Evaluating the Interpretability of Sparse Autoencoders with Concept Annotations
Pith reviewed 2026-06-26 00:17 UTC · model grok-4.3
The pith
Sparse autoencoders lose alignment with human concepts as dictionary size grows larger.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
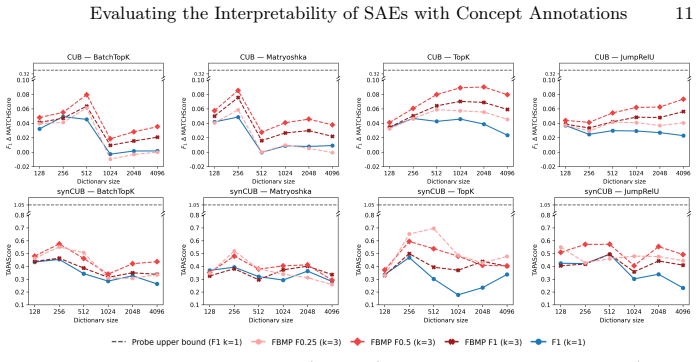
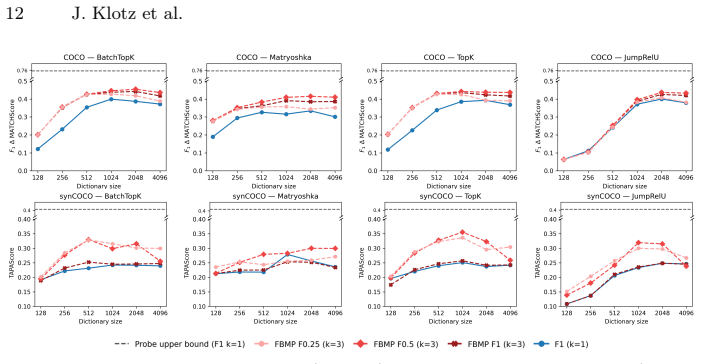
Across SAEs trained on CLIP and DINOv2 embeddings, increased overcompleteness reduces perturbation alignment, indicating a reduction in interpretability. The evaluation framework, built on synCUB and synCOCO paired images, Fully-Binary Matching Pursuit, and TAPAScore, identifies moderate dictionary sizes as the setting that yields the most interpretable SAEs.
What carries the argument
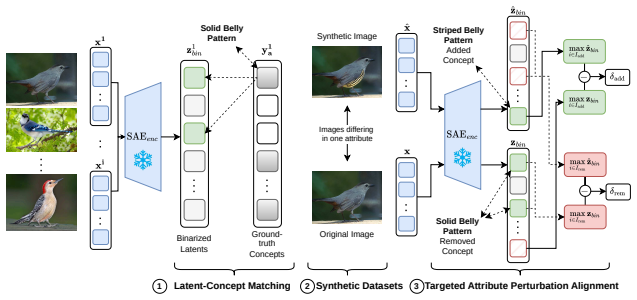
Targeted Attribute Perturbation Alignment Score (TAPAScore) that measures whether matched SAE latents change selectively and in the expected direction when a single annotated attribute is altered in synthetic image pairs.
If this is right
- Moderate dictionary sizes maximize perturbation alignment with human concepts.
- Overcompleteness reduces interpretability for SAEs trained on both CLIP and DINOv2 embeddings.
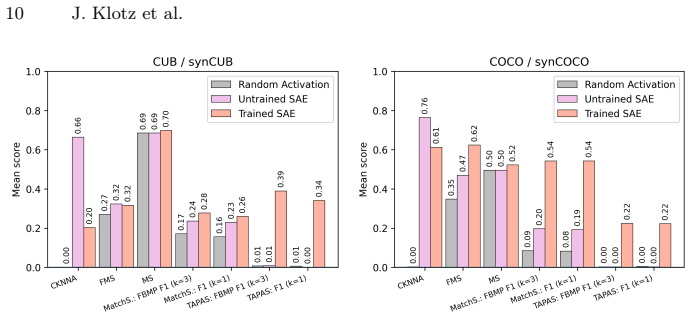
- The matching procedure and TAPAScore are the only tested metrics that reliably separate trained from untrained SAEs.
- Many-to-one mappings between latents and concepts improve matching accuracy over one-to-one baselines.
Where Pith is reading between the lines
- Practitioners extracting concepts from vision models may achieve cleaner features by avoiding extreme overcompleteness.
- The same perturbation test could be applied to other embedding models to check whether the moderate-size optimum generalizes.
- If the single-attribute isolation in the benchmarks holds for natural images, then current scaling trends toward larger dictionaries may systematically degrade concept-level interpretability.
Load-bearing premise
The synthetic benchmarks isolate exactly one attribute change per image pair without introducing unintended visual artifacts or correlations that affect SAE latents independently of the targeted concept.
What would settle it
Demonstrating that TAPAScore remains high or increases with very large dictionary sizes on the synCUB and synCOCO benchmarks would falsify the reported reduction in interpretability.
Figures



read the original abstract
Sparse autoencoders (SAEs) are increasingly used to extract interpretable concepts from vision and vision language models, yet existing evaluation methods largely rely on proxy metrics or qualitative inspection rather than measuring semantic correspondence. We present a human-grounded evaluation framework that quantifies alignment between SAE latents and human-annotated concepts, without requiring user studies, and validate this matching through targeted attribute perturbations. To enable this intervention-style evaluation in vision, we construct synCUB and synCOCO, synthetic benchmarks of paired images that differ in exactly one attribute. We introduce Fully-Binary Matching Pursuit (FBMP), a coalition-based matching procedure that supports many-to-one mappings between SAE latents and annotated concepts, and consistently outperforms one-to-one baselines. For functional validation, we propose a Targeted Attribute Perturbation Alignment Score (TAPAScore), which tests whether matched concepts respond selectively and in the expected direction under targeted image-level attribute perturbations. Under sanity checks, our matching and TAPAScore are the only evaluated metrics that reliably distinguish trained SAEs from untrained ones. Across SAEs trained on CLIP and DINOv2 embeddings, we find that increased overcompleteness can reduce perturbation alignment, indicating a reduction in interpretability. Our evaluation framework suggests that moderate dictionary sizes provide the best trade-off, yielding the most interpretable SAEs. Code and datasets are available at https://github.com/JonasKlotz/sae-concept-eval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a human-grounded evaluation framework for sparse autoencoders (SAEs) trained on vision and vision-language model embeddings. It constructs synthetic paired-image benchmarks (synCUB, synCOCO) differing in exactly one annotated attribute, proposes Fully-Binary Matching Pursuit (FBMP) to match SAE latents to concepts under many-to-one mappings, and defines the Targeted Attribute Perturbation Alignment Score (TAPAScore) to test selective response under attribute edits. The central empirical claim is that increased SAE overcompleteness reduces TAPAScore alignment on CLIP and DINOv2 embeddings, implying lower interpretability, with moderate dictionary sizes providing the best trade-off. Code and datasets are released.
Significance. If the synthetic benchmarks isolate single attributes without artifacts or unintended correlations, the framework supplies a quantitative, perturbation-based alternative to proxy metrics or qualitative inspection, strengthening claims about SAE interpretability. Public release of code and data is a clear strength that supports reproducibility.
major comments (3)
- [§3] §3 (Benchmark construction): The claim that synCUB and synCOCO pairs 'differ in exactly one attribute' is load-bearing for the TAPAScore results and the overcompleteness finding. The manuscript must supply explicit validation (e.g., pixel-difference statistics, background invariance checks, or semantic segmentation comparisons) showing that attribute editing introduces neither low-level artifacts nor correlated visual changes that could drive SAE latents independently of the target concept.
- [§5.3] §5.3 (Overcompleteness results): The reported reduction in perturbation alignment with larger dictionaries is the headline finding. The paper should report effect sizes, confidence intervals, and controls for multiple random seeds or training runs; without these, it is unclear whether the moderate-size optimum is robust or sensitive to the particular SAE training procedure.
- [§4.2] §4.2 (TAPAScore definition): The score is defined on matched concepts and requires that the matched latent responds 'in the expected direction.' The manuscript should clarify how directionality is determined when a concept can map to multiple latents under FBMP, and whether the score remains well-defined under the many-to-one regime.
minor comments (2)
- [§4] Notation for FBMP and TAPAScore should be introduced with explicit equations rather than prose descriptions alone.
- [Figures 2-3] Figure captions for the synthetic benchmark examples should include the exact attribute that was edited in each pair.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each of the major comments below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark construction): The claim that synCUB and synCOCO pairs 'differ in exactly one attribute' is load-bearing for the TAPAScore results and the overcompleteness finding. The manuscript must supply explicit validation (e.g., pixel-difference statistics, background invariance checks, or semantic segmentation comparisons) showing that attribute editing introduces neither low-level artifacts nor correlated visual changes that could drive SAE latents independently of the target concept.
Authors: We agree that providing explicit validation for the synthetic benchmarks is essential to support the TAPAScore results. In the revised manuscript, we will add detailed validation including pixel-difference statistics between paired images, background invariance checks, and semantic segmentation comparisons to demonstrate that the attribute edits do not introduce low-level artifacts or unintended correlations. revision: yes
-
Referee: [§5.3] §5.3 (Overcompleteness results): The reported reduction in perturbation alignment with larger dictionaries is the headline finding. The paper should report effect sizes, confidence intervals, and controls for multiple random seeds or training runs; without these, it is unclear whether the moderate-size optimum is robust or sensitive to the particular SAE training procedure.
Authors: We acknowledge that reporting effect sizes, confidence intervals, and robustness across multiple seeds is important for establishing the reliability of the overcompleteness finding. We will update the results section to include these metrics and controls for multiple random seeds in SAE training. revision: yes
-
Referee: [§4.2] §4.2 (TAPAScore definition): The score is defined on matched concepts and requires that the matched latent responds 'in the expected direction.' The manuscript should clarify how directionality is determined when a concept can map to multiple latents under FBMP, and whether the score remains well-defined under the many-to-one regime.
Authors: We appreciate this clarification request. The manuscript will be revised to explicitly explain how the expected direction is determined in the many-to-one mapping case under FBMP, including how the score is computed when multiple latents are matched to a concept, to ensure it is well-defined. revision: yes
Circularity Check
No circularity: empirical evaluation framework grounded in external annotations
full rationale
The paper presents an evaluation framework using human-annotated concepts on synthetic paired-image benchmarks (synCUB, synCOCO) and introduces FBMP matching plus TAPAScore for perturbation alignment. No equations, derivations, or first-principles claims reduce any result to fitted parameters or self-defined quantities by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The central findings on overcompleteness and dictionary size rest on controlled external perturbations and annotations rather than internal fits, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-annotated concepts provide accurate and complete semantic labels for the images in the benchmarks
invented entities (1)
-
synCUB and synCOCO synthetic benchmarks
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) (2025)
Bader, J., Girrbach, L., Alaniz, S., Akata, Z.: Sub: Benchmarking cbm generaliza- tion via synthetic attribute substitutions. Proceedings of the IEEE International Conference on Computer Vision (ICCV) (2025)
2025
-
[2]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Bau, D., Zhou, B., Khosla, A., Oliva, A., Torralba, A.: Network dissection: Quan- tifying interpretability of deep visual representations. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
2017
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) (2024)
Bhalla, U., Oesterling, A., Srinivas, S., Calmon, F.P., Lakkaraju, H.: Interpret- ing CLIP with sparse linear concept embeddings (SpLiCE). Advances in Neural Information Processing Systems (NeurIPS) (2024)
2024
-
[4]
ArXiv e-print (2024)
Bhalla, U., Srinivas, S., Ghandeharioun, A., Lakkaraju, H.: Towards unifying in- terpretability and control: Evaluation via intervention. ArXiv e-print (2024)
2024
-
[5]
Transformer Circuits Thread (2023)
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N.,Anil,C.,Denison,C.,Askell,A.,etal.:Towardsmonosemanticity:Decomposing language models with dictionary learning. Transformer Circuits Thread (2023)
2023
-
[6]
In: 2008 3rd International Symposium on Communications, Control and Signal Processing
Bruckstein, A.M., Elad, M., Zibulevsky, M.: Sparse non-negative solution of a linear system of equations is unique. In: 2008 3rd International Symposium on Communications, Control and Signal Processing. pp. 762–767. IEEE (2008)
2008
-
[7]
NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning (2024)
Bussmann, B., Leask, P., Nanda, N.: BatchTopK sparse autoencoders. NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning (2024)
2024
-
[8]
Proceedings of the International Con- ference on Machine Learning (ICML) (2025)
Bussmann, B., Nabeshima, N., Karvonen, A., Nanda, N.: Learning multi-level fea- tures with matryoshka sparse autoencoders. Proceedings of the International Con- ference on Machine Learning (ICML) (2025)
2025
-
[9]
IEEE transactions on neural networks and learning systems 35(7), 8747–8761 (2022)
Carbonneau, M.A., Zaidi, J., Boilard, J., Gagnon, G.: Measuring disentanglement: A review of metrics. IEEE transactions on neural networks and learning systems 35(7), 8747–8761 (2022)
2022
-
[10]
Advances in Neural Information Processing Systems (NeurIPS) (2025)
Chanin, D., Wilken-Smith, J., Dulka, T., Bhatnagar, H., Golechha, S., Bloom, J.: A is for absorption: Studying feature splitting and absorption in sparse autoencoders. Advances in Neural Information Processing Systems (NeurIPS) (2025)
2025
-
[11]
stat (2017)
Doshi-Velez,F.,Kim,B.:Towardsarigorousscienceofinterpretablemachinelearn- ing. stat (2017)
2017
-
[12]
ArXiv e-print (2022)
Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., Hatfield- Dodds, Z., Lasenby, R., Drain, D., Chen, C., et al.: Toy models of superposition. ArXiv e-print (2022)
2022
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) (2023)
Fel, T., Boutin, V., Béthune, L., Cadène, R., Moayeri, M., Andéol, L., Chalvi- dal, M., Serre, T.: A holistic approach to unifying automatic concept extraction and concept importance estimation. Advances in Neural Information Processing Systems (NeurIPS) (2023)
2023
-
[14]
Proceedings of the International Conference on Machine Learning (ICML) (2025)
Fel, T., Lubana, E.S., Prince, J.S., Kowal, M., Boutin, V., Papadimitriou, I., Wang, B., Wattenberg, M., Ba, D.E., Konkle, T.: Archetypal SAE: Adaptive and stable dictionary learning for concept extraction in large vision models. Proceedings of the International Conference on Machine Learning (ICML) (2025)
2025
-
[15]
Proceedings of the International Con- ference on Learning Representations (ICLR) (2026)
Fel, T., Wang, B., Lepori, M.A., Kowal, M., Lee, A., Balestriero, R., Joseph, S., Lubana, E.S., Konkle, T., Ba, D., et al.: Into the rabbit hull: From task-relevant concepts in DINO to minkowski geometry. Proceedings of the International Con- ference on Learning Representations (ICLR) (2026)
2026
-
[16]
Proceedings of the International Conference on Learning Representations (ICLR) (2025) 16 J
Gao, L., la Tour, T.D., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J., Wu, J.: Scaling and evaluating sparse autoencoders. Proceedings of the International Conference on Learning Representations (ICLR) (2025) 16 J. Klotz et al
2025
-
[17]
Advances in Neu- ral Information Processing Systems (NeurIPS) (2024)
Ghandeharioun, A., Yuan, A., Guerard, M., Reif, E., Lepori, M., Dixon, L.: Who’s asking? user personas and the mechanics of latent misalignment. Advances in Neu- ral Information Processing Systems (NeurIPS) (2024)
2024
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) (2025)
Härle, R., Friedrich, F., Brack, M., Wäldchen, S., Deiseroth, B., Schramowski, P., Kersting, K.: Measuring and guiding monosemanticity. Advances in Neural Information Processing Systems (NeurIPS) (2025)
2025
-
[19]
The Journal of Transactions on Machine Learning Research (TMLR) (2023)
Hedström, A., Bommer, P., Wickstrøm, K.K., Samek, W., Lapuschkin, S., Höhne, M.M.C.: The meta-evaluation problem in explainable AI: identifying reliable es- timators with metaquantus. The Journal of Transactions on Machine Learning Research (TMLR) (2023)
2023
-
[20]
Proceedings of the International Conference on Learning Representations (ICLR) (2024)
Hernandez, E., Sharma, A.S., Haklay, T., Meng, K., Wattenberg, M., Andreas, J., Belinkov, Y., Bau, D.: Linearity of relation decoding in transformer language models. Proceedings of the International Conference on Learning Representations (ICLR) (2024)
2024
-
[21]
Proceedings of the International Conference on Learning Representations (ICLR) (2024)
Huben, R., Cunningham, H., Smith, L.R., Ewart, A., Sharkey, L.: Sparse autoen- coders find highly interpretable features in language models. Proceedings of the International Conference on Learning Representations (ICLR) (2024)
2024
-
[22]
Mechanistic Interpretability for Vision at CVPR 2025 (Non- proceedings Track) (2025)
Joseph, S., Suresh, P., Goldfarb, E., Hufe, L., Gandelsman, Y., Graham, R., Bzdok, D., Samek, W., Richards, B.A.: Steering clip’s vision transformer with sparse autoencoders. Mechanistic Interpretability for Vision at CVPR 2025 (Non- proceedings Track) (2025)
2025
-
[23]
Proceedings of the International Conference on Machine Learning (ICML) (2018)
Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., et al.: Inter- pretabilitybeyondfeatureattribution:Quantitativetestingwithconceptactivation vectors (TCAV). Proceedings of the International Conference on Machine Learning (ICML) (2018)
2018
-
[24]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (JSTARS) (2025)
Klotz, J., Burgert, T., Demir, B.: On the effectiveness of methods and metrics for explainable AI in remote sensing image scene classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (JSTARS) (2025)
2025
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) (2026)
Kopf, L., Feldhus, N., Bykov, K., Bommer, P.L., Hedström, A., Höhne, M., Eberle, O.: Capturing polysemanticity with prism: A multi-concept feature description framework. Advances in Neural Information Processing Systems (NeurIPS) (2026)
2026
-
[26]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025)
2025
-
[27]
Japan Journal of Industrial and Applied Mathematics41(1), 1–12 (2024)
Li, H., Ying, H., Liu, X.: Binary generalized orthogonal matching pursuit. Japan Journal of Industrial and Applied Mathematics41(1), 1–12 (2024)
2024
-
[28]
ArXiv e-print (2024)
Lim, H., Choi, J., Choo, J., Schneider, S.: Sparse autoencoders reveal selective remapping of visual concepts during adaptation. ArXiv e-print (2024)
2024
-
[29]
CoRR (2014)
Lin, T.Y., Maire, M., Belongie, S.J., Bourdev, L.D., Girshick, R.B., Hays, J., Per- ona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. CoRR (2014)
2014
-
[30]
Proceedings of the International Con- ference on Learning Representations (ICLR) (2025)
Makelov, A., Lange, G., Nanda, N.: Towards principled evaluations of sparse au- toencoders for interpretability and control. Proceedings of the International Con- ference on Learning Representations (ICLR) (2025)
2025
-
[31]
IEEE Transactions on signal processing41(12), 3397–3415 (1993)
Mallat, S.G., Zhang, Z.: Matching pursuits with time-frequency dictionaries. IEEE Transactions on signal processing41(12), 3397–3415 (1993)
1993
-
[32]
Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) pp
Mueller, A., Brinkmann, J., Li, M., Marks, S., Pal, K., Prakash, N., Rager, C., Sankaranarayanan, A., Sharma, A.S., Sun, J., Todd, E., Bau, D., Belinkov, Y.: The quest for the right mediator: Surveying mechanistic interpretability for nlp through the lens of causal mediation analysis. Proceedings of the Annual Meeting of the Association for Computational ...
2026
-
[33]
SIAM Journal on Computing24(2), 227–234 (1995)
Natarajan, B.K.: Sparse approximate solutions to linear systems. SIAM Journal on Computing24(2), 227–234 (1995)
1995
-
[34]
Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
Olson, M.L., Hinck, M., Ratzlaff, N., Li, C., Howard, P., Lal, V., Tseng, S.Y.: Analyzing hierarchical structure in vision models with sparse autoencoders. Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2025)
2025
-
[35]
The Journal of Transactions on Machine Learning Research (TMLR) (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[36]
Advances in Neural Infor- mation Processing Systems (NeurIPS) (2025)
Pach, M., Karthik, S., Bouniot, Q., Belongie, S., Akata, Z.: Sparse autoencoders learn monosemantic features in vision-language models. Advances in Neural Infor- mation Processing Systems (NeurIPS) (2025)
2025
-
[37]
Con- ference Record of The Twenty-Seventh Asilomar Conference on Signals, Systems and Computers (1993)
Pati, Y.C., Rezaiifar, R., Krishnaprasad, P.S.: Orthogonal matching pursuit: Re- cursive function approximation with applications to wavelet decomposition. Con- ference Record of The Twenty-Seventh Asilomar Conference on Signals, Systems and Computers (1993)
1993
-
[38]
In: Proceedings of the International Conference on Machine Learning (ICML) (2025)
Paulo, G.S., Mallen, A.T., Juang, C., Belrose, N.: Automatically interpreting mil- lions of features in large language models. In: Proceedings of the International Conference on Machine Learning (ICML) (2025)
2025
-
[39]
Proceedings of the International Conference on Machine Learning (ICML) (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. Proceedings of the International Conference on Machine Learning (ICML) (2021)
2021
-
[40]
ArXiv e-print (2024)
Rajamanoharan, S., Lieberum, T., Sonnerat, N., Conmy, A., Varma, V., Kramár, J., Nanda, N.: Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders. ArXiv e-print (2024)
2024
-
[41]
Proceedings of the IEEE European Conference on Computer Vision (ECCV) (2024)
Rao, S., Mahajan, S., Böhle, M., Schiele, B.: Discover-then-name: Task-agnostic concept bottlenecks via automated concept discovery. Proceedings of the IEEE European Conference on Computer Vision (ECCV) (2024)
2024
-
[42]
Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) (2024)
Rimsky, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., Turner, A.: Steering llama 2 via contrastive activation addition. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) (2024)
2024
-
[43]
Proceedings of the IEEE98(6), 1045–1057 (2010)
Rubinstein, R., Bruckstein, A.M., Elad, M.: Dictionaries for sparse representation modeling. Proceedings of the IEEE98(6), 1045–1057 (2010)
2010
-
[44]
Knowledge-Based Systems263, 110273 (2023)
Saeed, W., Omlin, C.: Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. Knowledge-Based Systems263, 110273 (2023)
2023
-
[45]
Saphra, N., Wiegreffe, S.: Mechanistic? In: Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP (2024)
2024
-
[46]
Pro- ceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) (2025)
Shu, D., Wu, X., Zhao, H., Rai, D., Yao, Z., Liu, N., Du, M.: A survey on sparse autoencoders: Interpreting the internal mechanisms of large language models. Pro- ceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) (2025)
2025
-
[47]
Anthropic (2024)
Templeton, A.: Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet. Anthropic (2024)
2024
-
[48]
IEEE Signal Processing Magazine 28(2), 27–38 (2011)
Tošić, I., Frossard, P.: Dictionary learning. IEEE Signal Processing Magazine 28(2), 27–38 (2011)
2011
-
[49]
IEEE Transactions on Information Theory50(10), 2231–2242 (2004) 18 J
Tropp, J.A.: Greed is good: Algorithmic results for sparse approximation. IEEE Transactions on Information Theory50(10), 2231–2242 (2004) 18 J. Klotz et al
2004
-
[50]
IEEE Transactions on Information Theory53(12), 4655–4666 (2007)
Tropp, J.A., Gilbert, A.C.: Signal recovery from random measurements via or- thogonal matching pursuit. IEEE Transactions on Information Theory53(12), 4655–4666 (2007)
2007
-
[51]
Advances in Neural In- formation Processing Systems (NeurIPS) (2025)
Vielhaben, J., Bareeva, D., Berend, J., Samek, W., Strodthoff, N.: Beyond scalars: Concept-based alignment analysis in vision transformers. Advances in Neural In- formation Processing Systems (NeurIPS) (2025)
2025
-
[52]
California Institute of Technology Technical Report (2011)
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The caltech-ucsd birds-200-2011 dataset. California Institute of Technology Technical Report (2011)
2011
-
[53]
ICML 2024 Workshop on Mechanistic Interpretability (2024)
Wattenberg, M., Viégas, F.: Relational composition in neural networks: A survey and call to action. ICML 2024 Workshop on Mechanistic Interpretability (2024)
2024
-
[54]
Inverse Problems37(6), 065014 (2021)
Wen, J., Li, H.: Binary sparse signal recovery with binary matching pursuit. Inverse Problems37(6), 065014 (2021)
2021
-
[55]
yellow head
Zaigrajew, V., Baniecki, H., Biecek, P.: Interpreting CLIP with hierarchical sparse autoencoders. Proceedings of the International Conference on Machine Learning (ICML) (2025) Evaluating the Interpretability of SAEs with Concept Annotations 19 Supplementary Materials –S1:Discussions and Broader Impact –S2:Latent–Concept Matching Details –S3:Synthetic Data...
2025
-
[56]
Scene layout and arrangement of all remaining objects
-
[57]
Identity, pose, and appearance of all non-{target_class} objects
-
[58]
Background structures. 5. Lighting, shadows, reflections, and overall color grading
-
[59]
Global weather, time of day, and atmosphere
-
[60]
Prohibitions:
No stylistic changes; keep the image photorealistic. Prohibitions:
-
[61]
Do not add any new objects or people
-
[62]
Do not remove or modify any non-{target_class} object
-
[63]
Do not alter shapes or positions beyond removed pixel regions. 4. Do not change the environment or setting
-
[64]
Output: One realistic photograph matching the original except that all instances of {target_class} are absent and the scene hasbeen plausibly completed
Do not introduce stylization, blur, or artifacts. Output: One realistic photograph matching the original except that all instances of {target_class} are absent and the scene hasbeen plausibly completed. Prompt: synCUB Task: counterfactual single-attribute edit. Inputs: Image 1 is the base photograph. Image 2 is areference exemplar for the target attribute...
-
[65]
Bird identity and species-specific appearance
-
[66]
Pose, body shape, size, viewpoint, framing, and scale
-
[67]
Background, environment, and all non-bird objects. 4. Lighting, shadows, and overall color grading
-
[68]
All other colors, patterns, textures, and markings on the bird
-
[69]
No additions, removals, or hallucinated objects
-
[70]
Prohibitions:
Keep breast color from Image 1 when changing pattern. Prohibitions:
-
[71]
Do not change beak, head, eye shape, or unrelatedmarkings
-
[72]
Do not change the background or introduce new scenery
-
[73]
Gi- raffe
Do not import traits from Image 2 except the target attribute. Output: one realistic photograph matching Image 1 except for the single specified attribute change. Fig. S15:Prompts for the image generation the model to modify only the specified attribute while preserving identity, pose, and background. For synCOCO, no reference images are used. Since the e...
2048
-
[74]
From left to right:∆MATCHScore and TAPAScore on CUB/synCUB, followed by∆MATCHScore and TAPAScore on COCO/synCOCO
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.