transform- ers with auto-correlation for long-term series forecasting. InAdvances in Neural Information Processing Systems (NeurIPS), pages 101–112,
2021
-
[27]
Timesnet: Temporal 2d-variation modeling for general time series analysis
[Wuet al., 2023 ] Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. Timesnet: Temporal 2d-variation modeling for general time series analysis. InThe Eleventh International Conference on Learning Representations,
2023
-
[28]
[Yanget al., 2025a ] Wei Yang, Defu Cao, and Yan Liu. Foundation models for demand forecasting via dual- strategy ensembling.arXiv preprint arXiv:2507.22053,
-
[29]
Adaptive collaboration with humans: Metacognitive policy optimization for multi- agent LLMs with continual learning
[Yanget al., 2026 ] Wei Yang, Defu Cao, Jiacheng Pang, Muyan Weng, and Yan Liu. Adaptive collaboration with humans: Metacognitive policy optimization for multi- agent LLMs with continual learning. InThe Fourteenth International Conference on Learning Representations,
2026
-
[30]
[Yeet al., 2025 ] Wen Ye, Jinbo Liu, Defu Cao, Wei Yang, and Yan Liu. When llm meets time series: Can llms per- form multi-step time series reasoning and inference.arXiv preprint arXiv:2509.01822,
arXiv 2025
-
[31]
TS- reasoner: Domain-oriented time series inference agents for reasoning and automated analysis.Transactions on Ma- chine Learning Research,
[Yeet al., 2026 ] Wen Ye, Wei Yang, Defu Cao, Yizhou Zhang, Lumingyuan Tang, Jie Cai, and Yan Liu. TS- reasoner: Domain-oriented time series inference agents for reasoning and automated analysis.Transactions on Ma- chine Learning Research,
2026
-
[32]
Are transformers effective for time series fore- casting? InProceedings of the AAAI conference on artifi- cial intelligence, volume 37, pages 11121–11128,
[Zenget al., 2023 ] Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series fore- casting? InProceedings of the AAAI conference on artifi- cial intelligence, volume 37, pages 11121–11128,
2023
-
[33]
[Zhanget al., 2022 ] Yizhou Zhang, Defu Cao, and Yan Liu. Counterfactual neural temporal point process for esti- mating causal influence of misinformation on social me- dia.Advances in Neural Information Processing Systems, 35:10643–10655,
2022
-
[34]
[Zhanget al., 2024 ] Yizhou Zhang, Lun Du, Defu Cao, Qiang Fu, and Yan Liu. Guiding large language models with divide-and-conquer program for discerning problem solving.arXiv preprint arXiv:2402.05359,
arXiv 2024
-
[35]
Can LLMs understand time series anomalies? InThe Thirteenth Inter- national Conference on Learning Representations,
[Zhou and Yu, 2025] Zihao Zhou and Rose Yu. Can LLMs understand time series anomalies? InThe Thirteenth Inter- national Conference on Learning Representations,
2025
-
[36]
Informer: Beyond efficient transformer for long sequence time-series forecasting
[Zhouet al., 2021 ] Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. InProceedings of AAAI,
2021
-
[37]
[Zhouet al., 2025 ] Tianyi Zhou, Deqing Fu, Mahdi Soltanolkotabi, Robin Jia, and Vatsal Sharan. Fone: Precise single-token number embeddings via fourier features.arXiv preprint arXiv:2502.09741, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.