Fine-Tuning Improves Information Conveyance in Language Models
Pith reviewed 2026-06-28 22:56 UTC · model grok-4.3
The pith
Fine-tuning does not merely reduce uncertainty in language models but reorganizes it to produce more informative and semantically meaningful generations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
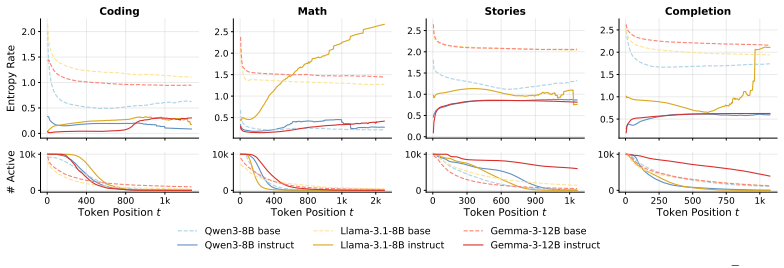
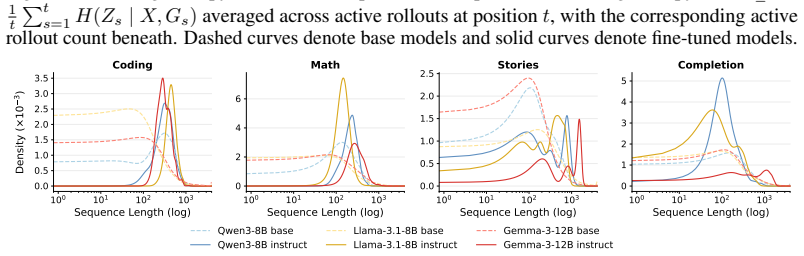
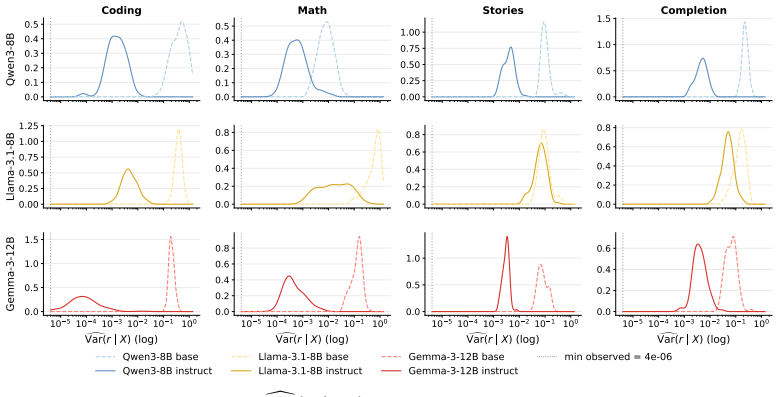
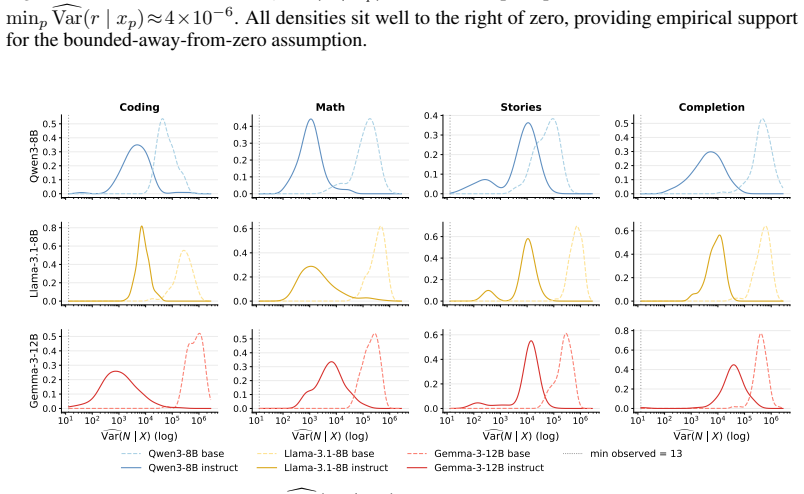
Fine-tuning reorganizes uncertainty in language models into more informative generations. Using Canopy Entropy, which captures total entropy of length and sequence, the study finds stronger length-entropy rate correlations in fine-tuned models. Controlling for confounds, the link between entropy rate and semantic diversity strengthens nearly threefold, showing aligned models convert token-level uncertainty into semantic diversity more efficiently.
What carries the argument
Canopy Entropy (CE*), defined as the joint Shannon entropy H(N, Y_{1:N}|X) of output length and sequence, which measures the effective size of the generation space from a tree perspective and yields the correlation term ρ(N, r_N).
Load-bearing premise
The experimental controls for model family, task, prompt, and output-length effects sufficiently isolate the causal effect of fine-tuning on the correlation between entropy rate and semantic diversity.
What would settle it
A controlled experiment on the same model families and tasks that finds the correlation between entropy rate and semantic diversity does not increase after fine-tuning would falsify the reorganization claim.
Figures
read the original abstract
Fine-tuning is often believed to reduce uncertainty and diversity in large language models, but existing analyses overlook output length, a key confounder, and therefore fail to capture how uncertainty is distributed across an entire generation rollout. To address this, we propose Canopy Entropy ($\mathrm{CE}^\star$), a measure that views language generation from a tree perspective, where ``canopy'' represents the space of all possible rollouts, making $\mathrm{CE}^\star$ naturally quantify the effective size of the generation space. $\mathrm{CE}^\star$ jointly captures uncertainty in both the output length $N$ and the generated sequence $Y_{1:N}$ -- indeed, we show that it equals to total Shannon entropy $H(N, Y_{1:N}\mid X)$, where $X$ denotes the prompt. This formulation yields interpretable metrics, including a length-entropy correlation term $\rho(N, r_N)$, where $r_N$ is the entropy rate, quantifying information conveyance efficiency by indicating whether longer outputs are more or less informative per token. Empirically, across tasks and model families, we find that fine-tuned models consistently exhibit stronger positive correlation $\rho(N, r_N)$, even when total entropy decreases. Furthermore, after controlling for model family, task, prompt, and output-length effects, we find that fine-tuning nearly triples the correlation strength between entropy rate and semantic diversity, suggesting that aligned models convert token uncertainty into semantic diversity more efficiently. Overall, these results demonstrate that fine-tuning does not simply reduce uncertainty, but fundamentally reorganizes it into more informative and semantically meaningful generations. Our code is available at https://github.com/WeiyiTian/canopy-entropy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Canopy Entropy (CE*), a metric equivalent by definition to the joint Shannon entropy H(N, Y_{1:N}|X) over output length N and token sequence given prompt X. It argues that fine-tuning does not merely reduce total uncertainty but reorganizes it, evidenced by stronger positive correlations ρ(N, r_N) (length vs. per-token entropy rate) in fine-tuned models and, after controls for model family/task/prompt/length, a near-tripling of the correlation between entropy rate and semantic diversity across tasks and families. Code is released.
Significance. If the causal attribution to fine-tuning survives detailed scrutiny of the controls, the result would usefully complicate the standard narrative that alignment simply compresses output distributions; the tree/canopy framing and explicit decomposition into length and rate components are conceptually clean. Public code is a clear positive for reproducibility.
major comments (2)
- [Experimental controls (abstract and §4)] The central causal claim (fine-tuning nearly triples the entropy-rate–semantic-diversity correlation) rests on the adequacy of the controls for output-length effects. Because CE* is defined to include H(N) and the paper already reports that total entropy frequently decreases post-fine-tuning, any residual length-distribution confounding would directly inflate the reported correlation strength. The manuscript states that length effects were controlled but supplies no explicit procedure (matching, stratification, regression specification, or post-hoc normalization) that would allow a reader to verify isolation of the fine-tuning effect.
- [Definition of ρ(N, r_N) and empirical results (§3, §5)] The interpretation of ρ(N, r_N) as a measure of “information conveyance efficiency” assumes that longer outputs being more informative per token is a desirable reorganization rather than an artifact of length bias in the fine-tuned distribution. The paper should demonstrate that this correlation remains after explicit length-matched sampling or length-regression adjustment, not merely after the stated controls.
minor comments (2)
- [Notation] The notation r_N for entropy rate should be defined explicitly in terms of the conditional entropy decomposition used for CE*; a short equation would remove ambiguity.
- [Figures] Figure captions and axis labels should state whether error bars reflect bootstrap, multiple seeds, or prompt variation, and whether the reported tripling is a ratio of Pearson or Spearman coefficients.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight the need for greater transparency in our controls and additional robustness checks. We address each point below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Experimental controls (abstract and §4)] The central causal claim (fine-tuning nearly triples the entropy-rate–semantic-diversity correlation) rests on the adequacy of the controls for output-length effects. Because CE* is defined to include H(N) and the paper already reports that total entropy frequently decreases post-fine-tuning, any residual length-distribution confounding would directly inflate the reported correlation strength. The manuscript states that length effects were controlled but supplies no explicit procedure (matching, stratification, regression specification, or post-hoc normalization) that would allow a reader to verify isolation of the fine-tuning effect.
Authors: We agree that an explicit description of the control procedure is essential. In our analysis, output-length effects were isolated by including log(output length) as a covariate in a linear regression model for the entropy-rate–semantic-diversity relationship, together with fixed effects for model family, task, and prompt. We will add a new subsection to §4 that fully specifies this regression (including the exact functional form, software implementation, and any multicollinearity diagnostics or sensitivity checks). This revision will allow full verification of the isolation of the fine-tuning effect. revision: yes
-
Referee: [Definition of ρ(N, r_N) and empirical results (§3, §5)] The interpretation of ρ(N, r_N) as a measure of “information conveyance efficiency” assumes that longer outputs being more informative per token is a desirable reorganization rather than an artifact of length bias in the fine-tuned distribution. The paper should demonstrate that this correlation remains after explicit length-matched sampling or length-regression adjustment, not merely after the stated controls.
Authors: ρ(N, r_N) is reported as an empirical observation of uncertainty reorganization (stronger positive correlation post-fine-tuning even when total entropy falls), not as an unqualified normative claim. The primary correlation analysis already incorporates output length via the regression controls described above. To directly test for length-distribution artifacts, we will add a length-matched subsampling analysis in the revision: generations from base and fine-tuned models will be subsampled to identical length distributions before recomputing both ρ(N, r_N) and the entropy-rate–semantic-diversity correlation. Results will be reported transparently regardless of outcome. revision: yes
Circularity Check
No circularity: CE* equality is definitional identity; reported correlations and tripling are empirical observations
full rationale
The paper defines Canopy Entropy (CE*) via a tree-based rollout view and states that it equals H(N, Y_{1:N}|X) by construction, which is a mathematical identity rather than a data-driven derivation. The central empirical claims—stronger ρ(N, r_N) in fine-tuned models and the tripling of its correlation with semantic diversity after controls—are measurements across model families, tasks, and prompts. These are not forced by the entropy equality itself. No self-citations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Canopy Entropy equals total Shannon entropy H(N, Y_{1:N} | X)
invented entities (1)
-
Canopy Entropy (CE*)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning
Shivam Agarwal, Zimin Zhang, Lifan Yuan, Jiawei Han, and Hao Peng. The unreasonable effectiveness of entropy minimization in llm reasoning.arXiv preprint arXiv:2505.15134, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Brown, Benjamin Mann, Nick Ryder, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, et al. Language models are few-shot learners. NeurIPS, 2020
2020
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
2024
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Mixed beta regression: A bayesian perspective.Computational Statistics & Data Analysis, 61:137–147, 2013
Jorge I Figueroa-Zúñiga, Reinaldo B Arellano-Valle, and Silvia LP Ferrari. Mixed beta regression: A bayesian perspective.Computational Statistics & Data Analysis, 61:137–147, 2013
2013
-
[7]
John Wiley & Sons, 1999
Gerald B Folland.Real analysis: modern techniques and their applications. John Wiley & Sons, 1999
1999
-
[8]
The vendi score: A diversity evaluation metric for machine learning
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning.arXiv preprint arXiv:2210.02410, 2022
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Benchmarking linguistic diversity of large language models.Transactions of the Association for Computational Linguistics, 13:1507–1526, 2025
Yanzhu Guo, Guokan Shang, and Chloé Clavel. Benchmarking linguistic diversity of large language models.Transactions of the Association for Computational Linguistics, 13:1507–1526, 2025
2025
-
[11]
Dharma: residual diagnostics for hierarchical (multi-level/mixed) regression models.CRAN: contributed packages, 2016
Florian Hartig. Dharma: residual diagnostics for hierarchical (multi-level/mixed) regression models.CRAN: contributed packages, 2016
2016
-
[12]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[13]
Amortizing intractable inference in large language models.arXiv preprint arXiv:2310.04363, 2023
Edward J Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, and Nikolay Malkin. Amortizing intractable inference in large language models.arXiv preprint arXiv:2310.04363, 2023. 11
-
[14]
Luchini, Reet Patel, Antoine Bosselut, Lonneke van der Plas, and Roger E
Mete Ismayilzada, Antonio Laverghetta Jr., Simone A. Luchini, Reet Patel, Antoine Bosselut, Lonneke van der Plas, and Roger E. Beaty. Creative preference optimization, 2025
2025
-
[15]
Perplexity—a measure of the difficulty of speech recognition tasks.The journal of the Acoustical Society of America, 62(S1):S63–S63, 1977
Fred Jelinek, Robert L Mercer, Lalit R Bahl, and James K Baker. Perplexity—a measure of the difficulty of speech recognition tasks.The journal of the Acoustical Society of America, 62(S1):S63–S63, 1977
1977
-
[16]
A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
Maurice G Kendall. A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
1938
-
[17]
From distributional to overton pluralism: Investi- gating large language model alignment
Thom Lake, Eunsol Choi, and Greg Durrett. From distributional to overton pluralism: Investi- gating large language model alignment. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6794–6814, 2025
2025
-
[18]
A diversity- promoting objective function for neural conversation models
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and William B Dolan. A diversity- promoting objective function for neural conversation models. InProceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies, pages 110–119, 2016
2016
-
[19]
Wei Lu, Rachel K Luu, and Markus J Buehler. Fine-tuning large language models for do- main adaptation: Exploration of training strategies, scaling, model merging and synergistic capabilities.npj Computational Materials, 11(1):84, 2025
2025
-
[20]
On stochastic limit and order relationships.The Annals of Mathematical Statistics, 14(3):217–226, 1943
Henry B Mann and Abraham Wald. On stochastic limit and order relationships.The Annals of Mathematical Statistics, 14(3):217–226, 1943
1943
-
[21]
The kolmogorov-smirnov test for goodness of fit.Journal of the American statistical Association, 46(253):68–78, 1951
Frank J Massey Jr. The kolmogorov-smirnov test for goodness of fit.Journal of the American statistical Association, 46(253):68–78, 1951
1951
-
[22]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[23]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[24]
Code Llama: Open Foundation Models for Code
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Principles of mathematical analysis
Walter Rudin. Principles of mathematical analysis. 2021
2021
-
[26]
Chantal Shaib, Venkata S Govindarajan, Joe Barrow, Jiuding Sun, Alexa F Siu, Byron C Wallace, and Ani Nenkova. Standardizing the measurement of text diversity: A tool and a comparative analysis of scores.arXiv preprint arXiv:2403.00553, 2024
-
[27]
A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
Claude Elwood Shannon. A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
1948
-
[28]
Does instruction tuning reduce diversity? a case study using code generation
Alexander Shypula, Shuo Li, Botong Zhang, Vishakh Padmakumar, Kayo Yin, and Osbert Bastani. Does instruction tuning reduce diversity? a case study using code generation
-
[29]
A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716, 2023
Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716, 2023
-
[30]
The proof and measurement of association between two things
Charles Spearman. The proof and measurement of association between two things. 1961
1961
-
[31]
Gemma 3 technical report, 2025
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, et al. Gemma 3 technical report, 2025
2025
-
[32]
Evaluating the evaluation of diversity in natural language generation
Guy Tevet and Jonathan Berant. Evaluating the evaluation of diversity in natural language generation. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 326–346, 2021. 12
2021
-
[33]
Shumin Wang, Yuexiang Xie, Wenhao Zhang, Yuchang Sun, Yanxi Chen, Yaliang Li, and Yanyong Zhang. On the entropy dynamics in reinforcement fine-tuning of large language models.arXiv preprint arXiv:2602.03392, 2026
-
[34]
Optimizing Diversity and Quality through Base-Aligned Model Collaboration
Yichen Wang, Chenghao Yang, Tenghao Huang, Muhao Chen, Jonathan May, and Mina Lee. Optimizing diversity and quality through base-aligned model collaboration.arXiv preprint arXiv:2511.05650, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference, 2024
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Jeremy Howard, and Iacopo Poli. Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference, 2024
2024
-
[36]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[37]
Base models beat aligned models at randomness and creativity
Peter West and Christopher Potts. Base models beat aligned models at randomness and creativity. arXiv preprint arXiv:2505.00047, 2025
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Chenghao Yang, Sida Li, and Ari Holtzman. Llm probability concentration: How alignment shrinks the generative horizon.arXiv preprint arXiv:2506.17871, 2025
-
[40]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
2019
-
[41]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, et al. Bigcodebench: Bench- marking code generation with diverse function calls and complex instructions.arXiv preprint arXiv:2406.15877, 2024. 13 A Missing proofs and algorithms A.1 Equivalence to a two-stage stoc...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
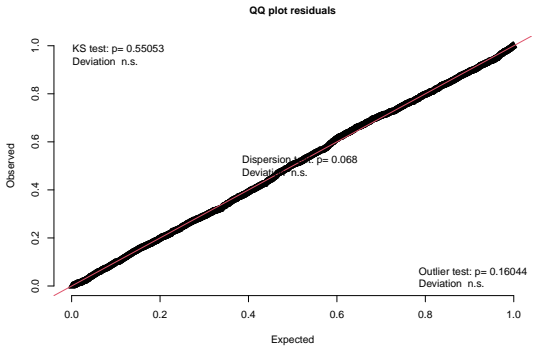
The residuals closely follow the diagonal reference line, indicating good overall model calibration and no substantial systematic deviation from the assumed distribution
for the fitted Beta mixed-effects regression model, comparing the empirical residual distribution against the expected uniform distribution. The residuals closely follow the diagonal reference line, indicating good overall model calibration and no substantial systematic deviation from the assumed distribution. The associated diagnostic tests further suppo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.