ConVer: Using Contracts and Loop Invariant Synthesis for Scalable Formal Software Verification
Pith reviewed 2026-06-29 15:37 UTC · model grok-4.3
The pith
ConVer decomposes C program verification top-down by synthesizing LLM contracts and refining them via CEGAR-CEGIS to reduce state-space explosion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
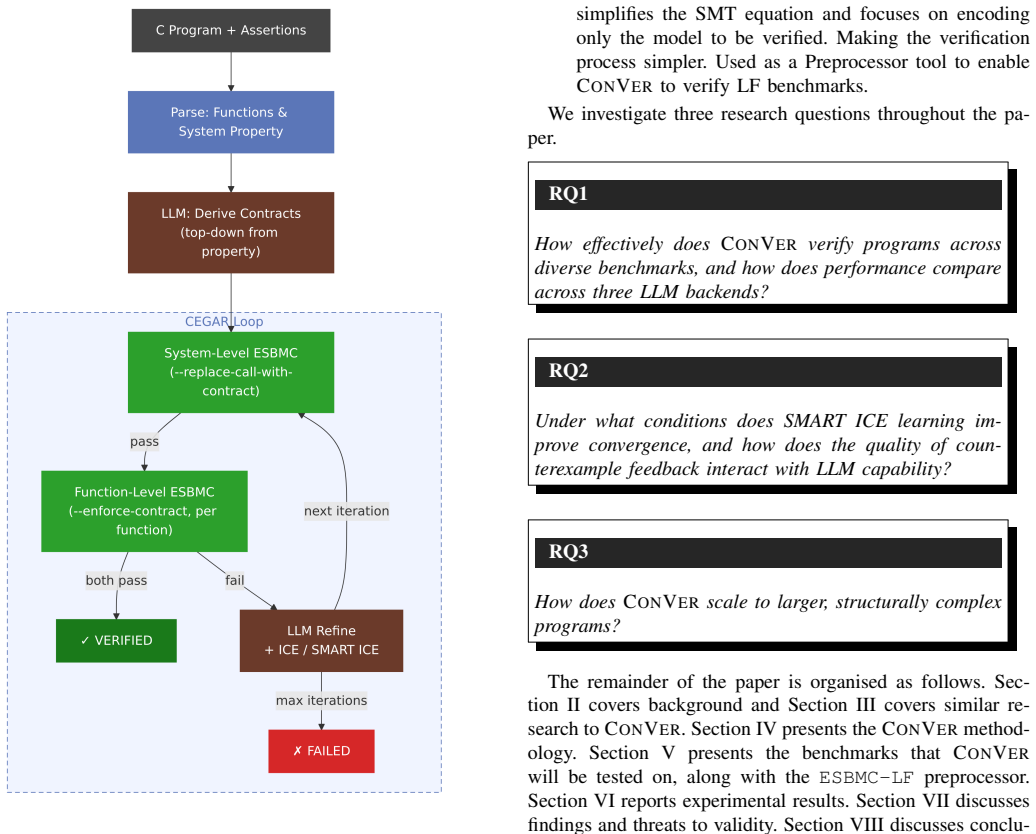
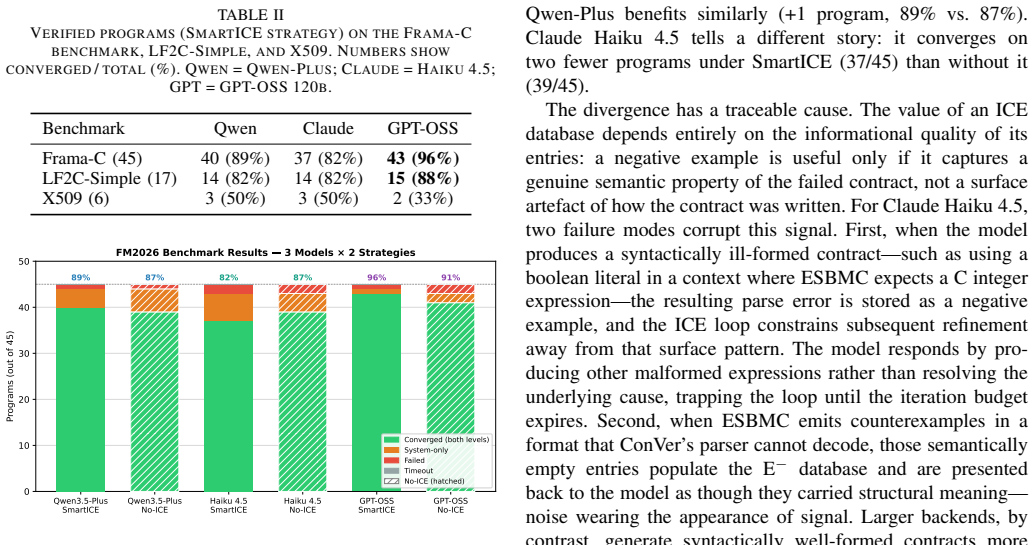
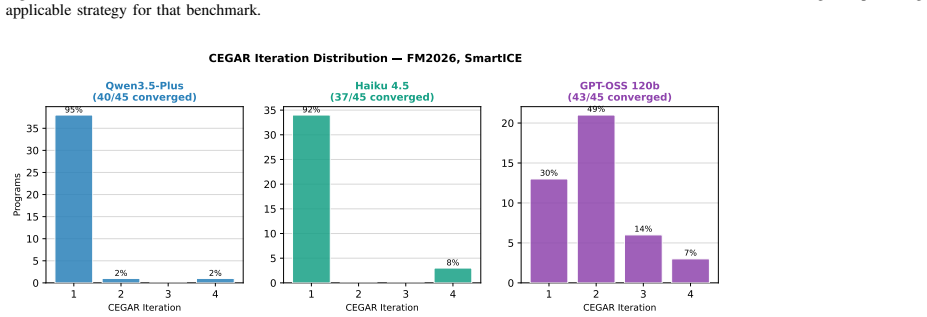
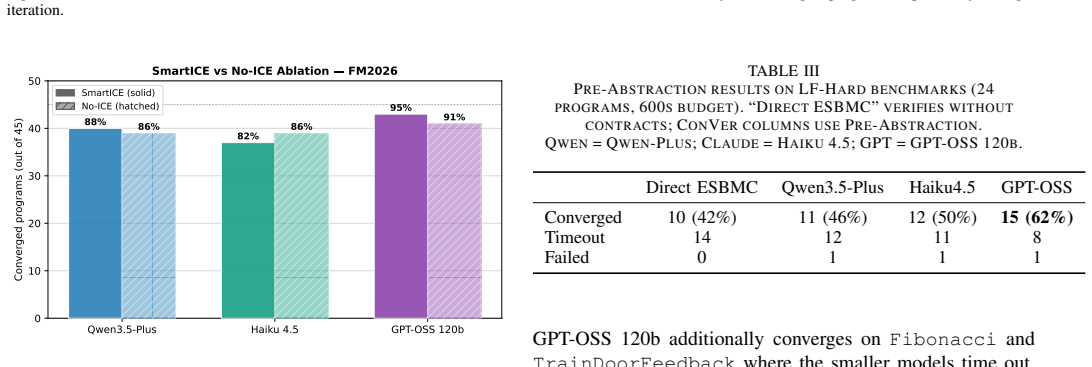
ConVer decomposes verification top-down: it uses a large language model to synthesise function contracts from the system property, then alternates system-level and function-level checks in a CEGAR-CEGIS loop, refining contracts whenever a check fails via SMART ICE learning. On the Frama-C benchmark of 45 simple C programs, it achieves 82-96% verification success across three LLM backends, with 93-95% of converged programs requiring only a single CEGAR-CEGIS iteration.
What carries the argument
Top-down compositional verification that synthesizes and refines LLM-generated function contracts inside a CEGAR-CEGIS loop with SMART ICE learning.
If this is right
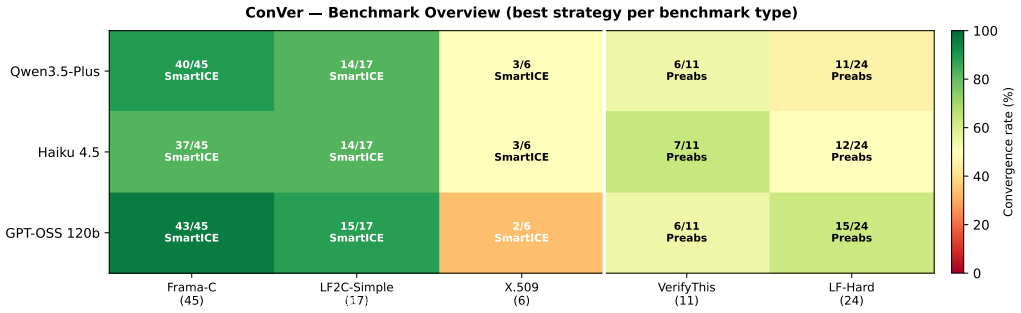
- 82-96% success on Frama-C with most cases converging after one iteration.
- 33-50% success on the X.509 parser suite and 82-88% on LF2C-Simple.
- 55-64% success on VerifyThis recursive programs using the Pre-Abstraction strategy.
- 67% success on LF-Hard benchmarks after transpilation to C via ESBMC-LF.
Where Pith is reading between the lines
- The same contract synthesis and refinement pattern could be tested on programs written in languages other than C if an equivalent model checker is available.
- If contract stability holds for industrial codebases, the approach would lower the manual annotation burden that currently limits adoption of formal methods.
- Different LLM backends yielding similar success rates suggests the method is not tightly coupled to any single model family.
- Programs with deeper recursion or more complex data structures than VerifyThis may require additional abstraction layers beyond the Pre-Abstraction strategy.
Load-bearing premise
LLM-generated contracts stay stable enough that the refinement loop can converge on programs whose structure matches the evaluated benchmarks.
What would settle it
A collection of C programs whose function dependencies differ markedly from the Frama-C and LF suites on which the LLM contracts repeatedly fail to stabilize after three or more refinement iterations.
Figures

read the original abstract
Formal verification of large C programs is impeded by state-space explosion: Bounded Model Checking (BMC) tools must encode the entire state space up to the predetermined bound by unrolling all nested constructs. We present ConVer, a top-down compositional verification tool. Given a C program with a top-level assertion, ConVer decomposes verification top-down: it uses a large language model (LLM) to synthesise function contracts from the system property, then alternates system-level and function-level checks in a CEGAR-CEGIS loop, refining contracts whenever a check fails via SMART ICE learning. We evaluate ConVer on four benchmark suites of increasing difficulty and against other state-of-the-art (SOTA) tools. On the Frama-C benchmark of 45 simple C programs, ConVer achieves 82-96% verification success across three LLM backends, with 93-95% of converged programs requiring only a single CEGAR-CEGIS iteration. On the X.509 parser benchmark (6~programs) and LF2C-Simple suite (17 programs), ConVer achieves 33-50% and 82-88% success respectively. On the VerifyThis suite of 11 recursive and loop-intensive programs, the Pre-Abstraction strategy achieves 55-64% success. In addition, we present ESBMC-LF a preprocessor tool that converts LF models to C while preserving the properties of the LF files, enabling ConVer to verify them. We transpile the LF Verifier Benchmarks using ESBMC-LF to C; we denote those LF-Hard. We show that ConVer successfully verifies 67% of LF-Hard benchmarks overall.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ConVer, a top-down compositional verification tool for C programs. It uses an LLM to synthesize function contracts from a top-level assertion, then alternates system-level and function-level checks in a CEGAR-CEGIS loop, refining contracts via SMART ICE learning when checks fail. The approach is evaluated on four benchmark suites of increasing difficulty (Frama-C with 45 simple programs, X.509 with 6 programs, LF2C-Simple with 17 programs, VerifyThis with 11 recursive/loop-intensive programs, plus LF-Hard derived via the new ESBMC-LF transpiler), reporting 82-96% success on Frama-C (with 93-95% single-iteration convergence), 33-50% on X.509, 82-88% on LF2C-Simple, 55-64% on VerifyThis (Pre-Abstraction), and 67% on LF-Hard.
Significance. If the empirical results hold under more rigorous experimental controls, ConVer could advance scalable formal verification by reducing manual contract specification through LLM assistance and compositional decomposition. The multi-suite evaluation, including introduction of ESBMC-LF for LF-to-C transpilation and testing on recursive programs, provides a useful baseline for LLM-assisted verification tools. The high single-iteration convergence on simple cases is a concrete strength worth highlighting.
major comments (2)
- [Evaluation] Evaluation section (results on Frama-C, X.509, VerifyThis): success percentages (82-96%, 33-50%, 55-64%) are reported without an experimental protocol, number of LLM runs per program, statistical tests, variance measures, or systematic failure-case analysis. This directly affects the ability to judge whether the numbers support the central claim of scalable verification via stable LLM contracts.
- [Evaluation] Evaluation on VerifyThis and X.509 suites: lower success rates are noted but without reporting iteration counts, contract refinement success/failure breakdowns, or metrics on contract stability for recursive/loop-intensive or parser programs. This leaves the CEGAR-CEGIS convergence assumption untested precisely where program structure diverges from the Frama-C simple cases.
minor comments (2)
- [Abstract] The abstract and evaluation could more clearly distinguish between the three LLM backends and their individual results rather than reporting ranges.
- [Approach] Notation for SMART ICE and the CEGAR-CEGIS loop could be introduced with a small diagram or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting gaps in the evaluation section. We address each major comment below and commit to revisions that add the requested experimental details to better support our claims about LLM-assisted contract synthesis and CEGAR-CEGIS convergence.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (results on Frama-C, X.509, VerifyThis): success percentages (82-96%, 33-50%, 55-64%) are reported without an experimental protocol, number of LLM runs per program, statistical tests, variance measures, or systematic failure-case analysis. This directly affects the ability to judge whether the numbers support the central claim of scalable verification via stable LLM contracts.
Authors: We agree that the current manuscript does not provide a full experimental protocol, the number of LLM runs per program, statistical tests, variance measures, or a systematic failure-case analysis. This limits readers' ability to evaluate contract stability. In the revised manuscript we will add a dedicated 'Experimental Protocol' subsection that specifies the number of independent LLM runs performed for each program and configuration, reports observed variance across runs, includes basic statistical measures where appropriate, and provides a categorized breakdown of failure cases (e.g., synthesis failure vs. refinement divergence). These additions will directly address the concern about supporting the central claim. revision: yes
-
Referee: [Evaluation] Evaluation on VerifyThis and X.509 suites: lower success rates are noted but without reporting iteration counts, contract refinement success/failure breakdowns, or metrics on contract stability for recursive/loop-intensive or parser programs. This leaves the CEGAR-CEGIS convergence assumption untested precisely where program structure diverges from the Frama-C simple cases.
Authors: We acknowledge that iteration counts, refinement success/failure breakdowns, and contract stability metrics are not reported for the X.509 and VerifyThis suites. In the revision we will extend the results tables and accompanying text for these suites to include per-program and aggregate iteration counts, the fraction of cases requiring refinement steps, and indicators of contract stability (e.g., whether contracts stabilized after the first synthesis or needed multiple updates). This will allow direct assessment of the CEGAR-CEGIS loop on recursive and parser programs. revision: yes
Circularity Check
No circularity; purely empirical evaluation on external benchmarks
full rationale
The paper describes a compositional verification tool (ConVer) that combines LLM contract synthesis with a CEGAR-CEGIS loop and reports success rates directly on four external benchmark suites (Frama-C, X.509, LF2C-Simple, VerifyThis, LF-Hard). No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the abstract or described content. All performance figures (82-96% on Frama-C, lower rates on other suites) are presented as measured outcomes rather than derived by construction from the tool's own inputs or prior self-citations. The central claims therefore remain independent of any internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Esbmc v7. 7: Efficient concurrent software verification with scheduling, incremental smt and partial order reduction: (competition contribution),
T. Wu, X. Li, E. Manino, R. S. Menezes, M. R. Gadelha, S. Xiong, N. Tihanyi, P. Petoumenos, and L. C. Cordeiro, “Esbmc v7. 7: Efficient concurrent software verification with scheduling, incremental smt and partial order reduction: (competition contribution),” inInternational Conference on Tools and Algorithms for the Construction and Analysis of Systems. ...
2025
-
[2]
Code-level model checking in the software development workflow at amazon web services,
N. Chong, B. Cook, J. Eidelman, K. Kallas, K. Khazem, F. R. Monteiro, D. Schwartz-Narbonne, S. Tasiran, M. Tautschnig, and M. R. Tuttle, “Code-level model checking in the software development workflow at amazon web services,”Software: Practice and Experience, vol. 51, no. 4, pp. 772–797, 2021
2021
-
[3]
Model checking and the state explosion problem,
E. M. Clarke, W. Klieber, M. Nov ´aˇcek, and P. Zuliani, “Model checking and the state explosion problem,” inLASER Summer School on Software Engineering. Springer, 2011, pp. 1–30
2011
-
[4]
Counterexample- guided abstraction refinement,
E. Clarke, O. Grumberg, S. Jha, Y . Lu, and H. Veith, “Counterexample- guided abstraction refinement,” inInternational Conference on Com- puter Aided Verification. Springer, 2000, pp. 154–169
2000
-
[5]
Ice: A robust framework for learning invariants,
P. Garg, C. L ¨oding, P. Madhusudan, and D. Neider, “Ice: A robust framework for learning invariants,” inInternational Conference on Computer Aided Verification. Springer, 2014, pp. 69–87
2014
-
[6]
Symbolic model checking without bdds,
A. Biere, A. Cimatti, E. Clarke, and Y . Zhu, “Symbolic model checking without bdds,” inInternational conference on tools and algorithms for the construction and analysis of systems. Springer, 1999, pp. 193–207
1999
-
[7]
Bounded model checking
A. Biere, A. Cimatti, E. M. Clarke, O. Strichman, and Y . Zhu, “Bounded model checking.”Handbook of satisfiability, vol. 185, no. 99, pp. 457– 481, 2009
2009
-
[8]
Bounded Model Checking of Multi-threaded Software using SMT solvers
L. Cordeiro and B. Fischer, “Bounded model checking of multi-threaded software using smt solvers,”arXiv preprint arXiv:1003.3830, 2010
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Esbmc 5.0: an industrial-strength c model checker,
M. R. Gadelha, F. R. Monteiro, J. Morse, L. C. Cordeiro, B. Fischer, and D. A. Nicole, “Esbmc 5.0: an industrial-strength c model checker,” inProceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, 2018, pp. 888–891
2018
-
[10]
Esbmc v7. 4: Harnessing the power of intervals: (competition contribution),
R. S. Menezes, M. Aldughaim, B. Farias, X. Li, E. Manino, F. Shmarov, K. Song, F. Brauße, M. R. Gadelha, N. Tihanyiet al., “Esbmc v7. 4: Harnessing the power of intervals: (competition contribution),” in International Conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 2024, pp. 376–380
2024
-
[11]
Large language model (llm) for software security: Code analysis, malware analysis, reverse engineering,
H. Jelodar, S. Bai, P. Hamedi, H. Mohammadian, R. Razavi-Far, and A. Ghorbani, “Large language model (llm) for software security: Code analysis, malware analysis, reverse engineering,”Journal of Information Security and Applications, vol. 98, p. 104390, 2026
2026
-
[12]
Automated Program Repair in the Era of Large Pre-trained Language Models,
C. S. Xia, Y . Wei, and L. Zhang, “Automated Program Repair in the Era of Large Pre-trained Language Models,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). Melbourne, Australia: IEEE, May 2023, pp. 1482–1494. [Online]. Available: https://ieeexplore.ieee.org/document/10172803/
-
[13]
Evaluating Language Models for Efficient Code Generation,
J. Liu, S. Xie, J. Wang, Y . Wei, Y . Ding, and L. Zhang, “Evaluating Language Models for Efficient Code Generation,” Aug. 2024, arXiv:2408.06450. [Online]. Available: http://arxiv.org/abs/2408.06450
-
[14]
A new era in software security: Towards self-healing software via large language models and formal verification,
N. Tihanyi, Y . Charalambous, R. Jain, M. A. Ferrag, and L. C. Cordeiro, “A new era in software security: Towards self-healing software via large language models and formal verification,” in2025 IEEE/ACM International Conference on Automation of Software Test (AST). IEEE, 2025, pp. 136–147
2025
-
[15]
The use of large language models for program repair,
F. Zubair, M. Al-Hitmi, and C. Catal, “The use of large language models for program repair,”Computer Standards & Interfaces, vol. 93, p. 103951, Apr. 2025. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S092054892400120X
2025
-
[16]
Towards Effectively Leveraging Execution Traces for Program Repair with Code LLMs,
M. Haque, P. Babkin, F. Farmahinifarahani, and M. Veloso, “Towards Effectively Leveraging Execution Traces for Program Repair with Code LLMs,” May 2025, arXiv:2505.04441 [cs] version: 1. [Online]. Available: http://arxiv.org/abs/2505.04441
-
[17]
Polyver: A compositional approach for polyglot system modeling and verification,
P.-W. Chen, S. Lin, A. Godbole, R. Singh, E. Polgreen, E. Lee, and S. Seshia, “Polyver: A compositional approach for polyglot system modeling and verification,” 2025. [Online]. Available: https: //repositum.tuwien.at/handle/20.500.12708/219538
2025
-
[18]
Z. Wang, T. Lin, M. Chen, H. Li, M. Yang, X. Yi, S. Qin, Y . Luo, X. Li, B. Guet al., “A tale of 1001 loc: Potential runtime error- guided specification synthesis for verifying large-scale programs,”arXiv preprint arXiv:2512.24594, 2025
-
[19]
Uclid5: integrating modeling, veri- fication, synthesis and learning,
S. A. Seshia and P. Subramanyan, “Uclid5: integrating modeling, veri- fication, synthesis and learning,” in2018 16th ACM/IEEE International Conference on Formal Methods and Models for System Design (MEM- OCODE). IEEE, 2018, pp. 1–10
2018
-
[20]
Array-carrying symbolic execution for function contract generation,
W. Lu, J. Ke, H. Fu, Z. Sun, Y . Zhou, G. Li, and H. Li, “Array-carrying symbolic execution for function contract generation,” inProceedings of the 26th International Symposium on Formal Methods (FM 2026), ser. Lecture Notes in Computer Science. Springer, 2026
2026
-
[21]
Yesterday, my program worked. today, it does not. why?
A. Zeller, “Yesterday, my program worked. today, it does not. why?” ACM SIGSOFT Software engineering notes, vol. 24, no. 6, pp. 253–267, 1999
1999
-
[22]
Simplifying and isolating failure-inducing input,
A. Zeller and R. Hildebrandt, “Simplifying and isolating failure-inducing input,”IEEE Transactions on software engineering, vol. 28, no. 2, pp. 183–200, 2002
2002
-
[23]
ESBMC 7.4: Harnessing the power of intervals,
R. S ´a Menezes, M. Aldughaim, B. Farias, X. Li, E. Manino, F. Shmarov, K. Song, F. Brauße, M. R. Gadelha, N. Tihanyi, K. Korovin, and L. C. Cordeiro, “ESBMC 7.4: Harnessing the power of intervals,” Systems & Software Verification Laboratory, Software Documentation, 2024, version 7.4. Available at: https: //github.com/esbmc/esbmc. Accessed: 2026-03-20. [O...
2024
-
[24]
Llm-generated invariants for bounded model checking without loop unrolling,
M. A. Pirzada, G. Reger, A. Bhayat, and L. C. Cordeiro, “Llm-generated invariants for bounded model checking without loop unrolling,” inPro- ceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, 2024, pp. 1395–1407
2024
-
[25]
Assume-guarantee abstraction refinement for probabilistic systems,
A. Komuravelli, C. S. P ˘as˘areanu, and E. M. Clarke, “Assume-guarantee abstraction refinement for probabilistic systems,” inInternational con- ference on computer aided verification. Springer, 2012, pp. 310–326
2012
-
[26]
Sketching concurrent data structures,
A. Solar-Lezama, C. G. Jones, and R. Bodik, “Sketching concurrent data structures,” inProceedings of the 29th ACM SIGPLAN Conference on Programming Language Design and Implementation, ser. PLDI ’08. New York, NY , USA: Association for Computing Machinery, 2008, p. 136–148. [Online]. Available: https://doi.org/10.1145/1375581.1375599
-
[27]
A complexity measure,
T. J. McCabe, “A complexity measure,”IEEE Transactions on software Engineering, no. 4, pp. 308–320, 1976
1976
-
[28]
Towards building verifiable cps using lingua franca,
S. Lin, Y . A. Manerkar, M. Lohstroh, E. Polgreen, S.-J. Yu, C. Jerad, E. A. Lee, and S. A. Seshia, “Towards building verifiable cps using lingua franca,”ACM Transactions on Embedded Computing Systems, vol. 22, no. 5s, pp. 1–24, 2023
2023
-
[29]
Introducing Claude 3.5 Sonnet,
Anthropic, “Introducing Claude 3.5 Sonnet,” 2024, accessed: 2026-03-27. [Online]. Available: https://www.anthropic.com/news/ claude-3-5-sonnet
2024
-
[30]
State of the art in software verification and witness validation: Sv-comp 2024,
D. Beyer, “State of the art in software verification and witness validation: Sv-comp 2024,” inInternational Conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 2024, pp. 299–329
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.