Agentra: A Supervisable Multi-Agent Framework for Enterprise Intrusion Response
Pith reviewed 2026-06-26 23:57 UTC · model grok-4.3
The pith
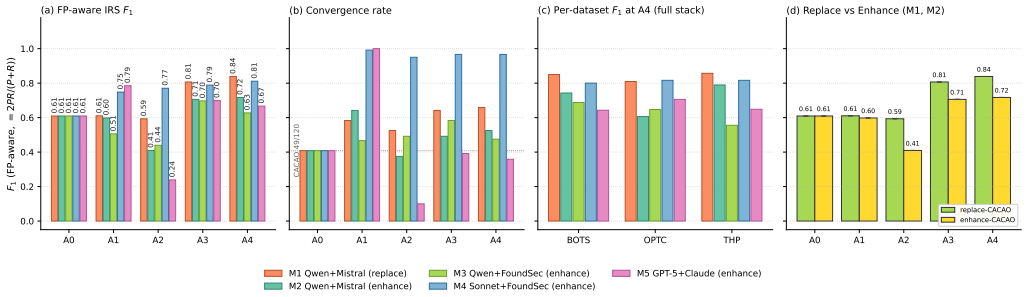
Multi-agent framework turns alerts into validated response plans that lift F1 from 0.61 to 0.84 while restoring harmful-action rate to zero.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
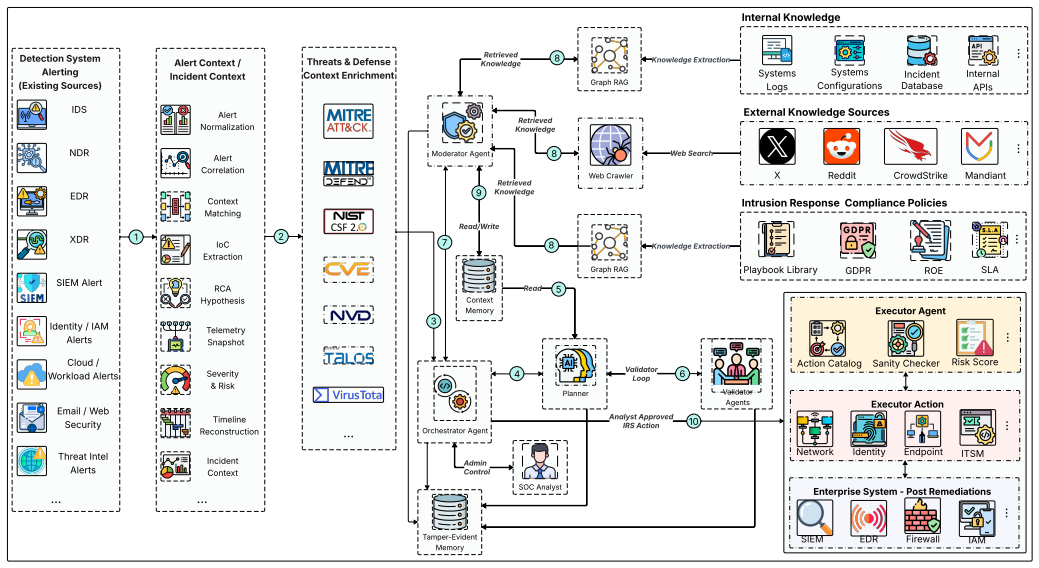
Agentra decomposes response reasoning across role-scoped agents, validates proposed plans through a bounded Planner--Validator review loop, screens retrieved threat intelligence through a Moderator security gateway, gates actions through an Action Catalog and risk score, and records decisions in an append-only audit log. Evaluation against a static OASIS CACAO v2.0 cyber-playbook baseline on a 120-event corpus drawn from ThreatHunter-Playbook, Splunk BOTSv3, and DARPA OpTC shows the strongest configuration improves FP-aware IRS F1 from 0.61 to 0.84 and restores the projected harmful-action rate to the static baseline level of 0.0 percent after Planner-only configurations introduce unsafe ove
What carries the argument
The bounded Planner-Validator review loop together with the Moderator gateway and Action Catalog that together enforce ontology-grounded, risk-scored, and fully auditable plans.
If this is right
- Multi-agent response planning improves ontology-grounded IRS coverage over static playbooks.
- The review loop and moderator restore harmful-action rate to the static baseline of 0.0 percent.
- Analyst approval and append-only audit logs remain intact.
- The framework converts alerts from IDS, EDR, and XDR platforms into structured plans.
- Bounded validation prevents unsafe overreaction seen in planner-only runs.
Where Pith is reading between the lines
- The same role-scoped decomposition with validation gates could be tested on other supervised automation tasks such as incident triage or patch deployment.
- Integration with live SIEM feeds would require measuring end-to-end latency from alert to approved action.
- The audit log structure may support regulatory reporting requirements beyond current evaluation.
- Scaling the Action Catalog to new threat ontologies would need explicit coverage metrics.
Load-bearing premise
The 120-event corpus drawn from ThreatHunter-Playbook, Splunk BOTSv3, and DARPA OpTC is representative enough to support claims of improved coverage and safety in real enterprise environments.
What would settle it
Running the full Agentra pipeline on a fresh corpus of several hundred live enterprise incidents and checking whether FP-aware F1 stays above 0.80 while harmful-action rate remains at 0.0 percent.
Figures
read the original abstract
Enterprise intrusion response still depends on static playbooks and analyst-driven triage, creating delay between alert generation and containment. We present Agentra, a supervisable multi-agent Intrusion Response System (IRS) framework that converts alerts from IDS, EDR, and XDR platforms into structured incident response plans grounded in MITRE ATT&CK, MITRE D3FEND, and NIST CSF 2.0. Agentra decomposes response reasoning across role-scoped agents, validates proposed plans through a bounded Planner--Validator review loop, screens retrieved threat intelligence through a Moderator security gateway, gates actions through an Action Catalog and risk score, and records decisions in an append-only audit log. We evaluate Agentra against a static OASIS CACAO v2.0 cyber-playbook baseline on a 120-event corpus drawn from ThreatHunter-Playbook, Splunk BOTSv3, and DARPA OpTC. The strongest configuration improves FP-aware IRS F1 from 0.61 to 0.84 and restores the projected harmful-action rate to the static baseline level of 0.0% after Planner-only configurations introduce unsafe overreaction. These results indicate that multi-agent response planning can improve ontology-grounded IRS coverage while preserving analyst approval and auditability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Agentra, a supervisable multi-agent IRS framework that decomposes alert response across role-scoped agents, employs a bounded Planner-Validator review loop, screens threat intelligence via a Moderator gateway, gates actions through an Action Catalog and risk scoring, and maintains an append-only audit log. Grounded in MITRE ATT&CK, D3FEND, and NIST CSF 2.0, it is evaluated against a static OASIS CACAO v2.0 playbook baseline on a 120-event corpus from ThreatHunter-Playbook, Splunk BOTSv3, and DARPA OpTC. The strongest configuration reports an FP-aware IRS F1 increase from 0.61 to 0.84 while restoring the projected harmful-action rate to the baseline level of 0.0%.
Significance. If the evaluation results hold under more rigorous conditions, the work could provide a concrete example of how multi-agent decomposition with explicit validation and gating mechanisms can improve ontology-grounded coverage in intrusion response while preserving analyst oversight and auditability. The design choices around bounded loops and risk scoring address practical deployment constraints in enterprise settings.
major comments (2)
- [Abstract] Abstract: The central quantitative claims (F1 0.61→0.84 and harmful-action rate restoration to 0.0%) are derived exclusively from a 120-event corpus assembled from synthetic playbooks and exercise captures. No evidence is supplied that this corpus matches the volume, alert-rate distribution, false-positive prevalence, or multi-vendor telemetry noise of production enterprise environments; without such grounding, the reported gains cannot be extrapolated to support the claim of improved coverage with preserved safety in real IRS workloads.
- [Abstract] Abstract: The reported FP-aware F1 improvement and harmful-action metrics are presented without error bars, statistical significance tests, detailed exclusion criteria, or a full description of the evaluation protocol. This absence makes it impossible to assess whether the observed differences are robust or whether the multi-agent configurations genuinely outperform the static baseline beyond the specific corpus.
minor comments (1)
- [Abstract] Abstract: The comparison baseline is referred to only as a 'static OASIS CACAO v2.0 cyber-playbook baseline' without specifying how the static playbook is instantiated, how its ontology grounding is measured, or how actions are selected in the absence of the multi-agent components.
Simulated Author's Rebuttal
We thank the referee for highlighting the evaluation scope and statistical presentation. We respond to each major comment below and will make targeted revisions to the abstract to qualify the corpus and reference the evaluation protocol.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central quantitative claims (F1 0.61→0.84 and harmful-action rate restoration to 0.0%) are derived exclusively from a 120-event corpus assembled from synthetic playbooks and exercise captures. No evidence is supplied that this corpus matches the volume, alert-rate distribution, false-positive prevalence, or multi-vendor telemetry noise of production enterprise environments; without such grounding, the reported gains cannot be extrapolated to support the claim of improved coverage with preserved safety in real IRS workloads.
Authors: We agree the 120-event corpus is assembled from synthetic playbooks (ThreatHunter-Playbook) and exercise captures (Splunk BOTSv3, DARPA OpTC) rather than live production telemetry. The manuscript frames the results as a controlled, reproducible comparison against the OASIS CACAO baseline on this corpus; the abstract conclusion is scoped to what the results indicate about the framework rather than a direct claim of production deployment. We will revise the abstract to explicitly describe the corpus composition and state that extrapolation to arbitrary enterprise alert volumes and noise profiles requires further validation. revision: yes
-
Referee: [Abstract] Abstract: The reported FP-aware F1 improvement and harmful-action metrics are presented without error bars, statistical significance tests, detailed exclusion criteria, or a full description of the evaluation protocol. This absence makes it impossible to assess whether the observed differences are robust or whether the multi-agent configurations genuinely outperform the static baseline beyond the specific corpus.
Authors: Section 5 of the manuscript details the event selection, labeling, and protocol. The abstract, however, omits these elements and any mention of variability. We will revise the abstract to reference the evaluation section and note that the reported point estimates are obtained from the fixed 120-event corpus. We can also add a brief statement on the consistency of gains across the three data sources if space permits. revision: yes
Circularity Check
No circularity: empirical evaluation on external corpus and static baseline is independent of framework internals
full rationale
The paper presents a multi-agent IRS framework and reports performance gains (FP-aware F1 0.61→0.84, harmful-action rate restored to 0.0%) measured on a fixed 120-event corpus drawn from public sources (ThreatHunter-Playbook, Splunk BOTSv3, DARPA OpTC) against an external static OASIS CACAO baseline. No equations, fitted parameters, or self-citations are used to define the reported metrics; the evaluation quantities are computed from ground-truth labels and action outcomes on held-out events. The derivation chain consists of system description plus standard IR metrics, with no reduction of predictions to inputs by construction. This is the normal case for an empirical systems paper whose central claims rest on external data rather than tautological re-labeling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 Global Threat Report
CrowdStrike, “2026 Global Threat Report.” https://www.crowdstrike. com/en-us/resources/reports/global-threat-report/, 2026. [Accessed 11- 05-2026]
2026
-
[2]
2026 Unit 42 global incident re- sponse report
Unit 42, Palo Alto Networks, “2026 Unit 42 global incident re- sponse report.” https://www.paloaltonetworks.com/resources/research/ unit-42-incident-response-report, 2026. [Accessed 11-05-2026]
2026
-
[3]
Cost of a Data Breach Report 2025
IBM Security and Ponemon Institute, “Cost of a Data Breach Report 2025.” https://www.ibm.com/reports/data-breach, 2025. [Accessed 11- 05-2026]
2025
-
[4]
A multi-vocal review of security orchestration,
C. Islam, M. A. Babar, and S. Nepal, “A multi-vocal review of security orchestration,”ACM Computing Surveys, vol. 52, no. 2, 2019
2019
-
[5]
Leadership compass: Emerging AI secu- rity operations center (SOC)
KuppingerCole Analysts, “Leadership compass: Emerging AI secu- rity operations center (SOC).” https://www.kuppingercole.com/reprints/ b23fa477e7a19a6e24f60c7413c25a44, 2026. [Accessed 11-05-2026]
2026
-
[6]
IR- Copilot: Automated incident response with large language models,
X. Lin, J. Zhang, G. Deng, T. Liu, T. Zhang, Q. Guo, and R. Chen, “IR- Copilot: Automated incident response with large language models,” in Proceedings of the Network and Distributed System Security Symposium (NDSS 2025), (San Diego, CA, USA), February 2025
2025
-
[7]
Advancing autonomous incident response: Leveraging LLMs and cyber threat intelligence
A. Tellache, A. A. Korba, A. Mokhtari, H. Moldovan, and Y . Ghamri- Doudane, “Advancing autonomous incident response: Leveraging LLMs and cyber threat intelligence.” https://arxiv.org/abs/2508.10677, 2025. [Accessed 11-05-2026]
arXiv 2025
-
[8]
Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,” inProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec), pp. 79–90, ACM, 2023
2023
-
[9]
AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,
E. Debenedetti, J. Zhang, M. Balunovi ´c, L. Beurer-Kellner, M. Fischer, and F. Tram`er, “AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[10]
The NIST cyberse- curity framework (CSF) 2.0
National Institute of Standards and Technology, “The NIST cyberse- curity framework (CSF) 2.0.” https://nvlpubs.nist.gov/nistpubs/CSWP/ NIST.CSWP.29.pdf, 2024. [Accessed 11-05-2026]
2024
-
[11]
Collaborative automated course of action operations (CACAO) for cyber security version 2.0
OASIS Open, “Collaborative automated course of action operations (CACAO) for cyber security version 2.0.” https://docs.oasis-open.org/ cacao/security-playbooks/v2.0/, 2022. [Accessed 11-05-2026]
2022
-
[12]
Toward a knowledge graph of cybersecurity countermeasures
P. E. Kaloroumakis and M. J. Smith, “Toward a knowledge graph of cybersecurity countermeasures.” https://d3fend.mitre.org/resources/ D3FEND.pdf, 2021. [Accessed 11-05-2026]
2021
-
[13]
From local to global: A Graph RAG approach to query-focused summarization
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, D. Metropolitansky, R. O. Ness, and J. Larson, “From local to global: A Graph RAG approach to query-focused summarization.” https://arxiv. org/abs/2404.16130, 2024. [Accessed 11-05-2026]
Pith/arXiv arXiv 2024
-
[14]
IRP2API: Automated mapping of cyber security incident response plan to security tools’ APIs,
Z. T. Sworna, M. Ali Babar, and A. Sreekumar, “IRP2API: Automated mapping of cyber security incident response plan to security tools’ APIs,” in2023 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), pp. 546–557, 2023
2023
-
[15]
The ThreatHunter-Playbook
R. Rodriguez, “The ThreatHunter-Playbook.” https://github.com/OTRF/ ThreatHunter-Playbook. [Accessed 11-05-2026]
2026
-
[16]
Boss of the SOC (BOTS) dataset version 3
Splunk Inc., “Boss of the SOC (BOTS) dataset version 3.” https://github. com/splunk/botsv3, 2018. [Accessed 11-05-2026]
2018
-
[17]
Operationally transparent cyber (OpTC) data release
Defense Advanced Research Projects Agency (DARPA) and Five Di- rections, Inc., “Operationally transparent cyber (OpTC) data release.” https://github.com/FiveDirections/OpTC-data, 2020. [Accessed 11-05- 2026]
2020
-
[18]
Llama-3.1-FoundationAI- SecurityLLM-Base-8B technical report
P. Kassianik, D. Kedia, A. Karbasi,et al., “Llama-3.1-FoundationAI- SecurityLLM-Base-8B technical report.” https://arxiv.org/abs/2504. 21039, 2025. [Accessed 11-05-2026]
2025
-
[19]
Qwen3 technical report
Qwen Team, “Qwen3 technical report.” https://github.com/QwenLM/ Qwen3, 2025. [Accessed 11-05-2026]
2025
-
[20]
Mistral-Small-3.2-24B-Instruct-2506
Mistral AI, “Mistral-Small-3.2-24B-Instruct-2506.” https://mistral.ai/ news/mistral-small-3-2, 2025. [Accessed 11-05-2026]
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.